基于多线程归并排序算法设计
2015-01-12孙琳琳侯秀萍孙士明
孙琳琳,侯秀萍,朱 波,孙士明,高 灿
(1.长春工业大学计算机科学与工程学院,长春130012;2.苏州大学附属第一医院,江苏苏州215006)
0 引言
近年来,处理器的发展已经由单核处理器转为多核处理器,由单一主频的提高转为由多个处理核心进行并行计算提高计算性能[1]。虽然多核处理器已经成为主要发展趋势,但传统的串行程序并不能在多核处理器结构下获得性能的提升。为了使串行程序能有效利用多核处理器硬件方面的优势,需要对串行程序进行并行化处理。目前比较流行的并行编程模型OpenMp,通过在源程序代码中添加编译制导语句,编译器识别这种标识会自动创建线程对程序进行并行化。同时在多核处理器系统中,多个线程可以同时在不同的处理核心上运行,以达到真正并行的效果,从而有效提高程序的效率[2]。
排序是处理数据过程中常用的运算,因此,提升排序算法的执行效率具有重要的现实意义。归并算法作为排序算法中比较稳定的算法,已经有很多学者对其进行研究,但大多数的研究都是基于串行程序的改进,如姜忠华等[3]提出了根据数据本身具有的规律对待排序列进行智能归并排序的划分方法。白宇等[4]基于分治策略,使用深度优先的方法,提出了一种用于线性表的稳定原地归并排序算法,算法在时间复杂度和空间复杂度以及排序稳定性上达到了较好的平衡。笔者采用OpenMp编译制导语句在多核处理器下使用多线程完成对数据的排序。
1 并行设计理论
1.1 数据依赖关系
将串行程序改写成并行程序,或利用编译工具将其并行化,都要保证程序的正确性[5]。保证程序的正确性就是使程序中原有的数据依赖关系保持不变。
定义[6]读集R(pi):表示程序pi在执行期间所需参考的所有变量的集合。
写集W(pi):表示程序pi在执行期间要改变的所有变量的集合。
数据依赖关系主要分析数据流的相关性,下面给出数据依赖的相关定义,若pi与pj满足下列3个条件之一,则称pi依赖于pj,否则pi与pj之间不存在依赖关系[5]。
流相关:若W(pi)∩R(pj)≠Ø,称pj流依赖于pi,记作▽f。
反相关:若R(pi)∩W(pj)≠Ø,称pj反依赖于pi,记作▽u。
输出相关:若W(pi)∩W(pj)≠Ø,称pj输出依赖于pi,记作▽o。
因此,判断两个或多个程序能否并发执行,需要分析它们的数据依赖关系,若不存在数据依赖关系,则能并发执行,且具有可再现性。
1.2 OpenMp任务分担指令
为将任务合理分配给多个线程,OpenMp提供了for和sections任务分担指令。
1)for指令语法:

for指令指定紧随它的循环语句由线程组并行执行,将一个for循环任务分配到多个线程,此时各个线程各自分担其中一部分工作[7,8]。使用for语句将循环分配到多个线程中是由系统自动进行的。
2)section指令语法:

sections制导指令用来实现多个代码段的并行执行,可并行执行的代码段需要用section指令做标记,表示分配每个section到不同的线程。使用section划分线程是一种手工划分线程的方式,最终并行性的好坏依赖于程序员[9]。
2 多线程归并排序算法设计
2.1 归并算法并行性分析
设待排数组为source[low…high],其中low和high表示数组起始位置和结束位置下标,temp为临时数组。采用递归方式进行归并排序,排序算法如下:


对程序进行数据依赖分析:

