高效视频编码的Merge模式候选决策研究与改进
2015-01-01杨静,孙煜
杨 静,孙 煜
(上海海事大学信息与工程学院,上海201306)
1 概述
Merge模式基于四叉树的图像编码方式,可以将多个具有相似运动信息且相邻的预测单元(Prediction Unit,PU)块合并为同一区域,并使其具有相同的运动信息。在这种情况下,编码器不需要为每个帧间预测块单独传输各自的运动信息,比如,运动矢量、参考索引、预测方向,只需为整个区域传递一次运动信息即可,大大提升了编码效率。
在H.264/AVC中,在帧间预测过程中采用了Direct模式和Skip模式,目的在于尽可能减少传递信息[1-3]。从概念上看,高效视频编码(High Efficiency Video Coding,HEVC)中的 Merge模式和 H.264/AVC中的direct模式是类似的,但它们之间有2个重要区别:(1)Merge模式可以构建一个候选列表,即运动矢量竞争机制,它会制定一个运动矢量候选集,并通过率失真优化(Rate Distortion Optimization,RDO)准则判断各个候选,然后从若干个中选取其一,并通过索引方式传送到编码端;(2)定义了参考图像列表和索引,而 Direct模式假定具有默认值[4-5]。
本文研究的HEVC中使用了Merge模式来获取运动信息,而不是自适应运动矢量预测(Adaptive Motion Vector Prediction,AMVP)选择机制,以此进一步增加Merge模式的利用率。
2 Merge模式
在HEVC中,对于每个正在进行帧间编码的PU,编码器主要使用以下2种方法:
(1)用运动矢量估计来编码运动矢量差和参考帧;
(2)使用Merge模式,为当前PU创建一个周围已经编码PU的列表。编码器根据率失真结果,从候选列表中选择最佳候选,此时当前PU的运动信息直接复制候选的运动信息即可。
在HEVC中,最大运动矢量候选数默认为5,可能的候选包括空间相邻候选、时间候选和生成的候选。Merge的时间和空间预测候选列表由以下元素构成:L(A1),A(B1),RA(B0),BL(A0),LA(B2),TRb,Tc[6-7],如图1所示。
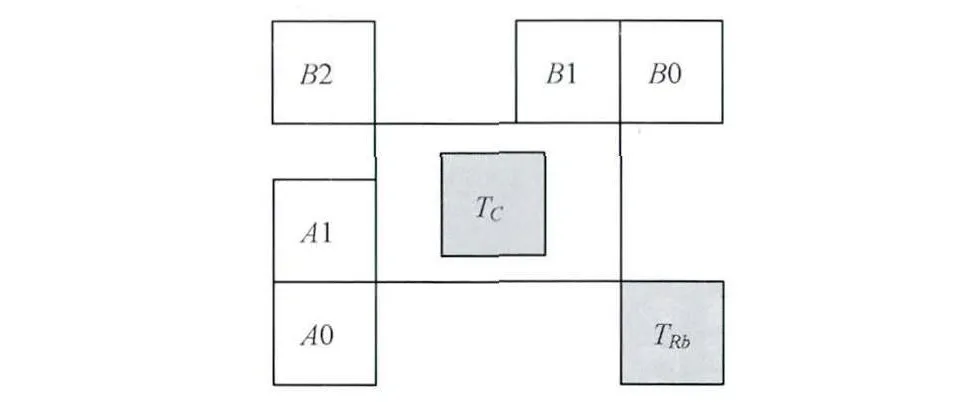
图1 候选位置示意图
