一种路网环境下LBS隐私保护算法
2015-02-27左正魏潘巨龙魏琳琳
左正魏,潘巨龙,魏琳琳
(中国计量学院 信息工程学院,浙江 杭州 310018)

一种路网环境下LBS隐私保护算法
左正魏,潘巨龙,魏琳琳
(中国计量学院 信息工程学院,浙江 杭州 310018)
近年来,基于位置服务(LBS)的应用越来越广泛.用户在享受这种位置服务带来的方便快捷之同时,也要承担可能暴露自身隐私信息(如位置等)的风险.目前,很多工作已经在诸如保护用户隐私信息方面取得了重大进展,但大多是集中于欧氏空间下的隐私保护技术,而路网环境下的隐私保护研究相对较少.针对路网环境下用户边权分布不均的问题,提出了基于哑元的边权均衡算法,即在保证匿名集中各路段邻近性的同时,以生成哑元的方式均衡各边边权分布.这样既能最大程度降低查询代价,又能使边权分布不会太分散.最后,通过实验验证了本算法的有效性,同时显示该算法还能有效防止边权分布不均引发的推断攻击.
位置服务LBS;路网;边权;隐私保护
网络技术、移动终端及地理信息系统(GIS)等技术的相互结合促使基于位置服务(location based services,LBS)的诞生.在LBS中,用户向第三方服务提供者(third service provider,TSP)发出查询请求,此请求携带自己的位置信息,服务提供者向用户提供所请求的服务,如用户请求查找离自己最近的加油站等.在此服务过程中,用户的隐私信息如位置等可能面临泄漏的危险.隐私简而言之就是不希望被别人知道的信息,曾经有过某人利用GPS技术跟踪别人的报道.随着LBS应用的普及,用户隐私问题也将引发很大的担忧,如文献[1-2]中所提到的.于是LBS用户的隐私保护问题被提了出来,目前,很多工作集中于欧氏空间下的用户隐私保护,如文献[3-12]等等,主要有假数据法、K-匿名模型及空间泛化等等,但路网环境下的研究相对较少.
在欧氏空间下用户的移动方向是任意的,但实际情况中,用户往往是沿着特定的路线如道路移动的,这时以前的很多隐私保护方法将遇到问题.图1描绘了在欧几里得空间下,采用某个现有传统技术的匿名结果如图(a)阴影部分,但是,在公路网络环境下的图(b)显示,当采用相同的匿名技术时,匿名集中很有可能仅有一条路段,这样,用户q的位置信息将很容易被攻击者跟踪,使该用户的位置隐私受到威胁.
于是,路网环境下的LBS隐私保护成为必须要解决的问题.在路网环境下,用户沿着特定的道路网络移动,这种情形下典型的隐私保护方法是K-匿名、L-路段长度技术[13],即形成的匿名路段集必须满足至少有K个用户,并且其总长度至少为L.这种算法显然没有考虑路段边权分布问题.
