K-means算法在玉米良种选育中的应用
2014-12-23邱建林卞彩峰陆鹏程
杨 娜,邱建林,潘 阳,卞彩峰,陆鹏程
(1.南通大学 电子信息学院,江苏 南通226019;2.南通大学 计算机科学与技术学院,江苏 南通226019)
0 引 言
聚类是一种无监督的分类方法,即没有任何先验知识可用[1]。k-means算法是以计算类的均值作为聚类中心的聚类方法。此算法简单快速,但是对k的选择需要人为确定,这使得聚类的准确性大大降低,聚类准则单一,不能综合考虑每个类内样本的相似性和每个类内数据个数的均匀性。Pun等人通过选取最佳的相似度度量方法来提高聚类的质量[2]。Nazeer等人为了提高k-means算法的准确性和有效性,提出了结合系统的方法来选择初始聚类中心,但是没有考虑到k值选取的问题[3]。文献 [4]结合遗传算法来选择最优的初始聚类中心,并且提高了聚类的准确性。在文献 [5]中从k=2开始聚类,根据数据的分布通过分裂原来的聚类中心来增加k 值,当数据比较分散时,此算法有很好的聚类效果。周士兵等人提出BWP聚类有效性函数来确定最佳聚类数目,但是计算复杂[6]。Dutta等人通过自动选取k值与人为经验结合来确定k-means算法中的参数[7]。虽然k-means算法存在选取初始聚类中心随机性比较大,聚类数目难以确定等问题,但是对k-means算法改进的研究在不断进行着。本文根据聚类的平均类内相似性和平均类间差异性来改进聚类有效性函数。以数字农业中的玉米良种选育为研究对象,先用主成分分析法和熵值法对玉米良种数据进行降维处理,然后根据改进的k-means聚类有效性函数来选取最合适的聚类数目,并进行聚类分析。最后用主成分分析和熵值法对玉米品种进行综合评价并选出精英玉米良种。
1 相关知识
1.1 主成分分析
原始的高维数据包含冗余信息和噪音信息,为了减少冗余信息对数据的影响,需要对高维数据进行降维处理。降维的方法大致分为线性降维和非线性降维2类。线性降维有主成分分析,线性判别分析等。非线性降维有多维尺度方法,核主成分分析等。线性判别分析使降维后的同一类中的数据尽量紧凑,非同类的数据尽量分离,但是需要知道数据的某种监督信息[8]。核主成分分析是线性主成分分析的推广,但是核函数需要人为定义[9]。主成分分析是1种常用的线性降维方法,它是通过线性投影,将高维的数据转换到低维空间中表示,并且要求低维空间的每一维数据方差最大,使各主成分的数据无关,同时最大化保留了数据的特性。通过比较低维空间中数据方差大小来确定数据的重要性。
1.1.1 数据均值化
为了消除量纲和数量级的影响,对数据进行主成分分析处理之前,先对数据进行预处理。一般数据预处理都是将数据标准化,即转化成均值为0,方差为1的数据集,但是这种标准化处理容易造成指标信息的丢失。为此我们采用数据均值化处理方式,这可以最大程度保留原始数据的特征,并且用在主成分分析中能提高第一主成分的贡献率,使得第一主成分能包含更多的信息[10]。
数据均值化就是用数据的均值去除原始数据,这种处理可以使处理后的新数据集中没有负数,便于处理。原始数据集包含n个样本,p个属性,构成n×p的数据矩阵X,每一行代表一个样本,每一列代表一个属性。对矩阵中的所有元素进行均值化处理,均值化计算公式为

式中:xij——X 中的任意一个元素,xj——X 中第j列的均值,yij——均值化后的数据元素值。
1.1.2 主成分分析过程
首先先要计算相关系数矩阵R,相关系数越大则关联性越大。相关系数矩阵是一个对称矩阵,每个元素数值大小代表2个属性的相关性的大小。

记Yi(i=1,2,…,p)为Y 的第i 列向量,则主成分表达式为

式中:Fi——第i个主成分的线性组合,Fi和Fj不相关(i≠j)。主成分中的权系数向 “高度相关指标子集”中的指标倾斜[11]。在每一个主成分表达式中,主成分权系数较大的对应的属性列向量是相关性较大的列向量,那么这几个列向量可以合并成一个列向量,达到降维的目的。根据主成分的累计贡献率选取主成分个数,一般要求累计贡献率在85%以上。
1.2 熵值法
根据信息论基本原理可知,信息的度量可以用信息熵来表示,如果信息熵越小,则其信息量就越大[12]。通过信息熵来计算各指标的权重,具体步骤如下:
(1)数据转换:将均值化的非负矩阵Y 转换成比重形式,即计算第i个样本的第j 个属性值在该属性中的比重。计算公式如下

