IG-RS-SVM的电子商务产品质量舆情分析研究
2015-02-27叶佳骏周杭霞
叶佳骏,冯 俊,任 欢,周杭霞
(1.中国计量学院 信息工程学院,浙江 杭州 310018; 2.杭州市质量技术监督检测院,浙江 杭州 310019)

IG-RS-SVM的电子商务产品质量舆情分析研究
叶佳骏1,冯 俊2,任 欢1,周杭霞1
(1.中国计量学院 信息工程学院,浙江 杭州 310018; 2.杭州市质量技术监督检测院,浙江 杭州 310019)
电子商务产品的评论信息对于电子商务产品质量舆情监测具有极大的参考价值.针对集成学习算法在高维度下分类精度降低的不足之处,提出了一种IG-RS-SVM(Information Gain-Random Subspace-Support Vector Machine)算法.以Random Subspace集成学习算法为基础,以支持向量机算法为基学习器.引入了信息增益特征选择算法.通过对特征空间中每个特征的信息增益值进行排序,剔除无价值的特征,降低RS集成算法生成的特征子空间的维度,从而提高了SVM分类算法的效率.实验结果表明,改进后算法可以有效提高评论内容的分类精度.
产品评论;信息增益;随机子空间;支持向量机
电子商务产品质量评论内容的分析属于文本情感分析的一种,通过采集消费者购买电子商务产品后对该产品做出的评价,分析消费者的主观立场、情绪、态度等,对消费者评论的情感倾向作出判断,不仅可以帮助其他消费者作出是否购买的决定,更可以帮助质检部门尽快发现可能存在的产品质量问题,有利于监督抽查工作的实施.目前对于电子商务产品评论情感分析的主要方法有基于情感知识的方法和基于数据挖掘的方法[1].基于情感知识的分析方法主要是以自然语言为基础,依靠一些已有的情感字典,直接对评论内容作出判定.这种方式不仅需要建立庞大的情感字典库,而且由于中文语意的复杂性,无法准确地判断评论的情感倾向.基于数据挖掘的方法则是通过数据挖掘算法中的分类算法对文本进行分类.
1 基于数据挖掘的文本情感分析
1.1 文本预处理
普通文本信息为非结构化数据,计算机无法理解其语意,所以必须将非结构化数据转化为结构化数据.文本分词是预处理中的主要环节,分词操作将文本信息转化为结构化数据,还可以删除大量冗余内容,包括标点符号、停用词,重复内容等等.英文文本分词较为简单,只需要根据空格和标点进行操作.中文文本则需要通过相关算法进行分词,目前主流中文分词系统有SCWS中文分词系统[2]和ICTCLAS汉语分词系统.
1.2 文本表示
预处理后的文本并不是完整的结构化数据,还需要通过数学模型对预处理后的文本进行表示.最常用的文本特征表示模型是向量空间模型(Vector Space Model,VSM).在该模型中,文本空间被视为一组正交词条向量所张成的向量空间[3].使用VSM模型表示的文本通常都是高维的,特征空间的维度可以达到几万甚至几十万,其中有大部分是冗余或者不相关的,冗余的特征会导致分类器性能的下降,也会影响分析人员进行数据挖掘工作的效率.特征提取可以降低VSM模型特征空间的维数,从而达到提高分类精度和降低计算复杂度的目的.常见的特征选择方法有文档频率(document frequency,DF)、信息增益(information gain,IG)、互信息(mutual information,MI)、开放检验(Chi-square,CHI)等[4].
1.3 文本分类
运用数据挖掘算法对结构化数据进行分类,获得实验结果.文本分类常用的数据挖掘算法有Bayes分类器、支持向量机(SVM)、决策树等.集成学习则能够有效提高分类算法的执行效率,通过调用一些简单的分类算法获得多个不同的学习机,然后再将这些学习机组合成一个集成学习机.目前各种集成学习算法正在被广泛应用于图像处理[5]、生物医学、控制工程等相关领域.
