Twitter加密网络行为自动识别方法
2015-01-01朱贺军祝烈煌
朱贺军,祝烈煌
(1.北京亿赛通网络安全技术有限公司,北京100085;2.北京理工大学计算机学院,北京100081)
1 概述
网络改变了人们的通信方式,使人们的生活发生了翻天覆地的变化,所有用户都在使用网络中的各种应用,每天都会产生数以亿计的数据流,而这些看似正常的流量中可能隐藏着各种恶意攻击行为。因此,分类识别网络流量与网络行为对规范网络应用、净化网络环境以及保护网络用户的隐私安全都具有重大意义[1]。目前,加密网络流量经常采用动态IP(Internet Protocol)、动态端口以及伪造端口等方式[2]使数据包载荷不断升级,而且数据量成几何级数增长。鉴于此,本文针对大规模加密数据提出一种高效的网络行为自动识别方法。以Twitter加密数据为研究对象,通过分析大量的Twitter加密网络行为,建立基于相关系数的数学模型,实现对海量Twitter加密网络行为的快速在线判别。
2 研究现状
传统流量识别方法包括基于深度报文检测的识别方法[3]和基于深度流检测的识别方法[4]。在加密流量识别上,传统识别方法面临以下问题:
(1)基于深度报文检测的识别方法依赖于对报文头部或载荷内容的匹配分析。加密流量的报文载荷为密文数据,不具备可供匹配的内容特征字段,传统的深度报文检测算法难以直接使用。尽管部分常用的加密协议具有固定的通信端口,可通过特定的端口信息识别,但随着随机端口和私有协议的广泛应用,这种检测方法的准确率严重下降。而且基于载荷信息识别对于加密应用模式匹配难度大,易受版本升级的影响[5-6]。
(2)基于深度流检测的识别方法依赖于单条数据流自身或从属于同一业务的多个数据流间的流量统计特性[7-8]。对于加密流量来说,仅针对单条数据进行深度流检测,往往难于突破。对于同一业务的多个数据流间的流量统计,文献[9]提出一种针对加密流量的识别法,该方法是一种基于数据包头部特征集和流量统计特征集的机器学习法,在识别过程中不依赖IP地址、端口和载荷信息,因此可以有效地识别加密的网络流量,文中以SSH(Secure Shell)和Skype加密流为测试对象,结果表明该方法识别加密流量准确率高,但计算开销大、实现复杂度高,无法满足在线实时识别的要求。
文献[10]提出一种主要用来区分端口号同为80的超文本传输协议(Hyper Text Transfer Protocol,HTTP)流量和非HTTP流量的分类法。该方法根据载荷前4个数据包的大小特征对流量进行初始判断,将可能性最小的数据流排除,然后根据特征码标记的统计结果对比之前建立的瀑布决策树,对剩下的数据包再次进行分类判断。该方法实时性好,既可用于在线识别系统,也可以与防火墙系统相结合进行流量的监控、过滤等相关工作,但是该方法的缺点是只针对80端口的流量进行了分类识别,无法识别其他端口的流量,而且决策树的建立规则也需要进一步的改进。
文献[11]提出传输层流量统计分析与主机行为相结合的网络电话(Voice over Internet Protocol,VoIP)流量识别法。将网络中检测出的主机IP地址与端口号作为主机行为,以此区分VoIP流量和传统流量。
