基于贝叶斯的软件错误定位方法
2014-12-23姜元鹏姜淑娟
姜元鹏,李 威,于 巧,姜淑娟
(1.中国矿业大学 图书馆,江苏 徐州221116;2.中国矿业大学 计算机科学与技术学院,江苏 徐州221116)
0 引 言
软件自动化错误定位是一种结合程序行为与运行结果对产生错误的语句进行定位的程序分析技术。随着软件规模的扩大和软件复杂度的提高,软件错误定位的实现也越来越困难。
基于程序执行错误定位方法的关键是获取程序的执行轨迹信息,在获取程序执行信息基础上,利用概率统计、关联分析等模型建立自动化分析工具,可以在一定程度上提高软件错误定位效率。目前用于获取程序执行轨迹的方式主要有3种:①获取程序日志;②插装技术;③依赖程序运行平台接口。其中,第一种方式会受到程序日志信息粒度的影响,导致获取完整正确的执行路径比较困难;第二种方式需要修改程序源码或目标代码,对程序的侵入性较高,存在很多不稳定的因素;第三种方式实现比较灵活且对程序的侵入性较低,已逐步得到广泛的应用。
在程序自动化调试及软件错误定位方面,根据是否需要运行程序可以分为:基于静态分析的错误定位方法和基于测试的错误定位方法。其中,静态分析无法获取错误发生时的上下文信息,而基于测试等动态分析方法在收集动态信息时会产生较大的代价。总的来说,当前错误定位方法中存在2 个重大的缺陷,一个是错误定位不准确,漏掉错误语句或者包含的语句数量过多等;另一个是计算的难度过高,处理大型程序时的时间和空间消耗过大。
针对目前软件错误定位技术的研究现状及存在的问题,本文提出了一种将动态切片技术和覆盖统计相结合的错误定位方法。针对能够确定切片准则的程序计算其执行过程中的动态切片;然后根据贝叶斯公式计算后验概率;最后以第二步中计算得到的后验概率作为语句的可疑度值,按照该值降序排列。通过实验验证本文方法可在一定程度上提高了软件错误定位的效率与精度。
1 基本概念
1.1 程序切片相关概念
(1)控制流图
控制流图G 是程序中语句逻辑执行的一种图形化表示,可由四元组 (N,E,entry,exit)表示。其中,N 为节点的集合,代表程序中的语句;EN×N 为边的集合,代表程序中语句间的控制关系;entry为程序的入口节点;exit为程序的出口节点。
(2)控制依赖
n1,n2是控制流图G 中的2 个节点,如n1,n2 满足以下3个条件则称n2控制依赖于n1,记为CD (n2,n1):①存在一条从n2到n1的可执行路径Path;②节点n2是路径Path中除去n1,n2的其它节点的后必经节点;③n2不是n1的后必经节点。
(3)数据依赖
n1,n2是控制流图G 中的2 个节点,变量v在n2 中被定值,如果n1,n2,v满足以下2个条件,则称n1数据以来n2记做DD (n1,n2):①变量v被节点n1引用;②存在一条从n1到n2的非空路径,并且该路径上没有对变量v重定值的节点。
(4)程序切片
程序切片定义请参见文献 [1]。
1.2 贝叶斯定理
贝叶斯定理是指对于随机事件A 和B,在事件B 发生的情况下事件A 发生的概率

