基于多维特征权重的虚假评论识别方法
2015-02-20皇苏斌修宇赵森严汪千松
皇苏斌,修宇,赵森严,汪千松
安徽工程大学计算机与信息学院安徽工程大学计算机应用技术重点实验室,安徽 芜湖 241000
基于多维特征权重的虚假评论识别方法
皇苏斌,修宇,赵森严,汪千松
安徽工程大学计算机与信息学院
安徽工程大学计算机应用技术重点实验室,安徽 芜湖 241000
[摘要]在线商品评论是消费者网购决策的重要依据,利益的驱动使得越来越多的网络虚假评论呈现在消费者面前。针对此问题,提出一种多维特征权重的在线虚假评论识别方法。首先,从网购信息有用性角度出发,在商品、评论者和评论内容3个维度中选取9个对评论属类语义贡献大的特征。然后,基于Fisher准则,运用赋予权重的特征构建用于识别虚假评论的方法。试验结果验证了基于多维特征权重的虚假评论识别方法的有效性:多维特征权重方法的准确率、查全率和综合分类率均高于Logistic回归方法和自适应聚类方法
[关键词]虚假评论;特征选择;特征权重;Fisher准则 在线商品评论作为短文本的一种[1,2],具有稀疏、正常评论与虚假评论分布不均衡等特点。现有虚假识别方法侧重于相关特征的选取,多数研究在识别分类上直接使用特征值作为分类依据[3,6~10],忽略已选特征信息对虚假评论识别的具体贡献权重,使得评论分类结果倾向于正常评论而忽视虚假评论[4],导致分类的准确率、查全率不高,不能满足实际需求。事实上,特征权重能够反映该特征对标识评论的贡献度,体现评论间的区分能力。因此,如何选择用于虚假评论识别的评论特征以及赋予其权重对在线虚假评论识别有着重要的意义。
虚假评论识别与传统文本分类有相通之处,但也存在评论文本自身的特点。总体来讲,按特征的选择现有虚假识别方法可以分为基于评论内容的识别和基于评论行为的识别2种。
1)基于评论内容的识别方法。JINDAL等[5]率先提出垃圾意见检测,并使用Logistic模型对垃圾评论进行识别[6]。邓莎莎等[7]从心理学角度对评论内容进行研究,提出包括11种欺骗语言线索的3类欺骗特征,实现对虚假评论的识别,并对不同欺骗组合特征的分类效果进行验证。任亚峰等[3]认为真实评论和虚假评论在情感极性和语言结构上存在差异,提出利用遗传算法对语言结构及情感极性特征进行选择优化,然后对优化的特征采用无监督硬、软聚类算法进行虚假评论识别。
2)基于评论行为的识别方法。虚假评论的产生通常伴随着一些特有的行为特征,而这些特征有助于识别评论中的欺骗内容。LIM等[8]将评论欺骗行为分为2大特点:欺骗者通常仅关注于某一种或一类商品,并在这些商品评论中最大化发挥他们的评论影响力;欺骗者的评分行为往往和其他正常用户有很大的区别,因此定义了4种不同类型的欺骗行为模型。宋海霞等[9]借助评论者的行为特征,对虚假评论进行识别,根据评论数据定义自身基本特征,并计算与其他评论之间的关联性特征,通过自适应聚类算法实现对虚假评论的检测。
然而,上述研究侧重于特征或方法的选择,未考虑特征本身对评论属类的贡献程度,为此,笔者提出一种基于多维特征权重的虚假评论识别方法。
1多维特征选择
商品评论所表达的属类语义信息与商品本身、评论者和评论内容密切相关。笔者以网购信息的有用性为出发点,基于特征对虚假评论分类的贡献度,从商品、评论者和评论内容3个维度中选择9个贡献大的特征来标识评论的分类,具体如下:
1.1商品维度
1)商品价格(F1) 商品价格越高,欺诈双方经济成本和风险程度也随之增加,因此相对于价格较高的商品,虚假评论更多存在于价格较低的商品评论之中[11]。
2)商品属性(F2)用户只有在使用商品之后才会获得切身体会,包括对商品特征、性能等属性的使用感受描述。如果一条评论中没有或较少涉及对商品属性的描述,那么该评论为虚假评论的可能性较大。
1.2评论者维度
1)评论者信誉(F3)一般情况下,信誉高的用户发表的评论比信誉低的更具有可信性。
2)是否匿名评论(F4) 实名用户发布虚假评论后被发现的风险比匿名用户要高,因此虚假评论更多存在于匿名评论中。
1.3评论内容维度
1)评论长度(F5)真实评论者一般不愿意评论或者给予简单的评论,而虚假评论者为取到夸大或诋毁的效果,往往较冗长地描述商品质量或服务。因此,篇幅较长的评论为虚假评论的可能性较大[3]。
2)正面情感词(F6)和负面情感词(F7)虚假评论者为了赞扬或贬低某一商品,会尽可能地增加正面或负面情感词,以达到夸大或诋毁的作用。如果一条评论中过多出现正面或负面情感词,则该评论为虚假评论的可能性较大。
3)品牌名称(F8) 评论中反复出现品牌名称,以此来提高该条评论的可信性,则该评论是虚假评论的可能性较高。
4)是否附图评论(F9)用户发布附带商品图片的评论要比直接的文本评论可信性高,虚假评论更多存在于直接文本评论中。
2单个特征的Fisher值
笔者采用Fisher准则来分析各特征对虚假识别的贡献权重,采用单个特征的Fisher值作为计算准则[12]。
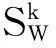

