基于帧内预测模式的HEVC音视频同步算法
2015-01-01王晓东王让定章联军
徐 辉,王晓东,王让定,章联军
(宁波大学信息科学与工程学院,浙江 宁波315000)
1 概述
随着数字多媒体通信与传输技术的发展,视频会议、远程教学、视频点播等多媒体服务已经广泛应用于生活的各个方面。然而在网络传输过程中会受到复杂网络坏境的干扰,如网络延时、抖动等因素[1],导致多媒体出现不同步的现象,而音视频同步作为其中的一个关键性技术越来越多地受到人们的关注。
为了解决音视频同步问题,传统的非嵌入式音视频同步方案有基于时间戳[2]和同步标记[3]来实现的;也有借助多线程和多路复用思想[4],在接收端把音视频流分开,但复用后的音视频流解码会使得音视频流的质量严重下降。国际上,针对视频会议和可视电话等应用中的同步问题,相关学者提出了包括语音辅助视频插补[5]、交叉模式预测编码[5]及同步视频帧自动生成[6-7]等方法,该类算法中人的嘴部定位较难,且需要人参与。
以上非嵌入式的音视频同步方案对解码器要求较高,且算法复杂度较高。针对这个问题,近年来有很多学者借鉴基于H.264的信息隐藏和视频水印的思想,将音频信息嵌入视频中进行同步编码,在解码端提取音频编码数据并重构音频,最终实现同步。如文献[8-9]通过修改离散余弦变换(Discrete Cosine Transform,DCT)系数建立待嵌音频信息与DCT系数之间的映射关系,但该类方案会因系数的修改而造成视频码率失真较大。为此,文献[10]在H.264运动估计的过程中通过调制1/4像素精度的最优运动搜索点的奇偶性建立相应匹配关系,降低了对视频质量的影响,但同时会引起帧间失真漂移。文献[11]通过修改CAVLC(Context Adaptive Variable Length Coding)熵编码高频拖尾系数和非零系数将音频嵌入其中。该方法可以保持码率稳定,但仍会因误差累计而造成视频质量下降,导致音频信息无法正确提取。为避免对视频质量造成较大影响,文献[12]提出基于帧间预测模式嵌入音频的算法,但该算法嵌入数据容量较小,每个宏块只有2bit。在文献[12]的基础上,文献[13]提出一种可变尺寸块嵌入音频编码数据的方法,平均每个宏块嵌入2.67bit数据量,提升了嵌入容量,也保证了音频数据的准确性。
基于上述分析,目前绝大部分嵌入式音视频同步算法都是基于MPEG-x和H.26x的,但随着人们对高清、超高清视频需求的增加,H.264/AVC标准已无法得到满意的压缩性能,其对高清以及超高清视频的音视频同步处理效果不佳。HEVC作为最新一代应用于高清、超高清视频并具有更高编码性能的视频压缩编码标准正变得越来越流行[14],旨在H.264/AVC的基础上提高编码效率,并在节省码率方面具有显著优势[15]。因此,基于HEVC的音视频同步算法的研究具有理论价值和现实意义。然而,目前基于HEVC的音视频同步算法研究尚处于起步阶段。