式中:P(A)——A 的先验概率或边缘概率;P(B|A)——已知A 发生后B的条件概率,也由于得自A 的取值而被称作B的先验概率;P(B)——B的先验概率或边缘概率,也作标准化常量 (normalized constant);P(A|B)——已知B发生后A 的条件概率,也被称作A 的后验概率。另外,贝叶斯也适用于多个事件的情况,假设Ai表示一个事件集合,那么则有
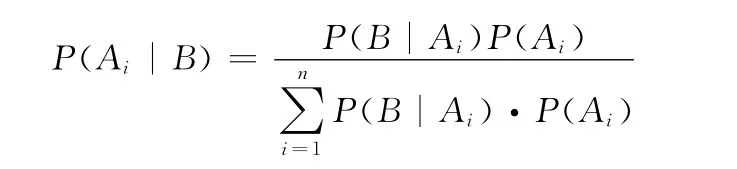
2 实例程序
通过一个实例程序来阐述我们的方法。表1左侧为求3个数中间值的函数mid,在该函数的第二行引入了一个错误:语句 “ret=z”误写成了 “ret=x”。然后我们设计了六组测试用例对其进行测试,覆盖情况如表1 中 “切片前”列数据所示,其中标记 [√]表示对应的左侧语句被该测试用例执行覆盖。表1的底部展示测试结果,其中T 代表成功执行,F代表失败执行。
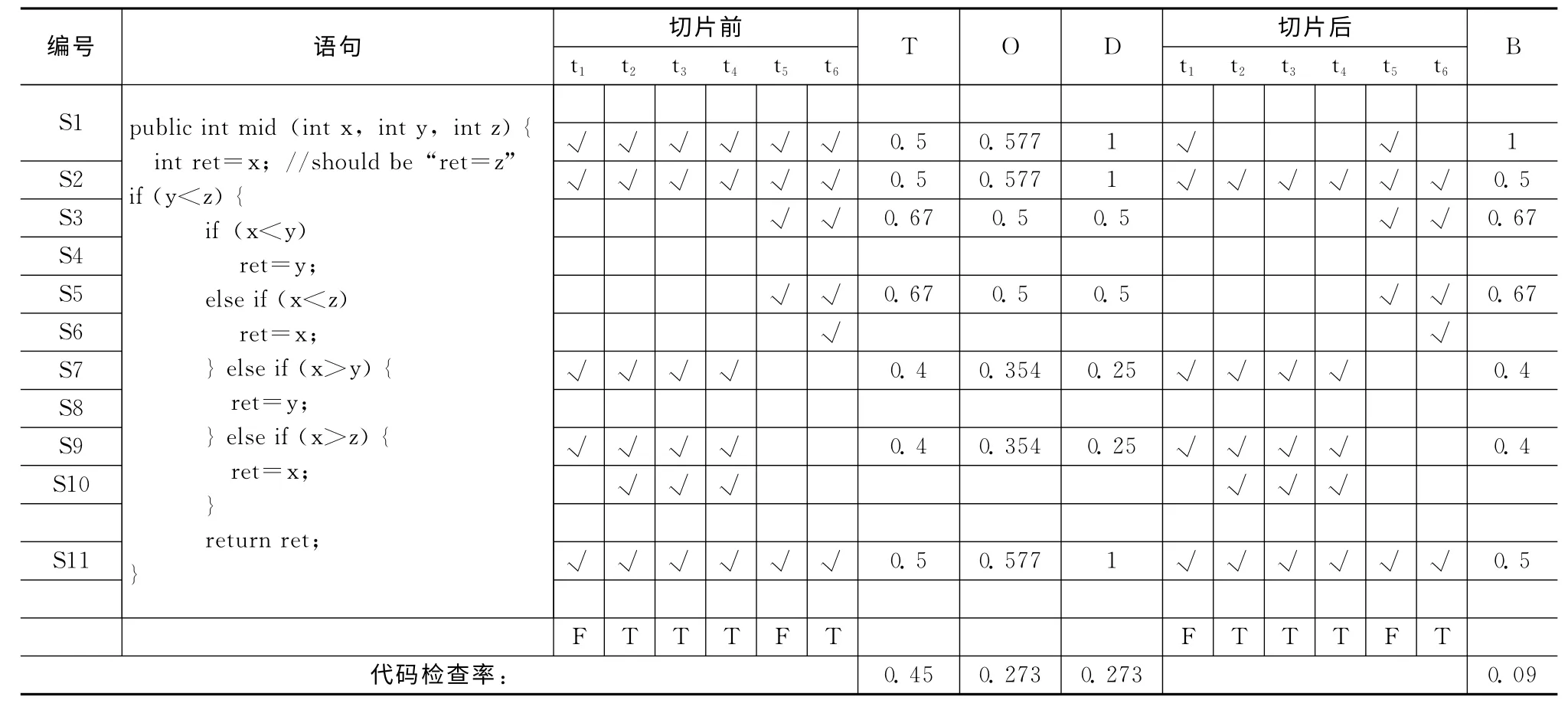
表1 实例程序
根据测试的覆盖情况和执行结果信息,我们引用了Tarantula[2,3],Ochiai[4],DStar[5]这3种基于覆盖统计的错误定位方法来定位错误语句。实验结果显示,需要检查超过27%的代码才能定位出错误语句。
实际上,在成功的测试中目标变量ret在重新赋值之前都没有被使用,而在失败执行中函数mid的最终返回值直接数据依赖于第二行代码。第二行代码出现在所有的测试执行中,但是它并不总是对最终结果产生影响。如果去除那些和目标变量没有关系的代码,然后再使用现有的一些可疑度度量方法将会得到更加精确的定位结果。实际上,错误的运行结果可能是由于执行了错误的分支,因此控制依赖关系也应该作为语句间关系进行分析。我们针对函数mid每次执行路径计算动态切片,然后再使用贝叶斯公式来计算语句的可疑度,计算结果如表1 中右侧部分显示,表明针对函数mid我们只需要检查10%的代码就可以定位到错误语句。由此显示我们的方法能够在一定程度上提高程序错误定位的效率和精度。
3 错误定位方法
为了获取程序执行轨迹,我们通过JDI[6]的事件机制实现了Java程序运行轨迹自动收集工具。该工具采用监听方式,等待目标程序的链接。在运行目标程序时只需要添加调试运行参数,即可实现执行路径的自动收集,程序执行轨迹算法如图1所示。

图1 程序执行轨迹算法
程序切片只分析与兴趣变量相关的语句,这样很容易缩小程序检查范围,去除不相关语句对错误定位的影响。本文针对给定的执行路径,在程序依赖图的基础上,利用图的可达性算法来计算程序的切片,大大缩小了检查语句的范围。
我们可得到程序执行结果和其精简后覆盖信息,然后使用Bayesian公式来估计语句的怀疑度。通过将语句的怀疑度转化为在语句X 出现情况下该次执行失败的概率 (记为P(H|X),其中P(H|X)中H 表示执行失败事件),而执行结果事件概率是根据统计信息获得,充当先验概率P(X|H),P(H|X)为后验概率。由贝叶斯公式我们可以获得以下计算公式
