一种基于FPGA的并行H.264/AVC编码器架构
2015-01-01张建国关则昂刘劲松
张建国,关则昂,徐 渊,刘劲松
(1.深圳市振华微电子有限公司,广东 深圳518060;2.深圳大学信息工程学院,广东 深圳518060)
1 概述
H.264是由视频编码专家组(Video Coding Experts Group,VCEG)联合动态图像专家组(Moving Pictures Experts Group,MPEG)提出的一种具有高压缩效率的视频编码标准[1]。目前国内外对相关编码器设计大多基于专用集成电路(Application Specific Integrated Circuit,ASIC)芯片结构或数字信号处理(Digital Signal Processing,DSP)+现场可编程门阵列(Field Programmable Gate Array,FPGA)编码器解决方案。基于FPGA芯片实现该系统既具有ASIC强大的运算能力优势,同时又有类似DSP的灵活性,已成为新一代的H.264编码器实现方案。而且,多数相关课题只基于FPGA实现H.264编码器内部分功能设计及优化,如新型运动估计结构[2-3]等研究。
本文在Xilinx的FPGA芯片上实现基于基本画质层次的整个编码系统,并针对高分辨率视频处理采用并行处理、高度吞吐量优化设计,对1080P,720P等高清视频进行实时编码处理。
2 H.264/AVC预测编码原理
编码器预测编码由帧内(I帧)与帧间预测(P帧)组成,本文对于I帧编码部分实现3种预测模式:水平,垂直以及均值预测,帧间编码实现P帧预测。
2.1 帧内预测
帧内预测中对于亮度域提供2种编码模式:基于4×4[4]和16×16块编码。前者共有9种预测模式,如图1所示,一般适用对存在大量细节的图像编码,而后者仅4种预测模式,适用于图像中较平坦区域的编码[5]。
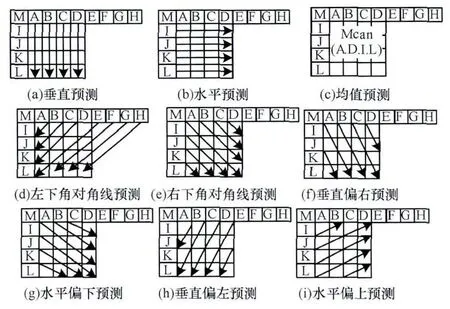
图1 亮度域的9种预测模式
如图1所示,4×4块周边相邻像素(A~L)是已编码与重构后像素,作为当前4×4块的预测参考像素。系统分别对9种预测模式进行预测,找出误差最小的一种预测模式。由于人眼视觉系统对色度变化的敏感性较低,只对色度定义了4种预测模式,且与16×16亮度块相似,只是对应的模式编码不同。
2.2 帧间预测
将当前编码图像视为当前帧,其前一帧视为参考帧,以宏块(16×16)为单位在参考帧中搜索出与当前编码宏块最相似的参考块,该过程被称为运动估计。而在目前提出的各种搜索算法中,全搜索方式下得到的效果更加准确,硬件结构也较易实现[6-7]。
2.2.1 运动估计