将集成学习算法应用到文本分类中,已有研究取得了一定的进展.文献[6]使用了一种基于属性选择的Bagging算法,但该算法只能评估部分属性对于分类的贡献,无法评估单个属性对于分类的贡献.为了提高高维度下文本的分类精度,文献[7]提出了一种RS-SVM算法,但该算法没有考虑到在选择特征子空间时本身的维度问题,无法过滤掉冗余或者对分类没有贡献的特征.
本文针对上述算法的不足之处,充分考虑单个特征对文本分类的贡献,以及高维度空间下的文本降维,提出一种IG特征选择的RS-SVM算法.
2 RS-SVM算法的改进
2.1 SVM
支持向量机SVM(support vector machine)是Vapnik等人在多年研究统计学习理论基础上对线性分类器提出的一种设计最佳准则[8],在解决线性、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中[9-10].SVM的原理是得到一个超平面,使得两类中接近这个超平面的点距离都最远.
假设有训练样本集D={(x1,y1),(x2,y2),…,(xn,yn)},其中每个样本的维度为d,y是类别标号.求解最有超平面的问题可以转换为一个在不等式约束下的优化问题,可以通过拉格朗日法求解:
(1)
对每个样本引入一个拉格朗日系数:αi≥0,i=1,2,…,N.
通过对偶问题的解,可以求得决策函数为
(2)
SVM的优势在于处理非线性问题.通过引入特征变换将原空间中的非线性问题转化成新空间中的线性问题,即将两个样本在元特征空间中的内积(xi·xj)变成在新空间中的内积(φ(xi)·φ(xj)),可以记作核函数K(xi,xj)=(φ(xi)·φ(xj)).
这样最终得到的决策函数为
(3)
采用不同的核函数就得到不同形式的非线性支持向量机.目前较常用的核函数主要有三种类型:
线性核函数K(x,x′)=(x·x′);
