一种基于本体的视频检索方法
2015-01-26梁俊杰熊亚军余敦辉
梁俊杰+熊亚军+余敦辉


摘 要:提出一种基于本体的视频检索方法,利用本体的基本概念获取样本图像组,并建立样本图像组和未标注视频的共同特征空间来实现视频的标注;在视频标注的基础上,对视频领域本体的基本概念集进行扩展来提高查询的命中率,以对扩展概念集记录进行检索的方式完成视频的检索。
关键词:领域本体;视频检索;共同特征空间;视频标注
中图分类号:TP391 文献标识码:A 文章编号:2095-1302(2015)01-00-03
0 引 言
近年来,随着多媒体技术和互联网技术的迅速发展,不断会有海量的、非结构化的视频数据产生。视频数据因其强大的内容承载能力正在越来越广泛地作为信息载体应用于信息传播领域。而传统的信息检索方式又难以有效应用于视频检索领域[1]。
通过构建计算机科普视频领域本体,条理化计算机科普视频中涉及到的概念,然后借助这些概念在线获取样本图像组,并建立它们与未标注视频的共同特征空间完成视频的标注。在此基础上,对该领域本体的基本概念定义存储结构以建立相应的记录,并对基本概念集进行扩展,提高匹配检索的命中率,最终完成对海量视频信息的检索。
1 视频领域本体的构建
本体是共享概念模型的明确形式化规范说明,广泛应用于信息检索、语义Web等领域[2]。本文以计算机科普视频为例,基于WordNet知识库提取计算机科普的相关概念,然后运用Protégé[3]本体编辑工具建立计算机科普视频的领域本体。该本体比较全面的涵盖了计算机科普领域的基本内容,为视频检索的图像集初始化和自动视频标注提供了载体,具体的计算机科普视频领域本体如图1所示。
图1 视频领域本体的构建
2 视频标注算法
2.1 传统的视频标注方法及其弊端
目前,大部分搜索引擎在检索视频文件时,是通过视频文件的标签等文本信息进行检索的。随着视频数量的快速增长,传统的视频标注方法存在很多弊端[4],主要如下:
(1)标注量大:对海量的视频信息逐个进行标注要耗费大量时间;
(2)客观性差:人工标注难免受人为主观性的影响。
传统的视频标注方法存在的这些弊端将导致标注偏差甚至错误等问题,进而直接影响到视频检索准确性。
2.2 视频标注
互联网是一个包含海量图像的巨大容器,而且蕴含了大量的图像知识。由此,可以根据关键字在线检索得到大量的图像,用以检索的关键字即为对应图像组的标注。然后通过CCA方法得到共同特征空间,这样将标注域的中图像样本的特征与被标注域中的视频的特征进行比较[5],并将比较得到相似度结果分别表示为r、rm、ra,其中r表示比较的最终结果,rm表示被标注域视频特征与图像组中每一幅图像的图像特征通过共同特征空间进行比较的得到最大值,ra表示与图像组中幅图像比较的均值,即r=rm+ra,即:
(1)
其中ri,i∈(1,2,…,n),n为该图像组图像样本的数量,最终运用式(1)将求得r值最大的图像组的标注作为该视频的标注。
2.2.1 图像库的初始化
根据领域本体的特点,可将领域本体的概念作为结点,而概念间的关系作为结点之间的层次关系,则领域本体可用树来描述,从概念作为树的结点的位置分,可大致将概念分为两种,一种为叶子结点概念,另一种为非叶子结点概念。
定义1.元概念集:用树描述的领域本体中处于叶子结点位置概念的集合,用Cm表示;
定义2.基本概念集:领域本体中所有概念的构成的集合,用Cb表示。
图像库的初始化就是将逐个元概念集中的概念作为关键字在线获取n幅具有代表性的图像作为该概念的样本图像,该概念的样本图像组成的集合称为对应概念的图像组,而该概念即为对应图像组的标注。
2.2.2 视频标注算法
为方便描述,特作以下定义:
定义3.源域(Source Domain):以元概念集中的概念为关键字通过互联网图像搜索引擎检索得到的图像组、该概念共同组成的数据集合,可用一个二元组SD来表示:SD={Ci,IGi},IGi={ Imagei1、Imagei2、…、Imagein },其中i为叶子结点概念的序号,imax为叶子结点位置概念的个数,n为每个叶子结点概念对应的图像组的图像样本数目;
