基于内容和旋律的音频片段识别与检索
2015-03-03吴海霞李艳玲刘潞锋
吴海霞,李艳玲,刘潞锋
(1.长治学院计算机系; 2.长治市郊区广电中心,山西 长治046011)
基于内容和旋律的音频片段识别与检索
吴海霞1,李艳玲1,刘潞锋2
(1.长治学院计算机系; 2.长治市郊区广电中心,山西 长治046011)
介绍了音频信号的主要特征和处理技术,给出音频检索系统的处理框架和主流产品,并列出典型检索引擎及应用行业;详细阐述了音频识别和检索的主要方法、基于旋律和内容的音频片段检索的原理和特点;最后结合实验和测试中的实际问题对音频检索进行展望.
信息检索;音频识别;音频片段;声纹
信息检索技术从人工检索和计算机辅助检索发展到当前网络检索和智能检索,检索对象涵盖文本、图像、视频、声音、乐谱、DNA序列等[1]结构化数据和非结构化数据.原先的数据对象基本稳定而封闭,由独立数据库集中管理,而现在的数据呈现出基于web、海量的、复杂的结构,且具有极强的开放性、动态性和分布式特点.移动互联网和社交网络的发展大大推动了数字化媒体技术的应用,从海量信息资源中获取有用音频成为人们的基本需求.在线音乐和语音数据呈爆炸式增长,给用户提供了丰富而灵活的选择空间.人们对娱乐文化的个性化便捷化追求,也使移动音频检索成为信息处理、多媒体和音乐艺术等领域的研究热点.
音频识别涉及信号处理、语言学、声学、音乐学、机器学习、人工智能、模式识别、计算机算法等学科,语音识别应用于语音拨号、语音导航、设备控制、语音文档检索、听写录入等[2].与自然语言处理相结合可衍生出更复杂的应用,如机器翻译和语音合成技术结合实现语音到语音的翻译.随着语音处理技术日趋成熟,国内外专业人士和研究机构做出大量贡献,成功研发出各具特色的音频识别检索系统.midomi.com网站、手机微信的摇歌摇电视等都成为广受欢迎的检索工具,对音频片段进行快速检索和精确识别.
1 音频信号
声音是物体振动产生的一种波,具有振幅、频率、相位等物理特性,传播到电子设备形成音频信号.音频包括静音、语音、音乐、歌声、环境音等,音频信息是时间序列数据流,广泛用于媒体行业信息处理、检索和分类.音频帧具有短时稳定、长时可变的特性,但由于时间粒度太小很难提取出有意义的特征,所以需要定义粒度更大的结构单元,即音频片段,如过门、间奏、首句、高峰句、结束句、念唱、简谱等.
1.1 音频的三类特征
根据不同的特征空间,音频分为时域、频域和时频特征[3].时域特征包括短时平均能量、静音比、过零率和线性预测系数等,可从原始音频信号上直接提取.频域特征是将原始信号傅立叶变换到频域后提取的一系列特征,如带宽、频谱中心、谐音、音调、倒谱系数等.时频特征反映时间域和频率域的联合分布,描述信号在不同时间和频率的能量密度或强度.
1.2 音乐的特征与类别
音乐具有物理属性和文本属性,物理属性如韵律、幅度、频率等,文本属性如歌名、歌词、演唱者、作词、作曲、专辑等.每个音乐都有音高、音长、速度、音量等基本特征.音乐包括无歌词纯乐器音乐、民族歌曲、流行歌曲、摇滚乐、戏曲等类别,其中乐器音乐分打击乐、弹奏乐、管弦乐等,我国戏曲包括京剧、豫剧、晋剧、川剧、越剧、黄梅戏、昆曲等种类.音乐的存取格式主要有wav,wma,avi,mp3,mid等.
1.3 语音识别技术
语音信号处理广泛用于便携式和嵌入式智能化设备语音模块,一些非实时和实时的识别系统已被开发和使用,改变着人机界面和交互方式,如PC机听写输入、语言对比学习软件、数码设备、声控玩具和智能仪器等[4].语音识别利用数字信号处理技术自动提取人类语音中的词汇内容并转换为计算机可读的输入,如按键、二进制编码或字符序列[5].
语音识别分为语音训练、特征识别、失真测度三个阶段.1)语音训练:预先分析语音的特征参数,制作语音模板并存放在语音参数库中;2)特征识别:语音经训练分析得到语音参数,与库中参考模板逐个比较,找出最接近的模板作为识别结果;3)失真测度:进行语音比较时需遵循特定的标准,即计量语音特征参数矢量之间的失真测度.
