Web数据抽取技术的研究和探讨
2015-02-05昌吉学院计算机工程系
昌吉学院计算机工程系 仇 岗
乌鲁木齐八一中学义教部 杨 琴
Web数据抽取技术的研究和探讨
昌吉学院计算机工程系 仇 岗
乌鲁木齐八一中学义教部 杨 琴
随着电子商务的迅猛发展,网络购物受到了大多数人的青睐,怎么样才能从众多的购物网站中找到自己需要的产品,是数据抽取技术的焦点。由于Web数据具有半结构化的特征,使得数据抽取技术更加复杂。如何发展Web数据抽取技术要充分利用网络资源,发挥Web数据抽取潜力。
Web数据抽取;Xpath;信息抽取;模型
引言
随着电子商务的不断发展,网络购物成为购物的主要渠道,如淘宝网、拍拍网、58同城网、赶集网等大型购物网站的购物交易,已经彻底打破了原来面对面的交易方式。但购物网站太多,往往同一产品在不同网站或者同一网站的不同网店销售价格存在差异,客户需要花费大量时间和精力在茫茫网店中淘出价格合理的商品, Web数据抽取技术显得尤为重要。
文章对Web数据抽取的定义和数据抽取技术探讨和研究,并提出了基于XPath及正规表示法的Web数据抽取方法,最后简单介绍了基于XPath及正规表示法Web数据抽取方法在购物网站的应用。
1 Web数据抽取定义
Web数据抽取就是从页面集合中抽取出相关的数据,并将这些数据用某种易于查询的数据模型来表示。
2 Web数据抽取技术
Web数据抽取的主要目的是从半结构化或非结构化的数据中抽取出可用数据。如购物网站中的商品品牌、名称、价格等信息等。数据抽取出来后将数据保存到相应的数据库或XML中以备使用。
Web数据抽取技术主要包括网页获取、抽取方法、抽取规则、数据校验和数据集成等。在抽取购物网站的页面中,一般使用网页包转器对页面进行处理,Web数据抽取过程可以做如下定义:
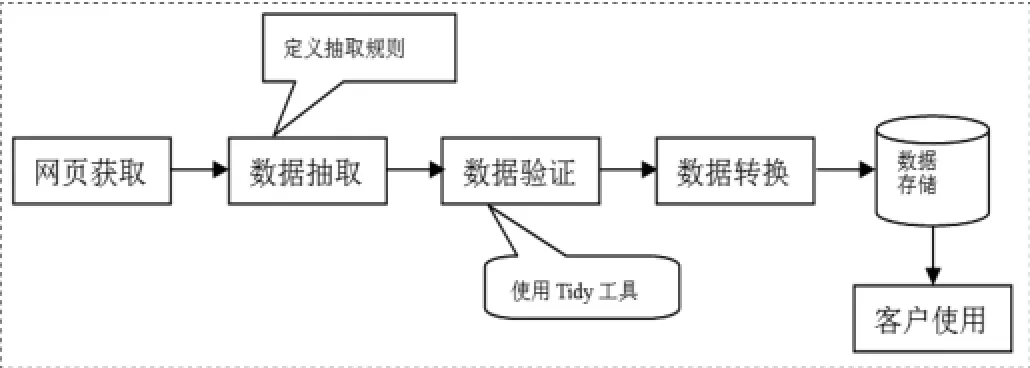
图2-1 Web数据抽取模型
Web数据抽取包括网页获取,数据抽取,数据验证、数据转换、数据存储等五个步骤。其中网页获取是根据指定一组领域网站网址的URL集合使用网络爬虫技术从网站中获取网页材料;数据抽取式使用网页包装器根据抽取规则对Web页面进行解析处理,抽取数据项;数据验证是为了保证数据抽取质量以及数据规范性,数据转换时应用相关领域知识和机器学习等技术进行数据纠错,并转化成格式严格的XML文档,如使用Tidy工具对网页进行编码情况修改存在标记错误,并转化成XML文档;数据存储是根据客户需求进行对已有数据库查询或者是从网页也中获得数据,并将客户的所需资料分类,存储到关系数据库中。
3 基于XPath及正规表示法的Web数据抽取方法
基于XPath的正规表示法的数据抽取方法。属于HTML结构分析方法主要包括使用正规表示法确定抽取点、利用XPath表示相对路径法进行数据定位和数据验证。基于XPath及正规表示法的数据抽取方法抽取过程如图3-1:
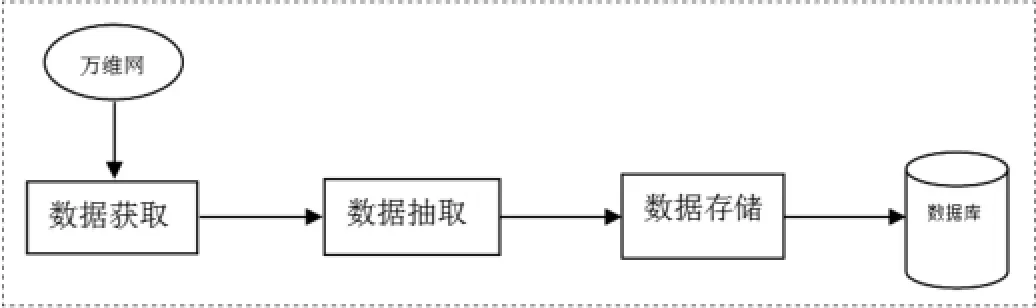
图3-1 基于XPath和正规表示法的Web数据抽取方法的抽取过程
基于XPath的正规表示法第一需要从网站中下载页面,第二需要Tidy工具处理转换为XSL的文档,第三对抽取的数据进行保存。
4 基于XPath及正规表示法的Web数据抽取方法在购物网站中的应用
商品信息来源于不同网站的不同页面,要实现相同商品在同一网站或不同网站价格的对比必须进行Web数据抽取。通过基于XPath及正规表示法的Web数据抽取方法,将不同页面上的商品信息提取到关系数据库中,并设计出B/S模式的价格对比完整。
4.1 购物网站的数据抽取流程
购物网站由网站搜索、数据规则定义、数据抽取,数据存储等四部分组成,定时进行数据更新。系统通过用户定义发现相关网站的数据,并对用户定义模式进行存储,方便下次使用,不同用户的数据抽取规则可以共享,形成一个数据规则库从而达到数据据自动提取的目的。如图4-1系统模块结构图:

图4-1 系统模块结构图
其中网站搜索模块是对用户提交的主页面的商品品牌和型号进行词频分析,然后提交到数据检索模块中进行检索,最后将结果返回到页面中;数据规则定义模块是用户定义或从共享数据库中提取;数据抽取模块包括包装器和规则生成模块,数据抽取模块是将数据源HTML页面通过Tidy修复规范化后转换为XHTML,使用基于Xpath的正规表示法对数据进行抽取,并执行XSL转换,完成数据抽取工作;数据存储模块是对数据库添加新的抽取规则或者存储相关网站数据的。
4.2 购物网站数据库设计
主要数据表有商品明细表、信息表、信息更新表:
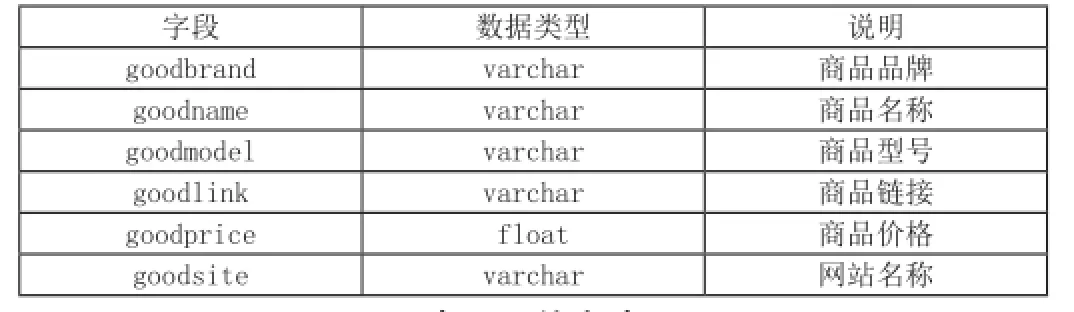
表4.1 商品明细表

表4.2 信息表

表4.3 信息更新表
4.3 部分XPath的生成代码
Public class XPathGet{
Public ArrayListgetXPath(char a,Stringkeyword)
ThrowsMException,NException{
ArrayListarraylist=newArrayList ()∶
Eleroot=a.getEle()∶
NodeListnl=root.getChildrenNodes()∶
intchangdu=root.getchangdu();
for(inti=0;i〈changdu;i++){
getMaNode(arraylist,nl.item(i),keyword);
输入的关键字并在Arraylist中查找xpath节点。
4.4 Web数据抽取部分的代码
String htmlStr=Postlnfor(this.nextPage);
Html str=XMLHelp.tidy(html str);//修正HTML数据
XMLFormString(htmlstr);//将HTM数据转换成XML
XMLHelp.XMLFromFile(txt1File);//对XSL文件进行处理
XMLHelp.transformXML(doc_str,txt1);//得到相应的商品
saveinfor(data);//保存相应的商品
XMLHelp.ParseXMLFromFile(txt1linkpath)∶//处理XSL页面的链接的文件
XMLHelp.transformXML(doc_str,nextlink)∶
//得到一个页面的链接的集合,赋予给Hashset后返回
5 小结
本文主要介绍了Web数据抽取的以及Web数据抽取流程模型,并提出了基于XPath及正规表示法的Web数据抽取方法。如何发展Web数据抽取技术要充分利用网络资源,发挥Web数据抽取潜力。
项目名称:Web信息抽取与数据挖掘技术及其在网络舆情监测中的应用研究,项目编号:2012YJQT03。