可得R(S6)∩W(S7)=Ø,R(S7)∩W(S6)=Ø,W(S6)∩W(S7)=Ø,因此S6与S7不存在依赖关系,相互独立,可以并行执行。
R(S8)={source[low…mid],source[mid+1…high]},W(S8)={source[low…high]},可得 R(S8)∩W(S6)={source[low…mid]}≠Ø 且R(S8)∩W(S7)={source[mid+1…high]}≠Ø,因此 S8流依赖于 S6和S7,S8需要S6与S7都执行完毕后才能执行。
对于S5,S6,S7,S8可以得到如图1所示的程序依赖关系前驱图,S6与S7可以并行执行,因此归并排序算法具有并行性。
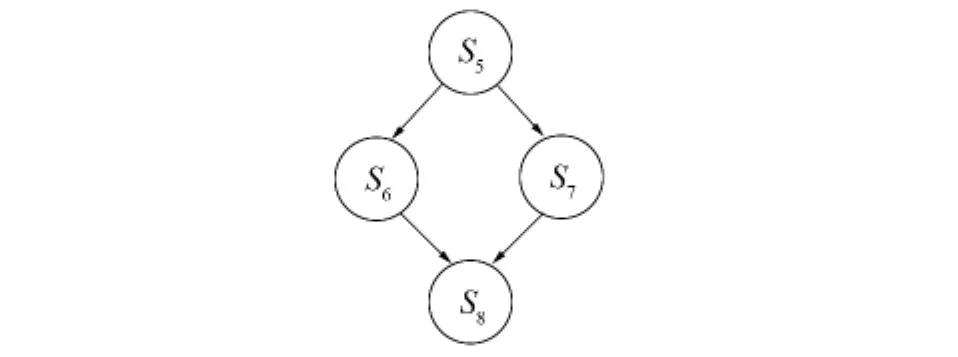
图1 程序依赖关系前驱图Fig.1 The program dependence graph of precursor
2.2 归并算法直接并行化
S6与S7没有数据依赖关系,理想情况下在双核处理器系统中设置两个线程对其并行执行。
使用OpenMp编译制导指令sections对S6、S7进行任务分担,编译器通过识别section,自动创建两个线程对S6、S7进行并行执行。
主要代码如下所示:

直接并行化是根据算法本身具有并行的特征,该过程也可理解为将待排序列均匀分成两组,每组的排序操作互不影响,最后将两组操作的结果进行合并。
当处理器核数增多,这种直接并行化的方法并不能使处理器资源达到充分利用。在数据量较大的情况下,可以考虑将待排序列分成更多的组,并使用更多的线程同时对数据进行操作,这样才能发挥多核处理器的作用。下面采用分组归并的方法实现多线程并行操作。
2.3 分组归并方法
采用分组的方法将待排序近乎均匀地划分为n组,为每组分配一个线程,使n个线程并行对每组进行归并排序。当n个线程执行完毕后,产生n个局部有序的序列,再将n个序列逐步地进行合并,最终得到一个整体有序的序列。
由于合并过程是将两个相邻的有序组进行合并,为了使每次合并时不出现剩余的小组,将n设置为2N(N≥1的整数),使用omp_set_num_threads(n)设置并行域中的线程个数。
分组过程:每个线程获取其对应的线程编号p=omp_get_thread_num(),计算每组对应的数组下标始末位置low=pl/n,high=(p+1)l/n-1(假设随机数组中有l个元素)。
合并过程:n个局部有序序列第1次两两合并时需要n/2个线程,第2次合并时需要n/4个线程,直到最后一次合并需要一个线程为止。
主要代码如下:

以4个线程为例演示分组归并操作过程(见图2)。
将待排序列近乎均匀分成4组,使用4个线程对4个组同时进行串行归并排序,当4个线程都执行完毕,形成4个有序的子序列 A1,A2,A3,A4。再将子序列进行合并,由于每次将相邻的两个子序列进行合并,因此,第1次合并时设置两个线程即可,一个线程对A1、A2进行合并,形成有序序列B1,一个线程对
A3、A4进行合并,形成有序序列B2。当两个线程都执行完毕后,再设置一个线程将B1和B2进行合并,最终形成一个整体有序的序列。
由于OpenMp采用fork/join并行模式,只有并行域中的线程全部执行完毕,才能执行后面非并行部分的代码[10]。如果各线程操作数据的时间相差较多,则最慢完成任务的线程会造成其他线程的阻塞,这样会降低处理器效率。采用分组的方法,使各线程操作的数据量近乎相等,达到各线程计算任务的负载均衡。