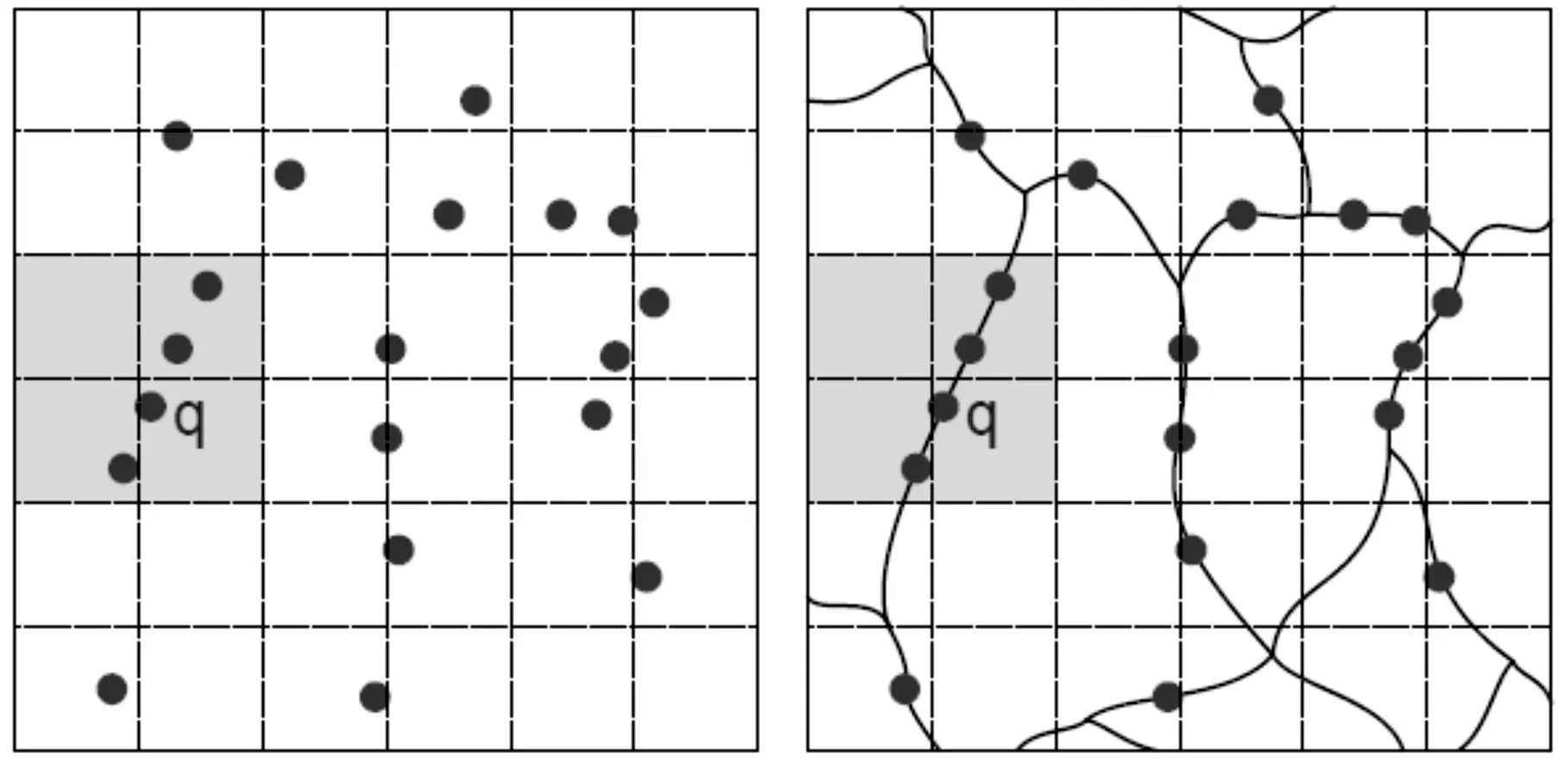
图1 欧式空间与路网环境匿名效果Figure 1 Anonimity in Euclidean and Road network space
1 相关工作
由于路网环境下用户隐私问题受到越来越多的关注,各种保护算法被提了出来,但又各有其局限性.文献[14]仅依赖于Casper匿名算法[15],而Casper主要应用于欧氏空间下,故也继承了欧氏空间算法的局限性.文献[16]提出了层次化结构模型,但由于该模型是静态的,不能抵御重放攻击.为了满足相互性,文献[18]为所有用户设置一个静态化的K-匿名参数,显然这不能满足用户的个性化需求,而且当用户需要比给定K更小的隐私需求时,其降低了查询服务质量.Wang等人[17]提出了X-Star子图匿名模型,其基本思想是将路网图转换为节点是子图的星状图,而其节点子图的度至少为3.X-Star虽然能满足相互性,但最后所得匿名结果集中的路段总长度可能很长,从而增加了查询处理开销.Kim等人对X-Star进行了扩展,结合Hilbert曲线提出H-Star算法.H-Star算法将Star节点按照Hilbert曲线进行编号,将Star节点按K值要求分装入bucket中.此算法虽然有些改进,但与X-Star有着同样的问题,即匿名结果集中路段可能太长,导致查询代价增大.周至贤等人提出了K-匿名、L-路段长度匿名算法.该算法要求最后形成的匿名集中包含至少K个用户,且所有路段的长度不能少于L.该算法全面考虑了服务质量与查询代价的平衡,但没有考虑用户在地理上的分布问题.为了解决此问题,孙岚等人提出了近邻算法NA,其思想是利用关联度来保证最后生成的匿名集中各路段边权分布均衡,但它牺牲了一部分邻近性,导到查询开销增大.