全搜索方式中的可变块大小运动估计(Variable Block Size Motion Estimation,VBSME)是 H.264标准的一种新型编码技术[8-9]。相比固定的块大小,VBSME更加适合小型和不规则运动区域搜索,能够更好地估算和适应运动边界。VBSME中每个宏块可以被分为P_16×16,P_16×8,P_8×16,P_8×8 4种一级宏块类型,而P_8×8又可进一步分为P_8×8,P_8×4,P_4×8,P_4×4 4种二级宏块类型共41个子块。运动估计就是基于可变块方式,在搜索窗内依次提取相应的参考块与编码块进行匹配,两者之间相对差值(Sum of Absolute Difference,SAD)[10]最小的为预测块,搜索完成后得到41个子块的最小相对差值(Minimum-SAD,MSAD)以 及 对 应 的 运 动 矢 量(Motion Vector,MV)(Vx,Vy),算法流程如图2所示。
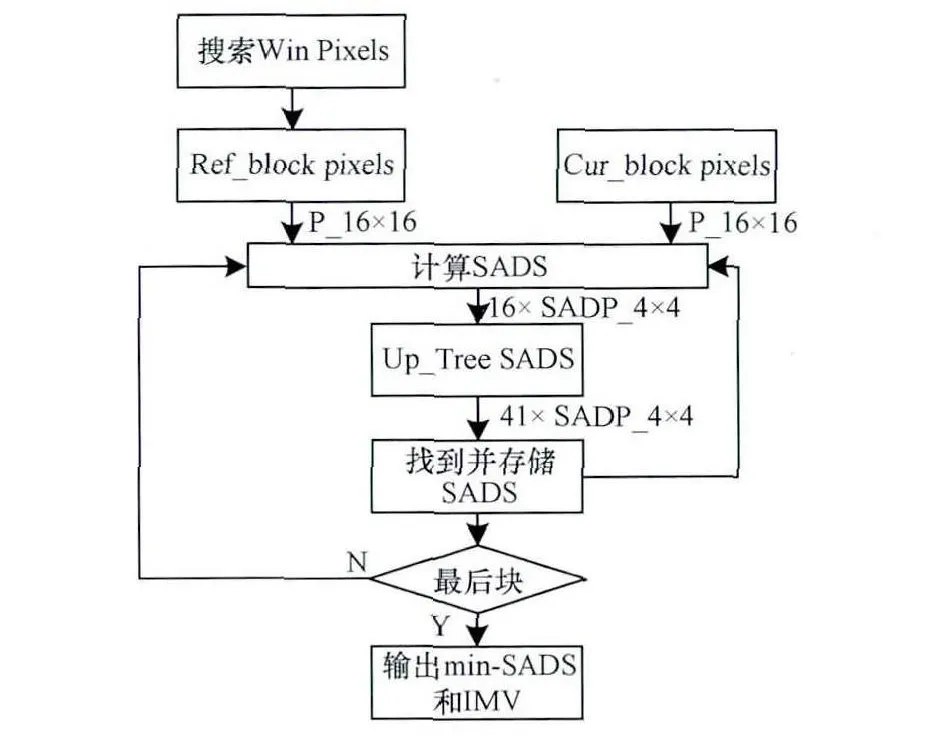
图2 运动估计算法流程
2.2.2 预测模式选择
宏块预测模式选择是以宏块为单位,分别对不同宏块分割模式下的编码代价量(COST)作评估,选择COST最小的一种分割模式。经运动估计处理分别得到了41个子块的MSAD和MV后,根据式(1)计算出宏块在不同分割模式下的对应若干子块的COST,并累加得到整个宏块的COST,最后比较得到代价量最小的一种分割模式,该模式为预测模式。
对COST的一般评估算法是仅以MSAD作为宏块的代价量,但H.264标准的编码码流同时包括了宏块的预测模式、运动矢量以及残差块数据等信息,所以该方式不能准确地评估出宏块编码的代价量。本文以宏块的MSAD和MV同时作为评估因素,能够更准确地预测出代价量最小的宏块分割模式。
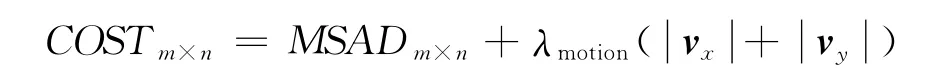
其中,MSAD表示不同分割模式下的子块最小相对差值;vx和vy为对应的运动矢量,都由运动估计计算得到。
另外,λmotion为运动矢量的平衡系数,取值与量化步长QP相关,其作用是平衡运动矢量部分的代价量与MSAD代价量之间的比重,目的是让总代价量均衡地反映在2个编码因素上。
2.2.3 运动补偿
编码码流中的残差数据由编码宏块和参考块的相差得到,该过程称为运动补偿,如图3所示。经过模式选择后得到宏块编码的运动矢量和预测模式,运动补偿根据该结果在搜索窗内提取对应的参考块并与编码宏块相差产生残差块。以图3为例,经过模式选择得到编码宏块的分割模式为P_8×8,根据MV在参考帧内找出各参考子块组合得到参考块,并与编码宏块相差得到残差数据块。
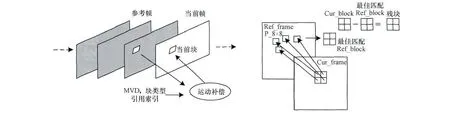
图3 运动补偿示意图
