基于差分压缩的大规模日志压缩系统
2015-01-01唐球1姜磊1戴琼1
唐球1,2,3,姜磊1,2,戴琼1,2
(1. 信息内容安全技术国家工程实验室, 北京100093; 2. 中国科学院 信息工程研究所, 北京 100093; 3. 中国科学院大学,北京 100049)
1 引言
随着计算机技术与网络应用的快速发展,企业或机构内部部署了多套网络设备与信息系统。这些设备或系统不间断地将各自的运行状态记录为日志数据,如Web服务日志、防火墙日志、入侵检测系统日志等。日志数据是服务改进、系统审计、安全分析、数据挖掘等应用的重要数据源[1~4],因此需要长期存储信息系统的日志数据。随着大数据、移动互联网时代的到来,信息系统变得日益复杂,面向互联网提供服务的信息系统访问量急剧增长,随之而来的系统日志数据也呈现出爆炸式增长。尤其对于一些核心系统模块,需要记录其所发生的一切操作并将其传输回数据中心进行存储与分析,海量的日志数据对于日志系统的设计是一个巨大的挑战。因此,有效的压缩、传输并存储大规模日志数据是现代信息系统的迫切需求。
在数据规模较小且可定期删除历史日志数据的情况下,可以使用传统的压缩工具定期进行日志数据的压缩存储,如Linux日志管理工具logrotate,它使用gzip定期对日志数据进行压缩与轮询存储。但是,使用传统的通用压缩算法降低日志数据存储空间存在效率低的问题。一方面,传统压缩算法的通用性导致了其压缩率低,因为通用的压缩算法没有充分利用日志数据的自身特性;另一方面,通用压缩算法计算量大,难以线速处理大规模的日志数据。近年来,针对大规模日志数据的压缩存储,国内外开展了大量相关工作。文献[5]利用Web日志数据在结构与内容方面均存在大量相似性的特性,提出了一种日志数据变换机制,将当前日志中与前一条日志相同的数据块转换为相同数据块的长度值;不相同的数据块则保留;然后对变换后的日志数据再使用通用的压缩算法做进一步的压缩;该方法的不足是对于不同类型的日志数据块采用同样的压缩算法。文献[6~8]先后尝试字段合并、不同字段差异化压缩策略等技术对Apache的Web日志进行差分压缩,与本文提出的方法的思想有一定的相似之处,但是该文献中的方法缺少可配置的灵活性,而且是专门针对于Apache的Web日志,缺少对更广泛类型日志数据的通用性设计。Kimmo等提出了基于日志数据中的频繁重复数据模式块消冗的防火墙日志压缩算法[9]。文献[10]通过分析DNS日志数据的特性,针对 DNS日志数据所涉及的时间、IP地址、域名和类型4类数据分别进行不同的压缩方法。文献[11]提出了基于通用压缩算法压缩日志数据的预处理算法,通过预处理算法中的分区函数将日志数据划分至多个同质日志桶(homogeneous buckets),然后对不同的同质日志桶内的日志数据使用传统的压缩算法bzip2或gzip进行压缩。由于同质日志桶内容日志结构高度相似,因此比直接使用bzip2或gzip压缩压缩更高。文献[12]使用硬件FPGA实现 LZ4算法对外汇交易系统中的事务日志进行压缩,在保证LZ4的压缩率的情况下,获得了专用硬件带来的压缩速度优势。已有日志压缩工作降低了日志存储空间,但是存在以下几点不足:1)通用性较差,依赖于具体的某一类日志;2)不具可扩展性,不支持压缩策略的可配置;3)粗粒度压缩策略,针对不同数据类型采用相同的压缩策略;4)不支持流式差分,难以满足在线实时日志压缩需求。
本文针对以上不足,提出了一种支持大规模日志数据的流式差分压缩架构。该架构首先充分利用日志数据的先验知识,将一类日志数据中固定不变的数据块提取为模板,日志压缩时,删除模板中定义的数据块,只存储一个模板指针。在解压时,根据模板内容即可复原日志数据;然后,针对日志数据中不同类型的数据块定制其差分压缩策略。本文提出大规模日志压缩系统不依赖于特定的日志类型,对于不同类型的日志数据可以配置不同的细粒度差分压缩策略,该系统采用流式的差分压缩架构,从而使本文提出的日志压缩系统具有明显的压缩率与压缩速度优势。
2 日志数据分析
日志数据格式可以是系统设计者自定义,或使用被广泛使用的 syslog日志格式[13],后者由RFC3164规范定义。它规定一条日志消息由“优先级”、“头部”与“消息体”3部分构成,其中优先级是一个数字,它代表了生成日志的程序模块(facility)与严重性(severity);头部包含时间与主机名;消息体是具体的日志内容。由于syslog日志规范只是一个建议,规范宽泛,其消息体包含了大量的日志属性,但这些内容的组织格式并没有确定的定义,由系统设计者自行定义。所以,很多日志系统是将其作为一种支持的格式,更多的是对它进行扩展。如防火墙安全领域更多的是使用 NetIQ公司提出的WELF日志格式。从真实的应用系统中采集了21 GB的真实日志数据,这个数据集由真实系统中的防火墙(天融信、思科)日志、交换机(华为)日志,入侵检测系统(IDS)日志、VPN日志与病毒检测系统日志构成。通过对该数据集分析,发现目前的日志系统存在以下3个显著特征。