定义4.目标域(Target Domain):把未标注并且将要借助标注域进行标注的互联网视频组成的集合,可用一个集合TD表示TD={V1、V2、…、Vm},其中m为未标注视频的数目;
由于图像特征和视频特征是异构的,不能通过分析图像与视频的相关性来决定是否将图像的标注信息作为视频的标注。为解决空间特征异构问题,引入共同特征空间的概念[6]。在标注域和被标注域的特征空间之间建立共同特征空间,这样任意标注域中的图像样本和被标注域中的视频样本均可以借助映射矩阵投影到该共同特征空间中。
利用视频关键帧提取工具[7],提取视频的关键帧建立视频的图像特征空间,给z个样本对{(K1,V1),…,(Kz,Vz)},其中K1、K2…、Kz∈Rdi视频关键帧的图像特征空间的样本,V1、V2…、Vz∈Rdv表示视频特征空间的样本,然后使用CCA(Canonical Correlation Analysis)方法来学习得到映射矩阵wi和wv。视频标注算法如下:
Begin输入:SD、TD中的某个Vm
(1)建立每个IGi中每幅Imagein的图像特征空间Sin、Vm的视频特征空间Sa;
(2)提取Vm的关键帧kf,建立kf的图像特征空间Sb;
(3)运用CCA学习方法得到映射矩阵wi和wv;
(4)利用wi和wv建立共同特征空间Sc;
(5)For每一个Sin
①将Sin和Sa→Sb同时映射到Sc比较得到rin并计算
②计算图像库内各个图像组间的Rm
(6)将Rm对应的图像组相应的概念作为视频Vm的标注;
End输出:带标注的视频Vm。
3 视频检索方法
3.1 视频检索框架
依据前文所述,基于计算机科普视频领域本体和自动视频标注进行视频检索的基本框架如下:
图2 计算机科普视频检索框架
3.2 检索预处理
3.2.1 基本概念集的扩展
视频检索采用用户搜索关键字与领域本体中的概念集项进行匹配的方式,但是包括汉语在内任何语言都会存在同义词的特性。而用户在查询时关键字的选取是随机的,所以如果单一的采用基本概念集作为用户查询关键字匹配库,会造成视频数据的漏查,影响查全率。
为解决上述问题,本文采用对基本概念集扩展的方法来缓解同义词给查询带来的影响。
例如,有元概念集Cm ={E, F, G},基本概念集Cb={A,B,C,D,E,F,G},假设Cb中,仅有概念B有典型同义词B1、B2、B3,则将B1、B2、B3加入Cb,有扩展概念集Ce={ A,B,B1、B2、B3,C,D,E,F,G}。
3.2.2 扩展概念集记录存储结构
为方便对视频数据记录进行查询,特对扩展概念集数据记录的存储结构用如下六元组R[8]定义:
Record={ID,Cei,Flag,Ch_ID,Vi,Vi_path},且把形如Record记录构成的视频数据库记为DBR,其中各部分含义如表1所示,其中各部分含义如表1所示:
表1 扩展概念集数据记录结构序号 项名称 项含义
1 ID 记录编号
2 Cei Ce中概念或同义词项
3 Flag 标识位
当Flag=0时,表示Cei非叶子结点;当Flag=1时,表示Cei为叶子结点概念或同义词;
4 Ch_ID Ce中Flag=0项孩子结点ID
5 Vi 各视频的编号和名称
6 Vi_path 视频Vi的存储路径
3.3 检索原理
本文中的视频检索是扩展概念集记录存储结构的基础上,采用用户输入的查询关键字KeyWord与扩展概念集记录中Cei进行匹配的方法完成用户的查询请求并将查询结果返回给用户。根据Cei在领域本体树中所处的位置,又分为以下两种情况:
(1)如果查询关键字与叶子结点概念或其同义词匹配成功,即Flag=1,则将叶子结点概念所在记录的视频数据返回给用户;
(2)如果查询关键字与非叶子结点概念或者其同义词匹配成功,即Flag=0,则需要通过Ch_ID逐层往下寻找其孩子结点,直至最终找到的结点没有孩子为止,则将最后找的一个或者多个叶子结点概念所在记录的视频数据返回给用户。
查询样例.查询关于B1的视频