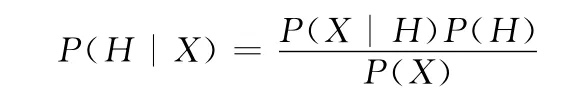
由于执行成功和执行失败事件共同组成全体执行事件,根据全概率公式将上述公式转换为
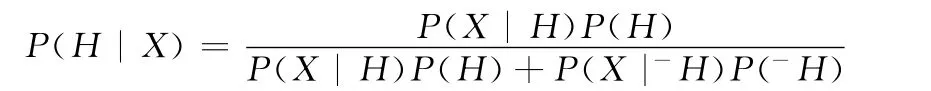
式中:H——执行失败事件,- H——执行成功事件,X——程序语句。
当得到语句怀疑度后,根据怀疑度值降序排列语句,然后调试人员根据该排序依次判断相应的语句是否为真正的错误语句。
4 实 验
为了验证我们所提出的方法的有效性,我们选取了4组开源程序作为实验目标程序。
4.1 实验对象
表2中列出了选取的4组实验对象,并给出了程序名称、功能描述、目标程序的代码行数、测试用例数和包含的错误数目。这4组实验目标程序都是Siemens suite中提供的程序,我们只选取了其中部分可测的错误。为验证提出方法的有效性,我们选择了基于频谱的错误定位方法Tarantula,Ochiai和Dstar作为比较对象来判定我们方法的优劣。
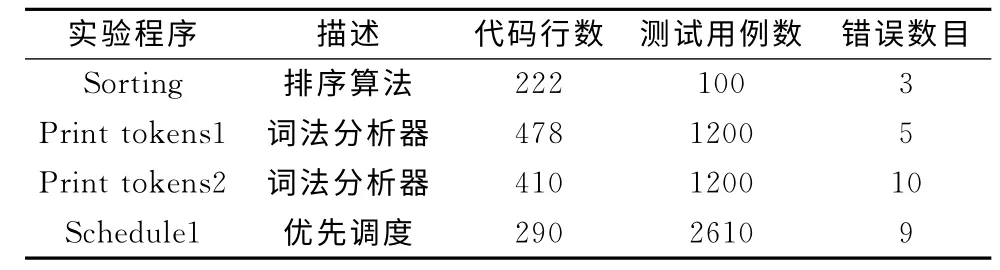
表2 实验目标程序
4.2 实验结果
在实验中,我们把定位出错误时所有需要检测的语句占总语句的百分比作为错误定位代价,把在不同的代价开销下定位出的错误占总错误的百分比作为错误定位方法有效性指标,记为LV。为了验证我们提出方法的有效性,我们分别统计了各个方法的最好情况、最坏情况和平均情况下的LV 值。图2中,x轴表示检查代码的百分比,y轴表示定位出的错误的百分比,折线上的点表示在对应x轴的代码检查百分比的情况下,定位出错误的百分比。图2 (a)显示在最好的情况下,采用我们的方法只需检查35%的代码即可定位所有错误,其它3种方法则需要检查45%的代码,而在代码检查率小于35%时,我们的方法检查出的错误率均比其它3种方法稍微高一些。图2 (b)中可以看出在最坏的情况下,检查出所有错误时采用我们的方法其代码检查率仍然低于其它3种方法,且在检查出相同错误率下,我们的方法代码检查率要远低于其它3 种方法。图2(c)显示了我们的方法的最坏定位效果和Tarantula,Ochiai差不多,比Dstar略差一些。图2 (d)可以看出我们的方法均比其它3种方法的整体定位效果显著。
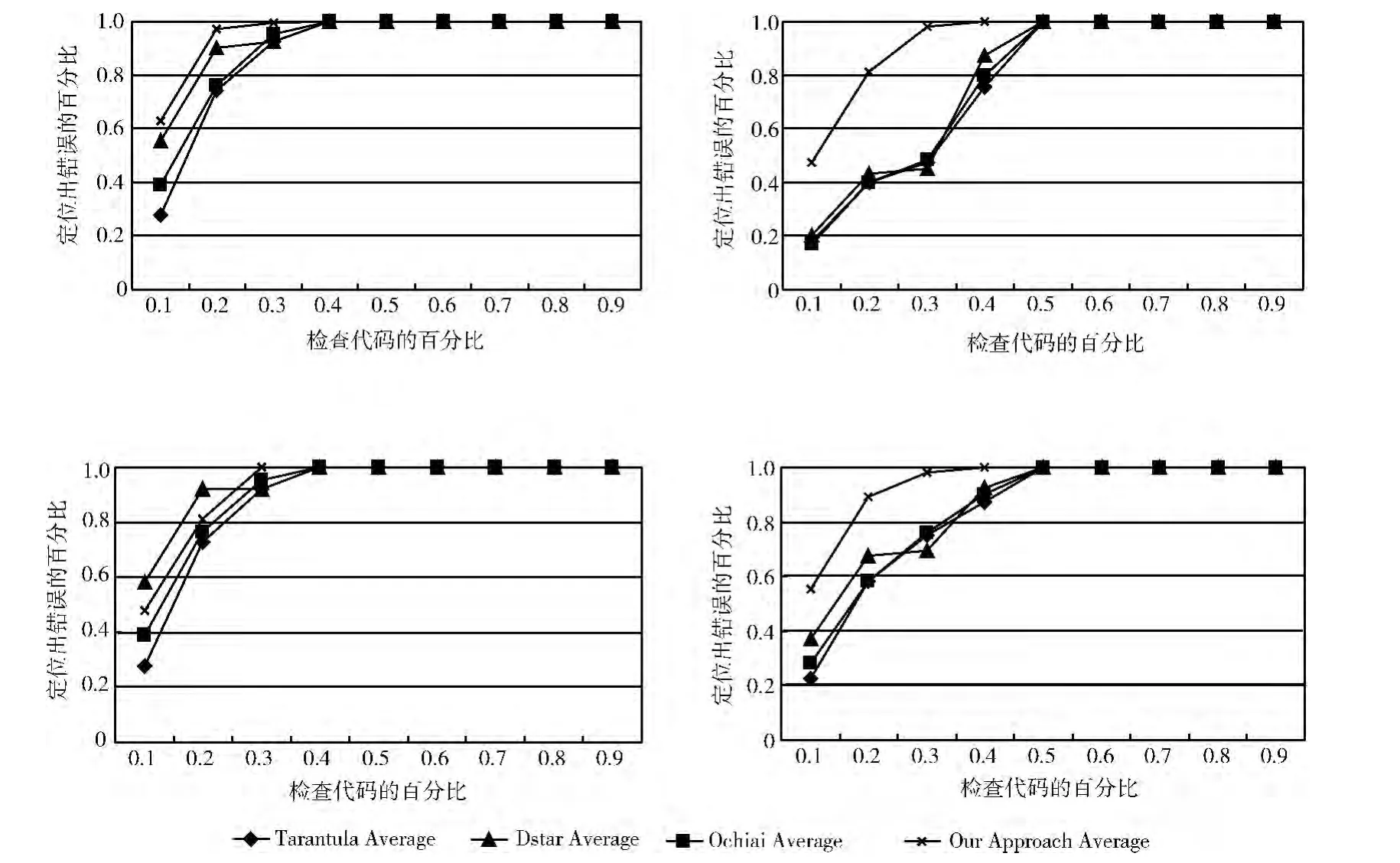
图2 实验结果
4.3 实验分析
本文方法通过计算程序切片缩小可以代码范围,然后在精简后的可疑代码集上做覆盖统计分析,而其它3种方法则是直接针对执行轨迹的覆盖信息进行统计分析,因此其它3种方法受到了不相关代码的影响。其中,对定位结果影响最大的不相关代码是那些和错误语句处在动态基本块中的语句或者是那些受错误语句影响的分支中的语句,而那些和错误语句处在动态基本块中的语句占有的比例相对大些,并且他们的可疑度值和错误语句的可疑度值相同,因此这些语句对最好的情况影响不大,而对最坏情况的影响比较大,因此造成图2 (a)、(b)中显示的最好情况下我们提出的方法定位效果提升的不大,而在最坏情况下却提升幅度很大的现象。