本文结合HEVC帧内编码技术,针对上述方法和标准应用的局限性,通过分析帧内预测模式的相关性,引入可变长编码的思想,建立预测模式和音频码组之间的双映射关系,根据匹配关系修改帧内预测模式来嵌入音频信息。在解码端,只需根据解码得到预测模式,对照映射关系,提取音频信息即可。
2 HEVC帧内编码
2.1 HEVC帧内编码结构
HEVC与上一代编码标准H.264/AVC的编码框架相似,但不同的是帧内编码采用了基于四叉树结构的编码技术和多角度预测技术[16]。与H.264/AVC不同的是HEVC使用编码单元(CU)、预测单元(PU)和变化单元(TU)3种更灵活的编码元素来描述整个编码过程。CU是每一帧视频编码的基本单元,CU的尺寸按四叉树递归的方式,根据深度的不同可以分为64×64,32×32,16×16,8×8。每个深度的CU中,多个尺寸的PU进行预测,而PU又包含多个尺寸的TU。如图1所示,一个视频帧首先被划分为64×64的非重叠的编码树单元CU,然后通过递归分解的方式,依次将CU划分为4种不同深度的CU,例如当CU的深度depth为n(n=0,1,2,3),且划分标志位flag为1时,则将其划分为4个尺寸为原CU四分之一大小的CU块,此时深度值depth为n+1。直到CU的尺寸为8×8,深度depth为3时,其预测单元PU的尺寸可以继续划分为4个尺寸为4×4的预测块。
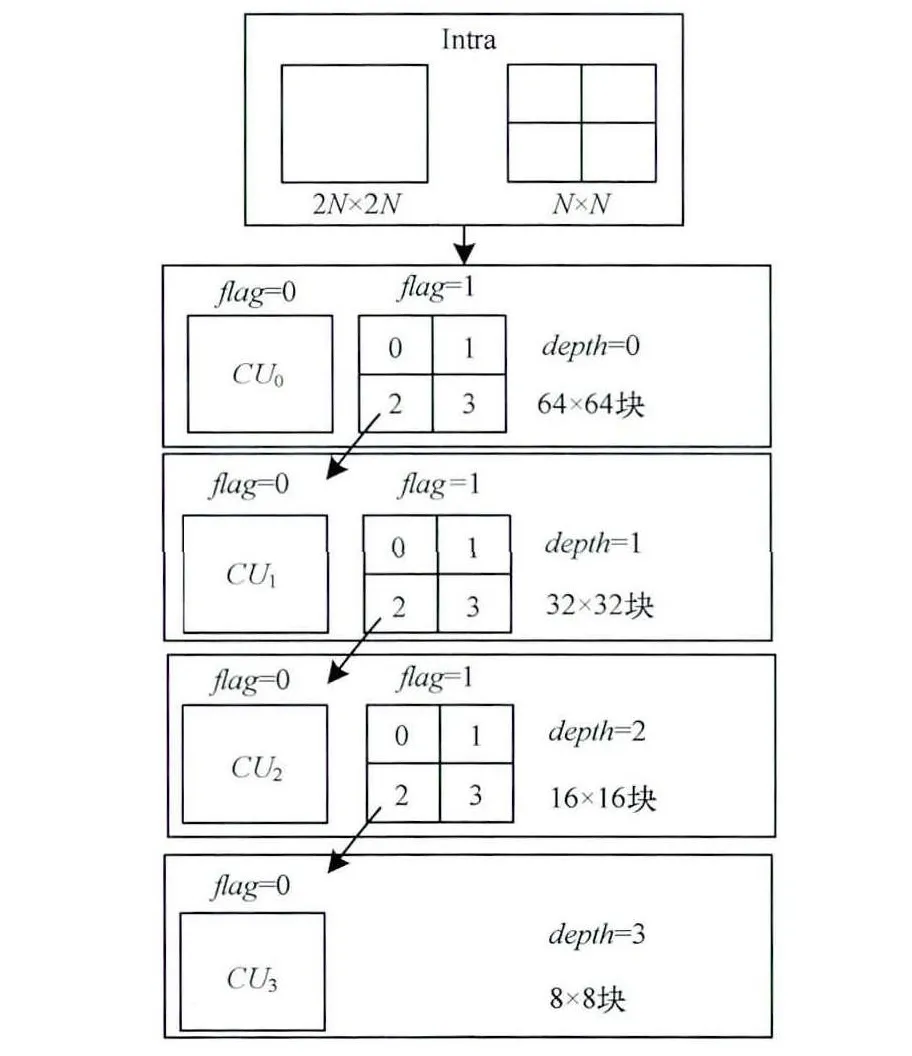
图1 LCU四叉树划分过程
2.2 帧内预测
和H.264/AVC帧内预测原理类似,HEVC利用像素点在空间上的相关性,当前块的像素值通过相邻已编码并重建块的边界像素值进行预测。但与H.264/AVC帧内预测不同的是,如图2所示,HEVC在相邻方向预测模式的角度差减小的基础上将方向提升到35种。

图2 HEVC的35种预测模式
更为细小的角度划分,使得帧内预测更加精准[17],为了从35种预测模式中,有效选择最优预测模式,HEVC采用了基于率失真优化(Rate Distortion Optimization,RDO)准则,遍历所有编码预测模式,通过Lagrangian函数选择出率失真代价最小的模式作为最佳预测模式,代价函数定义如下[14]:
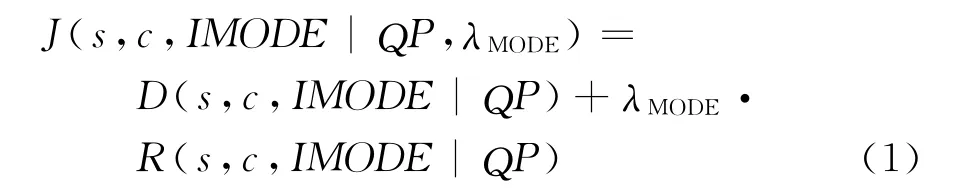
其中,QP为量化参数;D为失真度;λMODE为拉格朗日乘数;S为源视频块;C为重建视频块;R为编码码率。
3 同步算法实现
本文算法通过调制满足双映射关系的帧内4×4亮度块的最优预测模式进行音频信息嵌入、提取和重构。在分析预测模式相关性的基础上,对预测模式进行分组,根据读取的变长音频码组的长度,选择对应的映射关系,通过调制预测模式组中满足嵌入条件的4×4亮度块的预测模式,实现音频信息的嵌入。音频信息的提取只需根据双映射关系对码流中的预测模式解码即可。
3.1 帧内预测模式相关性分析