当前语音识别的研究热点有大词汇量、非特定人连续语音识别,研究策略由传统的基于标准模板匹配转向基于统计概率模型研究,技术日趋成熟.语音识别的最大突破是HMM和人工神经网络的应用.
2 音频检索系统
多媒体检索是ECIR、ACM SIGIR和ICMR国际会议的重要内容,专业研究机构已推出一些音乐检索系统,使用户通过清唱、哼唱、弹奏、播放等方式输入音频片段进行识别和检索[6].
音频检索系统由检索界面、音调跟踪、特征库生成和检索引擎模块构成.每个系统都有各自的资源库,数量上百万且规模不断扩展.与指纹识别相似,不同歌曲声纹各异,搜索算法从茫茫歌海中即时搜索和比对,最终与相似度高的音乐成功匹配.音频检索系统处理框架如图1所示.
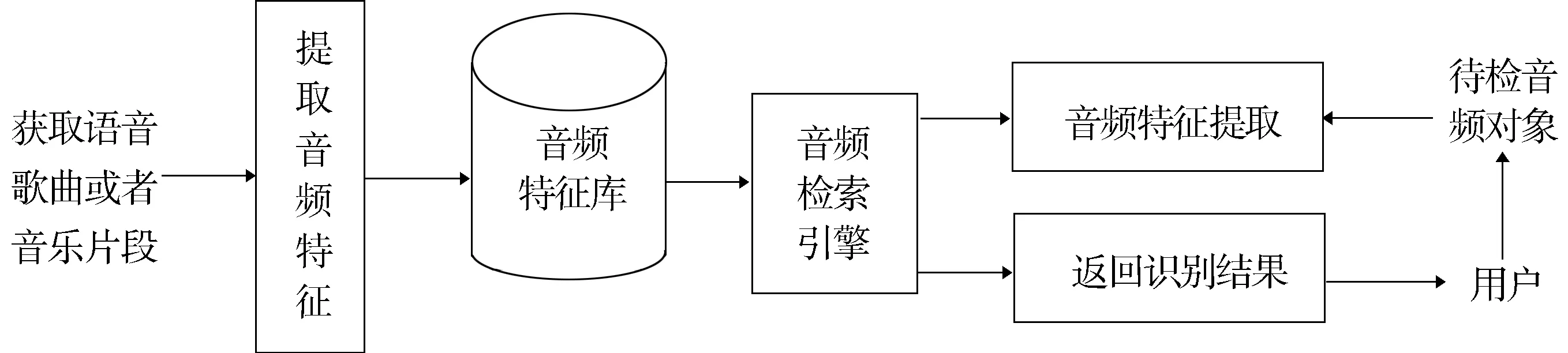
图1 音频检索系统的处理框架
2.1 音频搜索的关键问题
建立完整有效的音频检索系统需要考虑:如何表现旋律,即音频信号的预处理;如何构造音乐数据库并建立音频索引;如何提取旋律特征形成查询索引;如何构造用户查询实施匹配,根据查询索引和库中索引间的相似性对音频片段检索.
2.2 音频检索系统产品
音频检索研究和发展更加成熟,产品应用日趋丰富,创新和突破仍在继续.表1列出几种音频检索系统,其中我国的ARS系统拥有庞大的原始音频库,包含语音、音乐、笑声、铃声、动物声等不同类别[7].

表1 几种成熟的音频检索系统
2.3 音频检索引擎
文本检索根据关键字列表组成的查询对文档进行定位和匹配,把相关度高的文档反馈给用户.传统的音乐搜索通过匹配歌名、歌词、专辑、作者、歌手、流派等文本内容而返回查询结果,其本质也是文本搜索,如Google、百度MP3、酷我音乐盒等音乐搜索引擎,pandora.com和last.fm等音乐共享网站.亦歌(1g1g)等在线播放器甚至能根据用户历史记录、行为反应和变化分析其偏好与口味,进行个性化音乐推荐.但这些产品对媒体设备播放或演奏的音乐、哼唱的歌曲或戏曲片段难以识别.
真正的音乐搜索引擎是用音乐片段来搜索音乐,对于不知名称和出处的音乐或旋律,过播放、哼唱、吹口哨,或借助麦克风、键盘和乐器操作获得相应曲目,支持原唱和翻唱识别,即使音调不准、五音不全、不擅唱歌的用户,系统也可在一定时间内有效识别.表2对几种典型商业化音频检索引擎进行对比.

