基于深度图像梯度特征的人体姿态估计
2015-01-01徐岳峰周书仁佘凯晟
徐岳峰,周书仁,王 刚,佘凯晟
(长沙理工大学计算机与通信工程学院,长沙410004)
1 概述
人体姿态估计是计算机视觉技术领域下的一个重点研究课题,该课题是估计图像以及视频序列中的人体各个部位的位置[1]。然而由于现实生活中人体姿态是多种多样的,以及测试环境的复杂程度,导致了在人体姿态估计中有遮挡和自遮挡、服装和噪声的干扰、姿态多样性等一系列问题,从而使得人体姿态估计在准确率和鲁棒性上无法得到显著地提高,因此人体姿态估计是一个具有挑战性的课题。
在研究方向方法,一部分学者是通过将人体分为多个部件组合成为模型,通过部件检测器检测部件的位置进行人体部件之间的概率计算,从而对图像中的人体进行姿态估计。1973年,Fischler和Elschlager提出了图模型结构[2],为后来的学者在人体姿态估计奠定了基础。Sapp提出了适用于人体姿态估计的级联图模型结构[3]以及后期提出的3D图结构模型[4]都是基于这一理论。随后又有多种人体姿态估计的人体模型提出,文献[5]结合图像形态学提出了一种新的铰接式人体姿态模,以及文献[6]提出基于关节点检测的铰接式人体模型(Articulated Part-based Model,APM)和文献[7]提出的人体部件集合的扩展式人体模型(Expanded Parts Model,EPM)。同时国内学者也在这个方向做出了自己的贡献,文献[8]提出基于先验分割的外观转换人体姿态估计模型,以及文献[9]利用方向梯度直方图(Histogram of Oriented Gradient,HOG)优化后的人体姿态模型。另外也有部分学者从无模型的角度出发对人体姿态估计这一问题进行了探索。这种方法是通过对每张图像的像素点进行分析,通过先进的特征提取方法来估计人体部件的位置。2005年,文献[10]提出了一种基于新式图像矩的无模型人体姿态估计方法。由于当时硬件条件不够发达,这一方法并没有得到广泛的应用。然而随着微软公司在2010年推出的Kinect,使得深度相机得到了广泛的使用。进一步使得基于深度图像的无模型人体姿态估计又成为了热点。文献[11]提出一种高效的方法将深度图像人体姿态估计回归到常见的人体姿态运动中,以及新的3D人体姿态估计方法都为后期学者们的探索奠定了基础。同时国内学习者也在深度信息在姿态估计方面进行了研究,文献[12]提出的基于部件位置及尺寸特征的人体姿态估计方法,以及文献[13]提出的深度图像的差分特征都在该方面有较好表现。本文以深度图像为基础,结合深度特征提取方法[14]和GoD特征提取方法,提出一种新的人体姿态估计方法。
2 深度图像