(1)

(2)
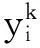
单个特征的Fisher准则表示为:
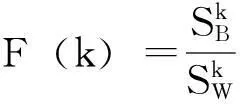
(3)
F(k)称为第k维的Fisher值。如果某一维特征在样本集上的F(k)值越大,则说明该维特征在类别区分上作用越强。
3权重计算及特征向量化

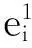
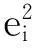
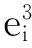
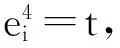


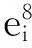

笔者将虚假评论识别看作一个二分类问题,形式化定义为:假设预处理评论类型集为D={d0,d1},其中,d0表示正常评论,称为负类,d1表示虚假评论,称为正类,需进行分类的评论集为P={p1,p2,…,pn},每条评论由特征集Fi(i=1,2,…,9)组成。
对此,根据式(1)~(3),计算评论中单个特征的Fisher值F(j):


(4)

最后,结合特征权重和特征值将评论样本向量化为表1所示。
4试验
4.1试验设置
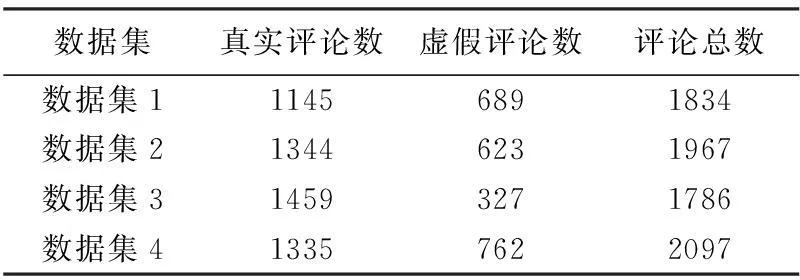
表2 实验数据集
采用专家标注方法,选择Alexa排名靠前的国内2家电子商务平台(淘宝:http://www.taobao.com;京东商城:http://www.jd.com),分别从中抓取5000条手机评论相关信息,分为4组每组2500条,包含8个字段的内容:评论者姓名、商品详情、商品价格、评论者信誉、评论内容、评论时间、是否匿名评论和是否附图评论。选择20名专家并将其分为5组,分别对4组数据集进行真实评论与虚假评论的人工标注,从5组标注结果中选取4组结果相同的评论作为实验数据集,最终取得真实评论5283条,虚假评论2401条,具体分布如表2。
采用中科院计算技术研究所研制的ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)[13]汉语语法分析系统对数据集的评论内容和商品详情进行分词处理,去除停用词、虚词和标点符号等;利用知网HowNet情感词典[14],除去一些生僻词,加入一些网络流行新词,构建评论情感词词典;采用哈工大信息检索研究中心同义词词林扩展版[15]构建商品属性、品牌名称同义词词典。
4.2试验结果分析
采用文本分类中通用分类性能评估指标准确率PR(Precision)、查全率RE(Recall)和综合分类率F1来分析引入特征权重方法后的评论样本分类效果。对于评论类型集li(i=0,1),假设xi为第i类的评论样本总数,yi为分类中正确被分到第i类的评论文本数,zi为分类中实际被分到第i类的评论文本数,则对于第i类评论样本的分类性能评估指标的计算方法如下:
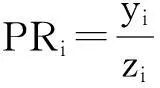
(6)
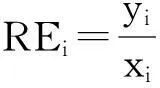
(7)

(8)
笔者采用宏平均对分类效果进行全局评价,具体如下:
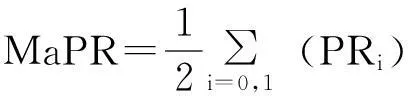
(9)
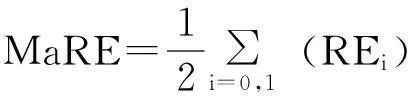
(10)

(11)