综上所述,对于加密的网络流量,基于IP、端口、载荷以及机器学习等方法,均无法有效及时地识别加密网络行为。本文以Twitter加密数据为例,提出一种新的加密网络行为自动识别方法,对大量的Twitter数据进行实验分析,提取出能够表征该加密网络行为的特征,并构建该加密网络行为的模型库及参考样本,实现加密网络行为在线快速自动识别,解决了因加密协议频繁升级带来的开发工作量巨大和在线识别效率低下的问题。
3 基本原理
加密是把明文转换成不可辨识的密文的过程,使非授权人无法识别和篡改。为了达到在密文中隐藏明文和密钥信息的目的,在设计加密算法时,会尽力消除密文中所包含的所有特征信息,根据密文难以获取明文及密钥信息,能够抵御各种暴力破解和密码分析攻击。对于加密流量来说,虽然对明文和密钥进行严格地隐藏,但是经过多次对同一类网络协议的网络行为进行研究和分析,发现对于同一类网络协议的网络行为(如Twitter的聊天、Twitter的图片、Twitter的语音、Twitter的视频、Facebook的聊天、Facebook的图片、Facebook的语音、Facebook的视频等)有相似的统计特征或其他外在特征。本文依据加密网络数据流量的这些统计特征,通过构建具体行为样本库,将实时采集的网络数据向样本库投影,投影值是依据相关系数进行计算。相关系数值的大小反映了2个随机变量之间的相似程度。
本文经过对Twitter数据大量研究分析表明[12],明文和密文从外在形式上保持一致,密文包的大小反映明文内容的多少,不同的网络行为动作,其特征不同,对于某一具体网络协议的网络动作行为,例如发送消息,客户端和服务器之间的交互模式相对固定,在交互过程中,反映交互双方负载流量也保持了某种趋势,该趋势不会因为版本不同而发生变化。
如图1所示,有2次是真Twitter消息,1次是伪Twitter消息,若需辨别真伪,则可选择其中一次真Twitter消息数据作为参考样本,将其他2个消息与之相比对,通过计算相关系数并给出对应结果。相关系数反映了2个随机向量间的相关程度,计算公式[13]如下:
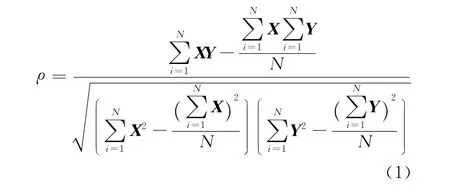
其中,X=[x1,x2,…,xN]表示样本数据;Y=[y1,y2,…,yN]表示新采集数据。相关系数ρ>0表示正相关,ρ<0表示负相关,ρ=0表示无关。ρ的绝对值越大表示相关程度越高。
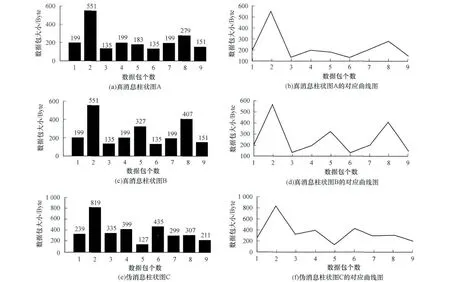
图1 消息交互过程中的流量记录
根据式(1)可知,2个真Twitter消息之间的相关系数为0.888 1,另外一个真Twitter消息和一个假Twitter消息之间的相关系数为0.605 8,由此可以说明2个真Twitter消息是强相关的,这样就可以通过相关系数实时计算并依据设定的阈值来在线判断Twitter加密协议的网络行为。因此,本文以Twitter的登录、聊天、音频、图片以及视频等消息为样板,通过大量的数据分析,建立相应的模型库及参考样本,且设定阈值为0.8,若大于设定阈值,判断为真,否则为假。
