C语言软件错误定位的测试用例库构建
2015-03-03王瑾
王 瑾
(北京航空航天大学 计算机学院,北京 100191)
C语言软件错误定位的测试用例库构建
王 瑾
(北京航空航天大学 计算机学院,北京 100191)
文章主要开发一个用于软件错误定位的测试用例库.该测试用例库具有标准化、复用性、版本管理和统一管理这几个特性,构建过程首先是确立了分类的标准,这里采用了三级分类的模式进行管理,通过分类产生了树形管理结构.然后对测试用例中的源代码文件进行了编码以及说明标签的填写,从而生成标准化的测试用例,不断完善测试用例库.同时,根据系统的更新对测试用例进行修改和维护,保持测试用例库的版本与当前系统版本的一致性.
C语言软件;错误定位;测试用例库
1 设计需求
传统人工调试工具,譬如GDB和DBX提供基于主控台的命令提示接口,而其他调试器前端应用普遍是提供给集成式开发工具(IDE)作为调试引擎,具有动态化、可视化等特点,但它们是命令行式工具,没有图形界面,不方便用户使用.Visual Studio 调试器是一个功能强大的工具,能够观察程序的运行时行为并确定逻辑错误的位置,该调试器可用于所有的 Visual Studio 编程语言及其关联的库,但它仅实现了传统的断点调试等功能,依然在很大程度上依赖人工调试.WinDbg是在windows平台下,强大的用户态和内核态调试工具,但是它的大多数调试功能还是以手工输入命令的方式来工作的.Eclipse CDT 作为Eclipse的面向C和C++语言的插件,它的存在使得Eclipse 可以完成许多C/C++ IDE一样的功能,但它主要是在Eclipse功能上进行了C/C++语言程序调试的改进,依赖于Eclipse调试模式.KDevelop是一款功能强大的集成开发环境应用程序.它的研发最初是为了给KDE提供一个便于使用的集成开发环境,但它并不支持跨平台,并且易用性不强.另外,目前(半)自动化调试工具采用的错误定位技术可以划分为轻量级和重量级错误定位两大类.轻量级错误定位通常是对测试的覆盖信息或者执行轨迹进行收集并分析,算法一般会在此基础上采用统计方法或数据挖掘等方法进行数据信息处理,代表工具有Tarantula,SOBER和Crosstab等等.重量级错误定位主要是对程序依赖关系分析,这里依赖关系主要指数据依赖和控制依赖,其代表技术为程序切片.此外还有关注错误修复的调试工具,BugFix[10]和PACHIKA[11]都是其中的代表.但是在实际的软件开发中自动化调试的应用技术仍旧不成熟,这是因为调试任务自身都具有其复杂性和特殊性,所以针对不同的调试任务想要寻找一种通用的调试方法是一件比较困难的事情.此外,在调试任务中,错误语句的定位结果往往具有不唯一性,因此调试方法需要对其定位结果具有较强的解释能力.此外,如何提高定位结果的可靠性和精确度,这也是目前自动化程序调试领域热点的研究问题.我们课题组正在研究和构建一个有机高效的软件测试、调试和验证环境,基本完成了面向C语言的半自动化调试系统的实现.而本文主要研究软件错误定位的测试用例库,测试用例的设计与编码,主要是为了检查程序执行的正确性和验证执行结果,进行对于测试程序的源代码的编码,用户反馈信息的输入设计,以及预期的定位结果等等的集合.测试用例库的构建使得软件错误定位的测试变得更加条理化和专业化.虽然在构建测试用例库的过程中,该库的设计需要耗费一定的成本,但是考虑到测试用例库的可重复性很高,这样可以极大地减少测试人员花费大量时间进行重复设计的成本,降低在系统开发过程中的各个测试活动的成本,缩短软件测试的生命周期,提高测试的效率,因此构建测试用例库是值得研究和开发的.
对于错误定位系统,软件的测试用例经常涉及到多重循环和复杂结构嵌套,不同的结构不同的执行路径都会产生不同的测试用例,并且对于每个测试的源代码程序,“错误”的设计不同也会形成类型不同的测试用例,这些测试用例都是构成测试用例库的基础.
