基于作答数据的模型参数和Q矩阵联合估计*
2015-02-06喻晓锋罗照盛秦春影高椿雷李喻骏
喻晓锋 罗照盛 秦春影 高椿雷 李喻骏
(1江西师范大学心理学院,南昌 330022)(2亳州师范高等专科学校,亳州 236800)
1 引言
认知诊断评价(也称认知诊断)是现代心理与教育测量学发展的新方向,它是心理学(如认知心理学、心理测量学)、数学(如现代统计数学)和计算机科学等相结合的产物。相对于其它的测验形式,认知诊断最吸引人的地方是能够提供被试在测验领域上细粒度的掌握情况报告。认知诊断通过被试在测验项目上的反应推断被试在测验领域上的知识掌握详情(即属性掌握模式),这个属性掌握模式可以使我们更准确的了解被试在测验领域上的长处和不足,有利于进一步的学习和辅导。近年来,越来越多的研究者加入到认知诊断评价的理论和应用研究中,认知诊断的理论和实践都取得了较快的发展。
在认知诊断评价研究过程中发展出了许多的计量学认知诊断模型,如规则空间模型(Rule Space Model,RSM)(Tatsuoka,2009)、属性层级方法(Attribute Hierarchy Method,AHM)(Leighton,Gierl,&Hunka,2004)、DINA(Deterministic Inputs,Noisy“And” gate,DINA)(Junker &Sijtsma,2001 )模型等。本文中的认知诊断模型特指潜在分类模型(Latent Class Model,LCM)(de la Torre &Douglas,2004;Maris,1999),不包括多成分潜在特质模型(Multicomponent Latent Trait Model,MLTM)(Embretson &Yang,2013)。在众多的诊断模型中,DINA模型由于简单、易于解释而受到广泛的关注。Q矩阵(Tatsuoka,1983)是认知诊断评价的一个重要组成部分,几乎所有的认知诊断评价研究都要建构一个Q矩阵。被试的属性掌握模式是潜在的、不可观察的,我们只能通过可观察的项目反应来推断被试的属性掌握模式,而这之间的桥梁是Q矩阵。因此,Q矩阵的准确性对于认知诊断评价的准确性影响很大。已有研究表明,错误的Q矩阵会影响诊断模型的识别和诊断分类准确率(Rupp &Templin,2008)。
通常情况下,Q矩阵是通过专家根据经验和领域知识来界定的,受到专家的知识和经验等主观因素的影响较大。在Q矩阵的定义中主要存在两个方面的问题:一是由于专家对测验所测领域的知识把握不准导致测验整体属性架构定义不准确,这可能会造成整个测验的属性个数和属性含义定义不准;二是专家对某些具体项目的属性定义不准确,这会导致这部分项目的属性向量定义不准确。正是基于对这些问题的认识,认知诊断评价中迫切需要研究更加客观的推导和验证Q矩阵的方法。国内外的研究者已经开始关注这方面的研究,比如de la Torre(2008)提出了一种基于经验的方法对Q矩阵进行验证;丁树良等人对 Q矩阵理论进行了深入研究(丁树良,罗芬,汪文义,2012;丁树良,毛萌萌,汪文义,罗芬,Cui,2012;丁树良,汪文义,罗芬,2012;丁树良,祝玉芳,林海菁,蔡艳,2009);涂冬波等人对DINA模型下的Q矩阵修正进行了研究(涂冬波,蔡艳,戴海崎,2012);Liu,Xu和 Ying(2011,2012)研究了在DINA模型下,Q矩阵中部分项目的属性向量定义不准确的问题。他们通过构建项目作答分布和属性掌握模式分布之间关系的T