3 H.264/AVC硬件系统研究与分析
图4为H.264编码器的系统框图,系统采用多通道数据读写方式从双倍率存储器(Double Data Rate,DDR)读取原图像的编码数据。同时对系统采用分时域共工作模式,在读写模块给予较高的时钟驱动,快速读取编码数据。整个编码系统可分4个部分:帧内预测,帧间预测,变换编码以及系统控制。其中,帧间预测主要包括了运动估计(图4中IME)以及运动补偿(图4中MC)模块。系统控制(图4中TopCtrlSM)模块负责系统的顶层控制,包括I帧和P帧预测的切换、编码图像设置、码流头信息生成等。

图4 H.264编码系统
3.1 系统参数
TopCtrlSM为整个系统的控制单元,同时也是微控制单元(Micro Control Unit,MCU)控制与系统硬件的通信模块,MCU可配置知识产权(Intellectual Property,IP)内部参数寄存器(图像尺寸等)和状态寄存器。
IP系统对外进行数据交互时,采用了典型的双向握手机制,即在接收数据时时刻反馈内部存储状态,信号有效可接收数据。从图4可看出,系统编码后的码流数据由先入先出队列(First Input First Output,FIFO)存储并输出,规范的对外通信接口使得外部只需简单的握手设计就可以调用该IP。在系统内部,模块之间均使用有效的握手信号进行数据传递,并使用FIFO对数据进行存储,以避免处理过程相邻模块处理速度不同步所引起的冲突。
3.2 帧内预测硬件结构
图5为帧内预测的功能模块分布图,整个预测过程为:由CtrlSM模块控制生成随机存储器(Random Access Memory,RAM)的读写地址,图中不同的RAM分别存储编码数据、预测参考数据(上方相邻行数据和左边相邻列数据),输出到差值计算模块,并比较得到预测模式以及对应的残差数据。
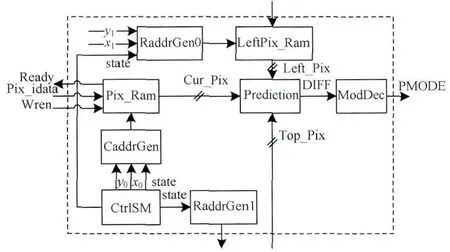
图5 帧内预测结构
数据缓存模块由RAM构成,并由控制模块CtrlSM根据预测模式(水平、垂直和均值预测等)控制生成RAM的读地址,分别在RAM中读取相应的参考数据进入预测模块,得到不同模式下的差值后通过预测模块进行选择,输出预测模式。
CtrlSM生成整个帧内预测系统控制信号,分别控制了编码块的数据请求、相邻参考像素读取、残差数据有效输出以及内部模块的反馈信号处理,保证帧内预测系统有条不紊地进行,状态图如图6所示。

图6 帧内预测状态图
帧内预测系统共有5个状态,如图6所示,其中,“001”为编码数据准备状态,该状态下判断内部RAM的编码数据是否足够,满足条件后跳转状态进行帧内预测操作。而当处于状态“010”,判断是否预测参考数据以及系统外部状态空闲,满足后进而判断是否已完成宏块内全部子块预测,即返回初始状态开始预测下个宏块,否则对当前宏块内下一个子块进行预测操作。