图2 分组归并操作图Fig.2 Packet merge operation diagram
3 实验结果分析
实验环境:使用单核处理器AMD Athlon(主频2.21 GHz,内存1 GByte)、双核处理器AMD Athlon(主频2.09 GHz,内存1 GByte)、四核处理器AMD Athlon(主频3.00 GHz,内存3 GByte)3台计算机,并在Windows Xp操作系统下使用VS2010软件进行实验验证。
实验所需要的数据是随机产生的10万、50万、100万个整数,分别统计串行、2个线程、4个线程、8个线程、16个线程和32个线程情况下排序所用的时间。由于操作系统内部的状态随时在变化,不能保证每次的实验结果都一致,因此实验结果取10次运行结果的平均值。在单核处理器系统中测得串行程序排序所用时间分别为31 ms、188 ms、421.4 ms。表1为多核处理器排序运行时间统计表。图3和图4分别为双核、四核加速比统计图。
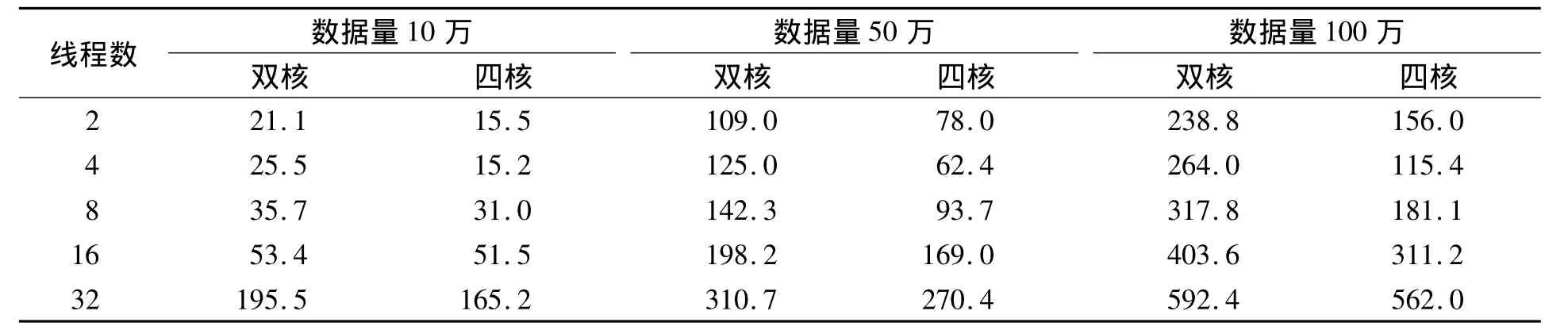
表1 多核处理器排序运行时间统计表Tab.1 Sort multi-core processor running time table (ms)
从表1可看出,多核处理器下采用多线程分组归并方法可提高算法的运行速度,并且当线程数目与处理器核数基本相同时,算法运行所用的时间最少。若并行过程中使用的线程数目过多,将导致线程间不断切换,系统开销增大,算法并行运行时间比串行运行的时间更多。
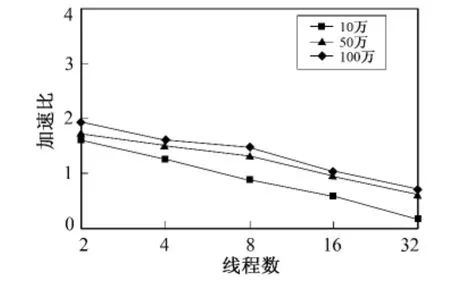
图3 双核处理器加速比统计图Fig.3 Dual-core processor speedup chart