2 基础知识与相关定义
2.1 相关定义
如果把公路网络抽象出来,用一个带权的无向图G表示,这时便可以用一个三元组(V,E,W)来表示公路网络.其中,V表示顶点集合,vi属于V,表示公路网中的节点i,也即路的交点或拐点.边集用E表示,eij代表顶点vi与vj之间的边.而W代表各边权值的集合,边eij的权值即该边上的用户数目用Wij表示.
定义1 关联度
假如一个用户向LBS服务提供者发送某个请求R,运用某个匿名算法来处理用户的位置信息,最后生成一个匿名路段集S,∀e∈S,称边e与匿名路段集S的关联度为rel(S,e),其公式定义如下:
(1)
其中,e.w—边e权值,也即边e上的用户数目.显然,关联度的范围为0到1之间,且边的关联度正比于e.w,也就是该边上的用户数量.边e的关联度正好反映了该边上用户被攻击者识别的概率.关联度越大,用户被识别的可能性也相应增大,位置隐私泄露的风险也越高.当匿名路段集中用户所在的边rel(S,e)值很大,也即用户分布很不均匀时,攻击者就能较容易识别出用户所在的路段,从而造成隐私泄露.可见路网环境下也必须考虑用户的分布均匀性问题,否则由前述可知,可能会带来推断攻击,让用户的隐私受到威胁.
定义2 信息熵
信息熵是衡量匿名边集中边权分布是否均衡的一个指标,其值越大,则匿名集中各边的关联度越均衡,也即集合中各条边的权重分布也越均衡,则抵抗边权分布不均所引起的推断攻击的能力也越强.其定义如下:
Entropy(S)=∑e∈Srel(S,e)×log[A(S,e)].
(2)
定义3 开放节点
在匿名集S中,一个顶点v如果满足以下条件:与v相交的所有边都包含在S中,则称点v是闭合节点,否则称其是开放节点.
2.2 用户分布不均引发的问题