1) 日志格式规整相似。目前成熟产品的日志数据格式类似于syslog RFC3164规范的格式,或者更加规范的日志格式,如WELF。前者如思科防火墙的日志格式(如表 1所示);后者的一条日志消息通常是由多个“<字段名,字段值>”的键值对构成,不同日志系统仅在键值连接符与键值对之间的分割符上有细微的差别,如表1中的最后3条日志数据,天融信的防火墙日志的键值对分隔符为空格,键值连接符为等号,而绿盟的IDS日志的分隔符为分号,键值连接符为分号。
2) 日志数据存在冗余结构模式。从表 1中可知,同一类日志数据无论以哪种格式表示,在消息结构上都存在大量的相同模式,如思科防火墙的106017类型日志(表1中的第1、第2行)均含有“ASA*Deny IP due to Land Attack from*to*”的模式;天融信防火墙的访问控制日志(表1的第3、第4行)均含有 “id=*time=*fw=*pri=*…”模式。其中模式中的星号表示可变内容,非星号字符为恒定不变内容(即冗余的结构模式)。
3) 日志数据中的属性值类型是固定且具有很强的时间局部性相似性。即对于同一类日志数据,即使在数据组织格式上有差异,但所承载的核心信息是相同的。如不同供应商的防火墙设备生成的访问控制日志数据均包含某一次穿越防火墙连接的五元组、时间、MAC地址、生成日志的设备名、防火墙策略 ID号等信息;在一个具体的日志系统中这些属性值的类型是确定的,且在短时间内,这些属性值是局部相似的,如时间属性值只是秒数的差异、少数IP地址在五元组中频繁重复出现等。

表1 常见网络设备日志数据实例(隐私信息已做替换)
3 日志数据差分压缩
3.1 基于模板的日志去重
基于第2节关于21 GB日志数据的分析结论,本节提出一种基于模板的日志消冗机制,消除日志数据中存在的冗余结构模式,形式化定义如下。
定义1(字段,field)。字段是由字段名(fld)与字段值(val)构成的键值对(fldλval),其中“λ”为字段名与字段值之间的连接符。一个字段表示一个具体的日志属性,如表 1中的天融信防火墙访问控制日志中的源IP地址字段为“src= x.x.x.x”,其中 src为字段名(源 IP),“x.x.x.x”为字段值(IP地址),字段名与字段值连接符为等号。
定义2(日志消息,log_msg)。一条日志消息表示一个事件,它是由有限个字段构成,字段之间有先后顺序、由字段分隔符(θ)相连接;即log_msg=field1θfield2θ…fieldN,其中,fieldi=fldiλvali。
定义 3(日志,log)。日志是由多条日志消息构成的集合,log={log_msgi | i∈1,2,3,…,M; log_msgi=field1iθfield2iθ …fieldNi;fieldji=fldjiλvalji,j∈1,2,…,N}。
由前一节的分析可知,已有的日志格式与本文形式化定义的日志格式很相似,因此只需对待压缩的日志数据进行简单预处理,将日志数据转换为规整的日志格式(log)。日志数据所有的字符都是可打印字符,不含控制类字符,因此可以选择控制类字符作为λ与θ。对于同一类日志数据,可以通过正则表达式匹配加文本处理脚本完成日志预处理。
同一设备或系统的日志存在冗余的结构模式:日志消息的字段组成结构是固定的,且各个字段名是相同的,即log_msg1与log_msg2都包含相同的内容 :fld1λ,θfld2λ … θfldN; 不 同 的 部 分 是 :val1,val2,…,valN。基于此特征,本文提出的日志压缩系统将日志中冗余的结构模式以字段为单位提取为模板,然后将模板定义的冗余模式从日志消息中删除,并在日志消息中存储模板指针。具体的模板形式化描述如下。
定义 4(模板,template)。一个模板由字段名与字段值连接符、字段分割符、各个字段名以及该模板的 ID 号(tid)构成,即template={tid,λ,θ,fld1,fld2,…,fldN}。
因此,基于模板的日志去重机制主要步骤如下。
Step1日志预处理。
Step2对每一条日志消息log_msgi进行如下操作。
1) 模板库中查找与log_msgi相匹配的模板(templatek);
2) 将templatek定义的字段名从log_msgi中删除,并将templatek的模板ID写入日志消息中,最后得到基于模板变换后log_msgi为“tidkθval1iθval2iθ…θvalN i”。