(3)差异系数:第j 个属性的差异系数,此值越大则说明这个属性对整体的评价影响越大。计算公式如下
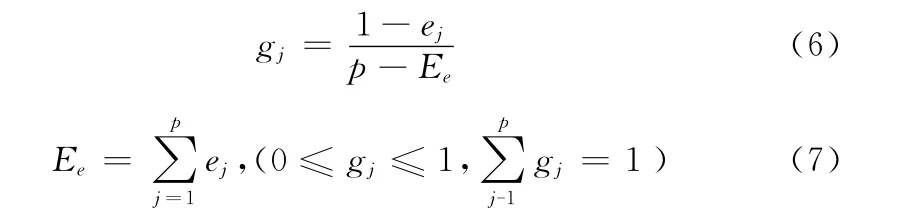
(4)权重:计算每个属性在总体属性中的重要性,权重越大,则该属性越重要。计算公式如下

2 k-means算法
聚类就是基于 “物以类聚,人以群分”的思想,按照数据的某种相似性度量,使得相似的数据聚为一类,使得同一类内的数据相似度高,不同类间数据差异性大。传统的聚类方法有k-means,k-mediods等,这些方法算法简单快速,但是难以确定具体的k 值。很多学者还在研究并改进k-means算法,足以见得k-means 算法的优势。对kmeans算法改进主要有以下几方面:一是对k 值的选取上进行研究;二是在聚类中心的选取上进行改进;三是在相似度度量方法上进行改进;四是与其他算法结合。
k-means算法的基本思想就是随机选取k个对象作为聚类中心,然后把剩余的对象按照某种相似度度量分配给相应最近的簇,再重新计算每个簇的聚类中心作为新的聚类中心,重复此过程,直到满足聚类准则。最基本的聚类准则函数是簇内误差平方和SSE,定义如下

式中:Ci——第i个类,ci——第i类的聚类中心,ni——第i类的样本个数,x——簇内的样本点。簇内的误差平方和越小说明簇内的点越紧凑,也就是簇内的点相似性越高。但是,SSE 不能保证簇与簇之间的差异性,也不能有效处理各个簇内样本个数的差别,不能保证每个簇样本数的均匀性[13]。
综合考虑类内数据的相似性,类间数据的差异性,还有每个类内数据个数的均匀性。根据聚类的目的,定义平均类内距来表达类内样本的相似性,平均类内距越小则类内样本相似性越高,其定义式如下

定义平均类间距来表达各个类之间的差异性,平均类间距越大则类间样本的差异性越大,其定义式如下

式中:ci、cj——第i类和第j 类的聚类中心,C2k——聚类中心之间距离的个数。
定义聚类有效性函数为

在不考虑k 值得情况下下,f 越大说明平均类内距越小,平均类间距越大,即样本的类内相似性越高,类间差异性越大。在保证聚类效果质量的前提下,希望k 值越小越好。
另外根据实际需要有时候还要考虑各个类内样本个数的均匀性,我们定义均匀性函数为