矩阵,定义了从作答数据中推导Q矩阵的判别函数,并据此推导出拟合该测验的最佳Q矩阵。但是,Liu等人将猜测参数和失误参数当作已知,直接设置成某个固定值。由于正确的Q矩阵本身是未知的,除了在模拟情形下,我们不可能预先得到项目参数的值,因此,假定项目参数值已知限制了该方法的进一步应用。另一方面,在实际的应用中,关于测验整体属性的个数也不是那么容易确定的,比如著名的“分数减法数据”的属性个数在二十多年后仍然存在争议(DeCarlo,2011,2012)。有研究者研究了项目属性向量界定错误的情况下对参数估计和分类的影响(Rupp &Templin,2008),但是也没有涉及到属性个数界定错误的情况。因此,有必要研究当属性个数存在错误的情况下,Q矩阵的估计问题。本研究基于实际应用的目的,一方面,引入一个联合算法,将 Liu等人的方法进行修改,在项目参数未知的情形下,从作答数据和“专家界定的 Q矩阵”中估计出较准确的项目参数和“正确的 Q矩阵”;另一方面,研究了当“专家界定的 Q 矩阵”中少了必要的属性或多了额外的属性时,如何利用联合算法得到的结果来判断Q矩阵的正确性。
本文的内容安排如下:第2部分介绍有关的符号、概念和联合估计算法;第3部分研究该算法在Q矩阵中存在错误项目时的表现;第4部分研究Q矩阵中属性个数界定错误时该算法的表现;第5部分对研究方法、研究结果进行了总结和讨论。
2 Q矩阵的估计
假定测验中一共有J
个项目,考察K
个属性,共有N
个被试参加测验。本文是基于DINA模型,在Liu等人方法(Liu et al.,2011,2012)的基础上进行的研究,因此首先对涉及到的相关概念、DINA模型和Liu等人提出的方法进行介绍。为了方便读者阅读,本文中的许多符号和表示方式与Liu等人的论文中保持一致。2.1 相关的概念和符号
属性:在认知诊断评价中,属性通常是指为了正确完成某个任务或项目,被试所需要拥有的知识、技能或特质,它是对被试知识掌握状况的细粒度描述。
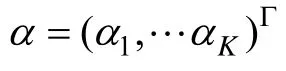
J
×K
的矩阵,其中每一行(也称行向量)代表一个项目,行向量中的每个值都是二值的,q
取0时表明项目j
没有考察属性k
,q
取1时表明项目j
考察了属性k
。q
向量:Q矩阵中的每一个行向量都代表了一个项目,记为q
,其中j
=1,2,…,J
,这个行向量也称为项目j
的属性向量。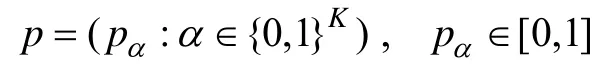
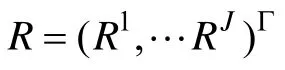
