基于选择性聚类集成的客户细分
2015-02-27王瑞琴
潘 俊,王瑞琴
(1.温州大学 建模与数据挖掘研究所,浙江 温州 325035;2.温州大学 物理与电子信息工程学院,浙江 温州 325035)
0 引言
近年来,随着企业信息化水平的提高和数据存储技术的发展,不少数据密集型企业积累了海量的客户业务数据,如何对这些数据进行深层次的分析,从中获取客户的行为特征和消费偏好,并有针对性地开展营销与服务,挽留高价值客户,成为企业面临的重要问题[1-2]。客户细分方法[3-6]是实现针对性营销的重要手段,它是指企业根据客户的特征和行为划分客户群体,从而制定相应的品牌推广战略和营销策略,合理分配服务资源。作为洞察力营销的核心概念和重要基础,客户细分能帮助企业构建更个性化并有更高利润的市场营销活动,受到企业的广泛重视[1]。
客户对象的特征划分是客户细分的基础,根据细分维度的不同,一般可分为人口统计细分、心理细分、地理细分和行为细分[1]。采用的细分手段主要包括拟合分析、因素分析和聚类分析三类。其中,聚类分析技术将未标记的客户对象按相似度进行分组,使得同组客户的相似度最大而不同组客户的相似度最小,能有效发现客户对象的内在特性,在实践中得到广 泛 应 用[2,4-6]。 文 献 [4]采 用 一 趟 聚 类 算法,将电信客户划分为若干具有不同消费能力及消费倾向的客户群体。文献[5]利用模糊聚类算法对客户进行划分后,根据划分结果选择重要的属性来刻画客户特征。文献[6]采用分阶段聚类方法,分别对客户所在城市进行聚类并通过对客户进行分类来实现多区域的客户细分。聚类分析方法采用单一聚类算法来识别客户的内在特征,而在实际应用中,随着数据来源的多样化和数据集规模的增大,单一聚类算法往往难以获得令人满意的聚类效果[7]。
集成学习通过集成多个不同版本的学习器来解决同一个回归或分类学习任务,被证明可以显著提高学习器的泛化能力[8],是当前机器学习领域的研究热点。聚类集成算法正是在此背景下发展起来的,它通过多个独立的聚类器对数据集分别聚类,并集成得到统一的聚类结果。许多研究表明,聚类集成技术在算法的鲁棒性和稳定性等方面超过单一聚类算法[7-17],因此一些研究采用聚类集成技术进行客户细分[14-15]。文献[14]以模糊C均值(FCM)算法为基聚类器,提出了一种基于模糊聚类集成算法的客户细分模型。文献[15]首 先 用 自 组 织 映 射 (Self-Organizing Map,SOM)和k均值方法对客户数据聚类并添加类别标记,然后分别采用支持向量机、神经网络和决策树作为个体分类器,最后集成得到结果。传统集成方法通常对所有的学习器都进行集成,而文献[16]提出的“选择性集成”理论表明,采用中小规模的选择性集成可以获得较好的性能。文献[17]基于该理论提出了基于bagging的选择性聚类集成并在UCI机器学习数据集进行了实验,获得了较好的结果。