式中:ni——第i类所含的样本个数——平均每个类的样本个数,n——样本的总个数。若每个类的样本个数越均匀则N 就越大。当样本中有某一类内所含的样本个数相对其他类较少时,可以将这一类的几个数据作为异常点处理。鉴于有异常点的存在,所以均匀性函数并非越大越好。这时我们要综合考虑聚类有效性函数和均匀性函数,聚类有效性函数越大说明聚类效果越好,在排除异常点的情况下,均匀性函数越大越好。根据这2点来选择最佳的k 值,使得最后聚类效果得到最佳。
3 k-means算法聚类有效性函数实验
首先要确定k 值的取值范围,通常聚类的数目的最小值取2,即kmin=2。至于k 最大值的选取,没有明确的理论,一般使用经验规则,即kmax≤。Frey等人提出AP算法来确定最大的k 值,该算法快速有效,还能缩小kmax[14]。
采用UCI数据库中的iris数据集,wine数据集和glass identification数据集进行聚类有效性函数的实验。iris数据集有150个样本,4个属性,由AP算法知,最高聚类数为6。wine数据集178个样本,13个属性,由AP算法知,最高聚类数为9。glass identification数据集有214个样本,10个属性,由于在k=7,出现空簇,所以最大聚类数为7。在matlabR2012b中,对3个数据集进行平均类内距,平均类间距,聚类有效性函数,均匀性函数的计算,并且比较,得出最佳的聚类k 值。由于k-means算法是随机选取初始点的,为了确保聚类结果的稳定性,所以每次运行k-means算法50次。
由图1可知,对于iris数据集,当k=3时聚类有效性函数值最大,并且此时的均匀性函数值也最大,这与UCI数据库中描述分为3类相符。由图2可知,对于wine数据集,当k=3时聚类有效性函数值最大,并且均匀性函数值也最大,与UCI数据库中的描述相符合。对于glass identification数据集,聚类的k 可以取2、5、6。分类最精细的是k取6。由图3可知,当k=6时聚类有效性函数值最大,但是此时的均匀性函数值不是最大,根据我们的实际需求选择均匀性比较好的聚类还是聚类效果比较好的聚类。然而在k=2时,虽然均匀性函数值比较大,但是聚类有效性函数值比较低。所以选择k=6。
文献 [15]根据类内紧致性和类间总距离,提出的新的聚类有效性函数,此聚类有效性的时间复杂度比较高,每次计算聚类有效性函数需要计算2n+k 次乘积。文献[6]根据最小类间距离和平均类内距离,提出BWP 指标,每次计算此有效性函数需要计算n2次乘法,时间复杂度更高。本文提出的聚类有效性函数,每次只需n+k* (k-1)/2次乘法,大大降低了时间复杂度。此聚类有效性函数在保证正确率的情况下降低了计算的复杂度,从而提高了运行的效率。这3个聚类有效性函数时间复杂度的比较见表1。

图1 iris数据集

图2 wine数据集

图3 glass identification数据集

表1 有效性指标函数时间复杂度比较
4 k-means算法和聚类有效性函数在玉米良种选育中的应用
4.1 选取样本数据集
本文选取样本集是农业信息组2006年年终汇总的玉米样本集。选取51个子类玉米品种,选取每个品种的9个主要属性作为研究对象。这9个属性依次为全生育期、株高、穗高、穗长、穗粗、穗行数、千粒重、小区产量。原始样本集见表2。
4.2 数据集的主成分分析
(1)先对原始数据集进行均值化处理,得到新数据集Z 见表3。
(2)对Z 集进行主成分分析,计算得出特征值为0.0288,0.0160, 0.0113, 0.0077, 0.0033, 0.0019,0.0011,0.0007,0.0003。累计贡献率分别为40.51%,63.01%,78.90%,89.73%,94.37%,…。由于前4 个主成分的累计贡献率已经达到85%以上,所以选择4个主成分,前4个主成分权系数见表4。
由第一主成分知,V3、V6、V9 的系数比较高,说明这几个属性的关联性比较大。由第二主成分知,V3、V6的系数比较大,说明穗高和千粒重关联性大。由第三主成分知,V4、V7、V8 这3 个系数比较大,可以把穗长、穗行数、行粒数作为关联属性。
对Z 数据集进行相关性分析得相关系数矩阵R (如式(16)),V2、V3的相关系数比较大,说明这2个属性关联性大。同理V5、V7 的关联性也比较大。因此V2、V3、V6、V9作为一组关联属性集,即新属性1。V4、V5、V7、V8作为一组关联属性集,即新属性2。全生育期V1 作为一个独立的属性,即为新属性3。

表2 原始样本集

表3 新数据集Z

表4 主成分系数

4.3 熵值法确定权重
用熵值法确定9 个属性的权重分别为:0.1694,0.0556,0.0737, 0.1142, 0.1404, 0.1320, 0.1018,0.1122,0.1008。根据这9 个权重还有新的属性集,作3个属性权重向量W1,W2,W3。