正如前面所讨论的,在路网环境下,很多欧氏空间下的传统隐私保护算法将遇到问题.路网环境下最典型的隐私保护算法是周至贤教授提出的K-匿名加上L-路网长度算法[13].该算法提出选取的匿名路段集在满足K-匿名的情况下,其总长度不得低于L.此算法虽然考虑了服务质量与查询代价的平衡,但它并没有注意到用户在地理上的分布情况,由此可能引发隐私泄露问题.如图2所示:
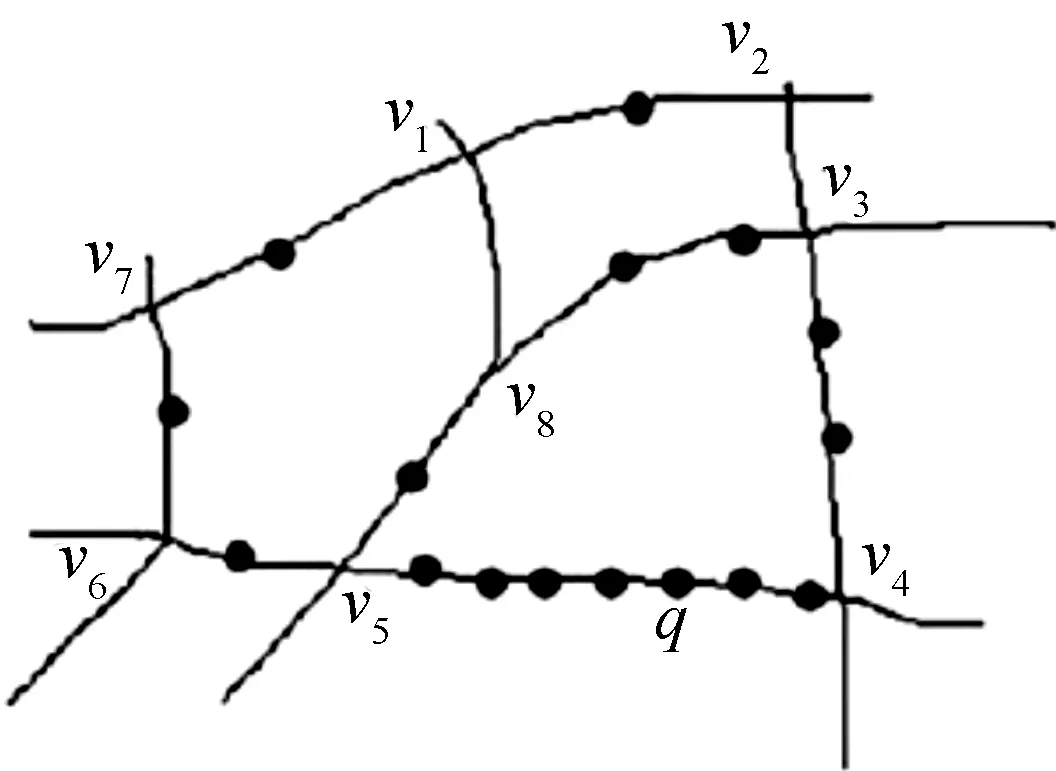
图2 边权分布不均示例Figure 2 Uneven distribution of wedge weight
用户q所在的路段v4v5是该网中用户非常密集的路段之一,用mij表示路段ViVj上的用户数.假设在满足用户隐私需求的情况下,路段v4v5、v5v8、v3v4构成了一个隐匿边集,那么攻击者已知路段用户分布情况下可以猜测出q在路段v4v5上的概率为m45/(m45+m58+m34),如图2的情况,此值接近于1,这便意味着用户q与路段v4v5匹配的概率很高,位置隐私将受到威胁.本文针对以上问题提出一种基于哑元,也即伪用户的边权均衡算法,可有效地解决上述问题,并通过实验验证了该算法的有效性.
3 基于哑元的边权均衡算法
3.1 查询代价模型
找到离用户最近的K个目标是一个典型的K近邻查询,该查询中,用户若直接提供自己的精确位置,称为普通K近邻查询.若用户的真实位置被泛化成一个匿名路段集,则称此查询为保护隐私的K近邻查询,简称为隐私K近邻查询.对于这样一种查询,我们的目标是要找到查询的候选结果集,其中包含了用户所需的真实查询结果.为方便起见,我们将此过程分为两步:第一步是范围内查询,即找到匿名路段集S里面的所有目标并将其加入到候选结果集中;第二步是外部查询,即对于匿名集S中的每一个开放节点,运用K近邻查询,找到离开放节点最近的K个目标并将其加入到候选结果集中.图3描绘了这两个过程.