在构建测试用例库的初始阶段,是对测试用例库的需求进行相应的分析,得到测试用例库在设计和实现的时候所要遵循和实现的几点要求.
1.1 标准化
要建立标准化的测试用例库,则需要对于每个测试用例都要求测试用例的内容完整性.测试程序的源代码程序需要根据本系统所定义的C语言核心子集的规则,进行编写,测试用例中不可出现规则以外的语言.
测试用例的编写以及描述需要规范化,也即测试用例要有标准格式.每个测试用例需要有源代码程序和说明标签.说明标签的内容主要有测试用例的编号、测试名称、测试功能,测试标题、测试级别、前置条件、测试输入、操作步骤、预期结果等.
测试用例编号:主要是由数字组成,这里编号具有唯一性,易识别性.
测试名称:主要是对该测试用例的简单描述.用概括性的语言来描述该测试用例的测试点.
测试功能:主要是这个测试用例所测试的系统的功能模块名称.
测试级别:主要是根据测试的重要性划分几个等级,测试级别则表示该测试用例的重要程度属于哪个级别.通常会分为三个等级,即高、中、低三个等级.高等级是指保证系统的基本功能的正确实现、系统特性的显示的测试用例,通常使用频率较高,测试的功能模块也是系统的核心.低等级是指对系统的关键功能影响不大的测试用例,通常使用频率也较低.中等级是重要程度介于高等级和低等级之间的测试用例.
前置条件:是执行该测试用例的前提条件,如果不满足这些条件,则无法进行测试.
测试输入:主要是测试用例执行时,需要输入的数据信息.
测试步骤:是测试用例在执行过程中所需的操作步骤,这里需要给出测试操作每一步的具体描述,使得测试人员并不需要对系统的实现方法进行了解即可进行测试工作,完成测试.
预期结果:对测试用例的执行结果进行预期,得到预期结果,可用来与实际执行结果对比,如果结果一致,则测试用例通过,如果不一致则测试用例失败.
1.2 复用性
对于测试用例库而言,测试用例的复用性可以在日后的测试工作中节约大量成本,测试工作人员不必耗费精力编写相似的测试,因此复用性对于测试用例库而言显得尤为重要.
1.3 版本管理
测试用例库通过不断地维护,对于测试用例可能会出现多个版本,对其进行版本管理也是测试用例库在设计过程中需要考虑的一点.并且系统在研发过程中可能会出现版本更替,如何将测试用例的版本与当前系统版本一致,根据系统的新版本,如何修改或者创建新的测试用例,也都是测试用例库构建的重点.
1.4 统一管理
系统构建测试用例库,而不是简简单单设计几个测试用例,就是系统对于测试用例的组织化的需求,系统需求一个系统性的有组织的测试用例库,从而能够达到对系统的各个功能模块的覆盖,减少重复性测试,扩展测试的覆盖范围.针对系统的不同的功能模块,不同的测试阶段,测试用例所实现的目的有所不同,这需要不同的测试用例来对其进行测试,而大量的测试用例需要有组织性的管理.通常测试用例库都是采用树形化结构管理,这种方式对于测试工作来说结构清晰易于管理.
系统对于测试用例库的构件会根据上述几点用例库的要求来进行设计和维护,形成系统化有组织结构的错误定位的测试用例库,提供各种测试用例来完成本系统的测试工作,提高测试的效率.
2 测试用例库构建
测试用例库在设计的时候主要针对本自动化调试系统进行分析设计,编写具有一定针对性的测试用例.考虑到测试用例库的组织结构,这里采用树形结构化管理,因此需要多级分类.
2.1 分类标准
首先,本测试用例库主要采用了三级分类的形式来进行测试用例的设计,然后确定三级分类的标准.本系统的基础部分也就是程序解析部分,定义了C语言的核心子集,系统主要是针对该核心子集进行功能实现,因此测试用例的源代码所包含的数据类型作为第一级分类.
而包含相同数据类型的源代码程序由于程序的语法结构的不同,也会产生多种不同的测试用例,因此在一级分类下根据程序的语法结构不同进行分类,作为二级分类标准.
考虑到错误定位是本系统所实现的最核心的功能,因此系统首要考虑的就是所需要定位出的错误是哪种类型,本系统所采用的错误定位算法是否能够检测出这类错误.因此错误类型的分类作为第三级分类标准.
