实时声源定位算法研究与实现*
2015-02-28姜志鹏唐加能梁瑞宇
姜志鹏,唐加能,梁瑞宇
(1.金陵科技学院电子信息工程学院,南京 211169;2.华侨大学工学院,福建泉州 362021;3.南京工程学院通信工程学院,南京 211167)
声源定位技术在基于麦克风阵列的语音信号处理中处于核心地位,其不但可以提供位置信息,而且对基于麦克风阵列的语音增强技术具有重要的作用。此外,利用声源定位技术,还可以改善基本的盲源分离技术在声音混迭的环境的性能,解决语音信号的重构问题,显著改善恢复的语音信号的质量。基于麦克风阵列的声源定位技术已经成为一大研究热点,对其开展研究具有很强的理论意义和实践价值[1]。现有的大部分定位系统使用的算法的计算量较大,实时性较差,不能满足实时性要求高的场合。
基于麦克风阵列的声源定位技术主要有三类[2]:基于高分辨率谱估计技术[3-4]、基于可控波束形成技术[5-6]以及基于时延估计的定位技术[7-8]。基于高分辨率谱估计技术利用特征值分解将数据的协方差矩阵分解为噪声子空间和信号子空间,再找出与噪声子空间正交的方向矢量来获得声源的方向估计。该算法主要是针对窄带信号提出的,当声源信号为宽带信号时,需要将其分为多个子带信号,然后分别用高分辨率谱估计算法进行声源定位,最后根据得到的结果计算声源位置。该算法复杂度较大[9-10],很难应用于实时系统。基于可控波束形成的声源定位对麦克风接收到的信号进行滤波并加权求和来形成波束,进而通过搜索可能的声源位置来引导该波束,使波束输出功率最大的点就是声源的位置。该算法需要全局搜索,运算量很大,很难实时实现[11]。而采用的一些迭代方法虽然减少了运算量,但很难得到有效的全局峰值,并且对搜索初始值十分敏感。基于时延估计的声源定位方法是一种双步定位法[12]。该方法首先估计声源到达不同麦克风的时间差,再根据多个时间差通过几何关系得到声源位置。基于时延估计的声源定位算法运算量小,实时性好,对硬件要求不高。但该类算法不适用于多声源定位,而且在较强混响和噪声的环境中,很难获得精确的时延,从而导致后续的定位产生很大的误差。尽管如此,由于基于时延估计的定位算法易于应用于实时系统,而且在适当改进后,在一定的噪声和混响下也能有比较好的定位精度,被广泛地应用于各种定位系统。
针对目前声源定位算法的问题,本文提出一种基于变步长标准最小均方差VLMS(Variable Step Size Least Mean Square)算法。该算法利用VLMS算法自适应估计声源到麦克风的脉冲响应系数,进而估计出各麦克风之间时延,并利用几何方法定位声源在3D空间的位置。此外,本文设计了基于Cor⁃tex-A8嵌入式平台的声源定位系统,并进行了相应的硬件选型与调试及算法移植工作。实时实验显示,本系统的方案合理有效,能够较好的实现声源定位。
1 基于VLMS的时延估计算法
当声源相对于麦克风阵列运动时,时延也相应地变化,广义互相关法不再适用。为此,有专家提出基于LMS自适应滤波时延估计算法[13-14]。LMS自适应滤波时延估计算法基于LMS自适应噪声抵消系统,其原理如图1所示[15]。s(n-τ)相当于语音信号s(n)经过了一个相移滤波器hs(n),hs(n)峰值处的横坐标对应的就是信号间的时延。采用LMS自适应滤波器来估计时延,就是用一个自适应滤波器逼近hs(n)。通过加入与基本输入端时间延迟相等的时延,使两路信号最大程度的相似,最终由收敛的滤波器权矢量求得时延估值。
从图1中可以看出,声源信号s(n)经过相移滤波器hs(n)后输出n1(n),再与环境噪声n2(n)相加,得到输入信号x2(n)。第二路是s(n)与n1(n)相加得到输入信号x1(n)。自适应滤波器在自适应迭代过程中,逐步逼近相移滤波器hs(n)。当自适应滤波器收敛,x2(n)与y(n)的均方误差最小时,s(n-τ)与其估计s(n-)的相似程度最大。此时自适应滤波器的权失量wopt就是相移滤波器hs(n)的复制。由wopt最大值的横坐标,可得到时延估计。