文献[18]在分析帧内预测模式方向特性时指出,H.264帧内预测时,相邻方向预测模式之间具有很强的相关性,最优预测模式与次优预测模式之间有类似的预测方向。HEVC相比H.264帧内预测,其将预测模式扩展到35种,相邻方向角度差相应也缩小了,因而基于空间相关性的原理,相邻方向预测模式的差异性不会很大。基于此分析,文献[19]通过实验测试得出:同组候选预测模式具有彼此方向相邻的特点,对于planar模式和DC模式,如果当前预测单元没有明显的方向性,由于其均匀平滑的特性,则此2种非方向性的模式很可能成为最优模式。因此,文献[20]在文献[19]论证帧内预测模式具有相关性的基础上,当最优预测模式Best_Mi(i=0,1,…,34)确定的情况下,统计次优预测模式Sub_opt_Mi(i=0,1,…,34)的概率分布,进而指导预测模式的分组。
本文算法利用文献[20]统计分析的思想,从HEVC标准视频库中选取BasketballDrive,Cactus,PeopleOnStreet等9个分辨率从1 920×1 080像素到2 500×1 600像素的高清视频序列,分别统计各视频序列在帧内预测过程中,最优预测模式确定后,其次优预测模式的平均分布情况。表1所示的是测试60帧时部分预测模式的前4个次优预测模式的分布情况。

表1 次优模式分布
从表1中可以看出,相邻方向预测模式成为次最优预测模式的可能性很高。如最优预测模式为5时,次最优预测模式往往是与其相邻的模式6或者模式7。
3.2 帧内预测模式划分
本文提出的基于HEVC的帧内音视频同步算法,根据音频信息与预测模式之间的映射关系,通过修改帧内预测模式来实现音频的嵌入。为使预测模式修改后的视频质量接近原始视频的质量,同时能实现较大容量的音频信息嵌入,本文根据相邻预测模式相关性分析结果,在最优预测模式确定的前提下,将具有相近预测效果的4个预测模式分为1组。
在预测模式划分的过程中,考虑到部分次优预测模式分布不均以及预测模式之间重叠程度不同,本文将次优预测模式出现概率在50%以上的4个模式(Sub_opt_M0,Sub_opt_M1,Sub_opt_M2,Sub_opt_M3)与当前最优预测模式Best_Mi构成一个集合Si(i=0,1,…,34),对应帧内的35种预测模式会形成35个集合。根据集合的运算规则,任意4个集合之间进行相与得到共同元素,依此原则,当预测模式组中的预测模式达到4个时,就将此4个具有相近预测效果的预测模式Ni(i=0,1,2,3)划分为一个预测模式组Classi={N0,N1,N2,N3}(0<i<12)。如表2所示,根据预测模式的相关性将35种帧内预测模式分为11个预测模式组。
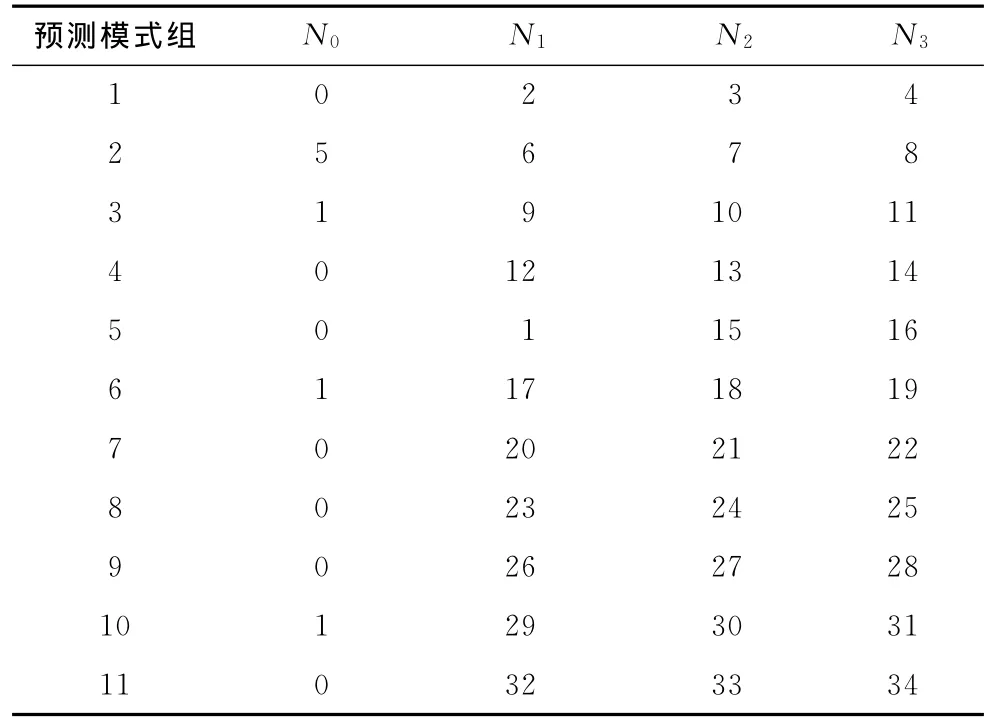
表2 预测模式分组
3.3 音频信息可变码长分组
针对每个预测模式组中4个具有相近预测效果的预测模式,建立其与待嵌音频之间的匹配关系。如果模式组中的每个预测模式表示2 bit的信息数据,分别是00,01,10,11,则不能满足较大容量的音频信息的嵌入;如果每个预测模式表示3 bit的信息数据,将相邻3 bit信息分为1组,共有000,001,010,011,100,101,110,111这8种组合,这样只能从8种组合中选取4种,如此会导致音频信息无法完整、正确地被嵌入并提取。