对于信息密集型企业,客户数据往往是海量的高维数据,为此本文借鉴选择性集成的思想,提出一种基于选择性聚类集成的客户细分框架。首先根据数据来源和业务需求构建统一的客户视图,然后在每个分视图下对客户对象聚类,并选择高质量的聚类进行集成。本文的选择性集成体现在两方面:在构造聚类集体阶段,选择评价函数值最大的标记向量参与聚类集成;在聚类集成阶段,采用基于权值的集成策略选择最具代表性的若干个簇参与集成。通过对某电信企业客户细分的实证研究表明,本文框架可以有效识别出不同价值和消费行为习惯的客户群,从而为企业开展针对性营销,制定战略决策提供依据和支持。
1 k均值聚类和聚类集成
1.1 k均值聚类
k均值聚类算法[18]是将数据集划分为k个簇的经典算法,给定簇的个数k后,算法随机选择k个点作为初始簇中心,按距离测度将每个样本分配到与之最近的簇中心,然后迭代更新各簇中心直至所有样本所属的新簇中心均与原来一致。设待聚类数据集为X={x1,x2,…,xn},k均值算法的目标是最小化簇内方差准则函数:
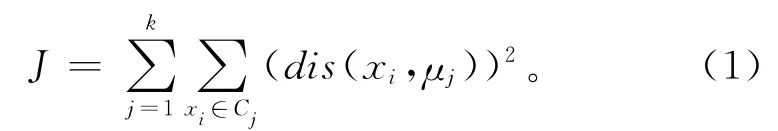
式中:μj表示簇Cj的中心点,(dis(xi,μj))2表示簇内各点到簇的中心点的距离平方。k均值算法采用的是贪婪搜索策略,聚类结果对参数k的取值较为敏感,本文采用一种评价函数来确定参数k,选择簇内紧密,簇间分散的聚类结果参与聚类集成。
1.2 聚类集成
聚类集成问题可表述如下:假设用M个聚类器分别对样本集X进行聚类,得到一个标记矩阵Π=[π(1),π(2),…,π(M)],其 中 标 记 向 量π(m)=[π1,π2,…,πn]T(m=1,2,…,M)将样本集X划分为k个聚类,πi∈{1,2,…,k}是对样本点xi置的簇标记,则聚类集成算法采用某种一致性函数将标记矩阵Π合并为最终标记向量π。聚类集成一般包含两个步骤:①生成聚类集体,即用各种聚类器产生不同的个体标记向量;②个体集成,即合并个体标记向量得到一个统一的聚类结果。
2 基于选择性聚类集成的客户细分
2.1 聚类集体的构造
集体的多样性被认为是影响集成学习的关键[8]。为了获得高质量的聚类集体,研究者们提出了多种构造方式,大致可分为三类:①使用同一个数据集,但选择不同的聚类算法[7]或者对同一个聚类算法选择不同的初始化参数[9];②使用同一个聚类算法,但选择数据集的不同采样子集[17];③选择数据集的不同特征子集[9]或者不同投影子空间进行聚类[11]等。对于信息密集型企业,其客户数据往往来自多个业务系统,数据规模庞大且维数较高,直接对全体客户对象进行聚类势必将增加聚类算法的开销,为此可以考虑第三种方式,即选择数据集的不同特征子集聚类。事实上,客户的特征可以通过不同角度来刻画,例如,既可以从人口统计特征(年龄、性别、兴趣、收入等)的角度来描述,也可以通过消费行为特征(购买的服务、购买时间、支付方式)的角度来描述。为此,本文根据数据来源和业务意义的不同,将客户特征划分为若干子集(每个子集表示一种业务视图)再分别聚类。假设客户数据集为X={x1,x2,…,xn},首先将客户特征划分为M个子集,每个子集表示一个视图,选择样本集X的不同征子集{Sm},m=1,…,M作为训练集,用k均值算法对每个训练集进行聚类,得到M个标记向量。
由于k均值算法对参数k的取值比较敏感,文献[19]提出了基于熵值的评价函数,认为熵值越低的k个划分具有较好的性能。本文采用一种新的评价函数来确定k值,选择簇内紧密,簇间分散的标记向量参与聚类集成。首先定义两样本间的相似度:

式中:‖xi-xj‖2为欧氏距离,σ为缩放因子,用于调节敏感度。显然,两个样本点的相似度为[0,1]的数值。类簇的紧密性可以用属于该类簇的所有样本之间的平均相似度来表示,则标记向量π(m)的类簇紧密性计算如下:

类簇间的分散性可用类簇中心之间的相似度表示,则标记向量π(m)的类簇分散性计算如下:
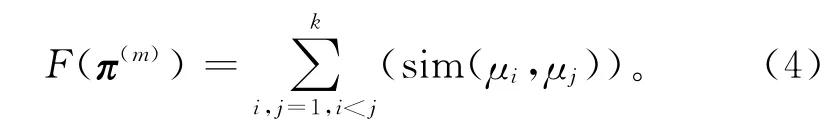
合并这两种度量作为聚类效果总体质量的评价函数,合并时要权衡权值分配,即

由式(5)容易看出,簇内紧密、簇间边界分开的标记向量将具有最大的评价函数值。本文以评价函数值作为选择聚类集成个体标记向量的依据,即对于范围Cmin和Cmax之间的k值,选择评价函数值最大的标记向量参与聚类集成。基于特征划分的k均值聚类集体生成算法描述如下:
算法1 基于特征划分的k均值聚类集体生成算法。
输入:簇个数的范围Cmin和Cmax,数据集X,特征子集数M;


2.2 聚类集成
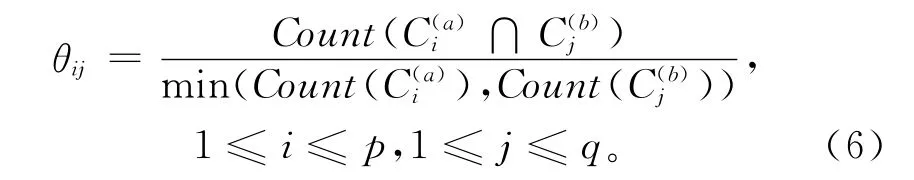

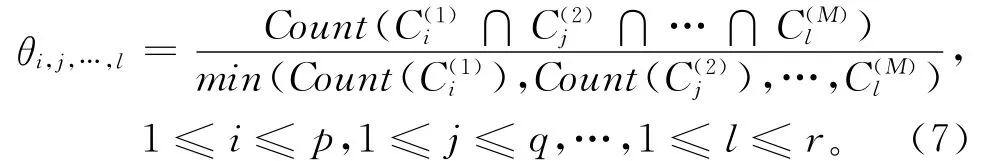
遍历该超立方体,选择权值高于某个预设阈值的簇作为输出结果。显然,所选择的客户簇是全体客户对象的子集,可以通过阈值来调节参与聚类集成的客户数。在客户细分应用中,还可以根据业务意义和客户数占比对输出的簇进行合并,最终输出客户细分结果。
2.3 基于选择性聚类集成的客户细分框架
基于上述分析,本文提出一个基于选择性聚类集成的客户细分框架,框架的整体架构如图1所示,主要分为三部分:
(1)客户统一视图 根据业务系统的建设情况建立统一的客户视图。对于已经建立数据仓库或数据集市的企业,可以直接从数据仓库中抽取数据建立客户视图。然后将客户特征按照业务分析需求划分为若干子集,从不同角度来描述一个客户。
(2)生成聚类集体 采用聚类算法分别对特征划分后的客户数据聚类,产生聚类集体。定义某种选择策略(式(5)),选择评价函数值大的个体标记向量参与下阶段的聚类集成。
(3)聚类集成 对于参与集成的个体标记向量,定义某种筛选策略(式(7)),选择权值高于某个预设阈值的簇进行聚类集成,并根据业务意义和客户数占比等因素合并相应的簇,输出客户细分结果。
3 实证研究
电信企业是典型的信息密集型企业,其各个IT业务系统中积累了海量的客户描述数据。例如客户关系管理(Customer Relationship Management,CRM)系统记录了客户的人口统计信息和购买的服务产品等信息;计费系统记录了客户的通话清单、付费欠费、账单等数据;呼叫中心记录了客户的投诉建议和业务咨询等信息。以某电信运营商的目标客户为例,对本文所提框架进行实证研究。首先按照客户交互分类主题,以客户ID为主键,抽取、转换并装载相关数据到一个集中的数据库中,建立临时的客户数据集市(DataMart)作为进行全面客户研究和分析的基础数据源。该数据集市包含的基准客户为某市去除免费和公免后的部分甲种客户(非经营性的私人住宅客户),样本总数为226 212。