深度信息是指通过深度相机所得的数据,记录的是场景空间中物体所在平面与深度相机所在平面之间的距离。深度图像是指通过将深度相机所得的深度信息进行矫正和定标后所得的图像。也就是说深度图像中的像素点所记录的是图像中的点在场景空间中与相机之间的距离。将深度图像中的每个像素点的深度信息提取出来进行计算,就可以对图像进行特征提取。
3 特征提取
由于深度图像记录的是场景中的距离信息,因此与传统的RGB图像相比具有更好的不变性、抗干扰能力以及解决了轮廓模糊的问题。因为和传统的图像记录的信息不同,所以传统的图像特征提取方法并不一定能很好地适应深度图像。如何能有效地利用深度信息是近年来学者们所面临的问题。
3.1 传统的图像梯度特征
传统的RGB图像中图像梯度是用于描述灰度值的变化率。图像梯度值G(x,y)定义如下:
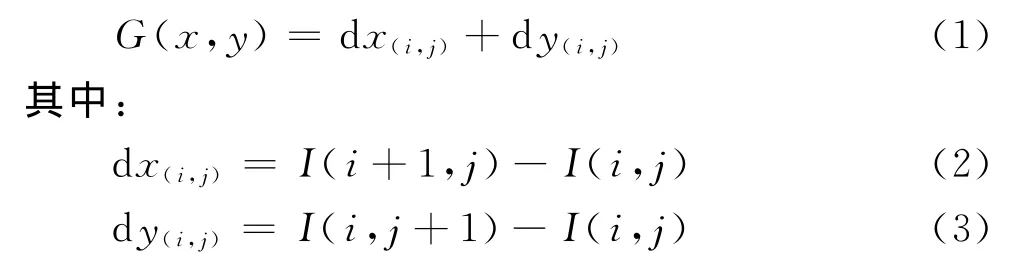
I(i,j)为图像在点(i,j)处的像素值。这个图像梯度特征在RGB图像中有着广泛的应用,后期的多种特征提取方法都与之相关如尺度不变特征变换(Scale Invariant Feature Transform,SIFT)方法。
3.2 深度图像的方向梯度特征
由于深度图像时记录场景空间中物体与深度相机之间的距离,通过简单的图像梯度计算和求梯度的反正切值可以得到像素点所在平面与深度相机所在平面的夹角关系,即深度图像的方向梯度特征(Directional Gradient of Depth,DGoD)定义如下:

其中,p(x,y)是深度图像中在位置为X列Y行处的深度值。方向梯度的取值范围是[0°,360°]范围内的一个值。当像素点落在同一平面内的时候具有相同的方向梯度。若不在同一平面则有不同的方向梯度。但是在计算方向梯度有以下2种特殊的情况:
(1)dx=0&dy=0;
(2)dx≠0&dy=0。
在上面2种情况下式(4)都等于0。但是2种情况所代表的平面是不相同的,如图1所示。

图1 方向梯度特征的特殊情况
图中平面b在水平和垂直方向都与深度相机所在平面平行(特殊情况(1)),即dx和dy同时等于0,则本文将方向梯度置为0。当dx不等于0而dy等于0的情况下如图1中平面a和c表示在垂直方向与相机所在平面平行,方向梯度的大小只与dx有关(特殊情况(2))。所以当dx大于0时,方向梯度为360°。当dx小于0时,方向梯度为180°。
3.3 DGoD特征的优化
在深度相机中,由于物体与相机之间的距离过近,可能会导致深度图像中的相邻像素点在空间场景中的实际位置相邻较近时,使得相邻像素点之间的深度值几乎相等。导致前面所说的特殊情况(1)和特殊情况(2)大幅增加。为了避免这种情况的发生本文提出优化后的DGoD特征描述子:
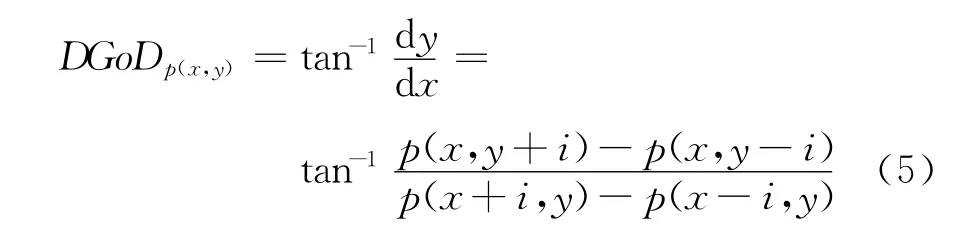
其中,i为步长,取值范围为(i,imax),imax是i的最大取值。当dx=0&dy=0或者dx≠0&dy=0的情况出现时,i进行自加1,使得步长变长,将新的i值代入式(5)重新计算DGoD特征值。当i=imax时,若dx=0&dy=0或者dx≠0&dy=0仍然出现。这时将依照式(4)中说所的方法对DGoD特征进行赋值。DGoD特征计算流程如图2所示。
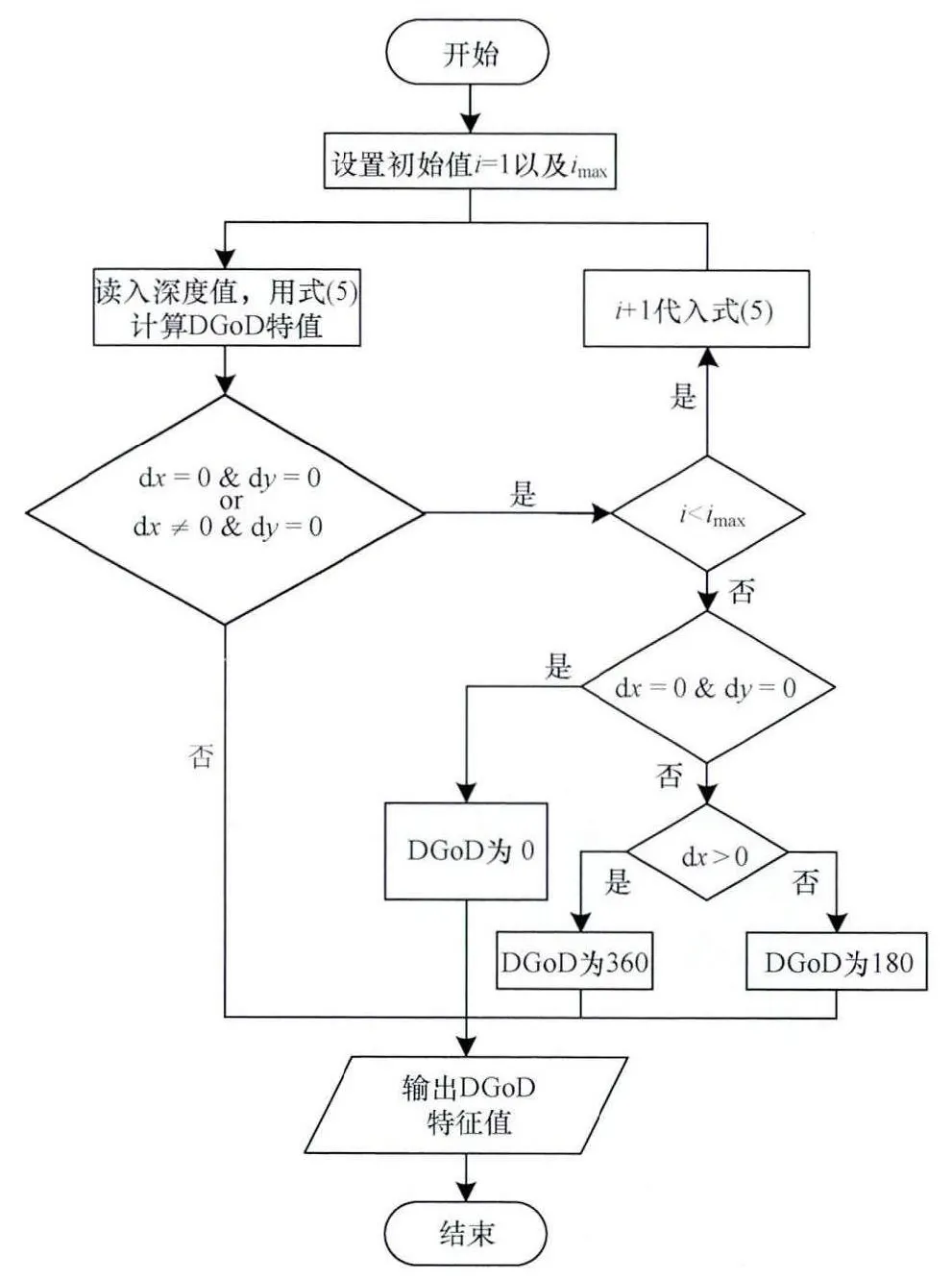
图2 DGoD特征提取流程
就上半身人体姿态估计而言,人体分为躯干(包括头部)、左右上下臂,以及左右手手掌7个部件,由于各部件之间通过关节点连接,而部件内部无关节点,因此同一部件内部的点处于同一空间平面中,但是不同部件内部的点可能位于不同平面(如图3(a)中的左下臂),也可能处于同一平面(如图3(b)中的左下臂)。由于DGoD特征在处理部件内部的点的分类具有较为明显的优势,然而无法处理部件与部件之间的点的分类。所以,需要梯度特征中的量级梯度来解决这一问题。
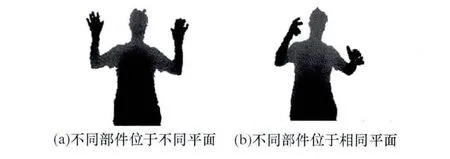
图3 人体部件示意图
3.4 传统的深度图像量级梯度特征
传统的深度图像量级梯度(Magnitude Gradient of Depth,MGoD)定义式为:
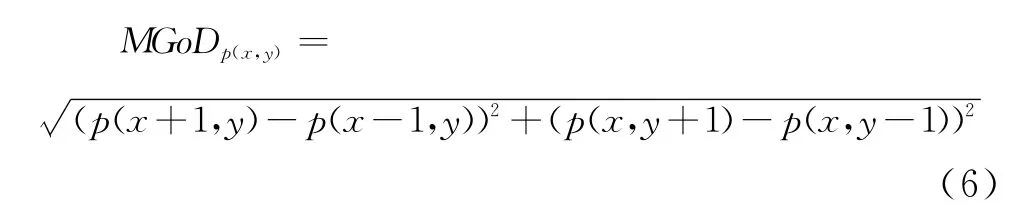
其中,p(x,y)代表深度图像中在位置为X列Y行处的深度值。MGoD的值为该点与领域点深度值的欧氏距离。
对于人体估计这一问题而言,很明显传统的MGoD不具有很好的表现。为了解决这一问题,本文将引入文献[11]方法对MGoD进行重新定义。
3.5 优化的深度图像量级梯度特征
本文将深度图像的量级梯度MGoD在一个已知像素点p处定义为:
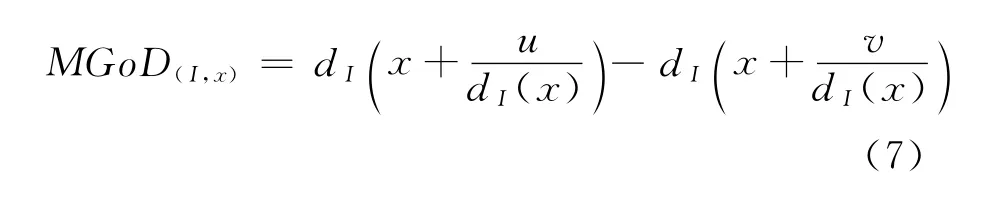
其中,MGoD(I,x)表示深度图像I中位置为x 的像素点的量级梯度特征值;d(·)为该点的深度信息;u和v分别为x点在水平和垂直方向的偏移量。
图4展示了MGoD特征提取的过程。其中,黑点为是位置为x的像素点;白点为偏移后的对比点。分别提取两点的深度值进行相减可得该点的三维MGoD特征值。如图4(a)所示,向上的偏移量方向在发现人体的顶部时具有较大反应,而向左和向右的偏移量在发现人体的竖直结构时拥有较大反应。由图4(a)可知,当x位于部件内部时,MGoD特征值给出的反应较小使得容易与背景混淆。所以,MGoD特征可以很好地弥补DGoD特征在处理不同部件位于同一平面的问题,同时,DGoD特征也弥补了MGoD特征的部件内部与背景混淆的问题。
