基于deep learning的语音识别
2015-02-21张炯陶智勇
张炯,陶智勇
(武汉邮电科学研究院 湖北 武汉 430074)
基于deep learning的语音识别
张炯,陶智勇
(武汉邮电科学研究院 湖北 武汉 430074)
针对目前智能计算机及大规模数据的发展,依据大脑处理语音、图像数据方法的deep learning技术应运而生。传统的语音识别技术对特征筛选的人工技能要求高,而且准确率低。deep learning技术是应用于音频信号识别,模仿大脑的语音信号学习、识别的模式。在音频信号处理的过程中,运用deep learning进行音频数据的特征提取和训练,将大幅度提高音频信号识别的准确性。
音频识别;信号处理;deep learning;智能计算机;特征提取
众所周知,人类在识别中英文语音并理解语义之前,都要经过对汉字及英文的字形、发音和语义的学习过程。在这个学习训练过程中,大脑将所有文字的字形、发音和语义存储在大脑的一个特定地方(大多数学者称之为心理词典)。并且,我们的大脑对于接收的信号,设置了一个限制,超过限制范围的信号,大脑就无法接收并使之进入下一个处理环节。对于接收到的信号,大脑经过识别将其与存在大脑皮层中语义最相近的文字字形或发音相匹配,找到它的语义[4]。Deep learning方法正是参照大脑处理语音信息的方式,通过一系列的算法和模型利用计算机仿真人脑对语音判断和识别来进行音频数据处理的过程。可以预见,如果将语音、图像的数据处理进行整合,那么用计算机制作出真正的智能大脑在未来也是同样可以实现的。本文将介绍如何将deep learning深度学习方法运用于音频识别,并大幅度提高音频识别的准确性。
1 语音识别过程
首先,我们要了解语音识别的关键步骤。语音识别的关键步骤为:对输入的语音信号进行预处理、提取特征参数并处理特征参数,为每一个词条创建一个参考模板,并保存为模板库;在识别阶段,语音信号经过相同通道获取语音参数,从而获取测试模板;之后将测试模板与参考模板进行遍历逐一比较,并在某种判别规则下,获得最佳匹配的参考模板作为识别结果[6]。
用原理图表示为:
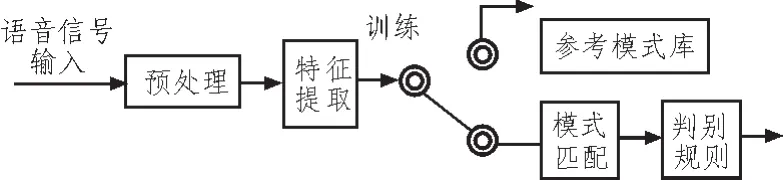
图1 语音识别系统原理图Fig.1 Diagram of recognition system of speech
语音识别结果的好坏,重点在于特征提取及其后的特征训练和参考模式库的建立。语音识别区别于图像等数据处理,语音识别的数据量大,特征形态复杂。传统的语音识别技术的特征训练采用混合高斯模型(GMM)[1],通过简单的单层次建模方法,通过稀疏算法对特征进行提取、整理和分类,进而得出参考模式库。这种处理方法又称为浅层网络分析方法,并曾一度在数据处理领域处于垄断地位。但由于它是单一的层次结构(内含一个单隐层,即训练层),因此这种方法无法反映出所提取的特征的状态空间分布,且由于所有特征的特性都在一个网络层次上处理,数据经过输入层进入训练层和数据从训练层进入输出层的过程中,会存在不可避免的数据丢失,因此这种算法对于特征提取的准确性要求很高,进而对于特征提取的人工技能要求很高,通常需要有丰富经验的人员才能尽可能的减少特征提取带来数据处理麻烦,因此其准确率不高[3]。
2 deep learning
Deep learning(又称DL或DNN)是一种机器学习方法。机器学习处理图像、语音信号的思路为通过传感器获得数据-预处理-特征提取-特征选择-推理、预测、识别,其示意图如图2所示。

图2 机器学习过程Fig.2 Process of machine learning
中间三部分统称为特征表达,好的特征表达对于最终算法的准确性起着至关重要的作用。传统的识别方式在这一部分要耗费大量的人力来进行特征提取工作,而且特征能否提取好,还要看经验和运气。能否用算法来取代这一部分人工,并且保证特征提取的准确性呢?答案是肯定的,deep learning就是这样一种工具。
Deep learning是一种算法,它借助大量的计算机处理器通过并行计算的方式处理大量的数据,这种算法模仿人脑神经网络结构处理信息的方法,进行数据处理。采用deep learning最直观也是最著名的例子是2012年6月《纽约时报》披露的Google Brain项目。这个项目是由斯坦福大学的机器学习教授Andrew Ng和在大规模计算机系统方面的世界顶尖专家Jeff Dean共同主导,用16 000个CPU Core的并行计算平台训练一种称为 “深度神经网络”(DNN,Deep Neural Networks)的机器学习模型(内部共有10亿个节点)。这一网络虽然不能跟人类的神经网络(人脑中有150多亿个神经元,互相连接的节点,即突触数量更是数不胜数)相提并论[2]。但是,该成果的发布,意味着计算机可以像人一样学习,我们只需要将大量的数据输入计算机,计算机就会自动进行整理和学习,并根据学习结果,对数据输入做出相应行动。
人类大脑的神经网络处理信息方式是多层次的,即低层次提取一部分基层特征,进行处理后传给高一层次,高一层次处理后,再传给更高一层次。这样就实现了特征表述的一层层抽象化,高层次更能表现语义和意图,因而更容易进行分类。Deep learning中deep就是这种层次的表现。浅层学习模型也称为shallow learning。
3 基于deep learning的语音识别
基于deep learning的语音识别技术正是参考人脑神经的这种多层次结构,创建出多层次的训练结构模型,低层次的分析训练结果作为高一层次的特征输入,进一步进行特征训练,其结果再作为下一层次的特征输入,如此往复,进行多层次的特征训练,提取特征的多维度信息,每一层次的统计学习过程,对特征一步一步抽象化,直至顶层的高度抽象化,可以方便做出数据分类和判断。因此这种方式更能反映数据的本质,并且更容易实现并行处理像语音识别这样的大数据分析。