针对这种等长信息分组不具备普遍适应性的缺陷,文献[13]引入可变码长的概念,针对H.264帧间7种预测模式,将音频信息分为若干2 bit和3 bit的分组,实现音视频同步。该变长分组的算法保证了音频信息的完整性和正确性,并且可以实现较大容量的嵌入。受文献[13]的启发,本文对exp-Golomb编码K值进行修改,根据读取音频信息长度为2或3,分别将K值修改为4或8,其具体变长算法修改如下:
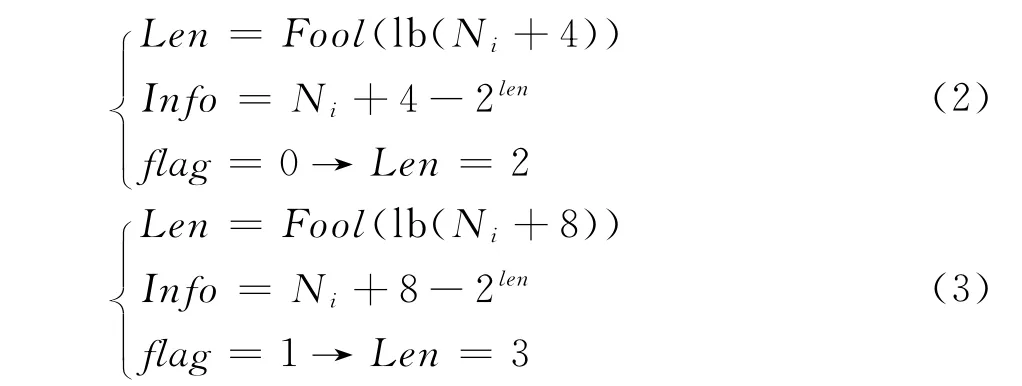
其中,Ni表示预测模式编号,令Ni=i(i=0,1,2,3);Len为信息组长度;Info为嵌入信息十进制数值;Fool(.)为向下取整函数;flag为标识位,用于标识读取信息长度。
在编码过程中,读入二进制音频信息,然后将信息分为若干2 bit和3 bit的变长分组,考虑到每个预测模式组中有4个预测效果相近的预测模式,为保证嵌入信息的完整性和正确性,建立如图3所示码字的双映射关系,每个2 bit信息组和3 bit信息组均包含4个元素。其中,2 bit信息分组为:Fi={00,01,10,11};3 bit信息分组为:Mi={000,001,010,011}。当读入信息长度为2时,flag标志位置0,进行Fi→Ni;当读入信息长度为3时,flag标志位从0置1,进行Mi→Ni映射。
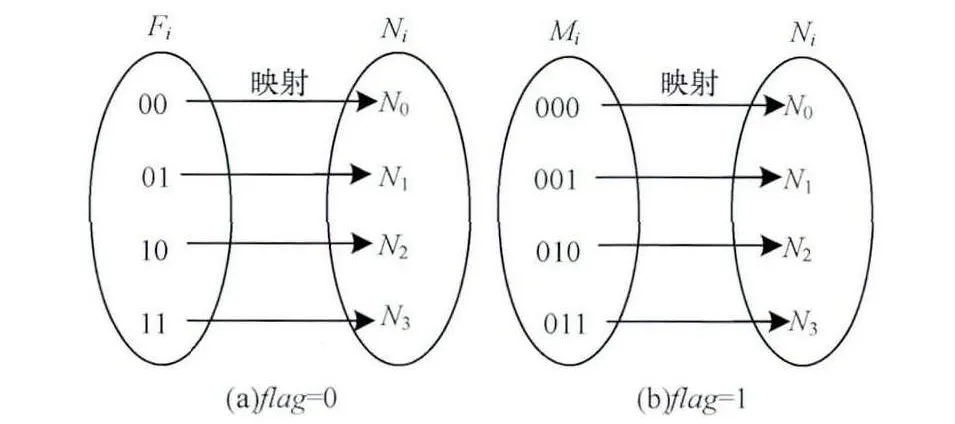
图3 预测模式与音频码组双映射关系
根据式(2)、式(3)可得到如图3的预测模式映射关系,如当flag=0时,Len=2,最优预测模式所在模式分组的模式编号Ni=2时,由式(2)得出Info=2,其他映射关系也根据式(2)或式(3)求得。
3.4 音视频同步编码
3.4.1 音频信息读取
本文在帧内预测过程中选择纹理比较复杂的4×4块嵌入音频数据。将经过G.729编码压缩后的音频数据转换为二进制数值,每次根据标志位的变换读取2bit或3bit数据。二进制音频数据Fi(Mi)表示为(Fi)2或(Mi)2,嵌入音频数据的十进制记为:(Info)10。数据分组及映射模式组如图4所示。
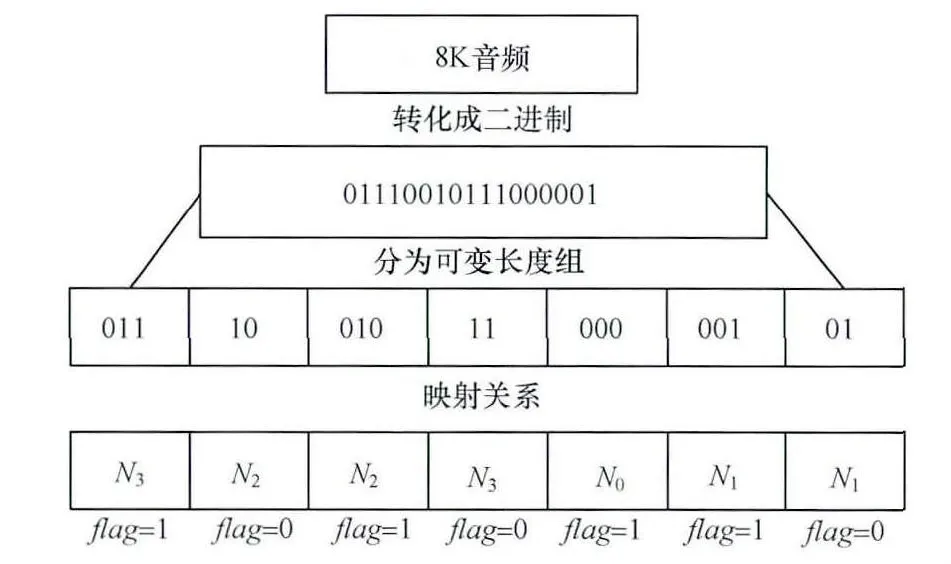
图4 数据分组及其映射模式组
读取音频信息的流程可分为3步:
Step1读取3bit音频信息,标志位flag=1,如果读取音频数据(Info)10>(011)10,标志位flag=0,并进入Step2;否则,根据Len=3和(Info)10值求得Ni,进行Mi→Ni映射,根据表2得到相应的预测模式,然后进入Step3。
Step2flag=0,读入2bit音频信息,根据Len=2和(Info)10求得Ni,进行Fi→Ni,根据表2得到相应的预测模式,并输出标志flag=0,然后进入Step3。
Step3读取位置向前移动Len个位置,重复Step1的操作。