3.1 构建客户模型

构建客户模型需要从业务的实际意义角度,将客户的各种相关信息,如人口统计信息、利益、生活方式、客户价值、客户行为等关联起来。电信企业传统上以客户的每户平均收益值(Average Revenue Per User,ARPU)作为划分客户的标准,这种方法可以识别企业的高价值客户,但是无法揭示客户群体的消费习惯和需求差异。另一方面,企业拥有的海量客户行为和消费记录则客观记录了客户消费行为的趋势和变化。对于客户细分来说,从客户价值和客户行为这两个角度对客户进行挖掘,分析不同价值的客户的行为规律及其特点,有助于企业对不同的客户群采取相应的措施以提高客户满意度。为此,本文以客户ID为主键,从行为和价值两个角度为每个客户生成一条多维度记录。由于客户的特征分散于各个独立系统(CRM、计费、10000号等),部分特征在业务上不具有直接的指导意义,因此从客户价值角度构造了月平均费用、费用占比、费用趋势、欠费周期等衍生特征;从客户行为角度构造了平均时长、时长趋势、时长占比、波动等衍生特征。部分衍生特征不参与聚类,而在聚类完成后用于客户群的特征刻画,从实际工程应用看,衍生变量不宜衍生的层次太深,需简单且能反映业务意义。最后在数百个客户特征中选择出85个关键特征,并划分为客户行为特征集和客户价值特征集两个视图。前者包括各类服务产品(如互联网业务、移动电话业务、本地固话电话、卡业务等)的月平均时长,时长趋势和占比、区内或区间跳次等行为特征,他网业务的使用时长占比以及工作时间、周末、节假日等时间分量的行为特征,共55个关键特征。后者包括各类服务产品的平均费用、费用趋势和占比、优惠费用占比、他网接入费用及趋势等费用信息,共30个关键特征。参与聚类的客户特征和衍生特征都已转化为数值型,部分非数值型的特征用于后期的客户群特征刻画。对于流量单位、时长单位、金额单位在数据预处理时进行统一。
3.2 生成聚类集体
聚类算法采用k均值聚类,分别从行为和价值两个视图对客户对象进行聚类。在k值设定为区间[5,15]的条件下,由算法1依据客户的价值特征共产生9个聚类,依据客户的行为特征共产生9个聚类,表1和表2分别给出了客户聚类结果的基本指标,其中每用户平均收入(Average Revenue Per User,ARPU)的单位为元/人月,每户平均通话时间(Minutes of Usage,MOU)单位为 min/人月,其中MOU值做了归零规范化处理(Z-score)。

表1 客户价值聚类结果

表2 客户行为聚类结果
3.3 聚类集成
在完成价值和行为两个视图下的客户聚类后,构造重叠矩阵记录每一对簇标记所覆盖的相同对象的个数,按照式(6)计算每个矩阵元素对应的权值θ,在阈值设定为30%的条件下,集成得到16个簇,客户覆盖率为86%,图2给出了在客户行为和客户价值两个视图下的客户细分热力图,对热力图中的每个点,从客户数占比、所属视图下的特征来分析其特点,并根据人口占比和特征一致性对各个值得关注的点进行合并,从业务角度合并部分簇,共得到7个簇。