Q矩阵界定错误:在界定Q矩阵的时候,存在两类错误,一种是Q矩阵中的项目界定错误,这通常是指在属性个数界定正确的前提下,但是部分项目的属性向量界定有错误;另一种是Q矩阵的属性个数界定错误,这样会导致即使其它属性是正确界定的,但是所有项目的属性向量都是错误的,因为Q矩阵中缺少了必要的列或多了不必要的列。如果没有特别说明,文中所提到的Q矩阵界定错误均是指Q矩阵中有部分项目的属性向量界定错误。
2.2 DINA模型
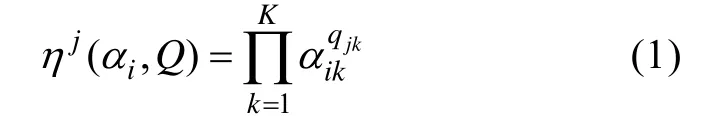
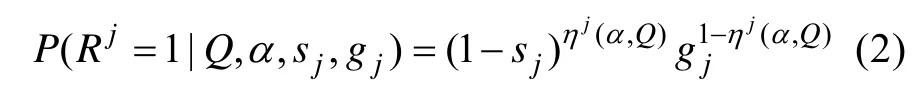
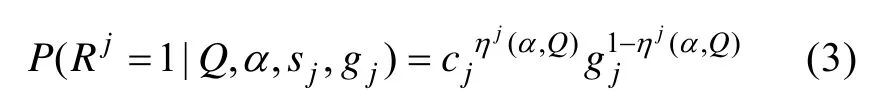
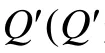
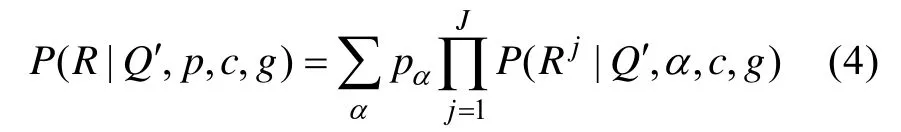
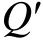
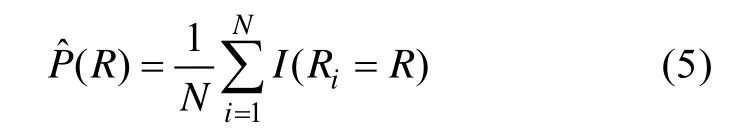
2.3 β向量、T矩阵和目标函数S
向量β描述的是测验中每个项目和项目组合上正确作答人数的比例。β向量的定义方式为
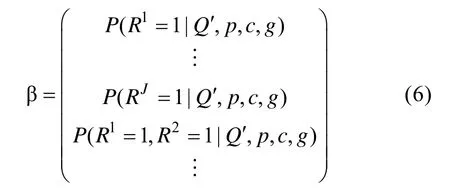
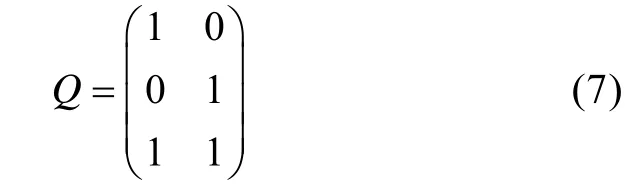
p
表示被试总体中对 A和 A都没掌握的人数比例,p
表示被试总体中没有掌握A,但是掌握了A的被试的比例。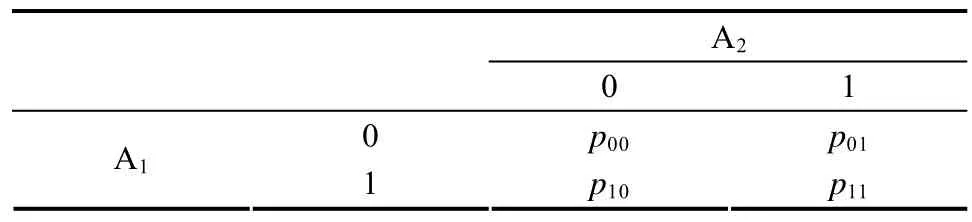
表1 测验考察两个属性时的总体分布
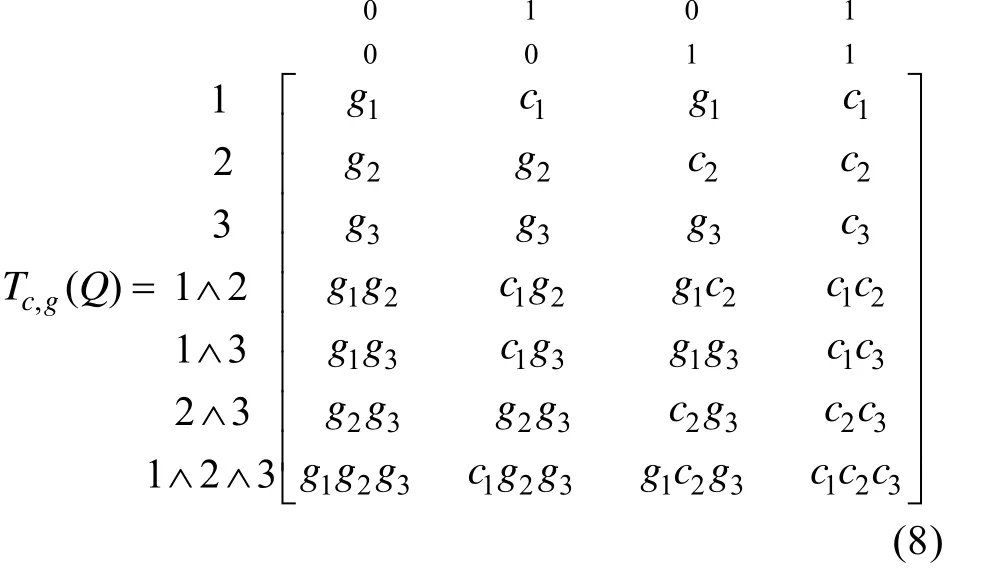
T
中的每个元素表示列编号对应的被试在行所表示的项目或项目组合上的正确作答概率

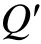
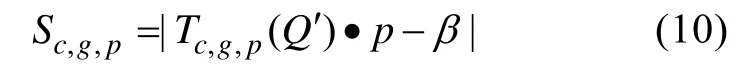
2.4 Q矩阵和项目参数的联合估计算法
Liu等人(2011,2012)提出通过作答数据推导Q矩阵的方法,其模拟实验结果表明,当固定项目参数为0.2,考察属性个数为3、4和5,整个Q矩阵中有3个项目的属性向量被界定错误的条件下,他们的方法恢复正确Q矩阵的可能性很大。具体结果请见表2,表2是直接从Liu等(2012)引用的。
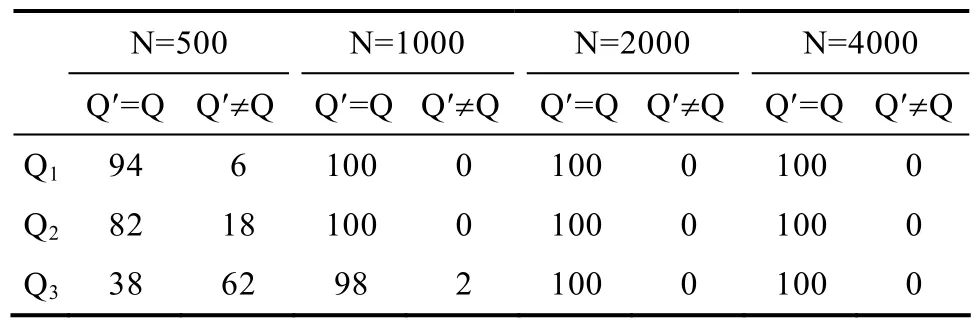
表2 100批模拟数据中正确估计Q矩阵的次数
由于Liu等人(2011,2012)固定失误和猜测参数都为 0.2,而现实情况中,不同项目参数通常是不同的。为此,我们对Liu等人的方法进行改进,设计了对项目参数和 Q矩阵进行同时估计的联合估计算法,简称为联合估计算法。
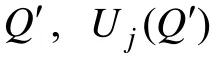
算法的具体描述如下:
第一次迭代从Q
(0)出发,迭代的结果记为Q
(1),作为第二次迭代的初始矩阵。类似地,第m
次迭代时,其“出发点”是算法上一次得到的估计值Q