Step1:通过用户输入的关键字KeyWord-B1与扩展概念集记录进行匹配;
Step2:匹配成功后得其Flag=0,为非叶子结点概念的同义词,则通过B1所在记录的Ch_ID信息找到得到B1的孩子结点概念为E、F,且E、F均是叶子结点概念;
Step3:返回E、F中的视频数据并通过VE_path和VF_path读取视频至检索结果列表,检索完成。
4 实验结果与分析
从互联网上收集与计算机相关的视频作为实验的基础数据,借助计算机科普视频领域本体完成图像库的初始化,并利用本文的视频标注算法完成视频的标注。
利用M-OntoMat-Annotizer[9]工具对视频基础数据进行语义标注,并编码实现本文的视频检索算法。为比较本文提出的视频检索算法与传统的视频检索算法优劣,同时借助已有方法完成传统的基于关键词的视频检索和完成基于内容的视频检索。
为保证实验的客观性,邀请多位区分度较大的用户提出5个查询要求:查询有关计算机软、硬件的视频、计算机应用的视频、互联网的视频、计算机发展历程的视频分别进行实验。实验中,采用查准率和查全率[10]作为衡量检索性能的标准,并定义如下:
查准率= 查询过程中需要的视频个数
查询过程中的视频总数
查全率= 查询过程中需要的视频个数
视频基础数据中需要的视频总数
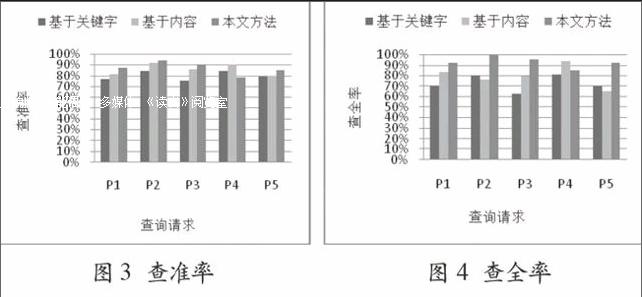
根据以上的实验设置,当图像组的图像样本数n=1 000时,实验结果如图3和图4所示。
图3 查准率 图4 查全率
从图3和图4的实验结果表明:本文提出的视频检索方法相对于基于关键字和内容的视频检索方法,大部分的查询请求的查准率有不同程度的提高,验证了本文方法的有效性。
5 结 语
本文提出了一种基于领域本体和自动标注的视频检索技术,通过领域本体的基本概念集收集样本图像组,并建立图像组和未标注视频的共同特征空间完成视频的标注;通过将领域本体用树来描述,在树结构的基础上完成视频的检索。实验结果表明,基于领域本体和自动标注的视频检索技术大大提高了视频检索的效率。
参考文献
[1]Rasiwasia N,Costa Pereira J,Coviello E,et al.A new approach to cross-modal multimedia retrieval[A].Proceedings of the International Conference on ACM Multimedia[C].Firence, Italy,2010:253-258.
[2]徐正宁.基于本体的Web数据语义信息的表示与处理方法研究[D].长沙:国防科技大学,2002.
[3]张小峰,唐新亭,赵永升,等.基于本体技术的Internet智能搜索研究[J].计算机工程与设计,2006,27(7):1915-1916.
[4]张静,马桔.利用本体的视频语义概念检测[J].小型微型计算机系统,2008,29(12):2354-2356.
[5]Yang Na,Luo Hangzai,Xue Xiangyang.A method to detect anchorperson shots for digital TV news[J].Journal of Software,2002,13(8):1559-1565.
[6]王晗,吴心筱,贾云得.使用异构互联网图像的视频标注[J].计算机学报,2013,36(10):2063-2065.
[7]隗华,陈晓鸥.一种格式无关的视频序列关键帧提取策略[J].计算机应用,2003(23):190-191.
[8]尹文杰,韩军伟,郭雷.图像与视频自动标注技术最新进展[J].计算机科学,2011,38(12):12-15.
[9]陆琳睿,周竹荣,邓维.一种基于本体的视频检索方法[J].西南大学学报(自然科学版),2008,30(11):122-123.
[10]老松杨,白亮,胡艳丽,等.基于领域本体的新闻视频检索[J].小型微型计算机系统,2007,28(8):1473-1476.