3.3 帧间预测硬件结构
设计采用全搜索设计,搜索窗为32×32,以单个像素点为步长,Meander蛇形(左上角点为起点,依次下移-右移-上移-右移……)搜索路线依次取尺寸对应(16×16)的参考块与编码宏块进行匹配,相差进而比较找出参考预测块。
3.3.1 运动估计处理架构
图7是帧间预测系统的结构框图,包含2条数据路径:参考块路径以及编码块路径。图中搜索窗的存储模块(Buffer Zone)输入数据由16个像素组成位宽为128bit。由于在宏块的搜索过程中会出现新的参考块,16_Rb_ram_stripe将输出的参考块新数据重新排列,组成新参考块的一行数据(16×8 bit),RB_shift_reg_array是一个存储参考块的移位寄存器,基于蛇形搜索特点,相邻参考块只有16个像素的新数据,所以只需将下一个参考块的新数据与RB_shift_reg_array内部的可用数据进行重新移位排列,组成下一个参考块进入PE阵列进行差值计算:PE阵列实现参考块与编码宏块的差值计算,该阵列由16个4×4运算阵列组成,仅需一个周期即可得到差值结果。
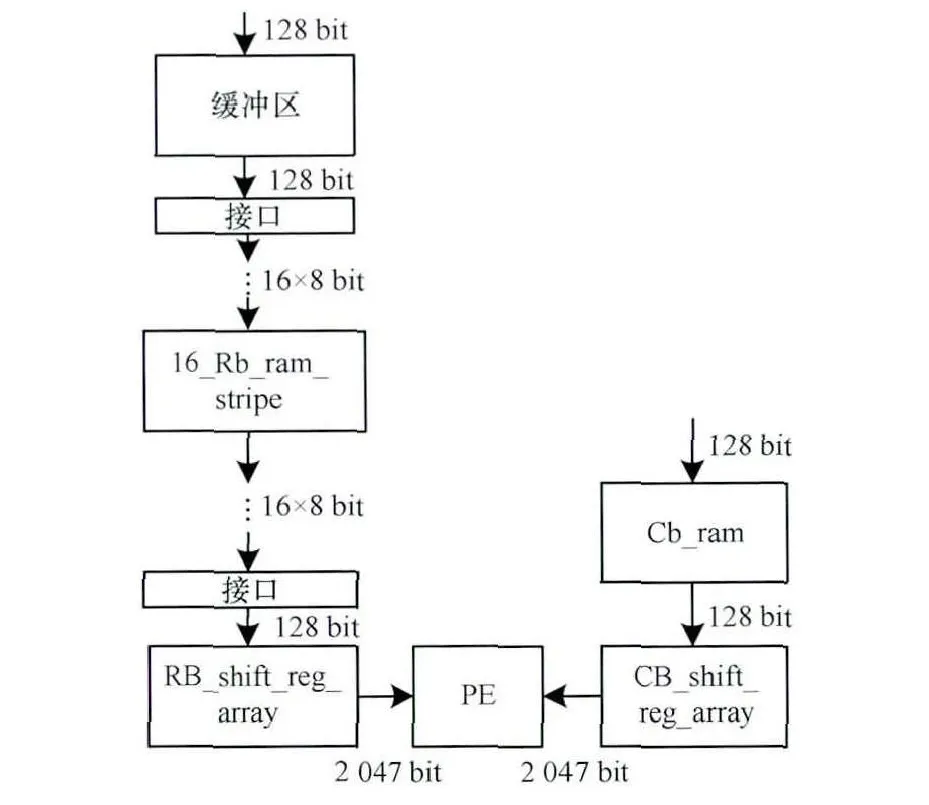
图7 整数运动估计结构
图8是搜索窗数据结构,包括2个存储单元,存储内容相同但用处不同。为对相邻编码块搜索窗的数据复用,内部存储一个48×32的数据块,该块包含了当前编码块的全部搜索窗数据以及下一个编码块的部分搜索窗数据,以实现数据复用。当在进行第n宏块搜索时,同时将第n+1宏块对应的部分搜索窗新数据覆盖掉第n宏块与第n-1宏块不重合的搜索窗数据,如此类推。另外,由状态机控制2个存储单元的读地址,Rb_buf0输出参考块上移及下移的新数据,Rb_buf1输出右移的新数据,存储单元内部机制如图9所示。

由于相邻编码宏块存在共同的搜索窗区域,适当的数据复用设计以减少新数据的读取次数是必不可少的。该架构由16条位宽为8bit的存储条构成,每次将128bit的输入数据分为16个8bit分别存储到各存储条中。在搜索过程中,参考块在上移和下移时的新数据由图中Crossbar接口输出,而每次右移时的数据可在其前一次上移或下移过程中控制输出,并由图中串转并接口模块寄存。这样的存储结构使得无论在参考块的上移、下移或右移下都只需简单的地址计算就能够在存储单元中提取出对应的新数据,无疑节省了搜索操作的时间,将复杂的结构简单化,图10为存储条数据在搜索窗内的位置。

图10 相邻宏块搜索窗
3.3.2 运动补偿结构设计
运动补偿是基于运动估计得到的宏块信息在搜索窗内锁定参考块,并与编码宏块相差得到残差块数据。