图1 LMS自适应滤波时延估计原理图

LMS时延估计具体的算法如下:
这里,umax和umin是步长的最大值和最小值,ξ

2 声源定位
以四元十字阵为例,阵列分别由麦克风M1、M2、M3和M4组成,阵元间距为L,以阵列中心位置为原点O,建立如图2所示的所示的直角坐标系。

图2 四元十字阵结构图


3 声源定位系统设计
在理论分析基础上,本文设计了基于S5PV210的实时声源定位系统。系统的硬件框图如图3所示。
系统采用四麦克风组成四元十字阵来估计声源位置。考虑到空间采样定理,本文设定的麦克风间距为15 cm。麦克风采集到模拟声信号后,送到WM8960音频编解码芯片进行编码。编码后的数字信号送往S5PV210处理,用定位算法计算出声源位置。再利用超级终端通过串口与嵌入式系统进行交互,最终结果打印在超级终端上。其中SD卡和USB模块用于嵌入式系统程序的烧写和未来系统的升级。

图3 系统硬件框图
S2PV210是一个32 bit处理器,采用ARMV7精简指令集,主频率高达1GHZ,低功耗并且高效益。内部集成ARM Cortex-A8核心,将ARMV7-A体系架构和外设支持相结合,同时也是第1个以ARMv7架构为基础的应用处理器。芯片带有32 bit宽度、64 bit深度,支持5.1版本的IIS协议和128 kbyte音频播放输出缓冲器以及硬件音频混合器。S5PV210具有多种音频接口,可以便捷的对音频进行各种复杂的高速运算处理,为用户提供性能优异的音频解决方案。
本系统采用的WM8960是一款24 bit低功耗、高质量的立体编码解码器。其运行的模拟电源电压低至2.7V,数字内核运行电压可低至1.7V,芯片的不同部分可以通过软件控制实现关闭,这使得能耗进一步降低。其高级的片上数字信号处理能够实现麦克风输入的自动电平控制,支持的采样率有:8,11.025,12,16,22.05,24,32,44.1,48(单位:kHz)。
4 实验结果与分析
4.1 实验设置
在仿真实验中,房间的尺寸为6 m×6 m×3 m,声源坐标为[4 m,4 m,1 m],两个麦克风的坐标分别为[1 m,1 m,1 m]、[4 m,1 m,1 m]。用Image法产生房间脉冲响应,在无混响时,设置房间墙壁反射系数为0。将声源信号与传递函数卷积,可得到两个麦克风的接收信号。由图4可以看出,两麦克风间的时延差为59个点。
有混响时,设置虚拟声源个数为8,房间墙壁反射系数为0.3,图5为声源到两麦克风的传递函数。

图4 无混响时声源到两个麦克风的传递函数
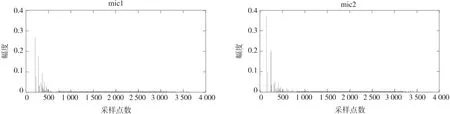
图5 有混响时声源到两个麦克风的传递函数
4.2 仿真实验
利用基于VLMS的时延估计算法,并根据式(14)~式(16),对声源进行空间定位实验。实验采用AV16.3数据库中不同语音片段进行,语音采样率为16 kHz,四元麦克风方阵中阵元之间距离d=15 cm。实验语音信噪比为20 dB和0 dB,分别进行30次实验,其平均定位效果如表1所示。
从表1可以看出,当语音信噪比较高(SNR=20 dB)时,3种算法都取得了较好的定位效果;而当语音信噪比较低(SNR=0 dB)时,VLMS算法定位精度最高,而基于互相关的GCC算法定位精度最低。

表1 空间声源定位平均效果
4.3 实时声源定位实验
测试设备包括:手持扩音器(用来提供声源)、声源定位系统(以S5PV210为核心处理器、WM8960为音频编解码器、电源及外围电路组成的电路板)、笔记本电脑(用来运行超级终端以与定位系统交互并观察结果)、支撑架(把扩音器固定在高处作为声源)、皮尺等。
测试实验在室外进行:地点为空旷的操场上,选取一个较为安静且无风的时间进行测试,主要噪声为远处传来的微弱噪声。
实验时,麦克风阵列均安放在地面上,声源信号为语音信号,麦克风一收到的波形如图6所示。采样率16 kHz,采样位数16 bit,帧长1 024。
测试时,对每个位置的声源都进行了10次测试,取其平均值作为最终结果。其中声源距麦克风阵的距离r为声源到阵列中心的距离(单位:cm),方位角用符号φ表示(单位:°),仰角用符号θ表示(单位:°)。为方便观察,统计结果均取绝对值,如表2所示。由表可知,方位角受声源距离和仰角影响较小,与距离和仰角相比,其误差较小。