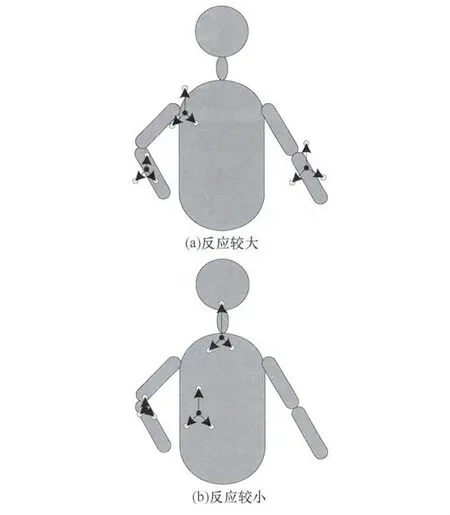
图4 MGoD特征提取示意图
4 随机森林的优化及姿态估计
随机森林[15]利用多棵相互独立的决策树对同一分类问题进行投票,分类结果是待分类对象属于所得票数最高的分类。随机森林中决策树的建立是通过利用“bagging”的方法建立n个数据子集,然后利用所建立的每个数据子集建立一棵决策树。对于每一棵决策树而言就存在参与建立随机森林的数据子集称为In-of-Bag数据。而没有参与决策树建立的数据子集称为Out-of-Bag数据。
在实验过程中,先设定决策树的数目N进行投票决策,但是决策树的数目过少则会减低准确率,而决策树的数目过多会使得运行效率减低。因此,本文在尽可能多建立决策树的情况下如何选取决策树和控制决策树的数量做出了一定的优化。优化方法步骤如下:
Step1建立N棵决策树。产生对于每棵树的In-of-Bag数据和 Out-of-Bag数据。
Step2对于每棵树进行一次测评。测评的标准为随机选取一定量的每棵树的Out-of-Bag数据,如果该决策树对该数据的分类结果为正确,则对该决策树投赞成票。
Step3将该决策树所得的总票数作为权重赋予该决策树,并将所有决策树按照权重由大到小进行排列。
Step4预测阶段使用前a棵决策树进行预测,预测结果为v1。
Step5使用a+b棵树进行预测,预测结果为v2。
Step6将v1,v2做差值计算,当时(c为人工设定的阈值),将v2作为预测结果。若,则重复Step5和Step6直到a+b=N。
在上述GoD特征以及随机森林的优化方法的基础上按照图5所示的流程进行人体姿态估计。

图5 人体姿态估计示意图
5 实验结果与分析
利用上述方法进行实验。目前没有公认的深度图像在人体姿态估计中的通用的数据集,所以,本文选取RGBD-GroundT-ruth样本库进行实验,样本库共有492幅分辨率为480×640像素的图像,按照人物分为3类,且每一类图像都包含由同一人物所做出的连续动作(主要包括头和躯干的扭动及手和手臂的转动)。本文分别在不同方法对比、鲁棒性对比、改进方法不同的imax对比、改进的MGoD与传统的MGoD对比,及8随机森林优化前后耗时对比方面进行了5组实验。
5.1 不同实验方法效果对比
图6中躯干部和手臂部分都出现了错误识别的情况。
右边的效果图出现了将手掌与背景的错误识别,3幅图像的躯干部都有大面积将躯干错误分为背景的情况。第3行为本文方法,由图6可知上述的躯干部的大面积错误识别得到了解决。同时并没有整个部件的错分。具体实验对比效果如图7所示。