多项式核函数K(x,x′)=[(x·x′)+1]q;
2.2 信息增益
对于某一特征,文本中包含或不包含这个特征时信息量(熵)的差值,就是信息增益(information gain, IG).公式表示如下:
(4)
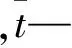
2.3 Random Subspace算法
即使运用特征选择算法,特征维度仍然很高.在Random Subspace算法中,在原始特征空间中提取出新的特征子空间后,使用基分类器对新的子集进行分类,最后运用投票表决法计算最终的分类结果.RS的结构如图1:
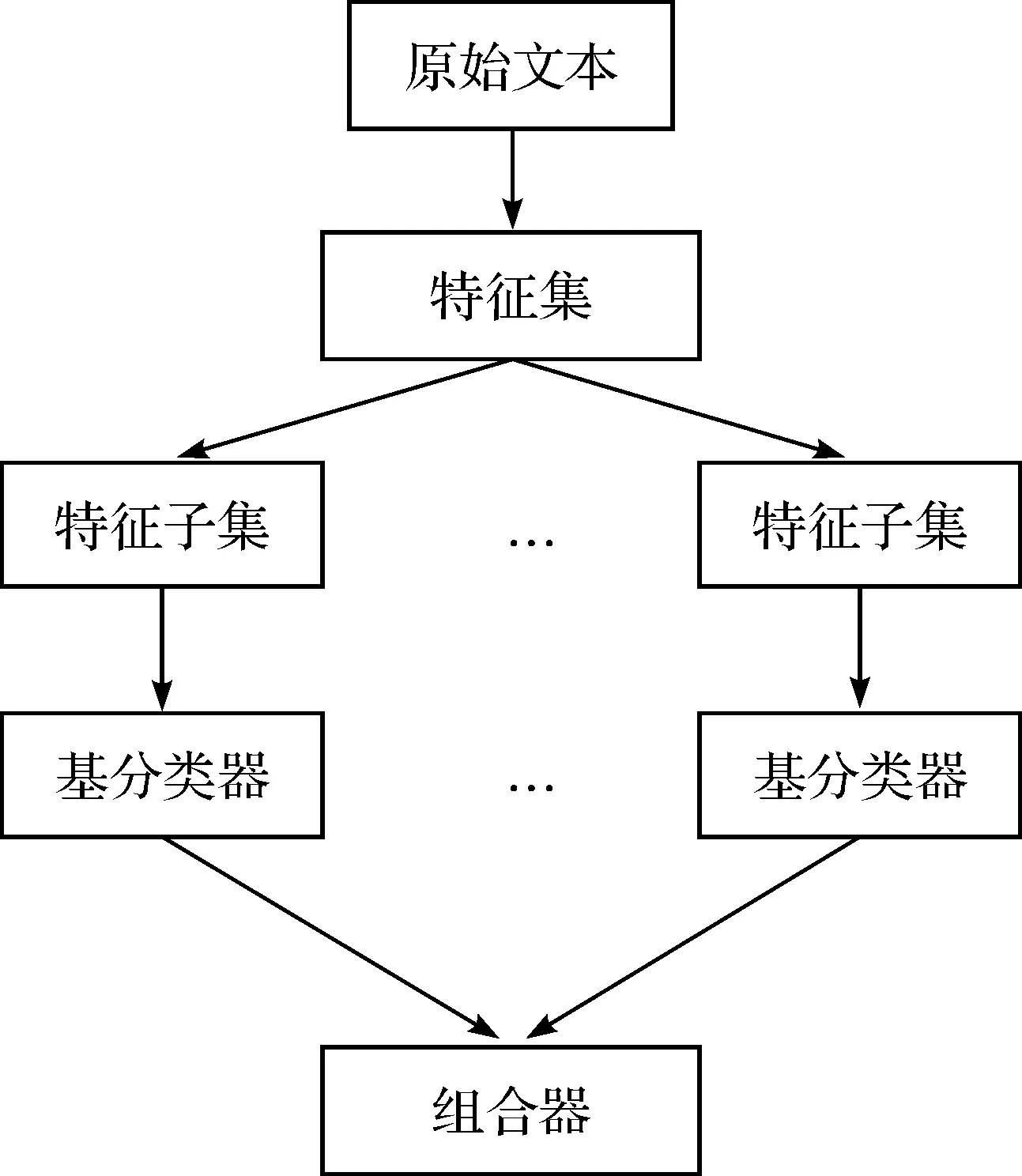
图1 RS结构图Figure 1 Structure of RS
2.4 改进的RS-SVM算法
对于一个文本di,进行预处理后可以将该文本表示为di={ti1,ti2,ti3,…,tin}(t表示特征,i表示特征的数量)和该文本所属类别ci.则文本数据集可表示为D={(d1,c1),(d2,c2),(d3,c3),…,(dm,cm)}和数量m,其中m表示数据集中文本的数量.
IG-RS-SVM算法描述如下:
输入:文本数据集D={(d1,c1),(d2,c2),(d3,c3),…,(dm,cm)}和数量m.
输出:分类结果F(di),F(di)∈C.
1)将文本数据集转换成VSM模型.
2)计算VSM模型中每一个特征的信息增益值IG(T),所得的值保存在一个特征集合中.
3)对该特征集合进行排序,并删除小于0的值.
4)根据新的特征集合重新建立VSM模型.
5)选择SVM分类器的数量.
6)对于每一个SVM分类器,从新的特征集合中随机生成一个特征子空间样本.
7)使用SVM分类器对特征子空间样本进行分类.
8)结合每个SVM分类器的结果,最终的输出由多数投票或通过组合后得出.