读取到音频数据末尾时,如果余下单比特数据,根据预测模式的奇偶对应关系进行映射。当结尾数据为0时,预测模式Ni为偶模式,则直接嵌入;否则,预测模式Ni为奇,则选取预测模式组Classi中为偶的次优预测模式Nj替换,然后对替换后的预测模式进行重编码。
3.4.2 音频嵌入过程
本文提出的算法旨在根据帧内预测模式的相关性建立预测模式组和音频信息之间的双映射关系,实现音频信息的嵌入。根据音频信息可变长分组及其读取规则,音频信息嵌入的整个流程如图5所示。

图5 音视频同步编码过程
具体步骤如下所述:
Step1将经过G.729语音编码标准压缩编码的音频信号转化为二进制数值Aui;
Step2判断当前编码块是否为4×4块,如果满足则进行音频信息嵌入,进入Step3,否则进入Step6;
Step3利用率失真优化函数计算出4×4块的最优预测模式(Best_Mi),根据表2得到次优预测模式组Classi={N0,N1,N2,N3};
Step4依次读取音频信息Au[i],根据音频信息和预测模式之间的映射规则,嵌入音频信息。如果当前音频信息和最优预测模式Best_Mi匹配,则不对预测模式进行修改;否则,用预测模式组Classi中满足图3映射关系的次优预测模式Nj代换当前最优预测模式Best_Mi,并对替代后的预测模式进行重编码,同时将标志位flag的值传给解码端;
Step5将调制后的4个连续的帧内4×4块的率失真代价值总和J(CU4)与包含该4个帧内4×4块的8×8块的率失真代价值J(CU3)进行比较,如果J(CU4)<J(CU3),则嵌入该音频信息并保留,否则不嵌入,并进入Step6;
Step6读取下一个帧内4×4块亮度块,并重复以上操作,当读取音频信息至结尾处剩下单比特数据时,则根据结尾数据奇偶映射规则,嵌入音频信息,此时音频信息全部嵌入完毕。
3.5 音视频解码
在解码端进行音频数据提取只需对帧内预测模式进行解码即可,具体步骤如下:
Step1判断当前块是否为4×4块,如果是,则解码当前块,否则转到Step3;
Step2读取当前4×4块的预测模式,结合标志位flag值,对照表2,根据编码模式和嵌入信息的双映射关系,提取出嵌入二进制信息组AujAuj+1或者AujAuj+1Auj+2;
Step3读取下一个4×4块,重复上述步骤,当结尾剩下数据为单比特数据时,则根据结尾数据奇偶映射规则提取Aun,此时所有音频信息全部被提取,然后再通过G.729音频编码标准将所提取的音频信号进行解码重构。
4 实验结果与分析
本文基于HM12.0参考软件对所提出的音视频同步算法的性能进行了评估,实验选取了分辨率为ClassA到ClassB共7组高清视频序列(BasketballDrive,BQTerrace,Cactus,Kimono,ParkScene,PeopleOnStreet,Traffic)进行了实验测试。HM12.0的基本配置参数设置如表3所示,其余参数均为默认值。嵌入的音频信号采用8kHz/s,16bit单声道PCM格式信号,经过G.729标准压缩后的码率是16Kb/s。

表3 测试平台HM12.0主要参数配置
4.1 视频主观质量分析