(m
-1),第m
次迭代过程的详细描述如下: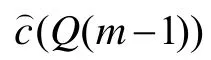
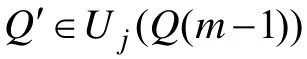
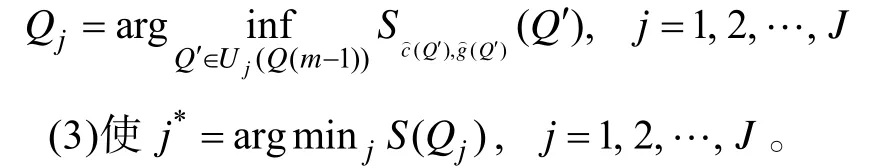
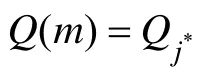
J
个项目的属性向量为止。(6)重复上述步骤,直到Q( m )=Q( m-1),即第m
次迭代前后两次的 Q矩阵不变,则所得到的Q
(m
)和项目参数即为算法最终的估计值。执行步骤(2)到(4)时会固定其它项目的属性向量不变,只对项目j
在所有可能的属性向量(共有2-1种)下计算S
,选择使S
值最小的向量作为项目j
的属性向量。所有项目都完成更新称为一次迭代,在一次迭代中,需要计算S函数和调用EM算法估计项目参数的次数都为J
×(2-
1)
。3 研究一 项目参数和Q矩阵的联合估计算法
考查在DINA模型下,联合估计算法在不同条件下的表现。
3.1 研究方法
使用和 Liu等(2012)相同的方法,模拟属性个数为 3、4和 5,被试人数为 500、1000、2000和 4000,项目个数为20,模拟真实的Q矩阵分别如图1。

图1 模拟的真实Q矩阵
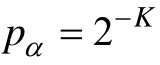
T
矩阵(Liu et al.,2012)是一个非常庞大的矩阵,因此,为了减少计算时间,提高算法的执行效率,按照 Liu等人(2012)的做法,在构造的T
矩阵中,选择的项目组合最大到K
+1个,这样一来,可以显著减少T
矩阵的行数。初始Q矩阵的选择按照Liu等人(2012)的做法,随机从Q矩阵中选择3个项目进行修改,使被选择的 3个项目的属性向量与正确的属性向量不一致(比如在 Q下,每个项目可能的属性向量有 2-1=7种情况,只有一种是正确的,可以随机选择剩余的6种之一作为其属性向量,这样就实现了模拟项目属性向量界定错误的情形)。在这里我们不只是考察了错误项目个数为3的情况,而且也考察了错误项目个数为4和5的情况,即在Q矩阵中随机选择3、4或5个项目进行随机修改,使得Q矩阵中除了这3、4或5个项目是被错误界定的,其它项目的属性界定都完全正确,以这样的矩阵作为初始Q矩阵,使用联合估计算法估计项目参数和Q矩阵。
所有的模拟过程使用matlab编写程序,在台式机上实现,CPU为intel I5 3400,内存为4G。当属性为3个、被试为500人、项目为20题时,平均完成一次估计Q矩阵的时间在10分钟左右。
3.2 研究结果
表3列出了在不同属性个数,不同被试人数,不同错误项目个数情况下,联合估计算法的表现。当被试人数达到 1000及以上时,联合估计算法能够 100%的估计出正确的 Q矩阵,因此,被试人数为2000,4000时的结果在表3中未列出。
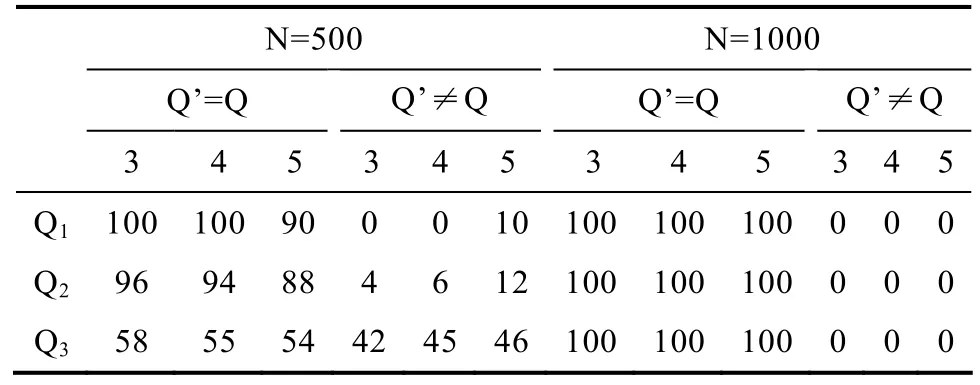
表3 使用联合估计算法从 100批模拟数据中正确估计Q矩阵的次数