对于压缩后的日志数据,根据模板指针,通过执行基于模板的逆去重操作即可恢复原始的日志数据。
3.2 日志数据细粒度差分压缩
基于模板的日志数据重后降低了日志的存储空间,但仍存在大量的信息冗余,尤其是短时间内的同类日志消息字段之间存在局部相似性。为了进一步压缩日志数据空间,本文设计的日志差分架构对基于模板去重后的日志数据做进一步的细粒度的差分压缩。首先定义几类通用的差分压缩策略(diff_strgy);然后,根据不同的字段值特性,选择各个字段值最适合的差分策略对基于模板去重后的日志数据进行字段级别的差分压缩。为了支持日志消息的线速压缩,日志差分压缩只选择与前一条同类型的历史日志消息进行差分计算;由于日志消息具有时间域的局部相似性,所以该差分压缩策略保证了日志压缩的时间与空间效率。
3.2.1 字段细粒度差分压缩
每个字段的细粒度差分压缩(FFDE, finegrained field differential encoding)可以描述为一个五元组:ffde=(fld,fld_type,diff_strgy,initVal,size),五元组中各个属性的定义如下。
fld:字段名。
fld_type:字段值类型,分为字符串、整数2大类,其中整数分为8位,16位,32位,64位的有符号与无符号整数;浮点数转化为指数与尾数的 2个整数表示。
diff_strgy:字段值差分策略,本日志压缩系统定义了4类差分策略,具体定义见表2,对于不同特性的字段采用不同差分策略,也可扩展新差分策略以支持新类型字段。

表2 字段差分策略定义
initVal:字段的初始值。当第一条消息差分压缩时,将initVal作为历史值(val')与当前字段值做差分运算。当字段差分策略为“定值”时,则initVal属性值定义为该字段的定值。
size:标识使用差分策略得到的字段差值使用定长编码(编码为size个字节)还是变长编码(size=0)。定长编码即保持原始值;变长编码采用被广泛使用的 LEB128[14]变长编码技术,即一个字节的7 bit表示实际数据,最高比特位标识当前字节是否为变长数据的最后一个字节(如0表示结束)。对于差分压缩后的字段值的取值范围固定(如 IP地址的一个段的值范围为0~255),且等于1字节或大于4个字节的定长值采用定长编码,反之采用变长编码。这样可以使存储空间达到最优。如一个无符号的 32为整数值采用变长编码时,当其值的区间为[0, 127]内的任意一个值时,只需要一个字节存储表示,而不是4个字节。
3.2.2 字段差分存在位图
差分策略导致字段的值具有3种“值存在”状态:存在、不存在、条件存在。“存在”表示字段差分之后总是有值,如“差值”字段差分策略;“不存在”表示字段差分后总是没有值,如“定值”差分策略;“条件存在”表示字段差分后依据条件可能有值也可能无值。如字段差分策略为“复制”,当与前一条日志消息的值相同时,当前日志直接删除该值,差分后的字段无值;反之则保留该值,差分后的字段有值。因此一条差分后的日志消息所包含的字段值数目不固定。为了正确解码日志消息,一条差分压缩的日志消息需要存储一个字段值存在位图向量(FVPB, field value presence bitmap),FVPB中的每一个比特对应日志中的一个具有“条件存在”状态的字段,置位表示字段值存在;复位表示字段值不存在。对于“存在”与“不存在”的字段值则不需要FVPB标示。
3.3 基于模板的日志数据细粒度差分压缩
结合3.2节与3.3节,本节给出基于模板的日志数据细粒度差分压缩总体架构。日志先通过模板去重,然后再对日志字段值进行细粒度的差分压缩。这两者均定义在日志差分压缩模板中,定义如下。
定义5(细粒度差分模板,template′)。一个细粒度差分模板由字段值存在位图向量、各个字段的细粒度差分五元组、模板 ID号、字段名与字段值连接符与字段分割符构成,即template'={ffdetid,λ,θ,ffde1,ffed2,…,ffedN}。其中模板ID号也作为日志消息添加的一个普通字段(ffdetid),使用“复制”差分策略(可减少连续同类型日志消除中模板 ID的存储)。基于细粒度差分模板的日志差分压缩算法描述为算法1。
字段差分压缩是当前值(val)与同类型的前一条日志数据的对应字段值(val')执行差分压缩,因此整个日志的差分压缩过程需要维护一个差分字典,用于记录前一条同类型日志数据的字段值。算法 1第 1行为每个模板定义一个差分字典(dict[k][0…N]),其初始值为对应模板的字段初始值(initVal);每执行完一条日志消息的差分运算,用当前日志的字段值更新该差分字典(算法1第6行)。对于每一条日志消息,首先需要确定适合其的模板,然后根据模板对该日志消息进行细粒度差分压缩(算法1中的第3~7行)。
