基于Agent技术的Web个性化数据挖掘研究
2015-01-04白亮
白 亮
(吉林建筑大学城建学院,吉林长春 130111)
基于Agent技术的Web个性化数据挖掘研究
白 亮
(吉林建筑大学城建学院,吉林长春 130111)
本文讨论了基于Web的概念、特性、分类以及相关技术,并在此基础上阐述了Web数据挖掘结构。然后对Agent技术进行了分析,根据Agent技术的智能性、移动性等特征,构造了一个关于Agent的Web个性化数据挖掘模型,设计了一个以J2EE技术的Web挖掘系统平台,通过实验分析结果和运行程序,得出的结论是基于J2EE平台,使用先进的移动Agent技术的Web挖掘,最终能够降低挖掘成本、提高挖掘效率。
Agent技术;挖掘;Web;J2EE
数据挖掘(Data Mining)是从超大型的数据库、知识库中获取有用知识的过程。这些知识可能是一些粗糙的、无结构的、不完整的信息,没有确定格式、没有语法对其进行描述。随着网络的发展,Web网页上还储存着很多没有被利用的资源。数据挖掘技术有利于用户便捷地传输、获取、存储、处理、分析Web网页上的大量数据。在数据挖掘过程中使用的技术有人工智能技术、数据库技术、机器学习、神经网络、数据分析和决策支持等。除了上述技术,运用程序设计及网络技术能够合理地设计数据挖掘平台,强化评价方法和完善内容,也起到了关键性的作用。国内外一些学者主要侧重对非结构化数据信息化处理以及Web挖掘的理论探讨,对实际应用的研究还偏少。JAVA是面向对象、平台无关、安全机制、高可靠性、多线程和内嵌的网络支持的软件开发工具,它是基于多层次构架的分布式网络环境下应用系统模型。
1 基于Web 的数据挖掘分析
在传统的数据库中,数据存在都表示为结构化,数据量不大,一般的服务器就可以满足储存要求。而现在由于大数据的出现,数据容量规模都在PB级以上,面对海量、复杂、变化莫测的数据,使用原来的挖掘、处理方式显然是不够的。一般的数据挖掘是指从大型数据库的数据中提取人们感兴趣的知识,这些知识是隐含的、事先未知的有用信息,数据挖掘侧重于从已有的信息中提取规律性知识,还要解决异构数据集成的问题。而Web挖掘的研究对象是以半结构化和无结构文档为中心的Web,这些数据没有统一的模式,数据的内容和表示互相交织,数据内容基本上没有用语义信息来描述,仅仅依靠HTML语法对数据进行结构上的描述。
1.1 基于Web数据挖掘的基本分类
从理论上分析,基于Web数据挖掘方法较多,国内外学者对数据挖掘过程众说纷纭。总之,根据挖掘对象的不同,我们可以把基于Web的数据挖掘分为三大类,即Web内容挖掘、Web使用挖掘、Web结构挖掘,如如图1所示。
1.1.1 Web内容挖掘
Web上的数据类型比较多,有结构化的,也有半结构化的。基于Web上内容挖掘就是将Web上的散列文档集进行递归关联比较、分析预测,挖掘知识和内容,其中内容涉及多媒体、网页等。目前的研究主要集中
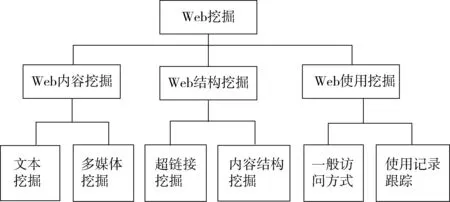
图1 Web数据挖掘分类
在词频统计、分类算法、模式识别,并从网页中分离出实体和属性。一般的Web信息检索使用基于词频的统计模型,矢量空间模型是最广泛采用的模型。在这个模型里文档用矢量来表示,而文档中词汇的属性用矢量的分量来表示,其分量值是该属性的权重,也就是该属性出现的频率。同理,查询组合也可以用矢量来表示,查询与文档的相似度就是两个矢量的内积,即两个矢量夹角的余弦值。
1.1.2 Web结构挖掘
Web结构挖掘主要是从Web本身隐含的以及链接过程与结构的数据中获取知识的过程,在通常的搜索引擎中没有考虑结构的复杂性,只把Web看作平面文档的集合。其实,在结构中隐藏着大量有用的信息,用户在寻找信息的过程中对页面进行聚类和分类关注,通常用户只关注网页搜索的结构内容,如果把页面信息一起加载到链接结构中,能够获得更多的数据量。最初人们使用PageRank结构挖掘算法,是因为PageRank是评价网页权威性的一种重要工具,搜索引擎Google就是利用该算法与anchor text标记、词频统计等因素相结合的方法对检索出的大量结果进行相关度排序,将最权威的网页尽量排在前面。
1.2 使用Agent的Web数据挖掘
目前大多数数据挖掘都是基于Web的,并且有很多的算法,但是这些算法与挖掘过程都有一定的局限性。大部分都是使用面向对象的语言工具对信息进行加工处理,有的使用关联规则和模式识别,将文档拆分为段落和语句,把准备好的段落或语句的语法结构与选中的语言模式结构进行匹配,从而获得所需的语句内容,这些内容一般通过编程和在数据库中自觉学习方式获得,但是耗费很大的学习成本和编程的人力资源,而且使运行速度明显变慢。有的人使用Ntology对数据自身进行数据挖掘,但这些方法不能完全满足数据挖掘的根本需要。将人工智能领域知识融入挖掘过程中,大大地提高了挖掘效率,更充分地实现了数据挖掘。Agent是人工智能中的重要分支,它具有智能性、移动性、自学性等特点,其应用于Web数据挖掘更能体现它的优越性。Agent挖掘结构由用户、知识库、Agent主体、数据库组成,如图2所示。

图2 基于智能Agent挖掘模型结构
当收到用户输入的初始挖掘请求时,系统把所有的请求放在工作日志上,移动接口Agent主体访问知识库中的领域知识库和网络信息知识库,然后抽取请求知识库,通过智能Agent进行学习训练,寻找分类模式及规则。
2 J2EE平台的Web挖掘过程分析
J2EE是由类组成的,运行之前首先要定义对象,然后对类进行实例化,根据对象的动态迁移性传输到其它用户机或代理服务器上,这些过程是通过类库里的方法实现的。例如,调用BufferedWriter类库里的void flush()方法,调用BorderLayout类中的void layoutContainer(Contatner target)方法可以把对象设置为容器组件,根据J2EE技术与平台无关性的特点,如果有新的数据加入这个模式中,注册表不需修改,直接刷新页面就可以了,基于J2EE的挖掘过程如图3所示。