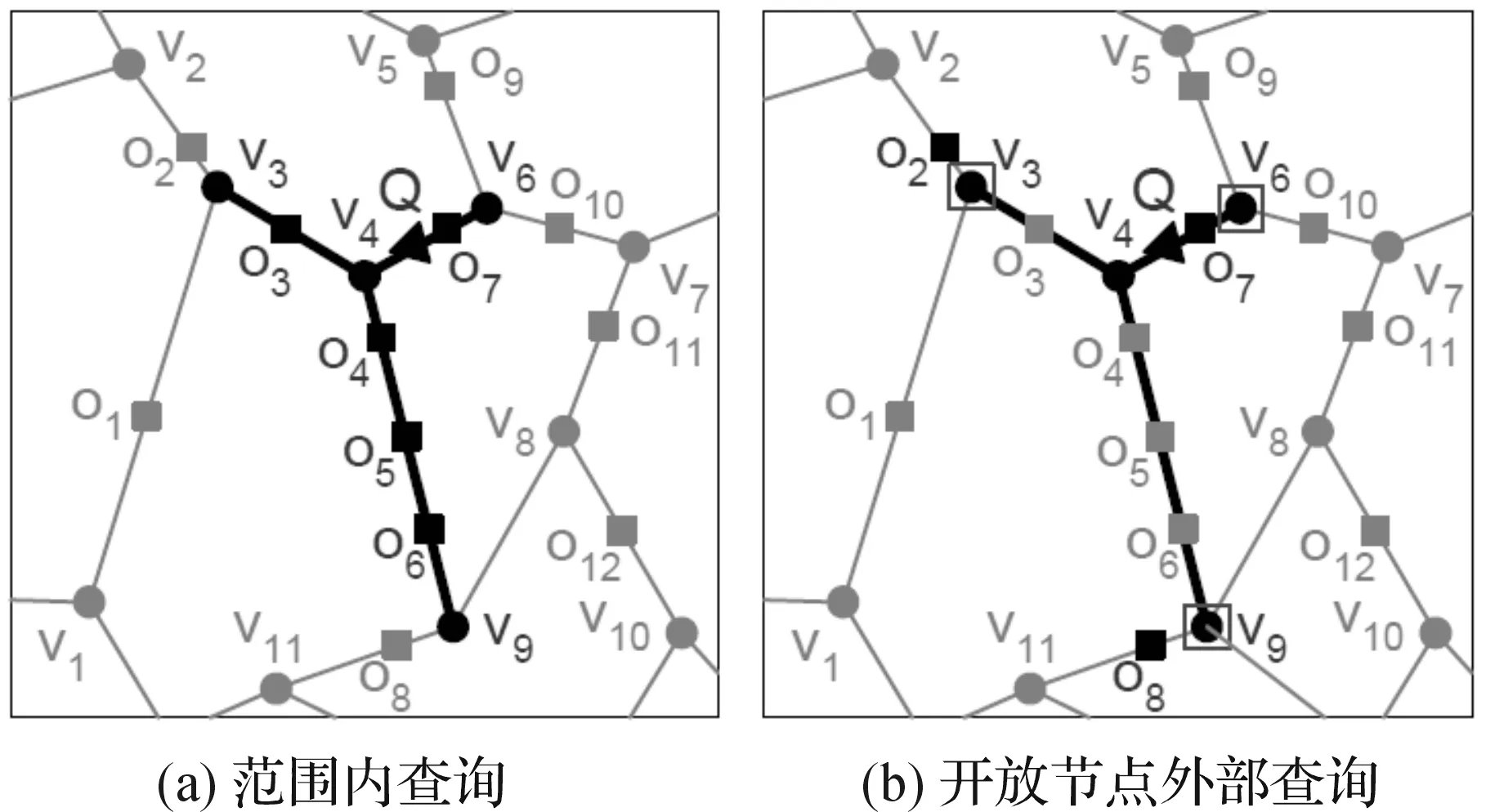
图3 隐私K近邻查询Figure 3 Privacy K nearest neighbor query
假设用E(S)代表匿名集S中的边数,V0(S)表示匿名集中开放节点数,R表示整个路网中所有路段数,T表示整个路网中所有查询目标,第一步为范围内查询,即查询S中所有路段的目标节点,我们可以用路段数来衡量其查询代价,即E(S).第二步,对于每个开放节点,找到一个目标需要平均搜索R/T路段,所以找到K个目标即需搜索(R/T)×K条路段,故对于所有开放节点,搜寻的路段数为Vo(S)×K×R/T,这便是第二步的查询代价衡量标准.综上所述,我们有如下隐私查询代价衡量公式
(3)
3.2 算法设计
正如上文所说,该算法首先是保证了路段之间的地理相近,也即每次选取离目标用户在地理上最近的路段加入匿名集中,然后才是通过生成哑元的方式解决权值分布问题.故而本算法能生成最紧凑的匿名路段集,也就是能使查询处理开销最优,同时也保证了权值分布的均衡性.为此提出了各边与目标用户所在边的相似度指数IoS(e),定义如下:
(4)
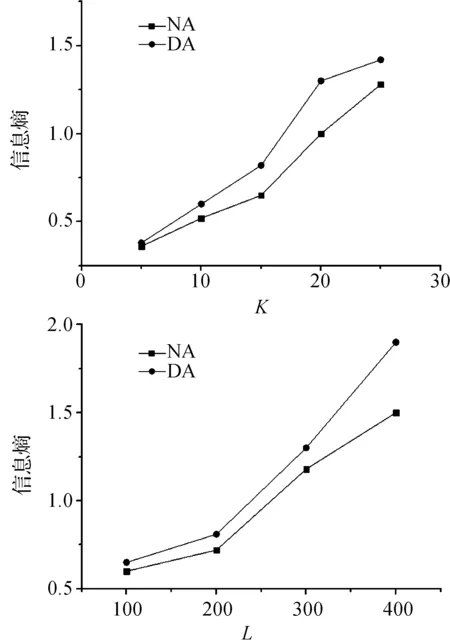
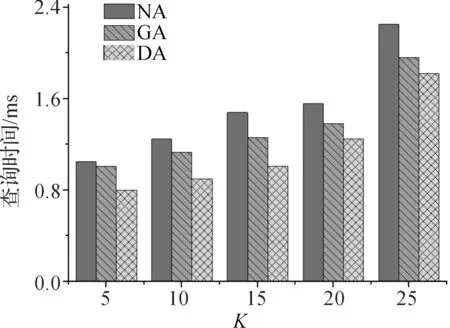
其中,m—目标用户所在边的边权值,即用户数,e.w—边e的权值,S—匿名路段集.相似度指数反映了各边与目标用户所在边的权值差异性,IoS越小,权值分布越均匀;反之越分散.基于哑元的边权隐私保护算法通过控制相似度指数小于某个阈值,从而控制边权分布.该算法首先将路网中的各边按距离目标用户所在边的网络距离进行排序,每次选取离目标边最近的边加入匿名集中,首先检查其权值是否满足相似度指数阈值要求,若不满足,则随机生成最少数量的哑元(伪用户)使得其满足IoS(e) Input: user U, query Q,IoSuOutput:S 1: Sorting all edges according to the network distance 2:e←the road segment contains the user U 3:S←{e} 4: while NumUser(S) 5: BestEdge←{e′|e′ is inSande′ is adjacent toSin the sorted sequence} 6: IfIoS(BestEdge)>u, Randomly generatendummies to satisfy IoS(BestEdge)≦u 7:S←S ∪ BestEdge 8: end while 9: returnS 为了验证本文提出基于哑元的边权均衡隐私保护算法的有效性,将该算法(以下简称DA)与文献[13]中提出的贪心算法(GA)及文献[20]提出的NA进行比较,验证了本文提出算法在降低查询处理开销方面的优越性.本实验用Java语言实现,数据由路网环境下Brinkhoff路网生成器基于Oldenburg地图产生,数据集大小如下表1. 表1 实验参数 实验环境为:Intel(R)Core(TM) i5-3470 CPU @3.2 GHz 3.2 GHz;4.00 GB内存;Windows7操作系统;Eclipse集成开发环境. 4.1 信息熵 信息熵可以反映算法所产生的匿名集中各边权值的均衡性,信息熵越大,权值越均衡;反之则分散.图4分别为在不同的K值和L值的情况下,算法NA和DA所产生匿名集信息熵的对比,图中纵坐标表示信息熵,横坐标分别表示K(用户数)和L(路段长度),由图可知,在相同的K或L的情况下,本文所提出的算法DA的信息熵较高,也即边权越均衡. 图4 不同K值和L值下DA及NA信息熵对比Figure 4 Entropy of DA and NA with different K and L 4.2 查询代价 通过式(3)的查询代价公式,在不同的K值和L值的情况下对比了GA、NA和DA的查询处理代价,如图5.图5中纵坐标表示查询代价,横坐标分别表示K和L,图中显示,当需求度K和L增大时,匿名路段集中必然会加入更多的路段,使匿名集中所包含的路段总数和边界点数增加,从而导致查询代价的增加,所以三种算法产生隐匿边集所需的查询处理代价也随之增加.