Merge模式先检查空域候选位置A1,B1,B0,A0,判断4个空域候选是否可用(是否为帧内模式)并且是否存在冗余信息,这里主要指的是2种冗余:(1)如果用于当前PU的候选位置指的是同一个CU中的第一个PU,则该位置可以被排除,这主要是因为PU合并后相当于一个未划分成预测分割的CU;(2)包含完全相同的运动信息。去除冗余候选后,只有当有效的空域候选数少于4的时候,B2位置才可以被检验。对于时域候选TRb,其位于时域参考帧中与当前块相同位置下PU的右下方。如果处在参考图像对应PU之外的右下角位置是可用的,那么使用该候选,否则使用处于中心位置的TC作为时域候选[8-9]。
在默认情况下,Merge模式预测候选的最大数量为5,若为P条带,此时若时间域候选集数加上空间域候选集个数仍小于5,则直接增加0归并候选,直到候选集个数等于5为止,此时结束候选集的选择过程。若为B条带,用于列表0(list0)和列表1(list1)的额外合并候选会通过预定义的顺序来选择2个候选生成。排除冗余后,对候选列表进行补充,数量不大于5个[10-11]。运动候选集选择过程如图2所示。
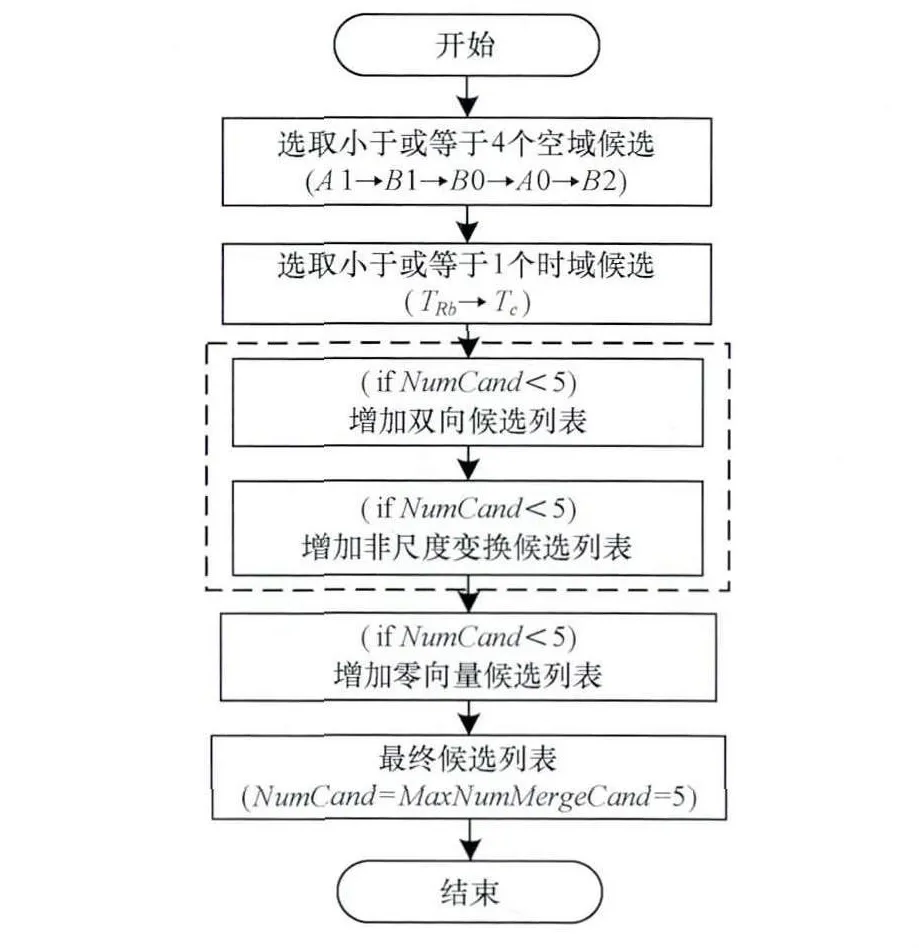
图2 候选列表选取过程
3 Merge模式的候选决策研究
分析并跟踪Merge模式的整个流程得知:
(1)选择候选集的过程需要在空间域和时间域至少进行5次判断,但最终通过率失真计算后得到的最终候选只有一个。并且由于是相邻块的缘故,A1与A0,B1与B0之间的关联程度很高,往往具有相同的运动信息,导致很多时候进行了多次不必要的判断。
(2)在进行率失真计算时,往往要考虑到编码参数、最终所需传输的运动矢量等总体编码数据的多少。由于在编码Merge_idx过程中使用的是一元截断码,对于MaxNumMergerCand=5,Merge_idx如表1所示,若MaxNumMergerCand=3,则 Merge_idx如表2所示。由表1、表2可以看出,减少候选个数,其一元截断码的位数也相应减少,势必会对率失真计算结果造成影响。由此可以推断出当MaxNumMergerCand=3时,既有助于使各个候选的JMerge减小,又可以减少由于5个候选bin位数跨度较大而对比较结果产生的影响,使在比较各个候选的率失真结果时更加公平。

表1 列表尺寸(ListSize=5)

表2 列表尺寸(ListSize=3)