算法1基于细粒度差分模板的日志压缩算法
输入:日志log={log_msgi |i=1,2,…,M}; 差分压缩模板集合temp_set={template'k|k=1,2,…,K};其中template'k={ffdetidk,λ,θ,ffde1k,…,ffedNk},ffedjk=(fldjk,fld_typejk,diff_strgyjk,initValjk,sizejk),j=1,2,…,N};
输出:差分压缩的日志数据;
1) 初始化模板字段差分字典dict[k][0…N]={k,initVal1k,…,initValN k};
2) 对于每个日志消息log_msgi,执行如下操作;
3) 根据日志消息的结构查找与其相对应的模板template'k;
4) 对模板ID号(k)与log_msgi的每个字段值valji执行如下操作;
5) 依据diff_strgyjk的对valji与dict[k][j]进行差分运算;如果当字段差分编码状态为“条件存在”且差分后有值,则FVPB[j']=1;否则FVPB[j']=0;/*j'为当前字段在字段值存储位图中的比特位*/;
6) 更新字段前值字典dict[k][j]=valj;
7) 输出FVPB与各个字段差分后的值。
4 实验结果与分析
本节通过测试真实的网络系统日志数据,分析本文提出的支持大规模日志压缩系统的效率。主要考察其压缩率与压缩速度。
实验环境:处理器为Intel Core I3-3240,内存2 GB,Fedora-14的操作系统。
由于提出的差分架构是流式工作方式,即只与前一条日志消息做差分计算,因此压缩总时延与日志的规模成正比关系,小规模数据集测试即可说明该架构的压缩速度。为了快速得到测试数据集的压缩率与压缩速度,本节从真实的天融信防火墙访问控制日志数据集中提出部分字段,组成4个数据集,数据集的特性描述如表3所示。

表3 数据集特性
对这4个数据集分别使用本文提出的基于模板的细粒度差分压缩架构与通用的压缩工具gzip进行压缩测试,选择gzip进行参照是因为广泛使用的开源日志管理工具logrotate使用的就是gzip作为其日志压缩算法;而且类似的日志压缩文献[6~9]的实验对比也是与gzip相比较。2个压缩工具对于各个数据集的压缩时间与压缩率分别如图1和图2所示,由于gzip可以设置其压缩参数典型的可以设置为快速压缩模式(速度快、低压缩率)、高压缩率模式(速度慢、高压缩率)与普通压缩压缩模式(压缩速度与压缩率介于前2种模式之间),所以在实际测试中对于同一数据集,分别使用3种不同的gzip模式进行压缩测试。从图 1可知,本文提出的基于模板差分的日志压缩系统在压缩速度上比普通或快速模式的gzip快2~5倍,比高压缩率模式的gzip快一个数量级(图1中的时间纵轴为对数刻度)。

图1 压缩时间对比
从图2可知,本文提出的基于模板的日志差分压缩架构的压缩率均低于 3种模式下 gzip 的压缩率,且压缩到达为10.5%。
图 3描述了本文所提方法与 gzip对于fw_log(150w)数据集在压缩速度与压缩率2方面的整体对比。其中柱状图表示压缩率,黑色三角形图块表示压缩时间。图3表明本文提出的日志差分压缩架构与gzip相比,具有明显的速度优势(快2~10倍),同时压缩率也优于 gzip。这是合理的,因为基于模板的差分压缩充分利用了日志数据自身的特性,在压缩前就获得了日志数据的先验知识(模板),而通用的gzip工具没有这些先验知识。
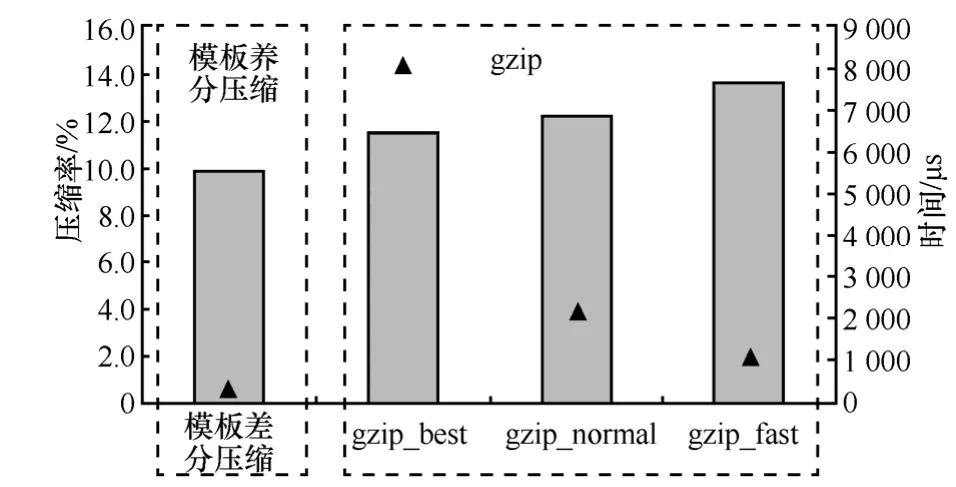
图3 基于模板的差分压缩与gzip在压缩率(柱状图)与压缩速度(三角形)上的对比
5 结束语
基于模板流式差分的日志压缩系统首先消除日志数据中冗余的结构模式。其次,利用日志数据在时间域上的局部相似性,通过配置适用于日志内容属性(字段)的差分策略执行差分压缩,进一步降低了日志数据的存储空间。由于采用流式差分压缩,使本文所提的日志压缩架构具有显著的压缩速度优势。差分策略的可配置性使该架构具有通用性与可扩展性,该方法可以应用于一般的日志压缩。
[1] YEN T F,et al. Beehive: large-scale log analysis for detecting suspicious activity in enterprise networks[A]. Proceedings of the 29th Annual Computer Security Applications Conference[C].2013.199-208.