4 加密网络行为自动识别模型
综上所述,结合数据包大小及特点[14],同时对Twitter,Facebook等加密网络行为进行分析,将基于相关系数的加密网络行为识别分成2类情形进行分析,即音频/消息类和视频/图片类,如图2所示,设计加密网络行为自动识别方法的总体流程,主要包括实时数据采集、根据域名“twitter.com”等进行分类筛选、与模型库及参考样本实时进行相关系数计算、在线分类判别以及判定加密网络行为输出等。通过观测与分析大量数据,构建参考样本X=[x1,x2,…,xN]。采用滑动窗口方式采集与参考样本相同长度的测量数据集Y=[y1,y2,…,yN],采用滑动窗口的数据采集方式如图3所示,247为历史数据,199为新采集数据。
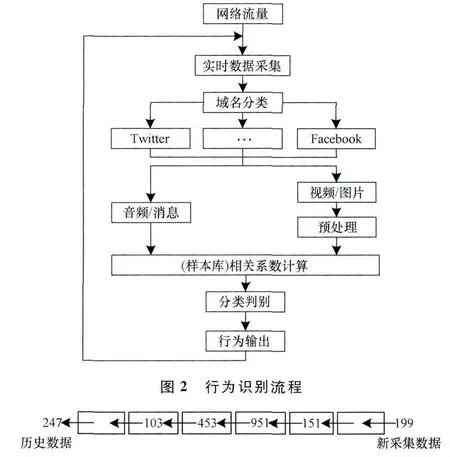
图3 数据采集方式
根据式(1)计算X和Y的相关系数,并结合ρ的大小和正负进行在线行为判别。对于音频类,与发送消息一样,直接计算参考样本与测试数据的正相关系数。对于视频/图片类,如果参考样本和采集数据集中有一个常量数组,且参考样本和测量数据不完全一样,如式(2)所示。如果参考样本和测量数据一样,则可以直接判断为加密流量。
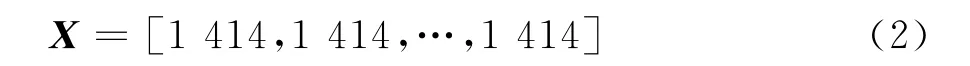
因为参考样本和采集数据集其中一个为常量数组,并且参考样本和测量数据不完全一样,所以不能依据相关系数进行直接判断。为此,需要对数据进行预处理,预处理方式针对特定位置并使其值微小波动,例如,改变上述变量的第2个和最后一个数值,得到如下形式:
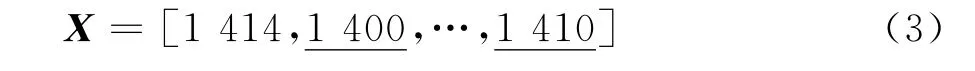
经数据实验证明,上述微小波动不影响判别结果。当参考样本和采集数据值完全一样,直接给出判断。采用上述处理方式和处理流程对预处理后的数据进行识别。
5 Twitter加密网络行为自动识别实验
分析对象:Android版本的Twitter加密网络行为。Twitter加密网络行为包括文字消息和上传图片,发送文字消息时,从安全套接层(Secure Sockets Layer,SSL)的交互过程中可以获取的域名为:“api.twitter.com”,在上传图片时的域名为 “upload.twitter.com”。
5.1 模型库构建
经过大量研究分析,Twitter加密网络行为可归纳为2种情况,即发送音频/消息类和视频/图片类。因此,需要建立2个参考样本。参考样本1为音频/消息类的参考样本,图4表示为参考样本1的数据包大小分布,即:X=[199,407,135,183,167,199,519,135,199,327,135,199,407,151]。
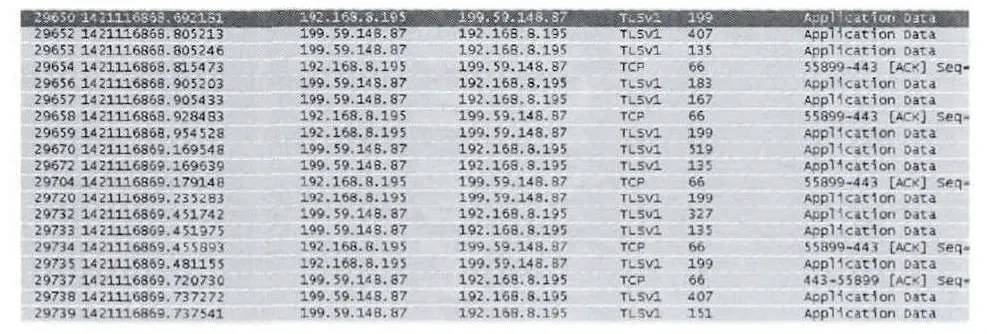
图4 参考样本1的数据包分布
包的大小分布X中带有下划线的数字表示对于同一个抓包环境,Twitter网络行为不同时其值不同。考虑到样本需要具有普适性,选取最后9个变量作为其中一个参考样本,其数据包大小分布为:X1=[199,519,135,199,327,135,199,407,151]。