表2 声源定位结果
由表2可知,从实验结果来看,该系统基本实现了声源的空间定位功能,但距离、和仰角的精度不够理想,需要进一步改进。因为在实际的声源定位系统中,除了定位算法自身的局限性之外,还有很多种因素影响着定位的结果。具体因素包括:(1)硬件因素:考虑到成本,本系统采用驻极体式麦克风,其性价比较高,但性能不如专业级麦克风。另外,系统硬件性能没有经过专业的测试,可能存在内部噪声,导致信号失真;(2)环境因素:声音传播的速度是不定的,而声速只能通过测量温湿度、风速、风向和气压等推算得到,本文取声速为340 m/s,这样在计算时就产生了误差。此外,在实际环境中存在不稳定的背景噪声,有些是人耳不易察觉,而麦克风很敏感的,这些噪声都会对最终结果造成一定的影响。(3)阵型因素:四元十字阵本身存在一些缺陷。其在估计距离时有较大的误差;其次,估计仰角时需要声源仰角较大时才有较高的精度。
5 结论
在理论研究基础上,本文设计了实时声源定位系统,并针对时延估计的问题,提出一种改进的时延估计算法。仿真和实时实验显示,该算法能较好的定位声源。但是,系统只能对单声源进行定位,无法满足对多声源进行定位的要求,后续需要进一步研究多声源定位的算法。本系统采用的是平面四元十字阵列,相比三维阵列,其定位精度较低,在后续的工作中可以改进麦克风阵列,用三维阵列来替代平面阵列。
[1]崔玮玮,曹志刚,魏建强.基于双麦克风的2维平面定位算法[J].信号处理,2008,24(2):299-302
[2]Flanagan J L,Johnston J D,Zahn R,et al.Computer-Steered Micro⁃phone Arrays for Sound Transduction in Large Rooms[J].J Acoust Soc Amer,1985,78(5):1508-1518
[3]Shan T J,Wax M,Kailath T.On Spatial Smoothing for Direction-of-Arrival Estimation of Coherent Signals[J].IEEE Transactions on Acoustics,Speech,and Signal Processing,1985,33(4):806-811
[4]Haykin S S.Adaptive Filter Theory[M].Pearson Education India,2005.50-57
[5]Carter G C.Variance Bounds for Passively Locating an Acoustic Source with A Symmetric Line Array[J].The Journal of the Acous⁃tical Society of America,1977,62(4):922-926
[6]Hahn W,Tretter S.Optimum Processing for Delay-Vector Estima⁃tion in Passive Signal Arrays[J].Information Theory,IEEE Trans⁃actions on,1973,19(5):608-614
[7]Benesty J.Adaptive Eigenvalue Decomposition Algorithm for Pas⁃sive Acoustic Source Localization[J].The Journal of the Acousti⁃cal Society of America,2000.107(1):384-391
[8]Brandstein M S,Adcock J E,Silverman H F.A Closed-Form Loca⁃tion Estimator for Use with Room Environment Microphone Arrays[J].IEEE Transactions on Speech and Audio Processing,1997,5(1):45-50
[9]Wang H,Kaveh M.Coherent Signal Subspace Processing for the Detection and Estimation of Angles of Arrival of Multiple Wide-Band Sources[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1995,33(4):823-831
[10]Buckley K,Griffiths L.Broad-Band Signal Subspace Spatial Spec⁃trum Estimation[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1998,36(7):953-964
[11]Dibiase J.A High-Accuracy,Low-Latency Technique for Talker Localization in Reverberant Environments[D].Brown University,USA,May 2000:12-56
[12]鲁佳.基于传声器阵列的声源定位研究[D].天津:天津大学,2008
[13]李雪梅,陶然,王越,等.时延估计技术研究[J].雷达科学与技术,2010,8(4):362-367
[14]付学志,刘忠,胡生亮,等.低信噪比下的变步长最小均方自适应算法及其在时延估计中的应用[J].中南大学学报,2012,43(3):1010-1018
[15]陆晓燕.基于麦克风阵列实现声源定位[D].大连:大连理工大学,2003
[16]Rotaru M,Albu F,Coanda H.A Variable Step Size Modified Decor⁃related NLMS Algorithm for Adaptive Feedback Cancellation in Hearing Aids[C]//2012 10th International Symposium on Electron⁃ics and Telecommunications,ISETC 2012.2012.Timisoara,Roma⁃nia:IEEE Computer Society:1011-1015.

姜志鹏(1978-),男,汉族,江苏省金坛市人,硕士,现为金陵科技学院讲师,主要研究方向为信号与信息处理、无线传感网络,jzp@jit.edu.cn。