表2 典型的商业化音频检索引擎
2.4 音频检索系统的应用
音频检索技术的发展和成熟催生了移动终端、广电传媒、文化生活等方面的应用和服务.
2.4.1 移动音乐检索
移动通信和无线网络的普及推动了音乐检索的发展和应用.如手机微信的“摇歌曲”就是一款典型的新兴应用,操作简单便捷.1)打开微信:微信4.5以上版本具有此项功能;2)开启应用:在“摇一摇”功能中选择“歌曲”项;3)播放音乐:用电脑、电视、手机、播放器或收音机等设备播放待识别音乐;4)搜索和识别:应用程序自动调用接收的信号,摇动手机时触动传感器,声音信号发给微信程序,与服务器中庞大的歌曲数据库进行比较和匹配;5)识别成功:应用程序将搜索到的相似度最高的歌曲反馈至用户手机,实时显示歌名、歌词、作者等信息并后台同步播放.用户核对无误后可继续进行收藏或分享操作.
2.4.2 广电行业
音频检索是多媒体检索的热点,也是广电行业应用研究的热点.音频检索系统在各级广播电台开始尝试和推广,市场空间较大.构建音频资料存储系统并实现高效管理成为重要工作和关键技术.音频可用文本标注,语音可转换为相应文本,电视台和广播电台利用语音识别能快速得到新闻和记录片等相关语言节目的文本稿件,高效快捷.
电视直播第二屏互动技术也已成熟和推广,像微信摇一摇电视功能可在三四米距离用手机录制电视直播,实时识别当前频道.其原理也是基于音频识别和匹配,服务器实时将电视直播流的声音转换成音频指纹,当用户摇动时把手机麦克风收到的声音与直播流的声纹进行匹配.Syntec TV、Shazam及MusicRadar音乐雷达都在应用这一技术.
2.4.3 娱乐服务
以前的KTV点歌系统只可通过歌名、歌手等文本信息查询,而增加音频检索功能后,用户通过手机播放或随机哼唱片段都可自动选歌.此外,利用音频检索系统,音乐培训教育机构的视唱教学模式也将发生改变,比如通过多次试唱和跟唱来校验音准、核对词曲.在学校和社区还可开展点歌、猜歌、影视配音、娱乐竞赛多种形式的综艺活动.
2.4.4 声纹鉴定
声纹是电声学仪器显示的带有语言信息的声波频谱,与指纹和虹膜一样是每个人相对稳定的特征.故意模拟或改变声音、语气和音量,其声纹也基本不变.在刑事案件中通过声纹鉴定技术进行对比检验,可有效分辨嫌疑人年龄、性别、方言、情绪,审查录音等证据的真伪,提高案件侦破效率.
3 音频检索方法
国内外专业机构对音频检索尤其是音乐检索进行深入研究,提出不同的建库方式、旋律表示、查询方式和匹配方式.在检索时利用音调、音强、过零率等特征,基于不同算法将音频文件聚类形成参数库.系统对原始音频库进行特征处理,形成特征数据库,利用基本属性、特征值、例子视频[8]等进行检索.
3.1 音频检索过程
音频检索的基本步骤为预处理、特征提取、音频分割、识别匹配、音频检索.
3.1.1 音频预处理
音频检索的对象是语音、音乐及风雨声、笑声、掌声、爆炸等丰富的声音数据.预处理即先获取原始信号,加强或减弱不同部分,检测音符序列和语音信号,进行滤波、去噪、预加重、加窗、分帧等处理,为特征提取、识别匹配和音频检索做准备.
3.1.2 音频特征提取
特征提取是音频检索的关键任务,是音频分割、识别和分类的基础.首先对待识别音频数据加窗处理形成帧,加窗大约数微秒,重叠移动形成多帧,邻帧叠加30-50%;再对每帧作快速傅里叶变换得到傅里叶系数和频域能量;然后计算帧特征和标准偏差、数学期望、方差;最后将帧特征推广为片段特征.
1)基音检测与提取 基音检测即基于基音的声学特征进行识别.目前主流技术包括时域自相关法、频域倒谱法、时频结合的小波变换分析法及相关衍生算法,对加窗分帧后查询片段中的每帧数据提取基音,即得到代表音调变化的基音序列[9].