3 实验分析
文本分类领域常用查准率Precision、查全率Recall和综合评价指标F-measure来最为评估指标,计算公式如下:
对于二元分类,TP(true positive)指的是真阳性,即预测分类与实际类别都为真的样本数量;FP(false positive)是假阳性,即预测类别为真而实际类别为假的样本数量;FN(false negative)是假阴性,即预测类别为假而实际类别为真的样本数量.查准率(Precision)表示正确分类的样本数量在总样本中的比例,查全率(Recall)表示正确分类的样本数量在总样本中正确分类的比例,F1表示查全率和查准率的调和均值.
查准率能够衡量分类器拒受非相关信息的能力,查全率能够衡量分类器分类出相关信息的能力,F值能够度量查准率和查全率的综合能力.
3.1 实验结果分析
为了验证IG-RS-SVM在电子商务产品评论分析中的有效性,本文选取了经典的MovieReviews数据集,该数据集共2 000条,1 000条正面评价(Pos),1 000条负面评价(Neg).本实验使用十折交叉验证法,即将数据集分为十份,轮流将其中的九份作为训练数据,另一份份作为测试数据,取每次实验的平均值.经过文本预处理,得到的特征集中包含1 165个特征.再对对原始特征集使用IG特征选择算法,保留IG值大于0的特征,并组成新的特征集.该特征集中包含了311个特征,特征空间维度大幅下降.实验中选用四种分类器分别对两份特征集进行分类,实验结果如表1.
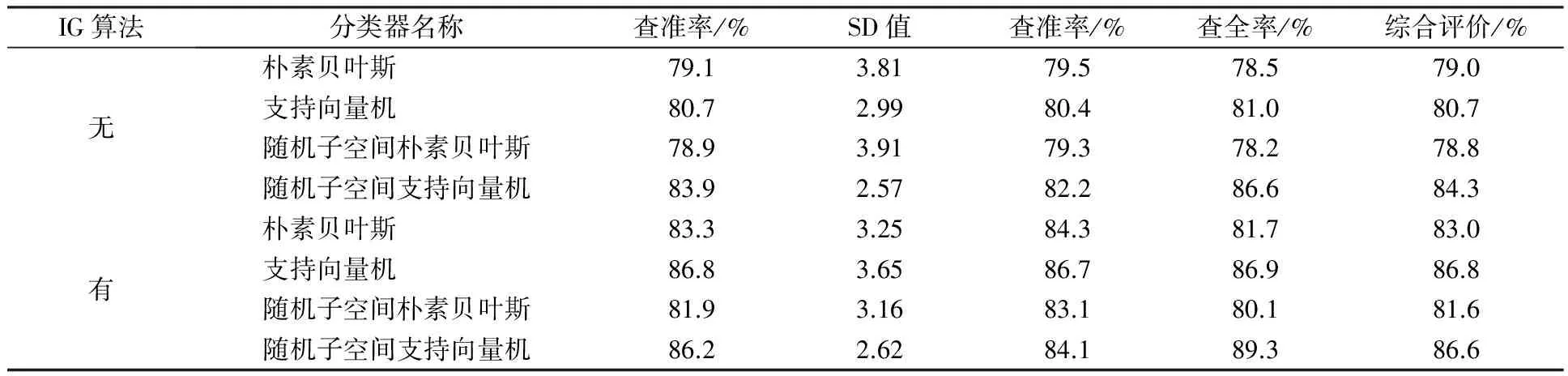
表1 不同方法在数据集上的分类结果表
通过对表1的分析,可以获得以下结果:
1)不使用IG特征选择算法和RS集成学习算法,SVM比NB要获得更好的实验结果.
2)不使用IG特征选择算法,使用RS集成学习算法对SVM算法有较大的提升.
3)不使用RS集成学习算法,使用IG特征选择算法对两类算法都有一定的提升.
4)同时使用IG特征选择算法和RS集成学习算法,并考虑标准差的因素,SVM算法获得了最佳的实验结果.分析这些分类器的ROC Area(接受者操作特征曲线),它表示ROC面积,为[0,1]范围的小数.ROC面积一般大于0.5,越接近1,说明分类器的分类效果越好,如果该值等于0.5,说明分类器完全不起作用.