得到客户细分结果后,再对各客户群进行分析和刻画,以帮助市场营销人员更好地理解客户群。首先用统计数据将客户群各特征进一步量化,再对客户群进行命名。通过分析得到7组用户:
(1)C1组用户的特征是本地费用、传统长途和IP长途费用均很低,数据业务使用很少,平均ARPU值为41.3元,平均欠费3.15元,离网率较低,属于中低端客户,命名为本地通话组。
(2)C2组用户的特征是传统长途费用较高,他网IP接入很少,欠费率较高,平均ARPU值为89.25元,命名为长途繁忙组。
(3)C3用户的特点是区内占比较高,区间费用较低,有一定的长途需求和他网IP接入,欠费较少,平均ARPU值为64.36元,命名为本地稳定组。
(4)C4组用户的特征是区间通话次数多,区间费用占比最高,区间费用下降最快,欠费率较高,平均ARPU值为82.12元,命名为短途差旅组。
(5)C5组用户的特征是数据业务需求大,宽带时长最高,宽带费用占比最高,其他费用均较低,欠费较少,离网率最小,平均ARPU值很高为118.52元,命名为宽带上网组。
(6)C6组用户的特征是IP国内费用很高,传统国内长途下降,国际长途费用较高,欠费较高,ARPU值较高101.25元,命名为商务精英组。
(7)C7组用户的典型特征是他网IP接入费异常高,上升趋势最快,国内长途也较高,但下降非常快,欠费较高,新用户较少,离网率较高,平均ARPU值较高108.68元,命名为高值易流失组。
通过客户细分,企业营销部门可根据各客户群的需求制定不同的营销活动。例如,对C5组客户提供增值服务和采取新业务推介策略,对C6组客户采取业务捆绑和交叉销售策略,对C7组用户采取IP包保、分段折扣等策略,从而有效提高客户的忠诚度、提升价值。
3.4 对比分析
为了测试本文方法的性能,设计了对比实验,将其和常用的客户细分算法k均值聚类进行比较,最大迭代次数设为100,循环停止阈值设为1e-5。从总样本数据中分别抽取1 000,1 500,…,5 000个样本,每次进行10次实验后输出平均结果。聚类性能的评价标准采用了规范化互信息(Normalized Mutual Information,NMI)指标[20]。NMI值是一个对称的可用来测量两个分布之间共享信息的度量。经过规范化后的互信息的值的范围在0~1之间,值越大表明聚类的效果越好。图3给出了两种算法随抽样样本数的增加的聚类精度结果。
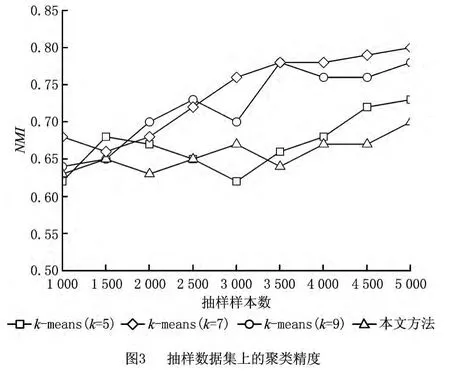
从图3可以看出,随着抽样样本数的增加,两种聚类算法的聚类精度都有一定的提升,本文方法在聚类精度上总体要优于k均值算法,这主要是因为本文方法是在用户行为和用户价值两个视图下分别聚类后再进行集成,这比k均值算法根据用户全部特征进行聚类更为精确。此外,k均值算法需要事先确定聚类个数k,由图3看出,当k的取值为7、抽样样本数为5 000时,取得了最高的NMI值,而本文方法由算法1根据式(5)在给定的k值区间中自动选择每个视图下最优的聚类个数,具有一定的优越性。
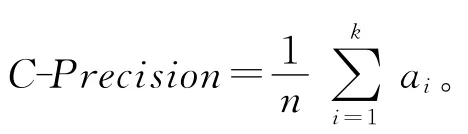