2)音高提取算法 音高是音乐的重要属性.提取算法主要有最大似然、自相关算法及基于生理声学的音高检测[9].
3.1.3 音频识别匹配
根据音乐特征,利用最邻近准则和Mahalanobis距离设计音频分类器,将数据划分为乐器声、男声、女声、掌声、噪音等类别.主要的匹配算法有HMM和DTW,主要运算有递归、求最短编辑距离、计算最长公共子序列、统计子串在长串中的频次等.通过音乐相似度计算和优先级排序实现音乐查询.利用Cool Editor、GoldWave等软件进行音频录制、片段截取、语音分析、格式转换,便于仿真读取、检索和调用音频数据,用Matlab分帧和编制滤波函数,检测语音端点平均能量和过零率,验证检测准确度.
3.1.4 音频检索
自动语音识别技术可以识别音频流中的词语,甚至自动定位到人,使检索达到语义级;音乐检索利用音符和旋律特性,计算特征矢量间的欧几里德距离或Manhattan距离作为近似度指标以返回最优检索结果.
3.2 音乐检索方法
主要有基于符号注释、基于内容、基于旋律、基于情感分析等方法,大部分基于音乐基本属性进行特征匹配,当前研究较多的是情感分析.
3.2.1 基于符号注释的音乐检索
最原始的音频检索是基于人工输入的音乐符号和标注的属性描述,缺点是当数据规模很大时人工注释强度增加,且标注符号无法表达清楚用户对音频旋律、音调和音质等感知.这恰是基于内容音频检索需解决的问题.
3.2.2 基于旋律的音乐检索
包括基于绝对音高序列和相对音高序列[10]两种方法,表3对二者做简单对照.UDS方法中的U表示音调较之前升高,D表示音调降低,S代表音调不变.

表3 基于音乐旋律的检索方法
3.2.3 基于内容的音频检索
音频的内容分为物理样本级、声学特征级和语义级三个级别[11].如表4所示.

表4 音频内容的三个等级
基于内容的音频检索常在声学特征级和语义级进行,基于内容本身认定乐曲,不依赖于标注信息.原始音频数据除采样频率、量化比特、编码方法等信息外,仅仅是一种非语义表示的非结构化二进制码流,缺乏对内容语义的描述,音频检索受限,同时它是一种相似性检索,无法实现精确匹配检索.
3.2.4 基于情感分析的音频检索
语义信息作为音频内容的最高级抽象形式,可被人们直接理解和交流,其中情感语义是表达音乐最本质的特性,基于情感的音乐内容分析和合成研究是计算机音乐研究的重要部分.通过音乐情感分析和情感建模对数据集中音乐情感信息进行人工标注,但音乐语料往往短小、稀疏、含蓄,需用聚类方法建立情感分类器对音乐进行识别[12].
3.3 音频识别方法
音频识别的典型方法有高斯混合模型(GMM)、隐马尔可夫模型(HMM)、支持向量机(SVM)、动态时间归整(DTW)等.下面介绍孤立词、连续多句和带噪音的片段识别方法.
3.3.1 孤立词语音识别
孤立词的语音识别方法很种,各具优缺点和应用场景.
1)动态规划法 其原理和算法简单,易于实现,识别率较高,但运算量很大.失真测度用欧氏距离或对数似然比距离,决策方法可用最近邻域准则.
2)矢量量化法 既可用于语音通信中波形或参数压缩,也可用于语音识别.经典的有限状态矢量量化方法对语音识别更有效,决策方法可用最小平均失真准则.
3)HMM法 这是一种用参数表示描述随机过程统计特性的概率模型,参数可用离散概率分布函数或连续概率密度函数,决策方法用最大后验概率准则.HMM模型可视为有限状态自动机,仅各时刻的输出值对外界可见,其内部状态对外不可见,音频识别系统的输出值是计算各帧所得的声学特征.离散HMM对特征空间的描述误差较大不够精确,因此在连续语音识别中使用连续HMM.相同条件下HMM与DTW识别效果相近,但训练阶段需提供大量语音数据,经反复计算得到参数模型,因此稍复杂一些.
4)DTW算法 基于动态规划解决发音长短不一的模板匹配,是典型的优化问题.用满足一定条件的时间规整函数描述输入模板和参考模板时间的对应关系,计算两矢量匹配时累积距离最小所对应的规整函数,以寻求最优匹配路径.此算法简单有效,训练过程不需额外计算,应用广泛,但在解决大词汇量、连续语音、非特定人语音识别问题时比HMM差一些.