本文算法通过修改帧内预测模式,用具有相近预测效果的预测模式代替最优预测模式,并且重新编码经调制后的次优预测模式,故本文算法不会对视频质量产生较明显的影响。图6为测试序列BQTerrace,Cactus和ParkScene在音频信息嵌入前后的第5帧图像,图6(a)为原始视频图像,图6(b)为未嵌入音频重构视频图像,图6(c)为嵌入音频重构视频图像。从主观上观察,嵌入音频信息前后的视频图像之间差别很小,说明同步后视频无明显失真。

图6 视频图像质量对比
4.2 视频客观质量分析
除了上述主观质量分析外,本文还从编码视频的峰值信噪比(Peak Signal to Noise Ratio,PSNR)、比特率变化(Bit Rate Interval,BRI)、嵌入开销(Oe)[11]、结构相似度(Structural Similarity,SSIM)[21]4个方面对同步算法进行评估。
嵌入音频后带来的开销Oe表示为:
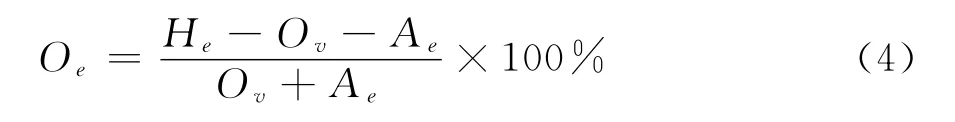
嵌入音频后的视频比特率变化为:

在式(4)中,Ov为视频单独压缩数据量;He为音视频同步编码数据量;Ae为G.729单独压缩数据据量;在式(5)中,R和R′分别为同步前后的视频比特率。
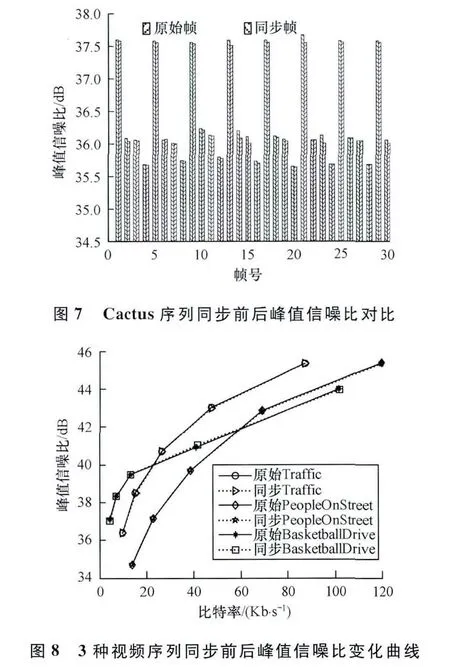
视频序列的测试结果如表4所示,分别给出了QP=28时7个视频序列Oe,PSNR和BRI的值在同步前后的变化情况。图7给出了Cactus序列同步前后30帧的PSNR对比结果。图8给出了视频序列Traffic,Kimono和PeopleOnStreet在QP分别为20,24,28,32,36时同步前后率失真变化曲线。

表4 本文算法实验测试结果
同步算法具体性能分析如下:
(1)从表4可以看出,对于所测试的序列,同步编码视频与单独编码视频的PSNR值相比差别很小,PSNR下降的最大值只有0.013 3 dB,不足0.05 dB。图7所示同步前后Cactus序列30帧的PSNR变化较小,没有大的波动,2条曲线基本重合,由此可见对视频质量影响较小,人眼不易察觉这种细微改变。而PSNR下降较多的视频序列分别为Cactus和Traffic序列,说明对于运动较为剧烈的视频序列,同步算法引起的PSNR下降较为明显,而对于运动相对平缓的序列如Kimono,其PSNR会表现平稳一些。
(2)图 8 分 别 是 Traffic,BasketballDrive 和PeopleOnStreet序列,在 QP分别为16,20,24,28,32时情况下同步前后的率失真变化曲线。从图中曲线可以看出,同步后比特率有所上升,但幅度不大,说明同步后比特率的增加表现较为平稳,处于可接受范围。从表4也可以看出,音频信息的嵌入并未对视频的比特率产生很大影响,增加率主要集中在1.091 3%~1.571 6%,码率变化控制在2%以内。分析可能的原因是对4×4块编码模式进行调制后,编码模式用次优预测模式代替最优预测模式,重编码后的非最优匹配导致比特率有一定的增加。