运动补偿先将搜索窗以及编码块数据进行暂存等待读取,为了节省数据读取的时间,内部分别设计了编码宏块与搜索窗数据双缓存机制,并有专门的控制电路实现读写控制操作。图11中的虚线内部分为存储单元组,通过控制选择信号进行切换读写。

图11 运动补偿内部存储结构
在完成数据存储进入处理阶段,双缓存机制能够有效提高系统的数据处理速度。图12对单通道与双通道缓存方式的工作模式进行了比较,对模块内部处理工作时域进行分析,整个处理的耗时控制为T1,与单缓存耗时T0相比,节省了数据写入时间(T2=T0-T1)。其他编码模块在设计上均采用流水线处理方式,并且各级模块间采用通用的数据接 口设计,保证了数据处理速度。
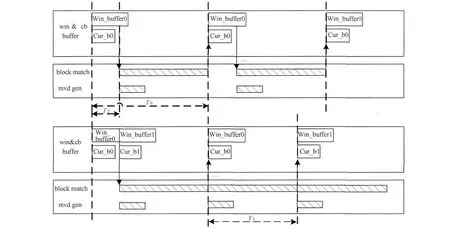
图12 运动补偿内部结构时域分析示意图
4 H.264/AVC编码器性能与效果
4.1 功能模块性能评估
以Xilinx公司的Virtex-6芯片为测试平台,表1列出了编码器内部所有模块的硬件综合信息,以及所能够支持的最大时钟频率。可以看出经过时序优化的系统内部各模块的最大可支持时钟频率较高。
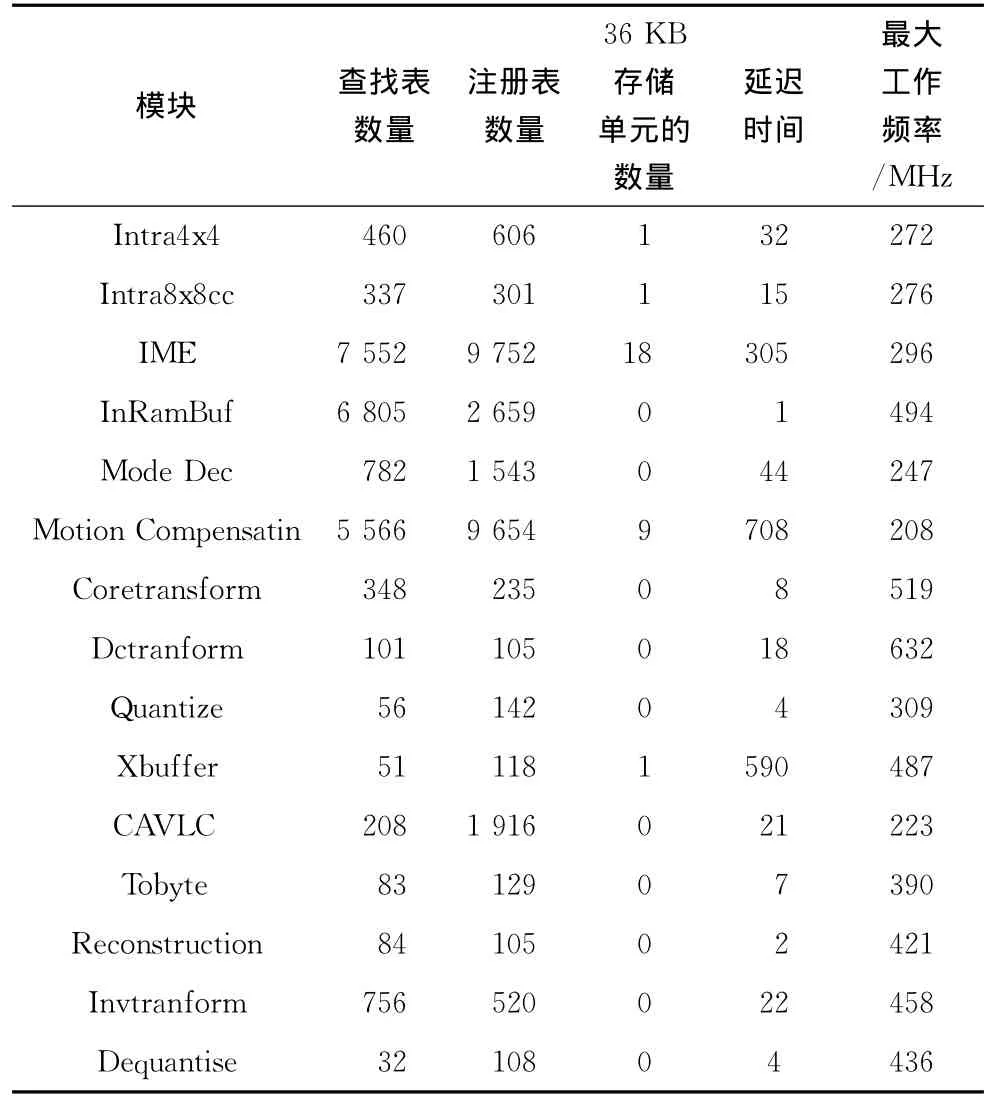
表1 编码器综合信息
4.2 系统性能评估
经过对硬件系统完成时序与布局布线优化后,得到H.264硬件编码器的FPGA资源利用量如表2所示。从资源列表可以直观看出该硬件系统的LUT利用率为28%,36 KB与18 KB的BRAM利用率分别为24%和5%,总体上该硬件编码器FPGA资源占用量较少。

表2 编码器硬件资源
4.3 视频编码效果
表3为H.264编码器实现的编码效率,实验结果表明编码器对720P图像的编码速度能够达到每秒34帧,具有较理想的编码速率,充分体现了高度实时性的压缩性能,同时能够保证较好的图像质量。
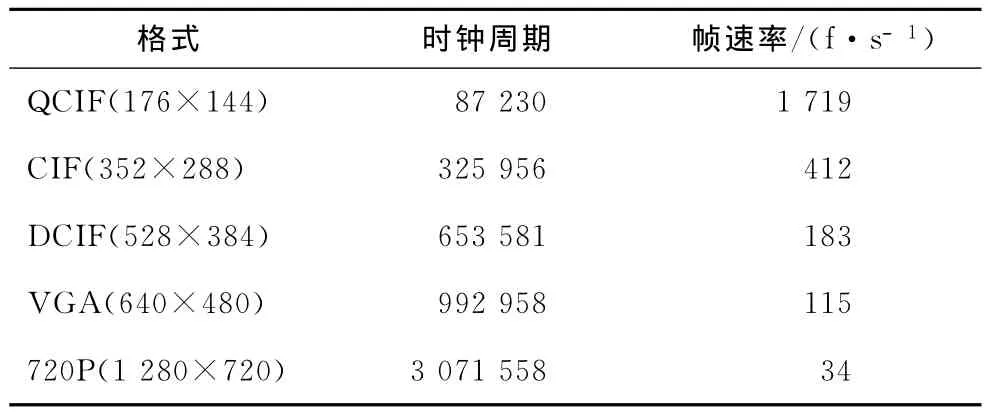
表3 编码性能实验结果
配置尺寸参数分别对图13(720P)格式视频进行编码,其中图片中右边的图像显示了解码后得到的图像,画质较好。本文实现的FPGA全硬件H.264编码器具有高清视频的实时编码能力,与文献[11]提出的以FPGA作为协处理器与DSP芯片共同实现的编码器相比,两者虽具有相近的处理能力,但本文提出的FPGA全硬件具有成本优势,同时系统升级性强。另外,文献[12]与本文实现方式相似,同样采用FPGA实现硬件编码,但其采用的是钻石搜索算法,图像质量较低,且系统框架较复杂,不方便系统升级。

图13 720P格式编码图像
5 结束语