图4 四核处理器加速比统计图Fig.4 Quad-core processor speedup chart
从图3和图4可以看出,线程数目一定,数据量增大,加速比会随着增大,即多线程更适合于数据量较大的情况。
因此,数据量较大使用多线程分组归并方法时,尽量设置与处理器核数相近的线程数目,这样才能充分利用处理器资源,使算法运行的速度达到最快。
4 结 语
笔者设计了一种多线程归并排序的方法,统计串行排序时间和并行排序时间以及并行加速比,可以看出,在多核处理器下使用多线程分组归并方法可以有效提高算法的运行速度,该方法相对于串行算法可充分利用多个处理器资源,同时设置与处理器核数相近的线程数目,算法的运行速度快。
[1]张剑.多核处理器架构下软件运行时验证方法研究[D].南京:南京航空航天大学计算机科学与技术学院,2010.ZHANG Jian.Research Authentication Method Software Running under the Multi-Core Processor Architecture[D].Nanjing:School of Computer Science and Technology,Nanjing University of Aeronautics and Astronautics,2010.
[2]徐金棒.基于多核多线程的FFT算法和堆排序算法的并行优化和实现[D].郑州:郑州大学信息工程学院,2011.XU Jinbang.The Parallel Optimization and Implementation of FFT Algorithm and the Heap Sort Algorithm Based on Multi-Core and Multi-Threaded [D].Zhengzhou:College of Information Technology,Zhengzhou University,2011.
[3]姜忠华,徐文丽,刘家文,等.智能归并排序[J].电子设计工程,2011,19(21):53-55.JIANG Zhonghua,XU Wenli,LIU Jiawen,et al.Intelligently Merge Sort[J].Electronic Design Engineering,2011,19(21):53-55.
[4]白宇,郭显娥.深度优先稳定原地归并排序的高效算法[J].计算机应用,2013,33(4):1039-1042.BAI Yu,GUO Xiane.Efficient Algorithm of Depth-First Stable in-Place Merge Sort[J].Journal of Computer Applications,2013,33(4):1039-1042.
[5]郭龙,陈闳中,叶青.构造串行程序对应的并行任务(DAG)图[J].计算机工程与应用,2007,43(1):41-43.GUO Long,CHEN Hongzhong,YE Qing.Develop Direct Acyclic Graph(DAG)Corresponding to Serial Program [J].Computer Engineering and Applications,2007,43(1):41-43.
[6]汤子瀛,哲凤屏,汤小丹.计算机操作系统[M].西安:西安电子科技大学出版社,1996.TANG Ziying,ZHE Fengping,TANG Xiaodan.Computer Operating System [M].Xi'an:Xi'an Electronic and Science University Press,1996.
[7]罗秋明,明仲,刘刚,等.OpenMp编译原理及实现技术[M].北京:清华大学出版社,2012.LUO Qiuming,MING Zhong,LIU Gang,et al.OpenMp Compiler Theory and Implementation Techniques[M].Beijing:Tsinghua University Press,2012.
[8]李建伟.基于多核多线程技术的通信网仿真算法研究[D].南京:南京邮电大学通信与信息工程学院,2011.LI Jianwei.Based on the Simulation Algorithm Multicore Multithreaded Technology Communication Network[D].Nanjing:School of Telecommunication and Information Engineering,Nanjing University of Posts and Telecommunications,2011.
[9]蔡佳佳,李名世,郑锋.多核微机基于OpenMP的并行计算[J].计算机技术与发展,2007,17(10):87-91.CAI Jiajia,LI Mingshi,ZHENG Feng.OpenMp-Based Parallel Computation on Multi-Core PC[J].Computer Technology and Development,2007,17(10):87-91.
[10]龚向坚,邹腊梅,胡义香.基于OpenMP的多核系统并行程序设计方法研究[J].南华大学学报:自然科学版,2013,27(1):62-64.GONG Xiangjian,ZOU Lamei,HU Yixiang.The Research of Multi-Core System Parallel Program Design Methods Based on OpenMp [J].Journal of University of South China:Science and Technology,2013,27(1):62-64.