其中:n为样本数,k为聚类数,ai为被正确分类的样本个数,值越大,表示聚类得到的标记向量越好。实验中将本文方法与基于投票的聚类集成算法(voting)、基于模糊聚类的集成算法(FCM-ensemble)和基于Bagging的选择性聚类集成算法(sel-bvoting)进行对比,基聚类器的聚类个数即已知的类别数都设为2。除了基于模糊聚类的集成算法采用了FCM聚类器,其余算法均采用k均值聚类器,迭代次数和阈值同上,重复10次取平均聚类精度。其中基聚类器的训练集都采用bagging重抽样技术生成,由于指定了聚类个数,本文方法的算法1中Cmin和Cmax都设为2,图4给出了四种算法的聚类精度和参与集成的个体聚类器数的关系。
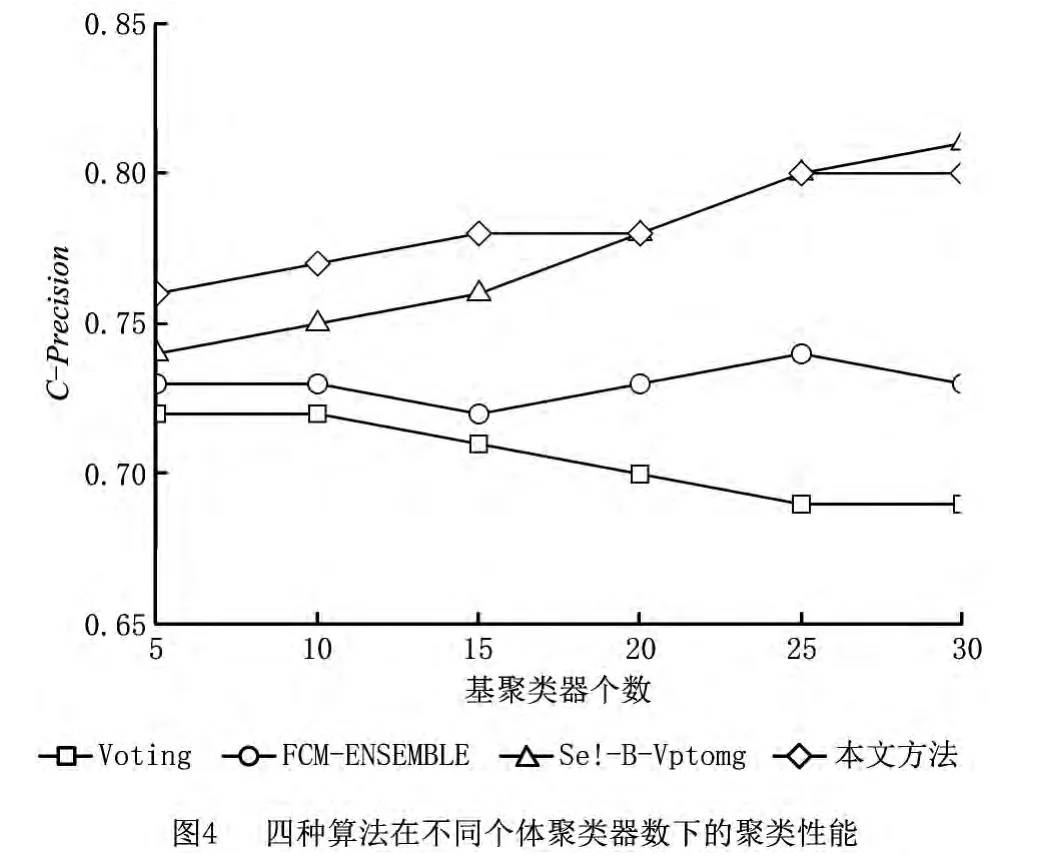
由图4可以看出,本文方法和基于Bagging的选择性聚类集成要优于基于投票的聚类集成和基于模糊聚类的集成,且聚类性能随个体聚类器数目的增加而有所提升,这说明在集成学习过程中,当得到了一组个体学习器后,按照某种策略选择其中一部分学习器进行集成,会取得更好的学习效果,这主要是因为剔除了某些可能会对学习带来误导的个体学习器。同为选择性的聚类集成算法,本文方法与基于Bagging的选择性聚类集成方法性能大致相当,但是由于本文方法是按照业务意义在不同视图下进行聚类集成,就客户细分这个具体应用而言,在得到聚类结果后,本文方法能较快速地对客户分群的行为和特征进行刻画,从而采取相应对策来挽留用户,因而更适用于业务意义明确的聚类应用。
4 结束语
本文针对信息密集型企业的客户细分问题,提出了一种基于选择性聚类集成的客户细分方法。本文方法将客户特征按照业务意义划分为若干子集后分别聚类,降低了计算开销和存储开销。另外,本文方法利用评价函数来确定参与集成的聚类集体,该过程只对k均值聚类算法生成的个体标记向量进行分析,独立于具体的聚类算法,因此本文提出的框架具有一定的宽泛性,可以扩展到k均值聚类以外的其他聚类算法。实证研究表明,本文方法可以有效识别出具有不同行为特征和消费能力的客户群,细分结果可作为企业制定营销方案的依据和参考。进一步的工作是将研究细分结果进行深化应用,如结合分类算法建立客户的套餐购买预测模型、客户流失预测模型等。
[1] LIU Yingzi,WU Hao.A summarization of customer segmentation methods[J].Journal of Industrial Engineering/Engineering Management,2006,20(1):53-57(in Chinese).[刘英姿,吴 昊.客户细分方法研究综述[J].管理工程学报,2006,20(1):53-57.]
[2] YU Xiaobing,CAO Jie,GONG Zaiwu.Review on customer churn issue [J].Computer Integrated Manufacturing Systems,2012,18(10):2253-2263(in Chinese).[于小兵,曹 杰,巩在武.客户流失问题研究综述[J].计算机集成制造系统,2012,18(10):2253-2263.]