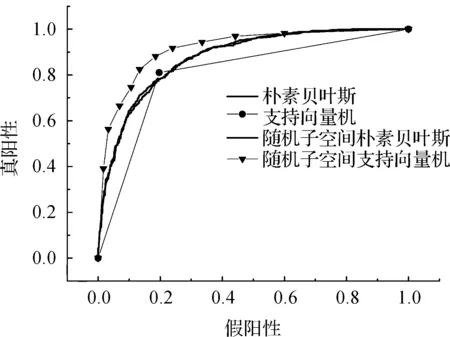
图2 无IG的ROC曲线图Figure 2 ROC graph without IG
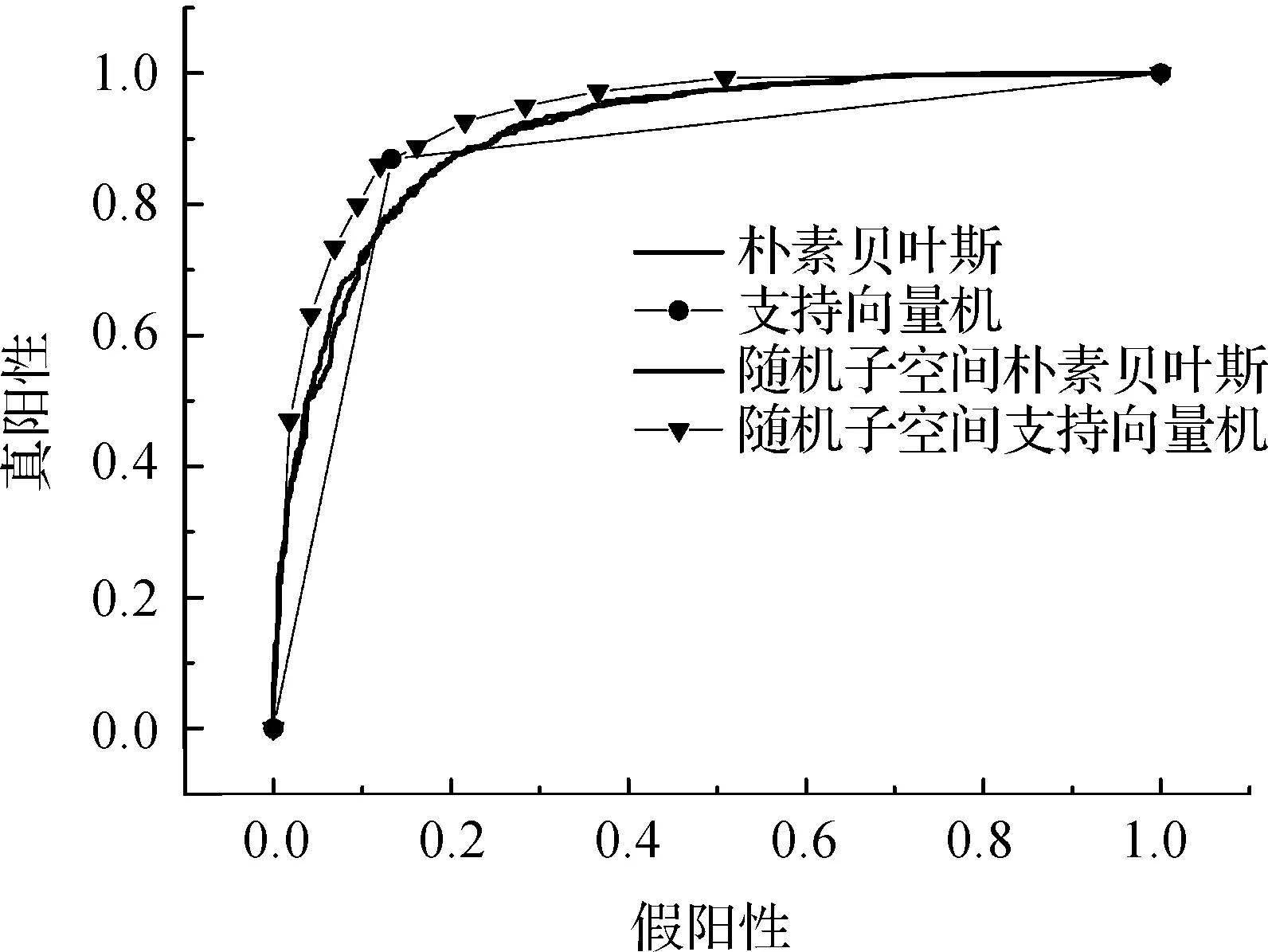
图3 有IG的ROC曲线图Figure 3 ROC graph with IG
图2和图3两幅ROC曲线图中,RS-SVM和IG-RS-SVM的ROC面积均为最高,且RS-SVM的ROC面积为0.915,IG-RS-SVM的ROC面积为0.927,说明IG-RS-SVM分类器的分类效果最佳.
