基于遗传算法的多模态视频场景分割算法
2015-02-16赵杰雪丰洪才
赵杰雪,丰洪才,杨 琳
(武汉轻工大学 数学与计算机学院,湖北 武汉 430023)
基于遗传算法的多模态视频场景分割算法
赵杰雪,丰洪才,杨 琳
(武汉轻工大学 数学与计算机学院,湖北 武汉 430023)
视频场景分割可缩短检索时间,提高检索的准确度,已成为视频领域的研究热点之一。为了实现快速、准确的视频场景分割,提出了一种基于遗传算法的多模态视频场景分割算法,根据多模态特征融合的思想提取视频关键帧中不同模态的物理特征,对镜头间同种模态数据的相似度和不同模态数据的相关度进行融合,并计算出不同镜头之间的相似度,构造镜头相似度矩阵,利用遗传算法实现视频场景的分割。实验数据验证了该算法对视频场景有较好的分割效果,查全率和查准率分别达到86.9%和87.7%,F值达到87.3%。
场景分割;多模态;遗传算法;相似度融合;镜头相似度矩阵
视频场景分割是视频检索中关键性的一步,可缩短检索时间、提高检索的准确度,已成为视频领域的研究热点之一。国内外学者进行了大量视频场景分割方法的研究,取得了一定程度上的突破。如文献[1]提出的基于帧熵和SURF(speeded up robust features)特征的滑动窗场景检测方法,该方法简单、效率高,对电影视频分割效果较好,但其只采用视觉特征,忽视了视频多种模态数据之间存在互补关系,因此对于动画等一些视频内容高强度变化的视频效果不佳,不具有通用性。此外,还有一些场景分割方法虽然利用了多种模态特征融合的思想,但是只针对某一特定类型的视频,如新闻视频[2]、体育视频[3]、电影视频[4]等,该方法分割准确度较高,但通用性较差,且需要特定领域的先验知识。
遗传算法是全局优化算法,其计算花费时间少、鲁棒性高、可扩展性强,且具有较好的收敛性。因此针对文献[1]中场景分割算法通用性低、局限性强的问题,笔者结合多模态特征融合的思想将遗传算法应用到视频场景分割的领域当中,提出了一种基于遗传算法的多模态视频场景分割算法,首先对视频的3种底层特征进行提取,并度量镜头间的相似度,构造出镜头相似度矩阵;然后结合遗传算法实现视频场景的分割,并对过分割视频场景进行合并。实验验证了该算法对视频场景有较好的分割效果,查全率和查准率分别达到86.9%和87.7%,F值达到87.3%。
1 底层特征提取和镜头相似度度量
1.1 图像特征向量
笔者采用文献[5]中对视频底层特征提取的方法,分别提取出图像特征向量H、音频特征向量A及文本特征向量T。镜头关键帧的图像特征向量H的表达式如式(1)所示:
H=(h0,h1,h2,…,h71)
(1)
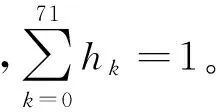
1.2 音频特征向量
一个镜头包含一段音频序列,该镜头的音频特征向量A的表达式如式(2)所示:
A=(En,Zn,C1,C2,…,C12)
(2)
式中:En为短时平均能量;Zn为过零率ZCR;Cτ为MFCC系数,τ=1,2,…,12。
1.3 文本特征向量
一个镜头的文本特征向量T为:
T=(ω1(d),ω2(d),…,ωk(d),…,ωn(d))
(3)
式中:n为视频中关键词的总数;ωk(d)为词条tk在文档d中所占权重。
1.4 镜头间同种模态相似度计算
(1)采用直方图相交法计算镜头Shoti与镜头Shotj图像特征之间的相似度。
(4)
(2)利用欧氏距离计算镜头Shoti与镜头Shotj音频特征之间的相似度。
SimA(i,j)=
(5)
(3)利用余弦距离计算镜头Shoti与镜头Shotj文本特征之间的相似度。
(6)
由式(4)~式(6)可得镜头Shoti与镜头Shotj之间同种模态数据的相似度Sim′(i,j)为:
Sim′(i,j)=ωHSimH(i,j)+ωASimA(i,j)+ωTSimT(i,j)
(7)
其中,ωH、ωA、ωT分别为镜头间图像、音频、文本相似度分量的权重。
1.5 镜头间不同模态相关度计算
利用张鸿等[6]提出的典型相关性分析法计算镜头Shoti与镜头Shotj不同模态之间的相关度,分别得到图像与音频特征之间的相关度ρH,A(i,j)、音频与文本特征之间的相关度ρA,T(i,j)及图像与文本特征之间的相关度ρH,T(i,j):
(8)
(9)
(10)
由式(8)~式(10)得出镜头Shoti与镜头Shotj之间不同模态数据的相关度Cor′(i,j):
Cor′(i,j)=ωH,AρH,A(i,j)+ωA,TρA,T(i,j)+ωH,TρH,T(i,j)
(11)
其中,ωH,A、ωA,T、ωH,T分别为图像与音频、音频与文本、图像与文本相关度分量的权重。
1.6 相似度与相关度融合
将镜头间同种模态数据的相似度Sim′(i,j)与不同模态数据的相关度Cor′(i,j)进行加性融合得到镜头Shoti与镜头Shotj之间的相似度Cor(i,j),如式(12)所示。
Cor(i,j)=ωSimSim′(i,j)+ωCorCor′(i,j)
(12)
其中,ωSim、ωCor分别为同种模态数据的相似度与不同模态数据的相关度所占权重。