2.2 树形管理结构
根据上一小节的三级分类标准,对每一个分类标准都进行类别选择,通过三级分类类别选择,则可以形成测试用例库的树形管理结构.
首先,根据分类标准进行每一级的类别选择.根据第一级的分类标准,针对源代码包含的数据类型的不同进行分类,可以分为int-tests(1)array-tests(2)pointer-tests(3)struct-tests(4)等等;根据第二级的分类标准,针对源代码程序的语法结构的不同进行分类,可以分为assgin-tests(1)if-else-tests(2)for-tests(3)while-tests(4)switch-tests(5)nest-tests(6)等,这里的数据结构主要是以源代码程序中包含的复杂度比较高的语法结构进行归类;根据第三级的分类标准,针对错误类型的不同进行分类,这里考虑到现阶段系统主要采用的是形式化的错误定位算法,该算法主要在定位赋值语句错误以及条件表达式错误等情况下效果良好,可以分为assginerror-tests(1)和conditionerror-tests(2)等.对于具体的测试用例,其编号为三位数字,每一位数字分别代表了第一级类别、第二级类别、第三级类别属性,比如某个测试用例的编号为2421,则它属于array-tests里for-tests中的assginerror-tests类里第一个测试用例,因此它的源代码程序是包含数组类型的,语法结构包含while循环语句的程序,并且它是用来测试对条件表达式错误定位的测试用例.
2.3 测试用例设计
根据测试用例库的管理结构,针对第三级下的每个类别,可以进行其测试用例的设计和编码,需要符合这个测试用例所在的三级分类各级的类别属性.比如说对于编号2421的测试用例源代码的编写,考虑其源代码的特性是包含数组类型的,语法结构包含while循环语句的程序.因此可以进行如下编码(这里以一个简单的源代码程序举例)以及其说明标签.
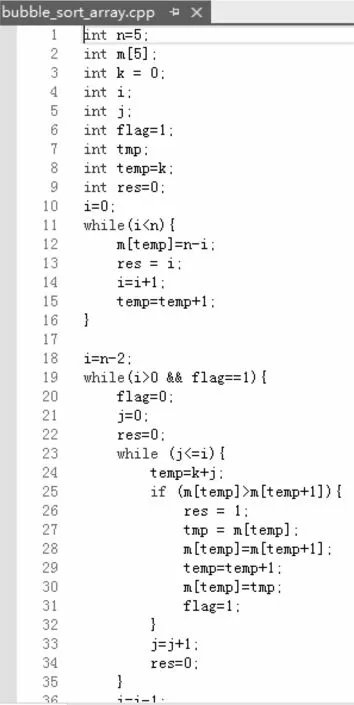
图1 1源代码编码
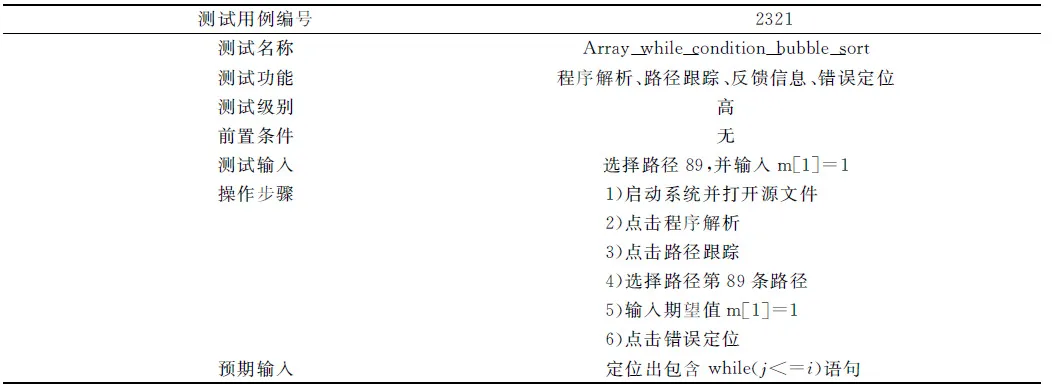
表1 说明标签填写
如此根据分类类别,来进行源代码的编码,以及说明标签的填写.本测试用例库中相对简单的程序均为自动手动编写,有较多复杂结构的测试源程序是由西门子测试用例集中的测试用例改编而来,将其结构修改为本系统所支持的数据类型及程序结构,从而形成系统的测试用例库,这个过程花费了大量的时间,但是为之后系统的各个功能测试奠定了基础.