3.2 参数分析
1)SVM核函数
本实验采用三种常用SVM核函数,分别是线性核函数、多项式核函数、RBF核函数.在引入IG特征选择算法的前提下,分别对这三种核函数进行实验,由表2可得,线性核函数的分类准确率跟标准差均为最佳.
表2 不同核函数的分类结果表
Table 2 Classification results of different kernel function table
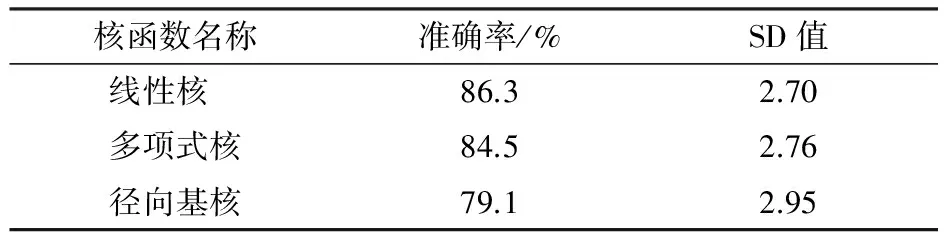
核函数名称准确率/%SD值线性核86.32.70多项式核84.52.76径向基核79.12.95
2)Random Subspace参数
Random Subspace Rate是Random Subspace算法中一个重要参数,它表示子特征空间的比例,选择的比例不同,会直接影响到最终的分类结果.本实验分别选取0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9的比例,评估不同比例下的分类结果.
如图4,线性核函数的分类结果最佳,多项式核函数其次,RBF核函数的分类效果最差.线性核函数和多项式核函数在Rate为0.7取得了较好的分类结果,RBF核函数的分类结果则随着Random Subspace Rate增大而增大.综上所述,在实际应用中推荐使用线性核函数的SVM分类器.

图4 不同比例的分类结果图Figure 4 Classification results of different rates
4 结 语
鉴于RS-SVM在高纬度特征空间下分类效果不理想的问题,本研究引入了IG特征选择算法,大幅度降低了Random Subspace集成学习算法选择的特征空间子集的维度.实验结果表明,相对于其他分类算法,IG-RS-SVM在分类精度和稳定性上都有较大的提升.并且考虑到SVM分类器核函数和Random Subspace Rate对分类结果的影响,比较各个实验结果,表明SVM线性核函数和0.7的Random Subspace Rate获得了较好的实验结果.
电子商务产品质量评论内容不但提供给其他消费者具有极大的参考价值,也有助于质检部门对于电子商务产品质量的舆情监测.通过对电子商务产品评论内容的分析,及时发布预警信息,可以有效避免由产品质量引发的各种问题,为电子商务的健康发展提供保证.
[1] PANG B, LEE L. Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1,2):1-135.