从上面的描述中,可得知,deep learning处理数据的模式是分层进行,那么怎么确定语音信号的特征结构呢?可以依据图片的特征结构分解模式,将一段语义分解为若干语句,一个语句分解为若干词汇,一个词汇分解为若干字,而一个字又可以分解为音位、频率、波幅等特征。目前常用的几种语音特征参数为LPCC、LPCC+、△LPCC、MFCC、MFCC+、△MFCC[5]。当然,这些特征参数挖掘还有很大的可扩展性,这里不作详述。
Deep learning处理语音的多层次结构中,每层的特征处理采用非监督模式,即在每层之间不设置特征分类机制,只是设置目标预期结果,之后由计算机自己去学习[1]。最能表现非监督学习强大的例子是西洋双棋游戏,它通过一系列的计算机程序,让计算机通过非监督的学习方式一遍遍自己玩游戏,并逐渐发展到比在这个游戏上玩的最好的人还要好。当然,进行语音识别的最终目的是特征分类,从而在接受待识别语音时,能够让计算机基于参考模型库中的使用频率、相似情况等表达出最接近人脑的语音识别结构。因此deep learning在语音特征各层非监督学习的基础上,在各层之间采用监督的学习方式,在最顶层设置分类机制,之后从特征输出结果的顶层向下,一层层计算,并根据计算出的基层特征数据,调整各层的权重系数,从而得出最小数据损失和最接近分类要求的特征结果[2]。
4 结束语
将deep learning用于音频识别,目前在国际上已经获得了长足的进步。微软率先将deep learning运用于语音识别,并在首次测试中获得了相较传统算法33﹪的准确率提升。由此可见,仿真人脑处理语音信号的基于deep learning的语音识别技术不仅是可行的,而且得到的结果是更加准确的。
[1](法)斯坦尼斯拉斯·迪昂著.脑的阅读—破解人类阅读字谜[M].周加仙,等译.北京:中信出版社,2011.
[2]刘雅琴,智爱娟.几种语音识别特征参数的研究[J].计算机技术与发展,2009(12):67-70.LIU Ya-qin,ZHI Ai-juan.Several studies of Speech Feature[J].Computer Technology and Development,2009(12):67-70.
[3]Frank Seide,Gang Li,Dong Yu.Conversational Speech Transcription Using Context-Dependent Deep Neural Networks[C]//Florence,Italy,2011.
[4](德)赫尔曼·哈肯.协同学—大自然构成的奥秘[M].上海:上海译文出版社,2001.
[5]胡振,傅昆,张长水.基于深度学习的作曲家分类问题[J].计算机研究与发展,2014(9):15-17.HU Zhen,FU Kun,ZHANG Chang-shui.Based on the classification composer depth study[J].Computer Research and Development,2014(9):15-17.
[6]Abdel-Hamid,O,Deng L,Yu.D.Exploring convolutional neural network structures and optimization for speech recognition[C]//Interspeech,2013.
Recognition of speech based on deep learning
ZHANG Jiong,TAO Zhi-yong
(Wuhan Research Institute of Posts and Telecommunications,Wuhan 430074,China)
In view of development of computers and big data,the technology of deep learning on the basis of voice and image processing come into being.Traditional technology of speech sounds demands high quality of personal skills,and it’s accuracy is lower,applying deep learning to the recognition of speech sounds,imitating the speech learning and recognition of the brain.Utilizing deep learning to filter and train the features,during the process of voice analysis,will rise the accuracy of the recognition of speech massively.
recognition of speech;signal processing;deep learning;intelligent computer;feature extraction
TN912.3
:A
:1674-6236(2015)18-0072-02
2014-11-17稿件编号:201411117
张 炯(1987—),女,湖北枣阳人,硕士研究生。研究方向:数字通信。