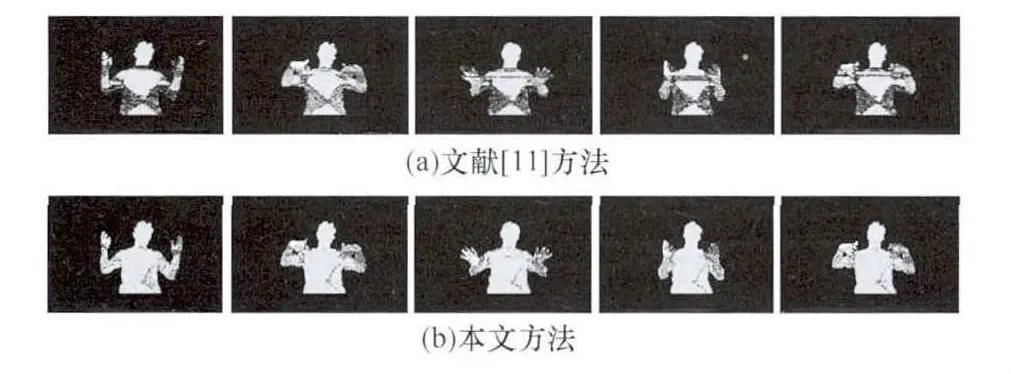
图7 深度特征提取实验效果
图7分析证明了GoD特征很好地解决了文献[11]中特征部件内部的点反应较小的问题。同时,各个部件并未出现整个部件的错误识别,解决了单一的梯度方向特征无法区分不同部件位于同一平面的问题。
5.2 不同方法鲁棒性对比实验
为了验证本文方法在姿态估计的识别率上的有效性,将本文方法与文献[11]的方法对于GBDGroundTruth样本库中的400幅图像的正确率进行对比,实验结果如图8所示。虽然在图中2条线走势相似,但是实线明显一直处于虚线上方,并且虚线跳变较大,最高可达95%最低不到91%,而实线基本维持在96%~97%之间。证明了本文方法不仅在识别率上明显提高,而且在鲁棒性上也有着较大提高。
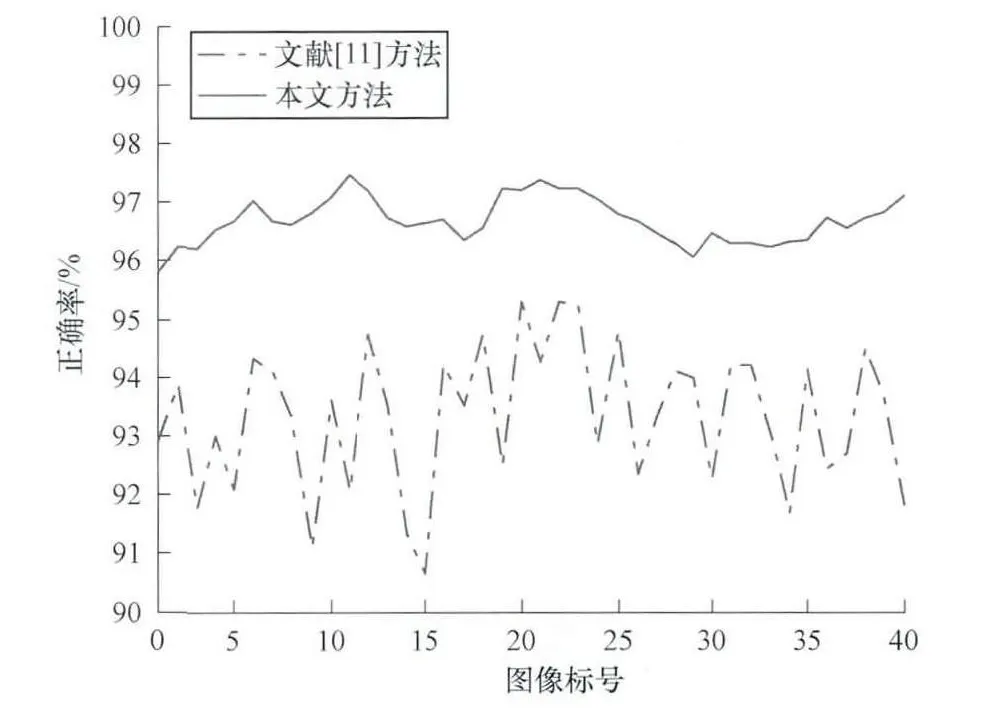
图8 正确率对比
5.3 改进DGoD方法对比
为了验证本文方法的有效性,选取样本库中的一部分图像进行实验,在imax值为1(即不加入优化方法),和imax的取值范围为1~20进行部分样本图像的平均正确率的比较,结果如图9所示。

图9 imax的取值对图像正确率的影响
由图9可见在imax为1时,平均正确率为最低。随着imax的增加平均正确率不断增加,在imax>6时,曲线趋于平稳。可知优化方法较为有效,在平均正确率上提高了将近1%。该效果明显的原因可能是RGBD-GroundTruth样本集中样本图像大多都是正面对着相机,使得空间平面中与相机处于同一平面的点的概率增加。
5.4 改进的MGoD与传统的MGoD对比
为了验证本文改进的MGoD对实验结果的影响,在同时都选用同样为优化后的DGoD后,进行了与传统MGoD的实验效果比较,如图10所示。由图10可以看出,传统MGoD虽然在部件内部未出现大面积的背景错分,但是在部件的区分上只有少部分的部件边缘区分正确。将大部分部件都分为了躯干部分。所以,传统的MGoD不能够满足人体姿态估计这一复杂的问题。

图10 传统MGoD实验效果
5.5 随机森林的优化前后耗时对比
为了验证本文中随机森林的优化效果,设计了随机森林的检测阶段优化前与优化后所用时间的比较,如表1所示。

表1 随机森林优化前与优化后运行时间对比 s
由表1可知,优化后的随机森林在测试阶段的时间开销有所降低,特别是在随机森林的决策树数量过多的情况下,时间开销降低得更为明显。并且由于有决策树的权重排列,使得在正确率方面没有明显降低,只在400幅图像的平均正确率上降低了0.1%左右。可见该优化方法是非常有效的。
6 结束语