本文分析国内外视频编码技术发展历程,实现了一种具有高压缩效率的编码器——H.264/AVC,并基于FPGA实现H.264/AVC基本画质层次的全硬件系统设计。为解决编码器的高编码效率及高实时性问题,在系统硬件设计中广泛采用并行处理架构。实验结果表明,本文实现的硬件编码器可以使得720P图像中的编码速度达34帧,且编码后的图像质量较好,适用于高清视频监控、视频文件压缩等领域。另外,可针对编码效率对系统多方面进行升级,如对运动估计扩展到小数像素级、动态码率控制等,以进一步减少编码后的码率,这是下一步工作需要考虑的问题。
[1]刘志刚.基于FPGA的 H.264编码器的硬件的实现[D].西安:西安电子科技大学,2009.
[2]Kao Chao-Yang,Lin Youn-Long.A Memory-efficient and Highly Parallel Architecture for Variable Block Size Integer Motion Estimation in H.264/AVC[J].IEEE Transactions on Very Large Scale Integration Systems,2010,18(6):866-874.
[3]Xu Yuan,Liu Jinsong,Gong Liwei,et al.A High Performance VLSI Architecture for Integer Motion Estimation in HEVC[C]//Proceedings of the 10th International Conference on Control & Automation.Washington D.C.,USA:IEEE Press,2013:1-4.
[4]周 巍,周 欣,段哲民.基于 H.264/AVC的帧内4×4预测模式快速选择算法[J].西北工业大学学报,2012,30(3):440-444.
[5]裴世保,李厚强,俞能海.H.264/AVC帧内预测模式选择算法研究[J].计算机应用,2005,25(8):1808-1810.
[6]Zhang Li,Guo Wen.Improved FFSBM Algorithm and Its VLSI Architecture for Variable Block Size Motion Estimation of H. 264 [C ]//Proceedings of International Symposium on Intelligent Signal Processing and Communication Systems.Washington D.C.,USA:IEEE Press,2005:445-448.