参考样本2为视频/图片类参考样本,如图5所示,其数据包大小分布为:X2=[231,103,551,935,119]。

图5 参考样本2的数据包分布
5.2 实时数据采集
Twitter发送消息时新采集的数据,如图6所示,采用滑动窗口方式不断地获取与参考样本相同长度的测量数据,即:Y=[199,551,135,199,183,135,199,279,151]。
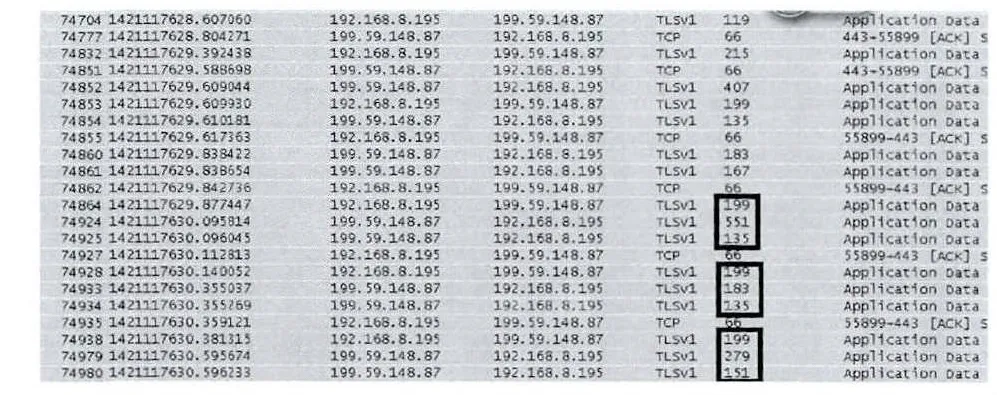
图6 Twitter发送消息时新采集的数据
5.3 相关系数计算
根据式(1)可计算出参考样本X1与测试数据Y的相关系数为0.888 1,参考样本X2与测试数据Y的相关系数分别为:-0.440 9,-0.115 9,-0.594 5,-0.365 7。其绝对值越大表示相关程度越高,值为正表示正相关,值为负表示负相关。因为5.1节实时采集的新数据与参考样本X1的相关系数大于0.8,所以该行为属于Twitter发送消息类加密数据。
5.4 算法实现
图7表示Twitter行为识别算法的实现。目前,依据相关系数值的大小决定分类,相关系数值大小根据经验值测定,本文相关系数参考值取0.8,大于0.8判为相关的加密网络行为,如:登录、聊天、音频、图片以及视频等。由5.3节相关系数的计算可知,X1与Y相关性较强,而X2与Y相关程度较弱。同理,当样本库中有图片或视频的参考样本,根据相关系数值的大小决定该动作属于哪一类行为。
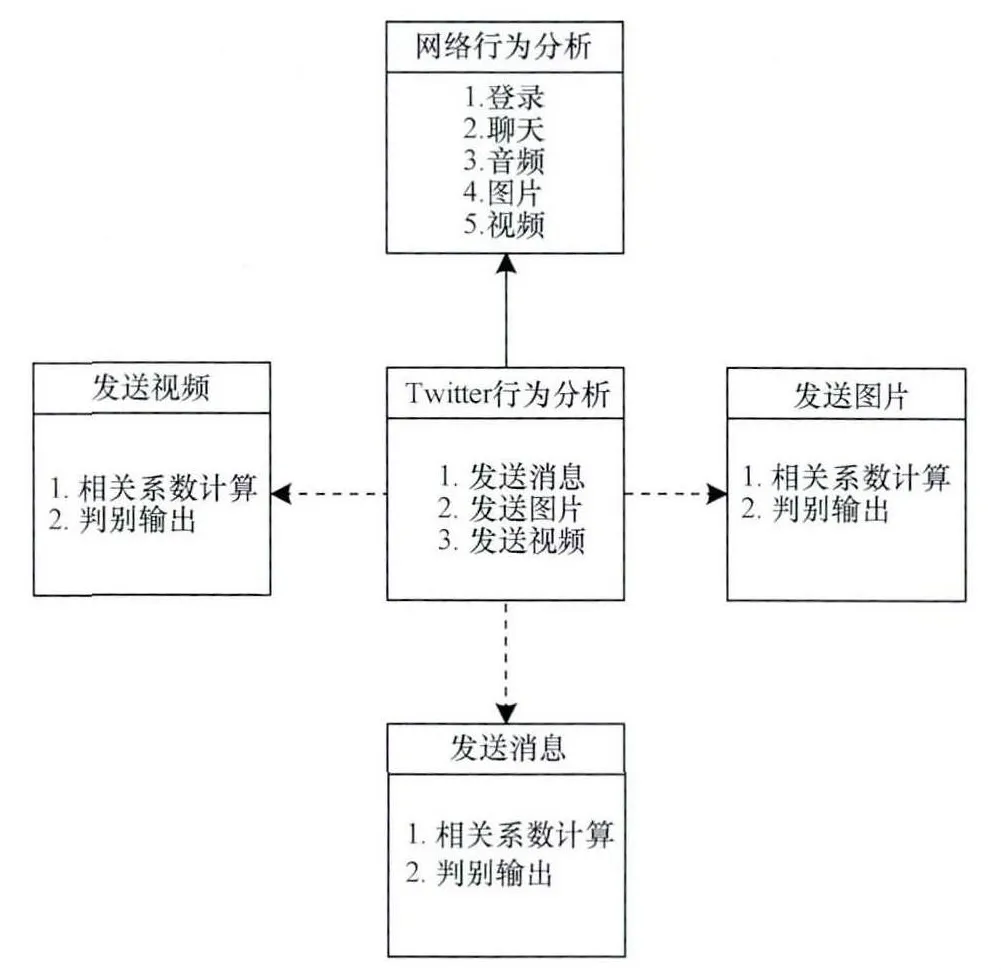
图7 Twitter行为识别算法的实现流程
5.5 性能分析
本文以Twitter加密数据为研究对象,实时采集网上的877MB数据进行模拟发包测试,经过域名“twitter.com”过滤后数据包大小为686MB,相关系数阈值大小选取为0.8,参考样本的维数一般选取在3~40之间,维数小于3无法表示其数字特征,在实施方面,交互数据维数一般小于40,本文的参考样本维数推荐选取为9。使用5.1节中的X1(维数为9)作为参考样本进行测试,相关系数总计运算1 957 916次,输出相关记录1 958次,总耗时4.8 s,在线识别率为99.80%,漏检4次,漏检率为0.20%。使用较大维数(维数为40)作为参考样本进行测试,相关系数总计运算1 957 885次,输出相关记录1 957次,总耗时6 s,在线识别率为99.75%,漏检5次,漏检率为0.26%。实际测试结果表明,该方法具有较高的识别效率。
6 结束语
本文以Twitter为例,分析研究了大量Twitter的登录、聊天、音频、图片以及视频等加密网络行为,提取出能够表征Twitter加密网络行为的特征,并构建其加密网络行为的模型库及参考样本。该方法实现了加密网络行为在线快速自动识别,并且解决了因加密协议频繁升级带来的开发工作量大和在线识别效率低的问题。同时经过实验验证,结果表明该方法高效可靠,并已在实际项目中得到应用,其行为识别准确率在96%以上。此外,加密数据包中的版本信息通常隐含在登录数据包中,根据密文及流量大小来判断版本信息是今后研究的重点。