但由于本算法(DA)是首先保证各边的邻近性,再用产生哑元的方式来保证边权的均衡性,所以使其产生的匿名边集比GA还小,从而获得更佳的查询处理开销.而NA由于首先保证边权的均衡性,损失了一部分的邻近性,从而查询处理代价较大. 图5 不同K值和L值下DA、GA及NA查询代价对比Figure 5 Query cost of DA, GA and NA with K and L 4.3 查询处理时间 在不同的K值的情况下,对GA、NA和DA从查询时间的角度对比它们的查询处理开销,由图6可知,图中纵坐标表示查询时间(ms),横坐标表示K值.NA由于保证了边权的均衡,从而牺牲了查询代价,其查询时间较GA更大.但DA在保证匿名边集的邻近性上达到了与GA同等的程度,而且由于增加了哑元,使得匿名边集里的边数进一步降低,从而有了更少的查询处理时间. 图6 不同K值下DA、GA与NA查询时间对比Figure 6 Query time of DA,GA and NA with different K 综上所述,相比于GA与NA,本文提出的基于哑元的边权均衡算法(DA),在保证匿名集中各边的邻近性的前提下,产生哑元以均衡各边的权值,使得其在邻近性上能达到GA的效果,而又有NA的抵御推断攻击的优点.不仅如此,由于哑元的引入,使得K匿名性更易满足,使得匿名结果集中边的数量进一步降低,从而使查询处理开销进一步降低. 本文针对路网环境下用户边权分布不均而可能引发隐私泄露的问题,提出了基于哑元的边权均衡算法,实验表明,在同等条件下本算法具有更好的隐私保护性能和较小的查询代价.下一步的工作重点将放在边权均衡算法的优化上,以期达到更好的查询效率,让用户在享受最大的隐私保护情况下获得更好的用户体验. [1] MOKBEL M F. Privacy in location based services: state of the art and research directions[C]//International Conference on Mobile Data Management. Mannheim:IEEE,2007:228-228. [2] PEDRESCHI D, BONCHI F, TURINI F, et al. Privacy protection: regulations and technologies, opportunities and threats[C]//Mobility, Data Mining and Privacy. Berlin: Springer,2008:101-119. [3] SHANKAR P, GANAPATHY V, IFTODE L. Privately querying location-based services with sybilquery[C]//Proceedings of the 11th International Conference on Ubiquitous Computing. New York: ACM,2009:31-40. [4] GRUTESER M, GRUNWALD D. Anonymous usage of location based services through spatial and temporal cloaking[C]//Proceedings of the 1st International Conference on Mobile Systems, Applications and Services. New York: ACM,2003:31-42. [5] ZHANG C, HUANG Y. Cloaking locations for anonymous location based services: a hybrid approach[J].Geoinformatica,2009,13(2):159-182. [6] BAMBA B, LIU L, PESTI P, et al. Supporting anonymous location queries in mobile environments with privacygrid[C]//Proceedings of the 17th