尽管图2 (a)、(b)、(d)中显示的是我们提出的方法的定位效果总是比其它3种方法好,但实际上在某些版本中定位效果不仅没有提升,甚至稍微差一些。造成这种现象是因为该数值是针对4 组程序的多个版本的汇总结果,再者由于x轴采用的是代码的检查率,我们只针对了10%,20%...90%这样的点进行了采样,每相差10百分点时代码数可能相差很大,尽管很多情况下提升幅度不大,但正好处在分界点上下区域。
5 相关工作
程序切片是一种比较主流的软件错误定位技术。目前,将程序切片技术应用到错误定位中的方法有:Sun[7]等提出了一种根据代码优先级策略和程序切片技术进行程序错误定位的启发式方法。文万志等人[8]提出了一种基于层次切片谱的错误定位技术,该方法通过分析分析程序不同粒度层次元素 (包、类、方法以及语句)之间的依赖信息,逐层对可能发生错误的元素进行筛选,缩小错误查找范围,提高了面向对象程序中的错误定位效率。Jiang等人[9]基于程序切片、动态信息和静态信息相结合,提出了一种空指针异常的错误定位方法。该方法在实时堆栈的指导下进行程序切片,在切片后的程序上进行空指针和别名分析,解决了空指针异常的错误定位问题。
Zhang等人[10]提出了只使用失效运行的FOnly错误定位方法。错误定位一般是基于成功和失效运行两类,而FOnly只关注失败运行,从统计趋势 (方差)上估计分析失败运行,并错误定位。Zhang等人[11]在分析错误与征兆的非确定性关系及后验概率的基础上,以概率加权二分图构造错误的传播模型,提出了基于贝叶斯疑似度的启发式错误定位方法。
Tarantula是一种基于代码覆盖的错误定位方法,根据语句块在成功和失败执行中出现的次数,计算语句块的可疑度,按照可疑度对程序语句排序的方法,调试人员依怀疑度降序检查语句,直到找到真正错误。在Tarantula基本思想的基础上一些研究人员对怀疑度计算公式进行了改进,Abreu等人[5]提出了Ochiai错误定位方法。Chen等人[4]提出了Jaccard错误定位方法。Wong等人[12]基于Kulczynski系数提出DStar(D*)错误定位方法。该方法可定位单错误 和 多 错 误 程 序。Artzi 等 人[13]将Tarantula、Jaccard、Ochiai这3种错误定位技术应用到WEB 错误定位中,效果良好。
我们的工作是首先利用程序切片技术来缩小查找的范围,然后基于切片后的执行轨迹统计语句覆盖信息,再利用贝叶斯公式来计算语句的可疑度。
6 结束语
本文提出了一种有效的错误定位方法,该方法结合了现有的程序切片和覆盖统计的错误定位技术。首先针对程序执行轨迹计算程序动态切片,减少了搜索空间;然后基于切片后的执行轨迹统计语句覆盖信息,利用贝叶斯公式计算语句的可疑度;最后根据语句可疑度降序排列语句,依次检查直至找出真正的错误语句。本文方法在程序切片的基础上给出了参照检查顺序,提高了传统的基于程序切片错误定位技术的效率;另外,相对于其它的基于覆盖的错误定位方法,使用程序切片技术在很大程度上减小了不相关语句对定位结果造成的影响。实验结果表明,该方法与以往的方法相比能够达到更好的效果。