1.7 镜头相似度矩阵
在用遗传算法[7]进行场景分割之前需先计算镜头相似度矩阵(shotsimilaritymatrix,SSM)。为了提高迭代效率,一段一段地进行检测,每一段为100个镜头。这样SSM就是一个100×100的对称矩阵,其值全部初始化为-1,然后根据式(12)计算出不同镜头之间的相似度,并将其保存在矩阵SSM中,如式(13)所示。
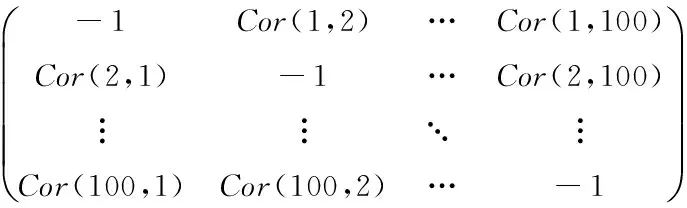
(13)
其中,元素SSMi, j表示镜头Shoti与Shotj之间的相似度值Cor(i,j)(i≠j),其值满足以下特性:0≤Cor(i,j)<1,Cor(i,j)=Cor(j,i)。
2 遗传算法在场景分割中的应用
假设得到的镜头分割结果为:Shot1,Shot2,…,ShotL,其中L为镜头总数,因为每100个镜头作为一段进行检测,所以L应满足条件:L≤100。
2.1 个体编码方案
一段视频中连续L个镜头的集合称之为一个个体。根据镜头相似度矩阵SSM采用二进制编码方式对个体进行编码(I1,I2,…,Ii,…,IL-1),Ii∈{0,1}。个体编码与镜头序列的对应关系如图1所示。
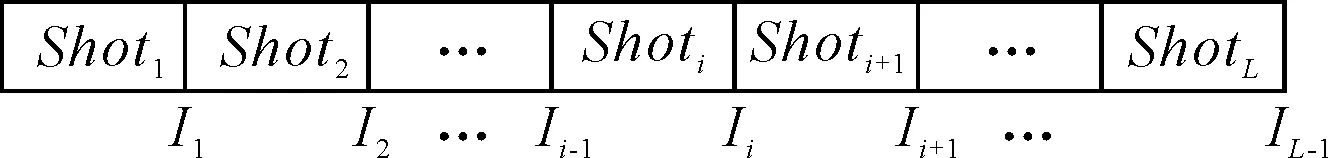
图1 个体编码与镜头序列对应图
Ii∈{0,1}为个体中的一个基因,Ii=0表示镜头Shoti和Shoti+1属于同一个场景;Ii=1表示镜头Shoti和Shoti+1不属于同一个场景。根据镜头相似度矩阵SSM得出个体编码的依据为:如果SSMi,i+1<给定阈值Th(根据多次试验的经验,笔者取Th=0.6),说明镜头Shoti和Shoti+1很有可能不属于同一个场景,就令Ii=1;否则,令Ii=0。于是,个体的编码就是场景划分的表示。
2.2 适应度函数
适应度函数[8]是用于评估个体优劣的指标。笔者以打分的形式衡量个体的适应度,个体得分越高,意味着适应度越高,个体越优,所划分的场景正确率越高。适应度函数定义如下:
(14)

2.3 交叉
采用单点交叉的方法,种群中的个体随机配对,配成对的两个个体以交叉概率Pc相互交换基因,交叉位置M随机产生。经过多次试验,取Pc=0.8,交叉过程如下所示:
交叉前:
PA(I1,I2,…,IM-1,IM,IM+1,…,IL-1)
PB(I′1,I′2,…,I′M-1,I′M,I′M+1,…,I′L-1)
交叉后:
Pnew1(I1,I2,…,IM-1,IM,I′M+1,…,I′L-1)
Pnew2(I′1,I′2,…,I′M-1,I′M,IM+1,…,IL-1)
2.4 变异
变异算子采用基本位变异,即随机选取一个基因以变异概率Pm对其进行取反操作,变异位置M是随机产生的,将IM取反变异成1-IM。经过多次试验,取Pm=0.1,变异过程如下所示:
变异前:
Pnew(I1,I2,…,IM-1,IM,IM+1,…,IL-1)
变异后:
Pnew(I1,I2,…,IM-1,1-IM,IM+1,…,IL-1)
2.5 选择
选择操作采用轮盘赌选择法[9-10]与最优保存策略[11]相结合的方式,具体操作步骤如下:
(1)用轮盘赌选择法从当前种群中选择两个个体直接复制到下一代种群,其余个体经过交叉和变异操作之后产生相同数量的新个体,新个体与之前选出来的两个个体一起构成新的种群。
(2)从步骤(1)产生的新种群之中找到适应度最高和最低的个体。
(3)将新种群中最高的适应度与截止到目前最高的适应度作比较,若前者大于后者,将前者所对应的个体作为截止到目前适应度最高的个体;否则,用截止到目前适应度最高的个体替换新种群中适应度最低的个体。
3 视频场景分割
根据镜头相似度矩阵得到个体的初始编码,称为I(1),而I(1)不一定就是正确划分场景的个体,因此由个体I(1)经过变异、交叉操作得到16个个体的初始种群,利用遗传算法不断迭代,产生更多新个体,向着最优解方向进化直至达到终止代数,找到适应度最高的个体,根据该个体的编码确定场景边界。
3.1 算法描述
利用遗传算法进行视频场景分割的具体实施步骤如下:
输入:根据镜头相似度矩阵SSM得到个体初始编码I(1):(I1,I2,…,IL-1)。
输出:场景边界scene[L][2]。
变量说明:sceneCount表示场景计数器,用于记录场景的个数;scene[L][2]用于记录场景的边界;scene[k][0]记录的是场景k+1开始的镜头编号;scene[k][1]记录的是场景k+1终止的镜头编号(0≤k (1)将个体I(1)按照上述变异方法,取Pm=1变异得到新个体I(2)。 (2)将I(1),I(2)按照上述交叉方法,交叉得到两个新个体I(3),I(4),由I(1),I(2),I(3),I(4)交叉得到4个新个体I(5),I(6),I(7),I(8),再由I(1),I(2),…,I(8)这8个个体交叉得到8个新个体I(9),I(10),…,I(16),并将I(1),I(2),…,I(16)这16个个体作为初始种群。 (3)按照式(14)算得种群中每一个个体的适应度值。 (4)判断当前迭代次数是否达到50次(根据多次试验,算法在迭代到40次时接近收敛,因此将终止迭代数定为50代),若未达到50次,则按照上述选择方法产生下一代种群,并返回至步骤(3);否则,输出当前代中适应度最高的个体。 (5)初始化。将sceneCount初始化为0,scene[sceneCount][0]初始化为1,i初始化为1。 (6)针对由步骤(4)中得到的适应度最高个体的编码,若i=L-1,则跳转至步骤(8);否则判断Ii是否等于1,若Ii=1,说明镜头Shoti是该场景的结束镜头,将i写入数组scene[sceneCount][1],sceneCount自增,将i+1作为下一个场景的起始镜头写入scene[sceneCount][0]。 (7)令i=i+1,进行下一个基因的判断,返回至步骤(6)。 (8)将最后一个镜头L写入scene[sceneCount][1],sceneCount=sceneCount+1,场景分割完毕,算法结束。 3.2 过分割处理 通过参阅多篇文献,得知一个真正场景包括的镜头数应当不小于3个[12]。若经上述演化之后存在镜头数小于3的场景,则属于过分割,应对其进行合并。笔者定义两个镜头类CA,CB之间的相似度为: (15) 其中,i和j分别代表镜头Shoti和镜头Shotj。将经过演化之后得出的场景都作为镜头类,找出过分割的场景,根据式(15)计算出该镜头类与前、后镜头类之间的相似度,与相似度较大的那个镜头类进行合并,直到没有过分割的场景为止。 为了检验笔者算法,选择4种不同种类的视频片段进行测试,分别是CCTV新闻联播(记为NNB)、电影《阿凡达》片段(记为Avatar)、动画《猫和老鼠:绿野仙踪》片段(记为TAJ)及NBA篮球比赛片段(记为NBA)。由于场景的划分没有统一的标准,不同的人分割结果可能不同,因此实验中通过多人商讨共同确定实验素材中场景的分割点即起始边界,以保证场景划分的正确性。实验素材涵盖了所有类型的场景,具有一定的代表性,总时长约135′51″,共195 535帧,1 266个镜头,107个场景,视频片段详细信息如表1所示。 表1 视频片段详细信息 使用查全率(Recall)、查准率(Precision)及综合度量指标F检测算法的性能,定义如下: (16) (17) (18) 式中:nc为检测正确的场景个数;nm为检测时漏掉的场景个数;nf为检测错误的场景个数。 将笔者算法与文献[1]算法进行比较,进而说明笔者算法性能的优劣。实验结果如表2所示。 表2 笔者算法与文献[1]算法结果对比 从表2中可以看出,在不同类型的视频中,笔者算法的查全率和查准率总的来说较文献[1]的算法均有明显提高,综合度量指标F值也相对较高。实验中所选取的4种不同类型的视频片段均取得了不错的效果,其中分割最好的是新闻视频,F值高达98.0%,查全率和查准率分别比文献[1]的算法提高了9.1%、13.5%;体育视频和电影的场景分割效果比新闻视频要差一些,F值分别为92.7%和86.6%;分割效果最差的是动画,F值为75.0%,比文献[1]提高了12.4%。可见,笔者算法与文献[1]的算法相比,场景分割的效果更好,且具有一定的通用性。 笔者通过对视频多模态底层特征的提取,将同种模态数据的相似度和不同模态数据的相关度融合得出镜头间的相似度,利用遗传算法实现了对视频场景的快速分割,并且对过分割的场景做了相应的合并处理,取得了较好的实验效果。多模态特征的融合对缩减“语义鸿沟”的作用非同小可,遗传算法的引入使得分割准确度更高、通用性更强。 [1] BABER J, AFZULPURKAR N, SATOH S. A framework for video segmentation using global and local features[J]. International Journal of Pattern Recognition and Artificial Intelligence, 2013, 27(5):13550071-135500729. [2] 刘嘉琦,封化民,闫建鹏.基于多模态特征融合的新闻故事单元分割[J].计算机工程,2012,38(24):161-165. [3] 华漫.基于语义的体育视频场景分割方法[J].计算机工程,2010,36(15):206-207. [4] 郭小川,刘明杰,王婧璐,等.基于频繁镜头集合的视频场景分割方法[J].计算机应用与软件,2011,28(6):116-120. [5] 杨亭,丰洪才,金凯,等.基于多模态融合和竞争力的视频场景分割算法[J].武汉理工大学学报(信息与管理工程版),2014,36(6):759-763. [6] 张鸿,吴飞,庄越挺,等.一种基于内容相关性的跨媒体检索方法[J].