International Conference on World Wide Web. New York: ACM,2008:237-246. [7] LI N, LI T, VENKATASUBRAMANIAN S.t-closeness: privacy beyondk-anonymity andl-diversity[C]//Proceedings of the 23rd International Conference on Data Engineering. Istanbul: IEEE,2007:106-115. [8] SOLANAS A, SEBE F, DOMINGO-FERRER J. Micro aggregation based heuristics for p-sensitive k-anonymity: one step beyond[C]//Proceedings of the 2008 International Workshop on Privacy and Anonymity in Information Society. New York: ACM,2008:61-69. [9] MASCETTI S, BETTINI C, WANG X S, et al. Providenthider: An algorithm to preserve historical k-anonymity in lbs[C]//Tenth International Conference on Mobile Data Management: Systems, Services and Middleware. Taipei: IEEE,2009:172-181. [10] ARDAGNA C A, CREMONINI M, DAMIANI E, et al. Location privacy protection through obfuscation-based techniques[C]// Data and Applications Security XXI. Berlin: Springer,2007:47-60. [11] CHENG R, ZHANG Y, BERTINO E, et al. Preserving user location privacy in mobile data management infrastructures[C]//Privacy Enhancing Technologies. Berlin: Springer Berlin Heidelberg,2006:393-412. [12] LEE J G, HAN J, WHANG K Y. Trajectory clustering: a partition-and-group framework[C]//Proceedings of the 2007 ACM SIGMOD International Conference on Management of Data. New York: ACM,2007:593-604. [13] CHOW C Y, MOKBEL M F, BAO J, et al. Query-aware location anonymization for road networks[J].GeoInformatica,2011,15(3):571-607. [14] KU W S, ZIMMERMANN R, PENG W C, et al. Privacy protected query processing on spatial networks[C]//Proceedings of the 23rd International Conference on Data Engineering Workshop. Istanbul: IEEE,2007:215-220. [15] MOKBEL M F, CHOW C Y, AREF W G. The new casper: query processing for location services without compromising privacy[C]//Proceedings of the 32nd