尽管实验证明我们的方法取得了较好的错误定位效果,但也存在一些不足,仍需要进一步的完善与提高。首先该方法是在能够确定切片的准则的基础上进行研究,而在实际应用中大部分程序很难确定切片准则,因此还需要进一步定义切片准则。然后,我们的实验针对单错误定位效果较好,而对于多错误定位效果一般,下一步我们将研究使用数据挖掘的技术来对多错误进行聚类分析,然后在聚类的基础上进行错误定位。最后,针对实验分析中统计方法造成的实验误差问题,我们将从多角度对实验结果进行综合分析,以达到更准确的错误定位效果。
[1]HUANG Yajing,GAO Jianhua.Refactoring location method based on coarse-grained slice metrics [J].Computer Engineering,2011,37 (11):80-82 (in Chinese). [黄雅菁,高建华.基于粗粒度切片度量的重构定位方法 [J].计算机工程,2011,37 (11):80-82.]
[2]Artzi S,Dolby J,Tip F,et al.Practical fault localization for dynamic Web applications [C]//Proceedings of the 32nd ACM/IEEE International Conference on Software Engineering-Volume 1.ACM,2010:265-274.
[3]Shay Artzi,Adam Kiezun,Julian Dolby,et al.Finding bugs in web applications using dynamic test generation and explicitstate model checking [J].IEEE Transactions on Software Engineering,2010,36 (4):474-494.
[4]Arumuga Nainar P,Chen T,Rosin J,et al.Statistical debugging using compound Boolean predicates[C]//Proceedings of the International Symposium on Software Testing and Analysis.ACM,2007:5-15.
[5]Abreu R,Zoeteweij P,Van Gemund A J C.On the accuracy of spectrum-based fault localization [C]//Academic and Industrial Conference Practice and Research Techniques-MUTATION.IEEE,2007:89-98.