从结果可以看出,使用联合估计算法对项目参数和Q矩阵进行估计,即使是在被试人数为500时,不同属性个数的 Q矩阵恢复成真值的可能性仍然很大。当被试人数达到 1000时,各种情况下都能100%恢复成正确的Q矩阵。
我们也考察了推导失败的数据集,估计失败时包含两种情况:一种是迭代过程中“没有经过正确的 Q矩阵”,另一种是“经过了正确的Q矩阵”。在这两种情况下,迭代次数和目标函数之间的变化关系,迭代次数和错误属性个数之间的关系,请参考图2和图3。图2和图3分别描述的是当被试人数为500,属性个数为5,错误项目个数分别为3和5时的一次失败估计过程。
从表3可以看出,当属性个数为5时,联合估计算法需要的被试人数要大于 500,才能 100%的恢复正确的Q矩阵。从图2和图3可以看出,当被试人数为500时,估计的Q矩阵可能无法到达正确的Q矩阵(如图2),或者经过正确的 Q矩阵但是并没有识别出来(如图3)。因此,在这两种情况下,增加被试人数是有效的解决手段,Liu等人(2012)年提到采用提前终止算法的方法来解决类似于图3的情况,但是这种方法所使用的提前终止策略主观性较强。
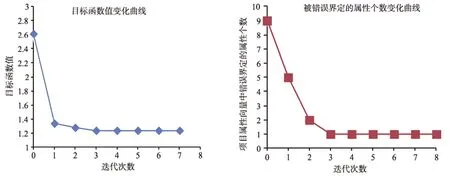
图2 估计的Q矩阵“没有经过”正确的Q矩阵
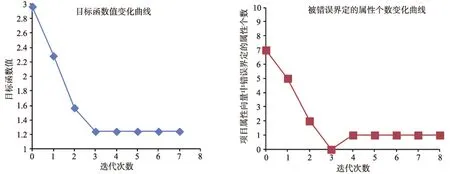
图3 估计的Q矩阵“经过”正确的Q矩阵,但算法此时没有收敛
为了更进一步考察被试人数较少和错误项目个数较多时联合估计算法的适应性,我们考察了Q下,被试人数分别为300,400,错误项目个数为3,4,5,6时的情况,模拟数据的方法与前面相同,每种情况都模拟100次,结果如表4所示。
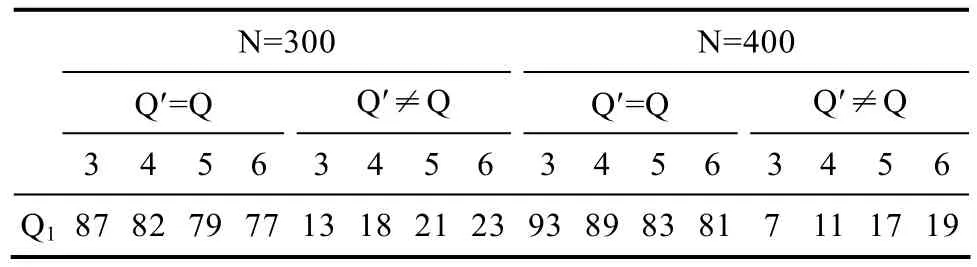
表4 使用联合估计算法从 100批模拟数据中正确估计Q矩阵的次数
表4中的结果进一步表明,联合估计算法在被试人数较少(比如 300),错误项目个数较多(比如 6个)时,联合估计算法依然有很大的可能估计出正确的 Q矩阵,成功率达到 77%。当被试人数达到400时,成功率达到81%。提高被试人数是提高Q矩阵估计成功率的有效手段,也表明被试人数是影响联合估计算法准确性的一个重要因素。
关于项目参数的估计结果,分两种情况,一种是通过联合估计算法可以得到正确的Q矩阵,在这种情况下,项目参数的估计精度与 de la Torre(2009)中的结果相近;当通过联合估计算法得到的Q矩阵与正确的Q矩阵有差别,此时项目参数的估计精度与 Q矩阵真实值和估计值之间的差异有关,Rupp 和 Templin(2008)对这种情况进行了详细和深入的研究。
4 研究二 属性个数界定错误时的Q矩阵估计
在实际的应用中,测验整体的属性个数也不是那么容易确定的。因此,有必要研究当属性个数存在错误的情况下,联合估计算法的适应性。基于此,考察当专家界定的属性个数与正确的属性个数相差为 1(少一个必要的属性或多一个额外的属性)时,算法所估计出的 Q矩阵和项目参数能给我们带来什么样的参考信息,是否能够估计出正确的 Q矩阵?