5)混合方法 将上面多种技术恰当结合形成混合方法进行应用,比如首先用矢量量化作为第一级识别,通过预处理得出候选结果,然后用DTW或HMM进一步识别.
3.3.2 连续多句音频识别
音频数据库中的特征提取以句为单位,所以当连续播放或哼唱多句时,特征之间应增加独立的特征值,通过检测前后音符的音乐差来识别片段轮廓.但哼唱不准时可能出现多个不同的特征值,检测质量受到影响.在这种出现插入删除错误的情形下,用DTW进行位置匹配和相似度计算,可得最合适的匹配子序列和最大相似度,实现多句哼唱的目标检索[13].
3.3.3 带噪音片段的语音识别
带噪音音频片段的特征点个数比无噪音的原始片段少,在强噪音环境下产生的特征也会导致片段的特征数增加,检索速度随平均特征数的增加而减慢.对在办公室、卧室等无噪音环境录制音频片段的识别率可达100%,而在有说话、鸟鸣、喇叭、空调、电视等噪音较大的环境下识别率偏低,且噪音特征的数量还直接影响检索速度.噪音环境下的语音识别方法有线性预测误差法、单边自相关线性预测法、语音前端声学处理法、特征综合法等[14].
3.4 音频检索中的问题
影响音频检索质量的因素较多,比如声源离识别设备的距离、环境噪音和“野点”、冗余片段、发声障碍、单调不准、旋律误差、片段间隔、二次匹配等问题.
1)噪音片段识别.有较大噪音干扰时,检测效果不佳,有时会出现误检.因此在噪音环境中如何实时获取相对准确的音符是一个关键问题.
2)端点检测和基音提取.音频片段中包括由浊音或过渡段构成的语音部分、清音或噪声构成的无声部分.基音检测包括声音信号预处理、浊音段端点检测和基音提取[15].通过预处理滤掉高频部分噪音,将随机语音信号分帧为短时平稳信号,然后进行端点检测,提取出浊音段.端点检测通过短时能量检测和过零率进行.
3)识别误差处理.旋律和节奏相似的片段在噪音环境或信号不清晰时会造成特征识别与匹配误差导致出错.存在相似度的歌曲对如生日快乐歌-新年快乐歌、字母歌-幼儿歌曲小星星、月亮之上-自由飞翔、国歌-国际歌起始部分.用k近邻法对音乐家或流派分类,在训练集中找出与待检对象相似度最高的k个邻居,根据属性投票,获得最多投票的属性赋予该对象.
4 音频检索实验与检测
音频检索性能的检测需要数量庞大资源丰富的音频数据库,分布合理的受测人员和曲目,对不同风格和流派、不同距离和环境、不同长度和片段进行测试,分析检索效率和精度.
4.1 音频检索数据及环境
音频数据库:从光盘和网站获取500首不同风格、语言、歌手的wav格式歌曲;
测试数据源:一组歌曲20首,每首选取5段5~20 s长的不同片段;另一组歌曲10首,对纯音效和带不同程度噪音效果的片段进行测试.
实验配置:编程平台Matlab7,辅助软件GUITAR PRO,采样频率8000 Hz,帧长30ms,帧移25ms.为验证哼唱旋律提取算法的性能,可用GUITAR PRO软件制作音乐片段,模拟乐器输入音符,生成MIDI序列.其生成标准的7个基本音阶的音乐旋律wav文件,对干净音乐波形文件采用传统自相关法进行基音提取,得到平滑的基音轨迹.
4.2 哼唱片段识别测试
选择测试对象:一定数量的曲目和哼唱测试者,如50名志愿者和50首歌曲;
测试方法:合理设置男女比例和成人儿童比例,每人每次随机哼唱音频数据库中的一首歌曲,允许反复,可用La,Da或Di单音哼唱.系统提取基音轮廓,根据频率和音高转换方法把基音值转化为MIDI格式音高.
测试目标:把所得哼唱旋律音高结果与歌曲数据库中MIDI格式音高的序列进行音高差匹配计算,统计出命中率最高的前3个或5个.
4.3 音乐检索效果评测
数据统计:歌曲总时长、纯音乐片段总时长、语音-音乐混合片段总时长;
计算指标:正确率=检测正确的音频片段数/待识别音频片段总数.