(3)在不同的CU尺寸情况下测试各个PU在进行Merge模式时其候选位置出现情况的概率,统计结果如图3~图5所示。
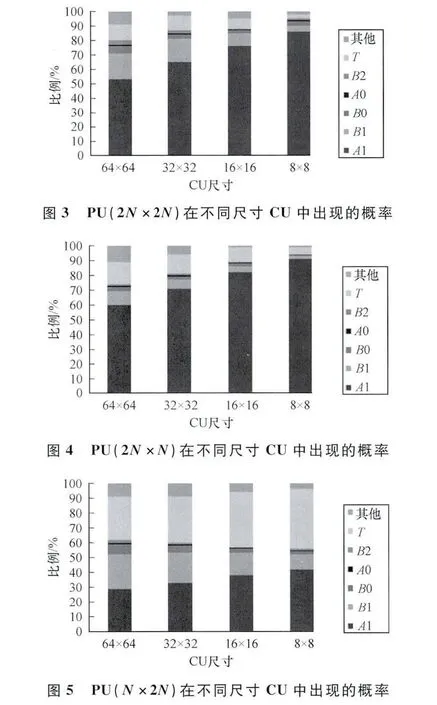
从图3~图5中可以得知,A1,B1,T三者所占比例之和远远高于其他候选之和。这主要是因为A1,B1的bin位数较低,在计算率失真过程中常常占有很大优势,其次B1,A1与B0,A0常常有着相同的运动信息,导致B0,A0在候选过程中无法出现。综上所述,将最大候选数量由5改为3,且在决策过程中优先选择A1,B1,T。
事实上,由于Merge模式的计算结果并不一定是编码过程最终所选取的结果,计算所得的JMerge还要与AMVP模式所得的JAMVP进行比较[12]。它们都只是得到最优结果的一种手段,如图6所示。当出现旋转或者形变运动时,由于Merge模式本身的局限性(主要解决刚体平移运动),就很难对这种运动得到较好的预测,但AMVP模式(预测更为精准,但需要更多的比特)就可以更好地解决其问题,所以适当减少候选数,既能让Merge模式在平移运动中更好地发挥优势,又能在一些非刚体运动中利用AMVP的预测结果,从而不会对整个编码结果造成较大的影响。
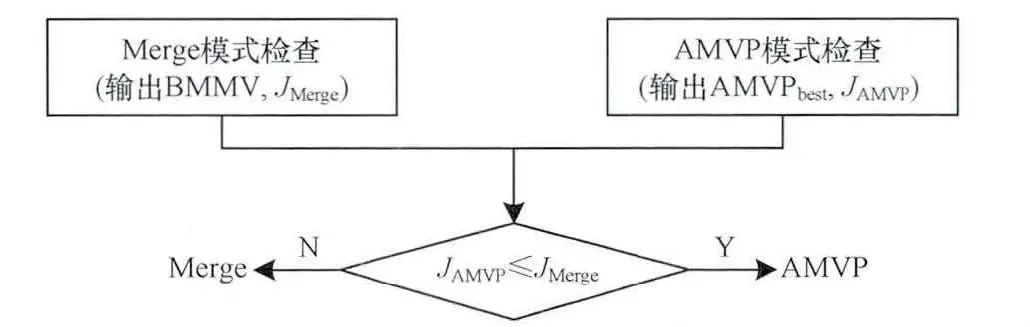
图6 帧间预测的决策过程
另一方面,通过观察图3~图5可以得到:对于2N×N和N×2N这2种情况,T的出现概率会高于B1,且在N×2N中T出现的概率几乎与A1持平。这主要是因为在N×2N中A1是不适用于第2个PU的,而在2N×N中,B1也不适用于第2个PU。如果在这2种情况下分别使用了A1和B1,则会出现2个本来属于同一个CU的PU又融合成了一个CU的情况[13]。所以在这2种情况下T候选的出现几率将得到提升。进一步分析可知,Merge模式主要应用于刚体平移运动,而通常在这种情况下,时间域上的相关性往往大于空间域上的相关性,并且从图3数据得知,T在bin位数较高的情况下,依旧可以有着较高的出现概率。因此,将时间候选T优先于空间候选,即在候选顺序上将时域候选排在空域候选之前,目的是让其分配更小的位数,这样做可以让预测结果更加精确并消耗更少的比特。为了让时间候选放在空域候选之前这一变化发挥更大的作用,还可以考虑通过增加时间候选的个数来提高候选的准确度。