[1]李 尧,郝 文.加密网络流量类型识别研究[J].计算机应用,2009,29(6):1662-1664.
[2]万月亮,朱贺军,刘宏志.流特征的Skype流量识别[J].智能系统学报,2010,5(2):139-143.
[3]于 强,霍红卫.一组提高存储效率的深度包检测算法[J].软件学报,2011,22(1):149-163.
[4]徐 鹏,林 森.基于C4.5决策树的流量分类方法[J].软件学报,2009,20(10):2692-2704.
[5]Calladoa A,Kelnerb J,Sadokb D,et al.Better Network Traffic Identification Through the Independent Combina-tion of Techniques[J].Journal of Network and Com-puter Applications,2010,33(4):433-446.
[6]陈 伟,胡 磊,杨 龙.基于载荷特征的加密流量快速识别方法[J].计算机工程,2012,38(12):22-25.
[7]张 波.基于流特征的加密流量识别技术研究[D].哈尔滨:哈尔滨工业大学,2012.
[8]叶春明,李 志,郑科栋,等.一种基于用户行为状态特征的流量识别方法[J].计算机应用研究,2015,32(2):560-564.
[9]Alshammari R,Zincir-Heywood A N.Can Encrypted Traffic Be Identified Without Port Numbers,IP Address-es and Payload Inspection?[J].Computer Networks,2011,55(6):1326-1350.
[10]Dainotti A, Gargiulo F, Kuncheva L,et al.Identification of Traffic Flows Hiding Behind TCP Port 80[C]//Proceedings of ICC’10.Washington D.C.,USA:IEEE Press,2010:1-6.
[11]Li Bing,Jin Zhigang,Ma Maode.VoIP Traffic Identification Based on Host and Flow Behavior Analysis[C]//Proceedings of WiCOM’10.Washington D.C.,USA:IEEE Press,2010:1-4.
[12]谢希仁.计算机网络[M].6版.北京:电子工业出版社,2013.
[13]王玉孝,柳 金,姜炳麟,等.概率论、随机过程与数理统计[M].北京:北京邮电大学出版社,2010.
[14]李 寅,周井泉.一种基于平均数据包长度的可变权值调度算法[J].计算机技术与发展,2012,22(9):116-118.