[3] ZOU Peng,LI Yijun,HAO Yuanyuan.Customer value segmentation based on cost-sensitive learning [J].Journal of Management Science in China,2009,12(1):48-56(in Chinese).[邹 鹏,李一军,郝媛媛.基于代价敏感性学习的客户价值细分[J].管理科学学报,2009,12(1):48-56.]
[4] WANG Lianxi,JIANG Shengyi.Segmentation of telecom customers based on clustering[J].Journal of The Society for Scientific and Technical Information,2011,30(11):1171-1177(in Chinese).[王连喜,蒋盛益.基于聚类的电信顾客细分[J].情报学报,2011,30(11):1171-1177.]
[5] ROMDHANE L B,FADHEL N,AYEB B.An efficient approach for building customer profiles from business data[J].Expert Systems with Applications,2010,37(2):1573-1585.
[6] ZOU Peng,YU Bo,WANG Xianquan.Cost-sensitive learning method with data drifts in customer segmentation[J].Journal of Harbin Institute of Technology,2011,43(1):119-124(in Chinese).[邹 鹏,于 渤,王宪全.面向数据漂移的代价敏感客户细分[J].哈尔滨工业大学学报,2011,43(1):119-124.]
[7] STREHL A,GHOSH J.Cluster ensembles:a knowledge reuse framework for combining partitions[J].Journal of Machine Learning Research,2002,3(3):583-617.
[8] DIETTERICH T G.Ensemble learning,chapter in handbook of brain theory and neural networks[M].Cambridge,Mass.,USA:MIT Press,2002.
[9] ZHOU Lin,PING Xijian,XU Sen,et al.Cluster ensemble based on spectral clustering [J].Acta Automatica Sinica,2012,38(8):1335-1342(in Chinese).[周 林,平西建,徐森,等.基于谱聚类的聚类集成算法[J].自动化学报,2012,38(8):1335-1342.]
[10] FERN X Z,BRODLEY C E.Random projection for high dimensional data clustering:a cluster ensemble approach[C]//Proceedings of the 20th International Conference on Machine Learning.Washington,D.C.,USA:IEEE,2003:186-193.
[11] TOPCHY A,JAIN A K,PUNCH W F.Combining multiple weak clustering[C]//Proceedings of the 3rd IEEE International Conference on Data Mining.Washington,D.C.,USA:IEEE,2003:331-338.
[12] FRED A,ANA L N.Combining multipleclustering using evidence accumulation[J].IEEE Transactions on Pattern A-nalysis and Machine Intelligence,2005,27(6):835-850.
[13] TOPCHY A,JAIN A K,PUNCH W.Clusteringensembles:model of consensus and weak partition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(12):1866-1881.
[14] GAO Wei,HE Changzheng,XIAO Jin.Customer segmentation study based on fuzzy clustering ensemble[J].Journal of Intelligence,2011,30(4):125-128(in Chinese).[高 伟,贺昌政,肖 进.基于模糊聚类集成算法的客户细分研究[J].情报杂志,2011,30(4):125-128.]
[15] FARVARESH H,SEPEHRI M M.A data mining framework for detecting subscription fraud in telecommunication[J].Engineering Applications of Artificial Intelligence,2011,24(1):182-194.
[16] ZHOU Z H,WU J,TANG W.Ensembling neural networks:many could be better than all[J].Artificial Intelligence,2002,137(12):239-263.
[17] TANG Wei,ZHOU Zhihua.Bagging-based selective clusterer ensemble[J].Journal of Software,2005,16(4):496-502(in Chinese).[唐 伟,周志华.基于Bagging的选择性聚类集成[J].软件学报,2005,16(4):496-502.]
[18] MACQUEEN J B.Some methods for classification and analysis of multivariate observations[C]//Proceedings of the 5th Berkeley Symposium on Mathematical Statistics and Probability.Oakland,Cal.,USA:University of California Press,1967:281-297.
[19] BEZDEK J C.Pattern recognition with fuzzy objective function algorithms[M].New York,N.Y.,USA:Plenum Press,1981.
[20] STREHL A,GHOSH J,MOONEY R.Impact of similarity measures on web-page clustering[C]//Proceedings of the AAAI Workshop on Artificial Intelligence for Web Search.Menlo Park,Cal.,USA:AAAI Press/MIT Press,2000:58-64.