图1 分类效果比较
对4组试验数据集进行特征权重计算和向量化处理,其中每组数据集的行代表评论样本,列代表分类特征。在Matlab环境下使用SVM分类器对多维特征权重方法进行分类测试,测试方法采用循环交叉试验方法,轮流将其中3组作为训练集,另外1组作为测试集,共进行4次训练和测试,取4次试验结果的平均值。然后以文献[5]中的Logistic回归模型和文献[9]中的自适应聚类方法作为对比试验。具体试验结果如图1所示。
从图1中可看出,多维特征权重方法的准确率、查全率和综合分类率均高于Logistic回归方法和自适应聚类方法,原因分析如下:在评论样本中,正常评论与虚假评论分布是不均衡的,这种不均衡现象对分类效果的影响体现为在不同批次的分类中分类效果会出现较大的波动。笔者提出的多维特征权重方法以网购信息的有用性为基础,多维度选取对评论分类标识重要的特征,并计算特征的权重,运用赋予权重的特征构建虚假评论识别分类的决策信息,从而实现待分类评论样本分布的优化,更好地反映特征对虚假评论分类的重要程度。特征权重方法综合考虑了各特征信息对全局的决策能力,进一步优化特征对评论样本划分的一致性程度,进而提高虚假评论分类的准确率、查全率和综合分类率。
5结语
考虑多维特征信息对虚假评论分类的贡献度,提出了一种基于多维特征权重的虚假评论识别方法。在特征的选取上,从网购信息的有用性角度出发,多维度的选取9个对评论分类标识重要的特征,在特征权重的计算上,综合考虑特征信息的决策能力,将赋予权重的特征运用于构建虚假评论识别分类的决策信息中。与已有的方法相比,该方法可以优化评论样本的分布,提高虚假评论分类的准确率、查全率和综合分类率。未来的工作将研究网购用户行为与虚假评论的关系以及店铺虚假销量的识别。
[参考文献]
[1]林煜明,王晓玲,朱涛,等.用户评论的质量检测与控制研究综述[J].软件学报,2014,25(3):506~527.
[2]黄婷婷,曾国荪,熊焕亮.基于商品特征关联度的购物客户评论可信排序方法[J].计算机应用,2014,34(8):2322~2327,2341.
[3]任亚峰,尹兰,姬东鸿.基于语言结构和情感极性的虚假评论识别[J].计算机科学与探,2014,8(3):313~320.
[4]林智勇,郝志峰,杨晓伟.不平衡数据分类的研究现状[J].计算机应用研究,2008,25(2):332~336.
[5]Jindal N,Liu B.Review spam detection[A].Proceedings of the 16th International Conference on World Wide Web[C].USA:ACM,2007:1189~1190.
[6]Jindal N,Liu B.Analyzing and Detecting Review Spam[A].Proceedings of the 7th IEEE International Conference on Data Mining[C].USA:IEEE Computer Society,2007:547~552.
[7]邓莎莎,张朋柱,张晓燕,等.基于欺骗语言线索的虚假评论识别[J].系统管理学报,2014,23(2):263~270.
[8]Lim E,Nguyen V,Jindal N,et al.Detecting product review spammers using rating behabiors [C].Proceedings of the 19th ACM International Conference on Information and Knowledge Management,ACM,2010.
[9]宋海霞,严馨,余正涛,等.基于自适应聚类的虚假评论检测[J].南京大学学报(自然科学版),2013,49(4):433~438.
[10]李霄,丁晟春.垃圾商品评论信息的识别研究[J].现代图书情报技术,2013,299(1):63~68.
[11]WEIJIA YOU,LU LIU,MING XIA,et al.Reputation inflation detection in a Chinese C2C market [J]. Electronic Commerce Research and Applications, 2011, 10:510~519.
[12]王飒,郑链.基于Fisher准则和特征聚类的特征选择[J].计算机应用,2007,27(11):2812~2814.
[13]ICTCLAS[EB/OL].http://ictclas.nlpir.org/,2014-09-20.
[14]HowNet[EB/OL]. http://www.keenage.com/html/c_index.html,2014-09-20.
[15]HIT-CIR Tongyici Cilin (Extended)[EB/OL]. http://ir.hit.edu.cn/demo/ ltp/Shari- ng_Plan.htm,2014-09-20.
[编辑]洪云飞
[引著格式]皇苏斌,修宇,赵森严,等.基于多维特征权重的虚假评论识别方法[J].长江大学学报(自科版),2015,12(16):34~38.
29 Collaborative Recommendation Method Based on Social Network
Wang Qiansong, Jiang Sheng, Wang Zhongqun(AnhuiPolytechnicUniversity,Wuhu241000)
Abstract:In consideration of the problem of lower recommendation precision in the traditional collaborative filtering recommendation algorithm, a new collaborative recommendation method is proposed based on social network.The similarities and credibility of users are integrated in the social network.Firstly, the similarities between the users are calculated based on the ratings, and then the credibility of users are calculated based on direct and indirect credibility.Finally, the similarities of user rating and the credibility of user’ recommendation are integrated to get the weights of users’ recommendations and get the nearest neighbor set and provide a more accurate recommendation.The experimental results show that the new method can improve the accuracy of recommendation.
Key words:social network; collaborative filtering; recommendation accuracy; credibility; recommendation weight
[文献标志码]A
[文章编号]1673-1409(2015)16-0034-05
[中图分类号]TP391