[6]Javadebug interface[EB/OL].[2014-04-05].http://www.ibm.com/developerworks/cn/java/j-lo-jpda4/.
[7]Sun J,Li Z,Ni J,et al.Software fault localization based on testing requirement and program slice [C]//International Conference on Networking, Architecture,and Storage.IEEE,2007:168-176.
[8]WEN Wanzhi,LI Bixin,SUN Xiaobing,et al.Technique of software fault localization based on hierarchical slicing spectrum[J].Journal of Software,2013,24 (5):977-992 (in Chinese).[文万志,李必信,孙小兵,等.一种基于层次切片谱的软件错误定位技术 [J].软件学报,2013,24 (5):977-992.]
[9]Jiang S,Li W,Li H,et al.Fault localization for null pointer exception based on stack trace and program slicing [C]//12th International Conference on Quality Software.IEEE,2012:9-12.
[10]Zhang Z,Chan W K,Tse T H.Fault localization based only on failed runs[J].IEEE Computer,2012,45 (6):64-71.
[11]Zhang C,Liao JX,Zhu XM.Heuristic fault localization algorithm based on Bayesian suspected degree [J].Journal of Software,2010,21 (10):2610-2621.
[12]Wong W E,Debroy V,Li Y,et al.Software fault localization using DStar(D*)[C]//IEEE Sixth International Conference on Software Security and Reliability.IEEE,2012:21-30.
[13]Artzi S,Dolby J,Tip F,et al.Fault localization for dynamic Web applications[J].IEEE Transactions on Software Engineering,2012,38 (2):314-335.