[2] FANG X, WANG S, CAO S. A Chinese Search Approach Based on SCWS[C]//Proceedings of the 9th International Symposium on Linear Drives for Industry Applications. Berlin: Springer,2014:665-671.
[3] 郭庆琳,李艳梅,唐琦.基于VSM的文本相似度计算的研究[J].计算机应用研究,2008,25(11):3256-3258. GUO Qinglin, LI Yanmei, TANG Qi. Similarity computing of documents based on VSM[J].Application Research of Computers,2008,25(11):3256-3258.
[4] NG H T, GOH W B, LOW K L. Feature selection, perceptron learning, and a usability case study for text categorization[C]//ACM SIGIR Forum. Philadelphia:[s.n.],1997:67-73.
[5] 廖炳根,何灵敏,潘益民.基于动态集成的遥感图像分类[J].中国计量学院学报,2011(2):159-163. LIAO Binggen, HE Lingmin, PAN Yimin. Remote sensing images classification based on dynamic ensemble[J].Journal of China University of Metrology,2011(2):159-163.
[6] BRYLL R, GUTIERREZ-OSUNA R, QUEK F. Attribute bagging: improving accuracy of classifier ensembles by using random feature subsets[J].Pattern Recognition,2003,36(6):1291-1302.
[7] 王刚,杨善林.基于RS-SVM的网络商品评论情感分析研究[J].计算机科学,2013,40(11A):274-277. WANG Gang, YANG Shanlin. Study of sentiment analysis of product reviews in interent based on RS-SVM[J].Computer Science,2013,40(11A):274-277.
[8] VAPNIK V N. An overview of statistical learning theory[J].Neural Networks, IEEE Transactions on,1999,10(5):988-999.
[9] 刘倩,崔晨,周杭霞.改进型SVM多类分类算法在无线传感器网络中的应用[J].中国计量学院学报,2013(3):298-303. LIU Qian, CUI Chen, ZHOU Hangxia. Application of a kind of modified SVM multi-class classification algorithm in wireless sensor networks[J].Journal of China University of Metrology,2013(3):298-303.
[10] 汪淑丽.基于支持向量机的无线传感器网络的入侵检测系统[J].传感器与微系统,2012,31(7):73-76. WANG Shuli. Intrusion detection system for WSNs based on SVM[J].Transducer and Microsystem Technologies,2012,31(7):73-76.
Analysis of public opinion on E-commerce product quality based on IG-RS-SVM
YE Jiajun1, FENG Jun2, REN Huan1, ZHOU Hangxia1
(1. College of Information Engineering, China Jiliang University, Hangzhou 310018, China;2. Hangzhou Institute of Calibration and Testing for Quality and Technical Supervision, Hangzhou 310019, China)
The remarks of E-commerce products have a great reference value for the public opinion monitoring of E-commerce product quality. Aiming at the deficiency of reducing the classification accuracy with ensemble learning for high-dimensional datasets, a new algorithm, IG-RS-SVM, was proposed. It was based on Random Subspace, taking SVM as a base learner, and applying the information gain algorithm. By sorting the information gain value of each feature in the feature space, excluding worthless features, and reducing the dimension of feature subspace generated by the Random Subspace algorithm, the efficiency of the SVM classification algorithm was increased. The experimental result shows that the improved algorithm can effectively improve the classification accuracy of remarks.
production review; information gain; random subspace; support vector machine

1004-1540(2015)03-0285-06
10.3969/j.issn.1004-1540.2015.03.007
2015-03-17 《中国计量学院学报》网址:zgjl.cbpt.cnki.net
国家自然科学基金重大专项项目(No.61027005).
叶佳骏(1990- ),男,浙江省余姚人,硕士研究生,主要研究方向为算法优化与数据挖掘.E-mail:254525738@qq.com 通讯联系人:周杭霞,女,教授.E-mail:zhx@cjlu.edu.cn
TP391.1
A