[7]Kim J,Park T.A Novel VLSI Architecture for Fullsearch Variable Block-size Motion Estimation[J].IEEE Transactions on Consumer Electronics,2009,55(2):728-733.
[8]Chen Ching-Yeh,Chien Shao-Yi,Huang Yu-Wen,et al.Analysis and Architecture Design of variable Blocksize Motion Estimation for H.264/AVC[J].IEEE Tran-sactions on Circuits and Systems I,2006,53(3):578-593.
[9]Kuo Tien-Ying,Chan Chen-Hung.Fast Variable Block Size Motion Estimation for H.264Using Likelihood and Correlation of Motion Field [J].IEEE Transactions on Circuits and Systems for Video Technology,2006,16(10):1185-1195.
[10]Li Dongxiao,Zheng Wei,Zhang Ming.Architecture Design for H.264/AVC Integer Motion Estimation with Minimum Memory Bandwidth [J].IEEE Transactions on Consumer Electronics,2007,53(3):1053-1060.
[11]Nirmalkumar P,MuraliKrishnan E,Gangadharan E.Enhanced Performance of H.264Using FPGA Coprocessors in Video Surveillance[C]//Proceedings of International Conference on Signal Acquisition and Processing.Washington D.C.,USA:IEEE Press,2010:157-161.
[12]Atitallah A B,Loukil H,Masmoudi N.FPGA Design for H.264/AVC Encoder[J].International Journal of Computer Science,Engineering and Applications,2011,1(5):119-138.