当Q矩阵中的属性个数存在错误时,考察缺少必要属性或存在多余属性时对 Q矩阵估计和项目参数估计的影响。
4.1 Q矩阵中包含一个额外的属性
4.1.1 研究方法
这里的Q矩阵还是与3.1中的相同,向Q矩阵中添加一个随机的二值列向量作为属性界定个数多一个的情形,其它未涉及到的列保持不变。在Q中,增加一列有 4种可能,即在第 1列前,第 1与第2列之间,第2与第3列之间,第3列之后。按照这种方法,从Q、Q和Q可以生成包含多余一个属性的Q矩阵15个,作答数据仍采用前面的数据,只是在估计时的初始Q矩阵是在真实Q矩阵上增加1个属性列后所对应的矩阵,被试分别是500、1000、2000和 4000人,一共就有 15×4=60种情况。
当Q矩阵中包含一个额外的属性时,这将导致所有项目的属性向量都是错误的,但是除了这个额外属性之外,其它所有属性在每个项目中的界定都是正确的。
4.1.2 研究结果
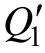
C
列,以这个删除C
列后得到的矩阵为基础,通过联合估计算法就可以很容易得到正确的Q矩阵。这说明,联合估计算法能很好的处理Q矩阵中有额外属性的情况。在实际的数据中,如果Q矩阵中出现C
列,可以通过计算SQ
值和项目参数值共同来决定该列是否多余,如果删除这个C
后的Q矩阵对应的SQ
更小,并且包含这些属性的项目的失误参数明显下降,就表明可以删除C
所对应的列,即 Q矩阵中有了一个额外的属性,可以删除该属性,进一步使用联合估计算法来验证或估计正确的Q矩阵。
图4 存在额外属性时联合估计算法得到的Q矩阵
4.2 Q矩阵中缺少一个必要的属性
4.2.1 研究方法
Q矩阵与3.1中相同,随机从Q矩阵中删除一列作为缺少一个必要属性的情形。以3个属性为例,删除一列有3种可能,即可以删除第1、2或3列,在删除列的时候,如果导致某行剩下的元素全部为0,则删除该项目。按照这种方法,从Q、Q和Q可以生成缺少一个必要属性的Q矩阵12个,作答数据仍采用前面的数据,只是在估计时的初始Q矩阵是在真实Q矩阵上删除1个属性列后所对应的矩阵,被试分别是500、1000、2000和4000人,一共就有12×4=48种情况。
为了便于说明问题,以 Q为例说明缺少一个必要属性的情况。假定项目参数都为 0.2。某个项目的属性向量为(1 0 1),被试总人数N
是一个很大的正整数,并且 8种属性掌握模式是均匀分布的,则理想情况下,属性掌握模式为(1 0 1)和(1 1 1)的两类被试可以正确作答该项目,其余6类被试只能通过猜测。因此,根据 DINA模型假设,应该有N
×0.2×2/8的被试发生失误而错误作答,有N
×0.2×6/8的被试发生猜测而正确作答。当缺少第一个属性时,项目变成了(0 1),则导致认为属性掌握模式为(0 0 1),(0 1 1),(1 0 1),(1 1 1)的被试均可以正确作答该项目,人数为N
×4/8,其余4种被试只能通过猜测,人数为N
×4/8。但是实际上,这部分被试中应该正确作答并且确实正确作答的人数为N
×0.2×2/8+N
×(1-0.2)×2/8=N
×2/8,应该正确作答但是错误作答的人数为N
×4/8-N
×2/8=N
×2/8,则采用错误的 Q矩阵导致失误参数为(N
×2/8)/(N
×4/8)=0.5,猜测参数为(N
×0.2×4/8)/(N
×4/8)=0.2。但是如果是另一个项目(0 0 1),删除属性后变成(0 1),通过同样的分析过程可知,其猜测参数和失误参数不会受到影响。对于4和5个属性的情况,结论同样适用。4.2.2 研究结果
表5列出了在Q中删除第1个属性,被试人数为500时,对剩余项目(因为删除属性1之后,项目1,4,7的属性向量变成了全“0”,只剩下17个项目)的参数估计与删除属性1之前的参数估计比较,△s
和△g
表示两种情况下参数估计的差值。
表5 在Q1中删除属性1前后项目参数估计的结果比较
表5中的粗体显示的数值对应考察了属性1的项目,从表5中可以看出,凡是考察到属性1的项目的失误参数都有明显的变化,并且变化量都在0.2以上,而其它未考察到属性1的项目的参数变化较小。
因此,当怀疑“专家界定的Q矩阵”中有多余属性时,可以在“专家界定的 Q 矩阵”中删除一列(多余的属性所在的列),然后通过联合估计算法进行参数估计。结果中如果发现有部分项目的失误参数明显上升,猜测参数变化较小,其余项目的参数基本保持不变,并且SQ
值会变大,这些信息就提示所删除的列不应该被删除,这个列所对应的属性是一个必要属性。进一步,可以在专家界定的Q矩阵的基础上使用联合估计算法估计正确的Q矩阵。当项目的属性向量中包含所有必需的属性和一个多余的属性时,会导致猜测参数上升,但是不会影响失误参数(de la Torre,2008)。以这样的Q矩阵(包含一个多余的属性)为基础,会导致计算的目标函数S
偏大。当Q矩阵中多余属性对应的元素值都为“0”时(即所有项目都未考察该属性),项目参数估计值更接近其真值,此时目标函数S
达到最小。因此,联合估计算法可以处理Q矩阵中多余一个属性的情况。当项目的属性向量中仅仅只缺少一个必需的属性,会导致失误参数上升,但是不会影响猜测参数(de la Torre,2008)。以这样的Q矩阵(缺少一个必需的属性)为基础,会导致计算的目标函数S