[2] BREIER J, BRANIŠOVÁ J. Anomaly detection from log files using data mining techniques[A]. Information Science and Applications[C].2015.449-457.
[3] DUMAIS S,et al. Understanding user behavior through log data and analysis[A]. Ways of Knowing in HCI[C]. 2014. 349-372.
[4] SRIVASTAVA M, GARG , MISHRA P K. Analysis of data extraction and data cleaning in Web usage mining[A]. Proceedings of the 2015 International Conference on Advanced Research in Computer Science Engineering Technology (ICARCSET 2015)[C]. 2015. 1-6.
[5] SKIBIŃSKI P, SWACHA J. Fast and efficient log file compression[A].Proceedings of CEUR Workshop of 11th East-European Conference on Advances in Databases and Information Systems(ADBIS 2007)[C]. 2007.
[6] GRABOWSKI S, DEOROWICZ S. Web log compression[J]. Automatyka/Akademia Górniczo-Hutniczaim Stanisława Staszicaw Krakowie, 2007, (11): 417-424.
[7] DEOROWICZ S, GRABOWSKI S. Efficient preprocessing for Web log compression[J]. International Journal of Computing, 2008, 7(1): 35-42.
[8] DEOROWICZ S, GRABOWSKI S. Sub-atomic field processing for improved Web log compression[A]. Proceedings of IEEE International Conference on Modern Problems of Radio Engineering, Telecommunications and Computer Science[C]. 2008.551-556.
[9] HÄTÖNEN K.et al. Comprehensive log compression with frequent patterns[A]. Data Warehousing and Knowledge Discovery[C]. 2003.360-370.
[10] 王艳峰, 王正,阎保平. 一种高效的 DNS 日志压缩算法[J]. 计算机工程, 2010, 36(15): 32-35.WANG Y F, WANG Z, YAN B P. High efficient DNS log compression algorithm[J]. Copular Engineering, 2010, 36(15): 32-35.
[11] CHRISTENSEN R. Improving compression of massive log data[EB/OL].http://www.erg.utal.edu, 2013.
[12] JANG J H,et al. Accelerating forex trading system through transaction log compression[A]. SoC Design Conference (ISOCC), 2014 International[C]. IEEE, 2014. 24-75.
[13] LONVICK C. RFC 3164: The BSD Syslog Protocol[S]. Network Working Group.
[14] LEB128 [EB/OL]. http://en.wikipedia.org/wiki/LEB128, 2015.