4 改进的低复杂度候选决策
针对上述情况,具体将做出如下改进:
(1)将最大候选集的个数由5改为3,其中空域候选集个数为2,时域候选集个数为1,这样做是考虑到A1和A0,B1和B0有着很高的相似程度。
(2)在进行空域候选时,优先选择A1和B1,看其是否存在并具有冗余,如果存在且不存在冗余,则空域候选集停止继续判断,直接进行时间域上的选择。假如在空域候选集判断出A1和B1有一个不存在或者2个不存在或者存在A1的信息与B1的信息相同,则此时继续依次判断B0,A0,B2,直到空域候选集个数等于2后停止进行判断。如果空域候选集个数小于2,则可以在后续添加双向运动候选和0候选。设NumCand为当前已选候选数量,空域候选的详细流程如图7所示。
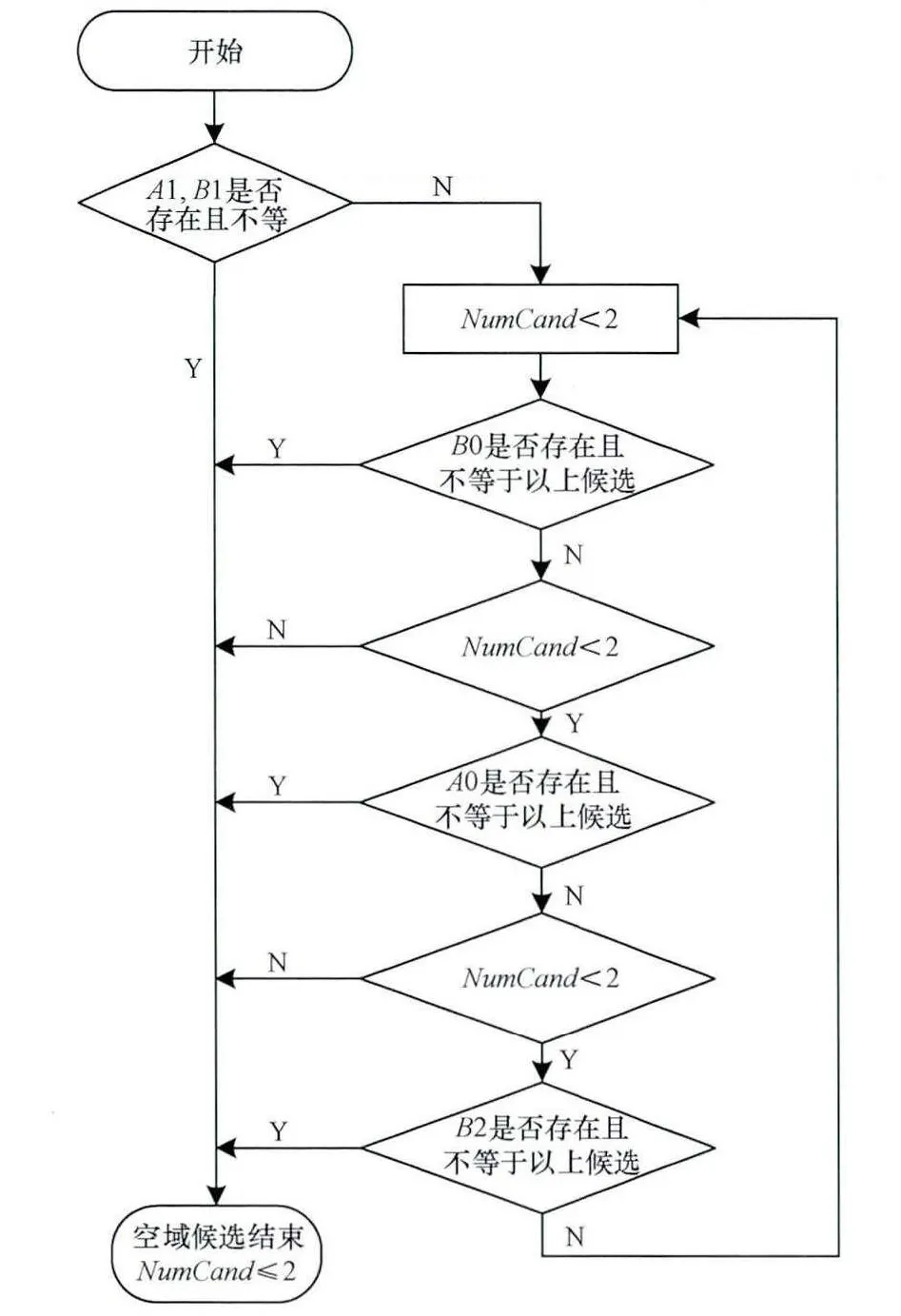
图7 改进后空域候选流
(3)更改候选决策的先后顺序,将时间候选T排在空间候选之前。
(4)当TRb不存在的情况下,通过增加时间域上的候选数量并取其中值,依旧可以较为精确地取得时间候选。具体操作为:如果TRb不存在,将检验参考帧中与当前帧位置相同的B0,A0还有TC,设它们三者的中值为median(B0,A0,TC),并用其代替TC;当B0,A0有一个不存在时,就按照原始算法直接使用TC。这么做的目的是可以将时间候选排在空间候选之前的这一变化发挥更佳的效果。
5 实验平台与仿真结果分析
仿真采用的是HM12.0代码,实验平台为CPU 2GHz Intel Core2,内存2GB,操作系统为Windows 7的64位计算机,运行环境是Microsoft Visual Studio 2010,编码结构为IPPP。实验结果如表3、表4所示,从中可以看出改进后的结果与标准算法结果之间的对比。
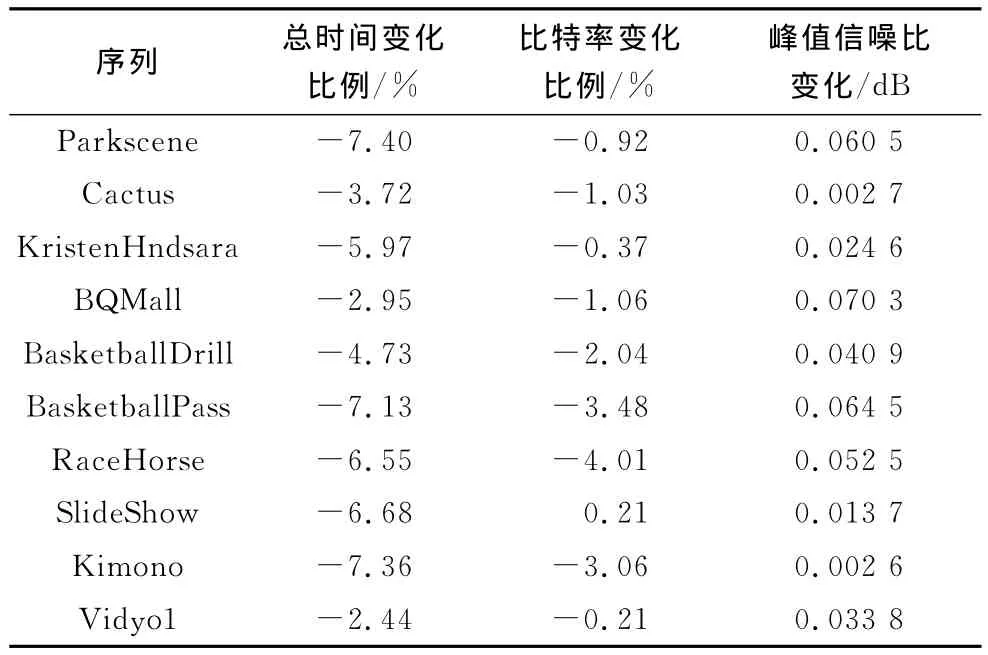
表3 改进前的测试序列
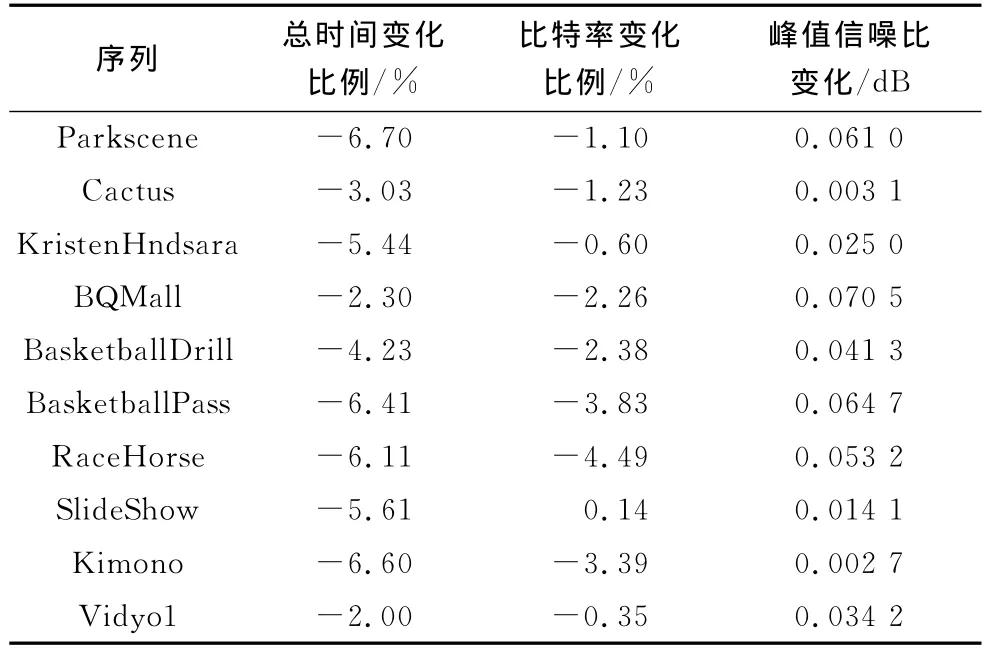
表4 改进后的测试序列
从表3中可以看出,首先通过减少候选数量,直接降低了候选决策的复杂程度,编码时间缩减了大约2.00%~6.70%不等;同时由于 Merge_idx的编码位数相对减少而导致JMerge相应减小,进而在与JAMVP比较中占据一定优势,让原来一部分使用AMVP模式的PU转而使用Merge模式,使得整个过程比特率降低,平均降低了大约0.35%~4.49%不等,并且PSNR值几乎都得到了提升。