(3)考虑对嵌入开销的影响,从表2可以看出,同步算法的嵌入开销主要集中在0.9%~1.3%这个区间,最小只有0.913 1,对于这样小嵌入开销可以满足音视频同步的应用。同时可以发现本文同步算法的嵌入开销有部分序列为负值,也就是说部分序列同步编码后的数据量少于音视频各自单独编码的数据量,说明所提算法真正达到了音视频同步压缩的目的。
基于上文的分析,虽然同步后的视频质量变化细微,为进一步说明嵌入音频后未对视频的相对质量产生较大影响,本文引入SSIM评价指标。SSIM是基于人眼视觉模型的视频客观质量评价标准,其值在0~1之间,越接近1,原图像的失真越小。如图9所示,测试的同步重构视频的SSIM值都在0.96以上,说明视频感知质量并未因音频信息的嵌入而下降很大。
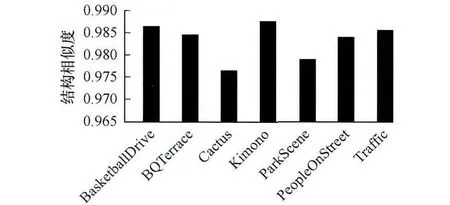
图9 SSIM感知视频质量测试结果
新一代高校视频编码标准HEVC相对于H.264/AVC标准在编码结构尤其是帧内编码结构、预测模式等方面进行了完全不同的设计和改进,应用对象也有所不同,且基于HEVC的嵌入式音视频同步算法目前还很缺乏,本文所提同步算法无法与基于H.264/AVC的音视频同步算法直接进行对比。故本文未给出相应的对比实验。
4.3 音频主观质量分析
对于音视频同步系统来说,人们对于音频质量的要求要高于视频,因为人耳对于声音的间断比较敏感,对视频的要求就没有音频那么严格。本文提出的音视频同步算法保证了所提取音频信息的完整性和正确性。图10(a)是原始音频时域波形图,图10(b)是同步编码重构的音频时域波形图,图10(c)是G.729单独编码的音频时域波形图。对比图10(b)和图10(c),可以发现同步算法较好地保护了音频质量,在传输和同步过程中重构音频的质量并未下降,其失真主要是因为音频的有损压缩造成的。
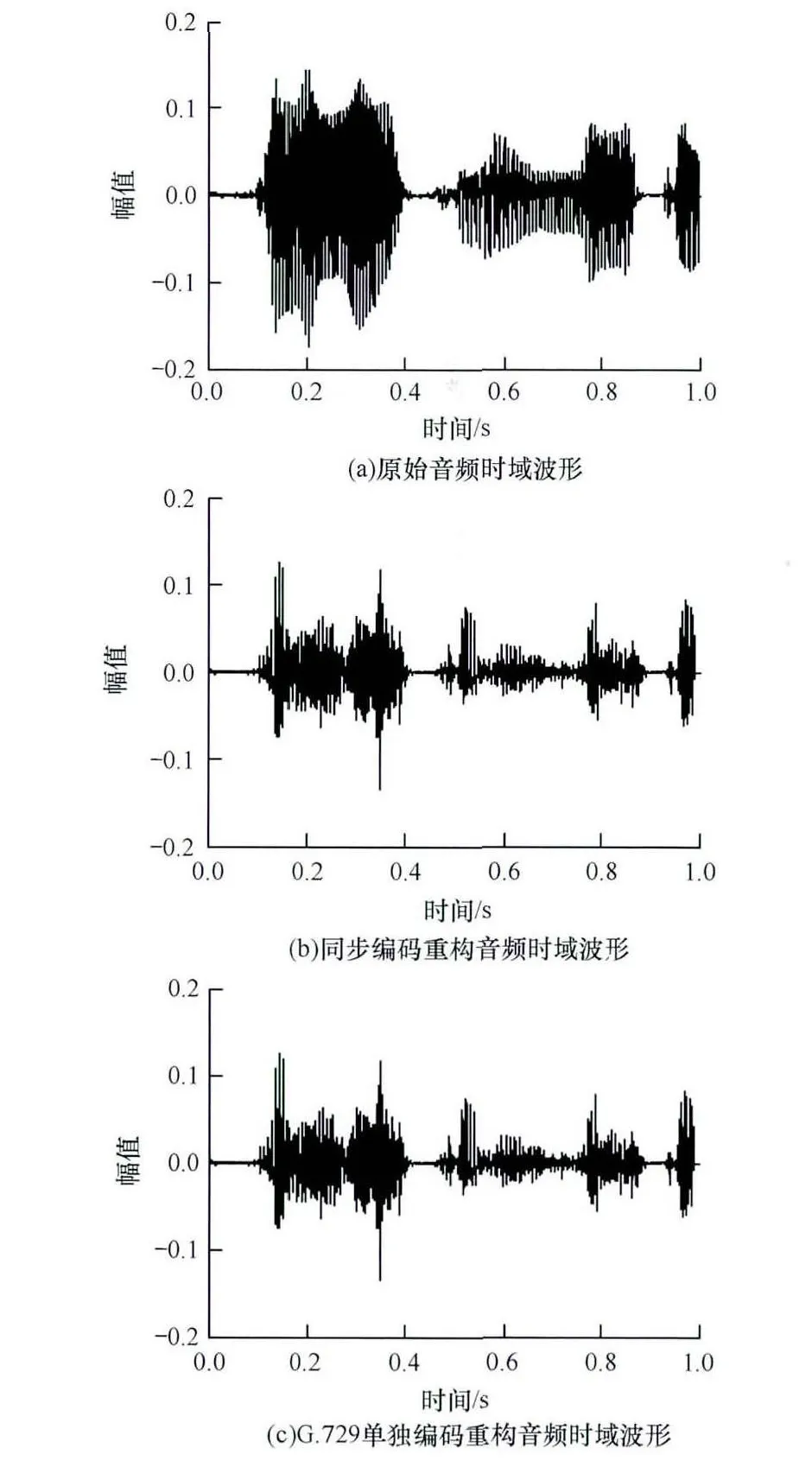
图10 时域波形图
5 结束语
针对高清视频序列,本文提出了一种在帧内编码过程中利用预测模式分组和可变长编码嵌入音频的HEVC音视频同步方法。将帧内预测模式进行分组,根据读取音频信息长度为2或3,分别对exp-Golomb编码算法的K值进行修改,通过音频信息长度标志位的变换,调制预测模式组和音频码组的映射关系,从而实现音频信息的嵌入,最后对混合音视频进行同步编码传输。实验结果表明,所提算法在实现较大音频信息量嵌入的同时,PSNR下降在0.05以内,嵌入开销和编码比特率增长不足2%,平均SSIM值下降0.02左右,保证了音视频的主客观质量,能够较好地应用到高清、超高清视频序列的信息隐藏、视频水印等相关领域中。但本文算法也存在不足,算法的计算复杂度较高,同时对于运动较为剧烈的视频,编码比特率增长过快。因此,下一步工作将对如何有效避免比特率的过快增长,并取得较低的计算复杂度进行研究。
[1]时美强,李 冰,熊 军,等.基于 H.264/AVC的音视频同步压缩方法[J].电视技术,2009,33(10):15-17.