International Conference on Very Large Data Bases:New York: ACM,2006:763-774. [16] PENG W C, WANG T W, KU W S, et al. A cloaking algorithm based on spatial networks for location privacy[C]//Proceedings of International Conference on Sensor Networks, Ubiquitous and Trustworthy Computing. Taichung: IEEE,2008:90-97. [17] WANG T, LIU L. Privacy-aware mobile services over road networks[J].Proceedings of the VLDB Endowment,2009,2(1):1042-1053. [18] MOURATIDIS K, YIU M L. Anonymous query processing in road networks[J].IEEE Transactions on Knowledge and Data Engineering,2010,22(1):2-15. A privacy protection algorithm designed for LBS in road networks ZUO Zhengwei, PAN Julong, WEI Linlin (College of Information Engineering, China Jiliang University, Hangzhou 310018, China) In recent years, location based services (LBS) have become more and more popular. However, the user’s privacy information such as his(her) locations is threatened, while the user enjoys the convenience and effectiveness provided by such services. Many different approaches have been raised to protect the user’s privacy under Euclidean space. But these approaches rarely focus on conditions under road networks. Now, we propose an edge weight balancing algorithm. The main idea of this algorithm is to create anonymous sets to guarantee the proximity of all edges and then to generate dummies to balance edge weight. Finally, the experiment verifies that the algorithm is able to resist inference attacks caused by uneven edge weight distributions. location based services; road networks; edge weight; privacy protection 1004-1540(2015)03-0359-06 10.3969/j.issn.1004-1540.2015.03.020 2015-05-18 《中国计量学院学报》网址:zgjl.cbpt.cnki.net 左正魏(1988- ),男,湖北省随州人,硕士研究生,主要研究方向为LBS隐私保护.E-mail:zzwstriver@163.com 通讯联系人:潘巨龙,男,教授.E-mail:pjl@cjlu.edu.cn TP309 A4 实验及结论


5 结 语