加入第4点改进后的仿真结果如表4所示,可以看出,相对表3,增加时间域候选后进一步降低了比特率,从而使率失真性能由于同时提升了复杂度,会损耗更多的时间。注意到SlideShow序列的比特率有轻微提升,这主要是由于其内容多有场景转换,导致时间候选T使用率较低,使得比特率提升。
整体上来看,本文算法在有效提高编码率失真性能的同时,明显缩短了编码时间,降低了编码复杂度。
6 结束语
本文针对HEVC中Merge模式的候选过程进行分析和改进,提出基于候选决策的低复杂度算法。通过减少候选列表的候选数量和改变时空域候选的选择顺序,既降低了计算的复杂度,又提升了各个候选列表的利用效率。仿真结果表明,在图像PSNR略微提升的同时,编码时间和比特率都得到了优化。
[1]ITU-T.Recommendation and Final Draft International Standard of Joint Video Specification[Z].2003.
[2]Tourapis A M,Wu F,Li S.Direct Mode Coding for Bipredictive Slices in the H.264Standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2005,15(1):119-126.
[3]高文赵,德 斌,马思伟.数字视频编码技术原理[M].北京:科学出版社,2010.
[4]ITU-T.H.264and ISO/IEC 14496-2010Advanced Video Coding for Generic Audiovisual Services[S].2010.
[5]Lin Jianliang,Chen Yiwen,Tsai Y P,et al.Motion Vector Coding Techniques for HEVC [C ]//Proceedings of the 13th International Workshop on Multimedia Signal Processing.Washington D.C.,USA:IEEE Press,2011:1-6.
[6]彭金虎,岑 峰.HEVC帧间运动归并技术的研究[D].上海:同济大学,2013.
[7]JCT-VC.Working Draft 4of High-efficiency Video Coding[Z].2011.
[8]Bross B,Han W J,Ohm J R,et al.High Efficiency Video Coding(HEVC)Text Specification Draft 10[Z].2013.
[9]Sullivan G J,Ohm J R,Han W J,et al.Overview of the High Efficiency Video Coding(HEVC)Standard[J].IEEE Transactions on Circuits and System for Video Technology,2012,22(12):1649-1668.
[10]Kim I K,McCann K,Sugimoto K,et al.High Efficiency Video Coding (HEVC)Test Model 9 Encoder Description[Z].2012.
[11]Helle P,Oudin S,Bross B,et al.Block Merging for Quad Tree-based Partitioning in HEVC[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1720-1731.
[12]Vanne J,Viitanen M,Hämäläinen T D,et al.Comparative Rate-distortion Complexity Analysis of HEVC and AVC Video Codes[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1885-1898.
[13]Zhou Minhua.AHG10:Configurable and CU-group Level Parallel Merge/Skip[C]//Proceedings of the 8th Meeting on Joint Collaborative Team on Video Coding.San Jose,USA:[s.n.],2012.