3 测试用例库维护
一个软件系统在研发的过程中,会经过多个版本的更替,系统会不断地进行改动,功能或者模块均可能产生变化,而随着这些改变,很多测试用例可能会失去其针对性和有效性,而有些测试用例会产生不同的执行结果,对结果分析也会有相应的影响,这就需要不断地对测试用例库进行维护,来保证测试用例库功能的完善以及测试结果的准确性.根据系统的改动,对于新增加的功能编写相应的测试用例,如果已有的测试用例与新增加的功能有所关联,则相应的修改已有的测试用例.
随着系统的不断完善,测试用例的不断增加,可能会不断出现新的分类类别,这原有的三级分类的基础上分别进行补充,使得测试用例库的规模逐渐扩大,逐步形成系统级的测试用例库.
4 总结
本文主要对系统的测试用例库的构建进行了详细阐述.第一小节主要是对测试用例库构建的需求,主要是要求测试用例库具有标准化、复用性、版本管理和统一管理这几个特性,因此在设计和构建测试用例库的过程中都需要遵循这些要求.第二小节主要就是描述了测试用例库构建的过程,首先是确立了分类的标准,这里采用了三级分类的模式进行管理,通过分类产生了树形管理结构.然后对测试用例中的源代码文件进行了编码以及说明标签的填写,从而生成标准化的测试用例,不断完善测试用例库.第三小节描述了跟据系统的更新对测试用例进行修改和维护,保持测试用例库的版本与当前系统版本的一致性.
[1] STALLMAN R,PESCH R,SHEBS S.Debugging with gdb-the gnu source-level debugger.GNU Press,2006
[2] LINTON M A.The Evolution of Dbx//In:Proceedings of the Summer USENIX Conference,1990,6:211-220
[3] DEBUGGER M V S.Microsoft Visual Studio Debugger.Network Dictionary,2007
[4] 车叔平.基于Eclipse的嵌入式开发平台的研究与实现.成都:电子科技大学,2007
[5] 王 倩.基于Android端到端实时无线视频传输系统.南京:南京邮电大学,2013
[6] NOLDEN R.Developing C/C++Applications with the KDEvelop IDE.Linux Journal,2002,95:11-15
[7] 贺 韬,王欣明,周晓聪,等.一种基于程序变异的软件错误定位技术.计算机学报,2013(11):2236-2244
[8] LIU C,YAN X,FEI L,et al.SOBER:statistical model-based bug localization.Sigsoft Softw.eng.notes,2005,30(5):286-295
[9] WONG W E,WEI T,QI Y,et al.A Crosstab-based Statistical Method for Effective Fault Localization//Software Testing,Verification,and Validation,2008 1st International Conference on.IEEE,2008:42-51
[10] JEFFREY D,FENG M,GUPTA N,et al.BugFix:a learning-based tool to assist developers in fixing bugs//Program Comprehension,2009.ICPC'09.IEEE 17th International Conference on.IEEE,2009:70-79
[11] DALLMEIER V,LINDIG C,ZELLER A.Lightweight defect localization for java..Lecture Notes in Computer Science,2005,3586:528-550
Test Case Library Building for Wrong Positioning of C Language Software
WANG Jin
(School of Computer and Engineering, Beihang University, Beijing 100191, China)
This paper mainly studies and develops a test case library for wrong positioning. It is some characteristics of standardization, reusability, version management and unified management, the building process includes two stages, the first stage decides the criterion which adopts three-level classification model and produces the three management structure by the three-level classification mode, the second stage encodes the source code file in the test case library to generate the standardized the cases and improve the test case library. Meanwhile, to modify and maintain the library according to system updating maintains the test case library version the consistency with the current system.
C language software; wrong positioning;test case library
2015-10-14
王 瑾(1991-),女,山西太原人,北京航空航天大学在读研究生,主要从事软件理论研究.
1672-2027(2015)04-0058-05
TP391
A