计算机学报,2008,31(5):820-826. [7] YANG H, YI J, ZHAO J, et al. Extreme learning machine based genetic algorithm and its application in power system economic dispatch[J]. Neurocomputing, 2013,102(15):154-162. [8] NGOC T A, HIRAMATSU K, HARADA M. Optimizing the rule curves of multi-use reservoir operation using a genetic algorithm with a penalty strategy[J]. Paddy and Water Environment, 2014,12(1):125-137. [9] GUPTA N, SHEKHAR R, KALRA P K. Congestion management based roulette wheel simulation for optimal capacity selection:probabilistic transmission expansion planning[J]. International Journal of Electrical Power and Energy Systems, 2012,43(1):1259-1266. [10] HWANG S F, HSU Y C, CHEN Y. A genetic algorithm for the optimization of fiber angles in composite laminates[J]. Journal of Mechanical Science and Technology, 2014,28(8):3163-3169. [11] 田景文,孔垂超,高美娟.一种车辆路径规划的改进混合算法[J].计算机工程与应用,2014,50(14):58-63. [12] 印勇,王旭军.基于主色跟踪和质心运动的视频场景分割[J].计算机应用研究,2010,27(4):1563-1565. ZHAO Jiexue:Postgraduate; School of Mathematics and Computer Science, Wuhan Polytechnic University, Wuhan 430023, China. [编辑:王志全] GA-based Multimodal Video Scene Segmentation Algorithm ZHAOJiexue,FENGHongcai,YANGLin Video segmentation based on scene can not only shorten the time of search but also improve the accuracy of retrieval. It has become one of the hot researches in the video field. In order to cut apart video scenes rapidly and accurately, a multimodal segmentation algorithm under genetic algorithm was presented. In light of the idea of different features fusion, it extracted physical characteristics of different modes from video key frame, integrated the similarity of same modal data and correlation of different modal data among shots to get the similarity, and the shot similarity matrix was constructed. The genetic algorithm was used to complete segmenting video scenes. The experiments suggest that the proposed method can segment video scenes effectively; recall rate and precision can reach 86.9% and 87.7%; the F value is up to 87.3%. scene segmentation; multimodal; genetic algorithm; similarity fusion; shot similarity matrix 2015-07-01. 赵杰雪(1993-),女,安徽亳州人,武汉轻工大学数学与计算机学院硕士研究生. 湖北省自然科学基金资助项目(2009Chb008, 2010CDB06603);湖北省教育厅重点科研计划资金资助项目(D20101703). 2095-3852(2015)06-0841-05 A TP391 10.3963/j.issn.2095-3852.2015.06.0394 实验结果分析


5 结论