本文在深度信息的特征提取方面提出了新的方法,并且对随机森林分类器进行了改进。实验结果表明,该方法的准确性较高,并且有着较好的鲁棒性。但是就姿态估计这一问题而言,任何方法都无法达到完美的效果。由于受到分类器的局限,运行效率并没有达到在实际生活中运用的标准,今后仍需在分类器的选择和优化上做进一步研究。
[1]Poppe R.Vision-based Human Motion Analysis:An Overview [J]. Computer Vision & Image Understanding,2007,108(1/2):4-18.
[2]Fischler M A,Elschlager R A.The Representation and Matching of Pictorial Structures [J].IEEE Transactions on Computers,1973,22(1):67-92.
[3]Sapp B,Toshev A,Taskar B.Cascaded Models for Articulated Pose Estimation[C]//Proceedings of ECCV’10.Berlin,Germany:Springer-Verlag,2010:1357-1365.
[4]Belagiannis V,Wang X,Schiele B,et al.Multiple Human Pose Estimation with Temporally Consistent 3DPictorial Structures[C]//Proceedings of European Conference on Computer Vision.Zurich,Switzerland:[s.n.],2014:742-754.
[5]Pishchulin L,Jain A,Andriluka M,et al.Articulated People Detection and Pose Estimation:Reshaping the Future[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2012:3178-3185.
[6]Sun M,Savarese S.Articulated Part-based Model for Joint Object Detection and Pose Estimation[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2011:723-730.