偏大。项目参数估计值总是围绕真值附近波动,仅仅考虑通过项目参数估计值来判断 Q矩阵的正确性存在较大主观性,而这里的目标函数S
同时考察了项目参数和作答数据,项目参数估计值越接近于真值,S
越小。并且Liu等(2011)已经证明,当Q矩阵正确时,随着被试人数的增加,目标函数S
会趋于0。因此,当Q矩阵中存在一个多余的属性或缺少一个必需的属性时,联合估计算法可以提供很好的参考信息。5 结论与讨论
通过对联合估计算法的研究,结果发现,当被试人数较少时,比如300,错误项目达到6个时,算法依然有很大可能恢复成正确的Q矩阵,这使得该算法在实际应用中成为可能的选择。当专家对部分项目的界定有困难、对Q矩阵的界定产生不一致的意见或者对界定的 Q矩阵的正确性产生怀疑的时候,可以使用该算法以作答数据和初始的Q矩阵为基础进行估计。这个算法的一个前提是,专家必须对部分项目的属性界定是有把握的,如果Q矩阵中大部分项目的界定都是错误的,该算法也很难估计出正确的Q矩阵。因为在估计过程中包含了太多的“噪音”信息而使得估计过程可能根本不会“经过”或“到达”真实的Q矩阵,并且整个可能的Q矩阵空间是巨大的,可能的Q矩阵个数为(2-1)个,搜索这个空间在短时间内是无法完成的,不可能对整个空间进行完全搜索。另一方面,在实际的应用过程中,Q矩阵的错误大多数是项目的属性向量界定错误,但是有时候测验中的属性个数也难以确定。一般来说,属性个数在界定的时候不至于出现较大的偏差,因此本文只考察了 Q矩阵中缺少一个必要的属性时和多余一个额外的属性情况下算法的表现。结果表明,当Q矩阵中多出不必要的属性时,算法能将其“识别”出来,因为几乎所有项目在这个属性上都被界定为0,这就提示我们,该 Q矩阵中可能包含了不必要的属性,在删除这一列之后,通过联合估计算法可以得到正确的Q矩阵。当在Q矩阵中删除必要的属性时,会导致考察了该属性的项目的失误参数明显上升,而其它未考察该属性的项目的参数基本不变,基于这些信息则基本可以确定该属性是必要的属性,不应该被删除,以此为基础,通过联合估计算法可以估计出正确的Q矩阵。当然,在实际的应用中,通过联合估计算法得到的Q矩阵最好还要由领域专家进行进一步“确认”,或者与其它Q矩阵的估计和验证方法共同来估计和验证Q矩阵。
总之,联合估计算法在部分项目被错误界定的情况下,有很高的恢复正确Q矩阵的成功率。相对于Liu等人的方法,联合估计算法恢复成功率更高,这也有可能是由于本研究中模拟的项目参数在大部分情况下更小(Liu等人采用的是固定 0.2,而这里采用的是[0.05,0.25]的均匀分布)的原因导致的,但是采用联合估计项目参数和 Q矩阵更加符合现实情况;另一方面,对于属性个数界定错误情况下的 Q矩阵估计,之前并未见有文献进行详细报导,当 Q矩阵中存在一个额外属性或缺少一个必要的属性时,该方法可以提供很好的参考信息,进一步可以通过联合估计算法估计出正确的Q矩阵。
联合估计算法存在的一个问题是必须对正确的Q矩阵有所了解,也就是已经有一个经专家初步定义好了的Q矩阵。如果对Q矩阵一无所知,联合估计算法就不太可能估计出正确的Q矩阵。如何在对Q矩阵一无所知或了解较少的情况下,通过作答数据估计出正确的Q矩阵,需要进一步的研究。并且本研究只是考虑了 Q矩阵中缺少一个必要属性以及添加一个多余属性的情况下,联合估计算法能够提供有用的参考信息。如果缺少或添加了更多的属性,算法得到的结果与真实的Q矩阵的差距就很大了,此时算法提供的信息的参考价值就很有限了,需要进一步研究推导Q矩阵中属性个数的方法。
de la Torre,J.(2008).An empirically based method of Q-matrix validation for the DINA model:Development and applications.Journal of Educational Measurement,45
(4),343–362.de la Torre,J.(2009).DINA model and parameter estimation:A didactic.Journal of Educational and Behavioral Statistics,34
(1),115–130.de la Torre,J.,&Douglas,J.A.(2004).Higher-order latent trait models for cognitive diagnosis.Psychometrika,69
(3),333–353.DeCarlo,L.T.(2011).On the analysis of fraction subtraction data:The DINA model,classification,latent class sizes,and the Q-matrix.Applied Psychological Measurement,35
(1),8–26.DeCarlo,L.T.(2012).Recognizing uncertainty in the Q-Matrix via a bayesian extension of the DINA model.Applied Psychological Measurement,36