[2]El-Helaly M,Amer A.Synchronization of Processed Audio-video Signals Using Time-stamps [C ]//Proceed-ings of International Conference on Image Processing.Washington D.C.,USA:IEEE Press,2007:193-196.
[3]Shepherd D,Salmony M.Extending OSI to Support Synchronization Required by Multimedia Applications[J].Computer Communication,1990,13(7):399-406.
[4]陈 勇,王林强,曹玉保.一种多线程的音视频同步控制方法及系统[J].中国集成电路,2012,(7):75-77.
[5]Chen T,Graf H P,Wang K.Lip Synchronization Using Speech-assisted Video Processing[J].IEEE Signal Process-ing Letters,1995,2(4):57-59.
[6]Cosatto E,Potamianos G,Graf H P.Audio-visual Unit Selection for the Synthesis of Photo-realistic Talkingheads[C]//Proceedings of IEEE International Conference on Multimedia and Expo.Washington D.C.,USA:IEEE Press,2000:619-622.
[7]Melek Z,Akarun L.Automated Lip Synchronized Speech Driven Facial Animation[C]//Proceedings of International Conference on Multimedia and Expo.Washington D.C.,USA:IEEE Press,2000:623-626.
[8]Qi Lifeng, Chen Hexin, Zhao Yan. New Synchronization Scheme Between Audio and Video[C]//Proceedings of the 8th International Conference on Software Engineer-ing,Artificial Intelligence,Networking,and Parallel/ Distributed Computing.Washington D.C.,USA:IEEE Press,2007:26-29.
[9]李晓妮.面向H.264的嵌入式音视频同步编码技术研究[D].长春:吉林大学,2012.
[10]李晓妮,陈贺新,陈绵书.基于H.264运动估计的音视频同步编码技术[J].吉林大学学报:工学版,2012,42(5):1321-1326.
[11]Qi Xiaoyin,Chen Mianshu,Chen Hexin.A CAVLC Embedded Method for Audio-video Synchronization Coding Based on H.264 [C]//Proceedings of International Conference on Multimedia Technology.Washington D.C.,USA:IEEE Press,2011:16-19.
[12]李晓妮,陈贺新,孙 元,等.基于 H.264的嵌入式音视频同步编码技术[J].吉林大学学报:工学版,2011,41(5):1475-1479.
[13]曾 碧,林健浩,肖 红,等.基于可变码长的音视频同步编码改进算法[J].计算机应用,2014,34(5):1467-1472.
[14]Sullivan G J,Ohm J,Han Woo-Jan,et al.Overview of the High Efficiency Video Coding(HEVC)Standard[J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1649-1668.
[15]王家骥,王让定,李 伟,等.一种基于帧内预测模式的HEVC视频信息隐藏算法[J].光电子·激光,2014,(8):1578-1585.
[16]Pourazad M T,Doutre C,Azimi M,et al.HEVC:The New Gold Standard for Video Compression:How Does HEVC Compare with H.264/AVC [J].IEEE Consumer Electronics Magazine,2012,1(3):36-46.
[17]Kim I K,Min J,Lee T,et al.Block Partitioning Structure in the HEVC Standard [J].IEEE Transactions on Circuits and Systems for Video Technology,2012,22(12):1697-1706.
[18]Meng Bojun,Au B.Fast Intra-prediction Mode Selection for 4ABlocks in H.264[C]//Proceedings of IEEE International Conference on Acoustics,Speech,and Signal Processing.Washington D.C.,USA:IEEE Press,2003:389-392.
[19]Yan Shunqing,Hong Liang,He Weifeng,et al.Groupbased Fast Mode Decision Algorithm for Intra Prediction in HEVC [C]//Proceedings of IEEE International Con-ference on Signal Image Technology and Internet Based Systems.Washington D.C.,USA:IEEE Press,2012:225-229.
[20]王家骥,王让定,李 伟,等.HEVC帧内预测模式和分组码的视频信息隐藏[J].光电子·激光,2015,(5):942-950.
[21]Wang Zhou,Bovik A C,Sheikh H R,et al.Image Quality Assessment:From Error Visibility to Structural Similarity[J].IEEE Transactions on Image Processing,2004,13(4):600-612.