因此新的数据列向量为N1,N2,N3,计算表达式如下

N 就是降维后新得到的新的数据矩阵。N 矩阵中的数据见表5。

表5 降维后新数据集
4.4 实验数据分析评价
4.4.1 对新数据集进行k-means算法处理并选择最佳的k值
对于k-means算法k 值得选取是人为确定的,但是不能保证选取到最佳的k 值。为了选取最佳k 值,我们需要考虑平均类内距,平均类间距,还有类的均匀性。平均类内距越小则类内相似性越高,平均类间距越大则类间的差异性越大。以平均类内距和平均类间距为基础,作聚类有效性函数f,f 越大说明聚类效果越好。另外考虑到每个类内样本个数的均匀性,定义了均匀性函数,以此来表征各类内样本的均匀性,并且均匀性函数越大则说明样本在各类内分布均匀。根据实际需要,更多希望样本相似度高点,但是样本中可能存在异常点的情况,所以我们优先考虑相似性。因为只有51个样本,所以只考察了k从2到8的情况。最后数据在matlab R2012b中运行所得见表6。
表6中可以看出k=2,3时均匀性很高,但是聚类有效性函数值不是很好,可能存在异常点。k=4时,聚类有效性函数值最高,排除异常点后的均匀性函数值也比较高。此次聚类是为了得到良种的聚类,所以对类均匀性要求不高,对相似度要求比较高。因此优先考虑相似度,再考虑类均匀性。k值得最佳选择为4。
由于k-means算法每次运行结果都会有点小差别,但对整体聚类效果的影响不大。最后聚类效果如下:
第1类:Y2,Y6,Y7,Y11,Y13,Y19,Y21,Y23,Y25,Y27,Y33,Y41,Y44;
第2 类:Y5,Y9,Y12,Y15,Y17,Y18,Y38,Y40,Y42,Y45,Y50,Y51;
第3类:Y3,Y4,Y8,Y10,Y14,Y16,Y20,Y22,Y24,Y26,Y28,Y29,Y31,Y32,Y34,Y35,Y36,Y37,Y39,Y43,Y46,Y47,Y48,Y49;
第4类:Y1,Y30。
图4为在三维空间内所有的样本点及其聚类中心。第1类中心用*号表示,由原始数据分析可知,这一类的特点是除了穗长、穗行数、行粒数值比较大和全生育期比较短之外,其他特征都不是很理想,很明显不是我们所要的玉米良种。第2类中心用圆圈o表示的,这一类穗长、穗粗、穗行数、行粒数都很小,没有明显的优势特征,还不如第1类的品质好,也不是我们所要的玉米良种。第3类中心用钻石表示的,这一类的特点比较突出,株高、穗高、千粒重、穗粗、小区产量都很高,符合我们所需要的良种要求,所以这一组可以作为玉米良种加以扩大繁殖。第4类中心五角星表示,只有2个样本点Y1、Y30,Y30株高和产量都很低,Y1穗高特别低,没有突出特点,可以作为异常点删除。由以上分析可知第3类的样本属于玉米良种,并且分析可得玉米产量与穗高的关联性很大。作玉米良种集S′,它由第3类中的24个样本和降维后的4个属性组成的数据集。

表6 不同k值下的各项指标的数值

图4 k=4时的聚类效果
通过计算全体样本的平均值和第3 类样本的平均值,发现第3类的大多数属性的平均值比总体平均值大,比较明显的有株高、穗高、千粒重、行粒数、区产量比总体平均值高出2.72%、5.78%、8.10%、1.17%、7.70%。这也充分说明第3类样本是玉米良种。
4.4.2 玉米种子的综合评价
利用主成分分析和熵值法来计算聚类得到的玉米良种中每一个种子的综合得分,再对每个种子得分进行排序,得到得分最高的几个种子。
(1)主成分分析综合得分:聚类得到的玉米良种数据集可以简化为由4个主成分组成的新数据集S′,S′是由24个样本4个属性的矩阵。我们把每个主成分的贡献率作为每个主成分的权重,得到权重集W1。因此得到主成分综合得分Score1,计算公式如下

(2)熵值法计算综合得分:为了避免主成分分析的综合得分中会丢失部分信息,我们再用熵值法计算每个样本种子的综合得分。由熵值法计算结果可得比重集P,属性权重集W2,综合得分为Score2,计算公式如下
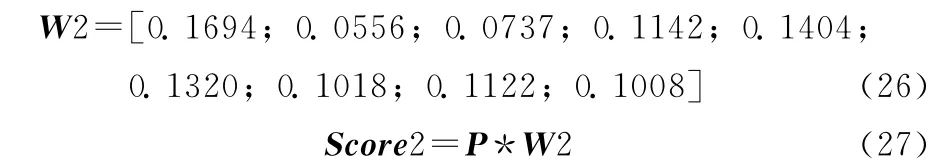
最后赋予主成分得分和熵值法得分的权重分别为0.5,0.5。最后综合得分为Score计算公式如下