(6),447–468.Ding,S.L.,Luo,F.,&Wang,W.Y.(2012).Extension to Tatsuoka’s Q matrix theory.Psychological Exploration,32
(5),417–422.[丁树良,罗芬,汪文义.(2012).Q矩阵理论的扩展.心理学探新,32
(5),417–422.]Ding,S.L.,Mao,M.M.,Wang,W.Y.,Luo,F.,&Cui,Y.(2012).Evaluating the consistency of test items relative to the cognitive model for educational cognitive diagnosis.Acta Paychologica Sinica,44
(11),1535–1546.[丁树良,毛萌萌,汪文义,罗芬,Cui,Y.(2012).教育认知诊断测验与认知模型一致性的评估.心理学报,44
(11),1535–1546.]Ding,S.L.,Wang,W.Y.,&Luo,F.(2012).Q matrix and Q matrix theory in cognitive diagnosis.Journal of Jiangxi Normal University(Natural Science),36
(5),441–445.[丁树良,汪文义,罗芬.(2012).认知诊断中 Q 矩阵和 Q矩阵理论.江西师范大学学报(自然科学版),36
(5),441–445.]Ding,S.L.,Zhu,Y,F.,Lin,H.J.,&Cai,Y.(2009).Modification of Tatsuoka’s Q matrix theory.Acta Psychologica Sinica,41
(2),175–181.[丁树良,祝玉芳,林海菁,蔡艳.(2009).Tatsuoka Q 矩阵理论的修正.心理学报,41
(2),175–181.]Embretson,S.E.,&Yang,X.D.(2013).A multicomponent latent trait model for diagnosis.Psychometrika,78
(1),14–36.Junker,B.W.,&Sijtsma,K.(2001).Cognitive assessment models with few assumptions,and connections with nonparametric item response theory.Applied Psychological Measurement,25
(3),258–272.Leighton,J.P.,Gierl,M.J.,&Hunka,S.M.(2004).The attribute hierarchy method for cognitive assessment:A variation on Tatsuoka's rule-space approach.Journal of Educational Measurement,41
(3),205–237.Liu,J.C.,Xu,G.J.,&Ying,Z.L.(2011).Theory of the self-learning Q-matrix.Bernoulli,19
,1790–1817.Liu,J.C.,Xu,G.J.,&Ying,Z.L.(2012).Data driven learning of Q matrix.Applied Psychological Measurement,36
(7),548–564.Maris,E.(1999).Estimating multiple classification latent class models.Psychometrika,64
(2),187–212.Rupp,A.A.,&Templin,J.L.(2008).The effects of Q-matrix misspecification on parameter estimates and classification accuracy in the DINA model.Educational and Psychological Measurement,68
(1),78–96.Tatsuoka,K.K.(1983).Rule space:An approach for dealing with misconceptions based on item response theory.Journal of Educational Measurement,20
(4),345–354.Tatsuoka,K.K.(2009).Cognitive assessment:An introduction to the rule space method
.New York:Taylor &Francis Group.Tu,D.B.,Cai,Y.,&Dai,H.Q.(2012).A new method of Q-Matrix validation based on DINA model.Acta Psychologica Sinica,44
(4),558–568.[涂冬波,蔡艳,戴海崎.(2012).基于DINA模型的Q矩阵修正方法.心理学报,44
(4),558–568.]