图3 基于J2EE的挖掘过程
Web 数据挖掘过程是由Web服务器端进行的,通过发送JAVA Applet,SQL申请,将其下载到客户机服务器与RMI/IIOP协议链接上,让服务对象注册引用,SQL查询封装为本次申请参数之一;通过数据挖掘算法以及挖掘工具完成整个运行过程,再把计算结果反馈给用户。
3 实例验证
此次实验中,我们选取的指标有访问页面连接次数、点击次数、预取页面数、选中页面数、然后统计命中率,由式(1)可得到挖掘效率。
.
(1)
随机选取一台客户机的150个页面,里面装有JavaBean和EJB模块。采用基于Agent的Web移动平台,通过跟踪、预测来模拟用户的行为特征。表1为对页面点击得出的数据。
确定预测模型(prediction model)算法程序:
(ⅰ)定义抽象累
{ Data members;
The return value of the data type method(parameters……){}
Abstract The type of return value The method name(parameters……);
}
(ⅱ)定义抽象类派生的子类
Abstract Public name extends class wjuexiaolu {
Double sum; //定义累加器类型
Public void sumber(int m) //定义处理方法
{
For(int x=0;x<=m;x++)
{sum=sum+mtmt[x]; } // 求页面总和
返回sum的平均值 ; }
}
(ⅲ)抽象类方法的实现
Class abst
{public static void main(String[] args)
{
abst ss=new abst() ;
ss. sumber (10); }
}
实验结果表明,点击率与用户的兴趣、爱好有很大关系。经过统计分析和程序的运行结果不难发现, 用户的点击率主要取决于自己的兴趣,用户对不感兴趣的页面选中几率不到10%,用户对感兴趣的页面选中几率占50%以上。因此,用户使用智能数据挖掘大大提高了数据挖掘效率。
4 结语
由于数据量的不断增大,数据的存储问题越来越受到人们的关注,在大数据中获得我们需要的信息是数据挖掘的主要任务。传统的挖掘技术已不适合现代挖掘需求,目前专家们正在不断地扩展数据挖掘的模式、算法以及数据存储方式等。但实际上,在设计一个Web数据挖掘系统时,要考虑的问题比较多,比如:如何处理各个用户之间的交互问题、服务器之间负载均衡和瓶颈问题、通信过程的安全问题等,这些仍将是目前乃至今后的Web数据挖掘系统研究的主要目标和任务。这里我们使用J2EE作为开发平台,以基于Agent技术的Web信息挖掘系统作为技术支持,不断优化和完善Web数据挖掘模型,从而大大提高挖掘效率。
[1]徐宝文,张卫丰.数据挖掘技术在Web预取中的应用研究[J].计算机学报,2011(4):430-436.
[2]陈莉,焦李成.Internet/Web数据挖掘研究现状及最新进展[J].西安电子科技大学:自然科学版,2011(1):114-119.
[3]廖乐健,曹元大,李新颖.基于Ontology的信息抽取[J].计算机工程与应用,2012(23):110-113.
[4]Paul J. Perrone,et al.J2EE构建企业系统专家级解决方案[M].张志伟,谭郁松,张明杰,译,北京:清华大学出版社,2010.
[5]李雪,于书举.基于J2EE的市场需求预测支持系统模型的研究与实现[J].计算机与信息技术,2006(7):37-40.
Abstract: This paper discusses the concept, characteristics, classification and related technologies, and expounds the structure of Web data mining.Then the Agent technology is analyzed, based on intelligent, mobility, etc., we construct a personalized Web data mining model and design a system platform based on J2EE.Through the experimental analysis results and running program, we find that the system platform used of advanced mobile Agent,it is able to reduce the mining cost and improves the mining efficiency.
Public digging- efficacy //定义挖掘效率抽象类
The Research of Web Personalized Data Mining Based on the Agent
BAI Liang
(The City College of Jilin Jianzhu University,Changchun Jilin 130111,China)
Agent;mining;Web;J2EE
2015-10-12
白 亮(1984- ),男,吉林榆树人,吉林建筑大学城建学院助教,从事数据库开发与数据挖掘研究。
TP311
A
2095-7602(2015)12-0043-04