对音乐信号分帧,提取短时能量和过零率,以1或2秒为一个音频段,提取音乐片段中的平均短时能量和过零率标准差特征进行识别,对结果进行平滑处理,对比识别结果会发现,总体正确率获得10%左右的提升.可见平滑处理显著提高音频识别正确率.
实验检测显示,专业歌手比业余人员演唱的歌曲容易识别,打击类音乐节奏明显故检测效果较好,噪音较小的环境中音频识别率高,过短和过长片段的识别都不佳,因为过短不利于提取旋律特征,太长又会造成特征匹配度不高.
5 音频检索技术展望
音频识别和检索发展迅速,应用广泛.在音乐学中可用于乐器鉴定、音乐摘要、音乐标注、录音旋律提取,在医疗上根据音频相似性匹配技术辨别心音,及早发现心脏病变,在刑事案件中通过辨别嫌疑人的声音来帮助侦破,提高工作效率.但是,由于音乐信号的复杂性和多变性,识别精度、性能和效果仍有待提高.
主要问题和瓶颈有:机器识别率低于人耳听觉敏感度,音乐中单音符识别精度有时不高;一些检索系统所占时空资源消耗大,需提高算法效率;语音-音乐混合片段辨识度低;数据资源越来越多,识别率有时反趋下降;对变调和配乐哼唱等特殊音频不能较好识别.在今后的研究中还要考虑检索精度、用户接口、系统的自适应性和鲁棒性等问题.
此外,将神经网络引入语音识别,并将音频、文本和视频检索等多媒体技术相结合,利用标签云、标签超图、标签聚类等方式分类,可提高检索效率与检索能力,并应用于更多的领域和场景.
[1] David A.Grossman,Ophir Frieder.信息检索:算法与启发式方法[M].北京:人民邮电出版社,2010
[2] 郝志伟.汉语大词汇量连续语音识别系统的声学建模[D].长春:吉林大学,2009
[3] 唐 峰,刘玉贵.广播电台音频检索技术研究[J].计算机应用,2007(6):364-366
[4] 史水平,李世作.线性预测编码(LPC)技术及其在音频文件上的应用[J].现代电子技术,2004(4):21-23
[5] 胡 优.语音识别算法及其在嵌入式中的应用[D].北京:电子科技大学,2010
[6] 承江红.基于MATLAB的语音信号识别及矢量模式匹配[J].微计算机信息,2012,28(10):443-445
[7] 王小凤,耿国华,孙 霞,等.一个以句为单位的音乐哼唱检索算法[J].西安:第五届和谐人机环境联合学术会议,2009
[8] 白云晖.基于内容的音频检索[J].广播与电视技术,2007(6):30-36
[9] 庄越挺.通过例子视频进行视频检索的新方法[J].计算机学报,2000,23(3):300-305
[10] 刘 林.自动音乐识谱系统中的音符检测与流派分类[D].北京:电子科技大学,2008
[11] 李 晨,周明全.音频检索技术研究[J].计算机技术与发展,2008,18(8):215-218
[12] 庄越挺,潘云鹤.网上等多媒体信息分析与检索[M].北京:清华大学出版社,2002
[13] 王小凤,耿国华.基于相对特征的音乐哼唱多句检索算法研究[J].计算机应用研究,2011,28(3):918-920
[14] 吴淑珍,冯成林.噪声环境下语音识别方法研究[J].北京大学学报,2001,37(3):365-369
[15] 蒋永平,卢传泽.有效的哼唱旋律基音提取方法研究与实现[J].计算机工程与应用,2014,50(3):215-220
Audio-clip Recognition and Retrieval Based on Content and Melody
Wu Haixia1,Li Yanling1,Liu Lufeng2
(1.Department of Computer Science,Changzhi University;2.Changzhi Suburban Radio and Television Center, Changzhi 046011, China)
It introduces the fundamentals such as main features and technologies of the audio signals, gives the frame and productions of the audio retrieval systems, and also lists the typical retrieval engines and application fields. The main audio-clip recognition retrieval methods based on contents and rhythms are analyzed in detail. At last it prospects the development and applications of audio retrieval according to the problems in testing.
information retrieval;audio recognition; audio-clip; voiceprint
2015-02-01
山西省高校科技创新项目(2013160); 长治学院校级科研课题(201223).
吴海霞(1978-),女,山西晋城人,硕士,长治学院讲师,主要从事数据挖掘和信息处理研究.
1672-2027(2015)02-0033-07
TP391
A