[7]Sharma G,Jurie F,Schmid C.Expanded Parts Model for Human Attribute and Action Recognition in Still Images[C]//Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Washington D.C.,USA:IEEE Press,2013:652-659.
[8]李少波,赵毅夫,赵群飞,等.机器人的人体姿态动作识别与模仿算法[J].计算机工程,2013,39(8):181-186.
[9]Ahri O,Chaumette F. Complex Objects Pose Estimation Based on Image Moment Invariants[C]//Proceedings of IEEE International Conference on Robotics and Auto-mation.Washington D.C.,USA:IEEE Press,2005:436-441.
[10]Girshick R,Shotton J,Kohli P,et al.Efficient Regression of General-activity Human Poses from Depth Images[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2011:415-422.
[11]Ye M,Wang X,Yang R,et al.Accurate 3dPose Estimation from a Single Depth Image[C]//Proceedings of IEEE International Conference on Computer Vision.Washington D.C.,USA:IEEE Press,2011:731-738.
[12]赵文闯,程 俊.深度图像中基于部位位置及尺寸的人体识别方法[J].集成技术,2012,1(3):10-14.
[13]殷海艳,刘 波.基于部位检测的人体姿态识别[J].计算机工程与设计,2013,(10):3540-3544.
[14]Shotton J,Sharp T,Kipman A,et al.Real-time Human Pose Recognition in Parts from Single Depth Images[J].Communications of the ACM,2013,56(1):116-124.
[15]Breiman L.Random Forests[J].Machine Learning,2001,45(1):5-32.