根据Score的最后综合得分,对玉米良种集中所有的种子按照综合得分多少进行排序,其排名顺序见表7。

表7 玉米品种综合得分排名
为了确保我们所得到的玉米良种的质量,对玉米样本集进行了k-means算法聚类,这样使得大多数优良品种聚集在一起,减少了盲目选种的复杂性和工作量。还对聚类得到的玉米良种集中玉米种子进行计算主成分分析和熵值法相结合的综合得分,并对其进行排名。综合得分比较高的几个玉米品种作为最后的精英玉米良种,这样减少了由于误差错把劣种作为良种的可能性,使得我们得到的玉米良种更为优良。我们取排名在前5名的玉米品种作为精英玉米良种。
精英玉米良种:Y49,Y35,Y47,Y34,Y48。
5 结束语
为了选取最佳的k值,综合考虑平均类内距,平均类间距,用改进后的聚类有效性函数来选取最佳的聚类数目。实验结果表明所选取的k值能得到较好的聚类效果。为了减少玉米良种集中混入劣种的可能性,再用主成分分析和熵值法对聚类得到的玉米良种进行计算综合得分,并对其进行排名。
通过k-means算法、改进后的聚类有效性函数、主成分分析和熵值法综合对玉米样本集的处理,最后从玉米样本集中得到所需要的玉米良种。为了提高计算效率,还可以把k-means算法与其他算法相结合,选取最佳的初始聚类中心来提高算法的稳定性。这样可以使k-means算法更加完善。
[1]SUN Jigui,LIU Jie,ZHAO Lianyu.Clustering algorithms research [J].Journal of Software,2008,19 (1):48-61 (in Chinese). [孙吉贵,刘杰,赵连宇.聚类算法研究 [J].软件学报,2008,19 (1):48-61.]
[2]Pun WKD,Ali AS.Unique distance measure approach for kmeans (UDMA-Km)clustering algorithm [C]//TENCON 2007-2007IEEE Region 10Conference.IEEE,2007:1-4.
[3]Nazeer KAA,Sebastian MP.Improving the accuracy and efficiency of the k-means clustering algorithm [C]//Proceedings of the World Congress on Engineering,2009:1-3.
[4]Al-Shboul B,Myaeng SH.Initializing k-means using genetic algorithms[J].World Academy of Science,Engineering and Technology,2009,54:114-118.
[5]Joshi KD,Nalwade PS.Modified k-means for better initial cluster centres[J].International Journal of Computer Science and Mobile Computing,2013,2 (7):219-223.
[6]ZHOU Shibing,XU Zhenyuan,TANG Xuqing.Method for determining optimal number of clusters in k-means clustering algorithm [J].Journal of Computer Applications,2010,30(8):1995-1998 (in Chinese). [周世兵,徐振源,唐旭清.K-means算法最佳聚类数确定方法 [J].计算机应用,2010,30 (8):1995-1998.]
[7]Dutta H,Passonneau RJ,Lee A,et al.Learning parameters of the k-means algorithm from subjective human annotation[C]//FLAIRS Conference,2011.
[8]CHEN Shiguo,ZHANG Daoqiang.Experimental comparisons of semi-supervised dimensional reduction methods[J].Journal of Software,2011,22 (1):28-43 (in Chinese). [陈诗国,张道强.半监督降维方法的实验比较 [J].软件学报,2011,22 (1):28-43.]
[9]WU Xiaoting,YAN Deqin.Analysis and research on method of data dimensionality reduction [J].Application Research of Computers,2009,26 (8):2832-2835 (in Chinese). [吴晓婷,闫德勤.数据降维方法分析与研究 [J].计算机应用研究,2009,26 (8):2832-2835.]
[10]ZHU Shengwei,ZHOU Deyun,LI Zhaoqiang.Object threat evaluation based on improved principal components analysis[J].Computer Simulation,2010,27 (3):1-4 (in Chi-nese).[朱胜伟,周德云,李兆强.基于改进的主成分分析法的目标威胁评估 [J].计算机仿真,2010,27 (3):1-4.]
[11]SUN Liuping,QIAN Wuyong.An improved method based on principal component analysis for the comprehensive evaluation[J].Mathematics in Practice and Theory,2009,39 (18):15-20 (in Chinese).[孙刘平,钱吴永.基于主成分分析法的综合评价方法的改进[J].数学的实践与认识,2009,39 (18):15-20.]
[12]HUANG Guoqing, WANG Mingxu, WANG Guoliang.Weight assignment research of improved entropy method in effectiveness evaluation [J].Computer Engineering and Application,2012,48 (28):245-248 (in Chinese).[黄国庆,王明绪,王国良.效能评估中的改进熵值法赋权研究 [J].计算机工程与应用,2012,48 (28):245-248.]
[13]ZHANG Xuefeng,ZHANG Guizhen,LIU Peng.Improved k-means algorithm based on clustering criterion function [J].Computer Engineering and Applications,2011,47 (11):123-127 (in Chinese).[张雪凤,张桂珍,刘鹏.基于聚类准则函数的改进k-means算法 [J].计算机工程与应用,2011,47 (11):123-127.]
[14]Frey BJ,Dueck D.Clustering by passing messages between data points[J].Science,2007,315 (5814):972-976.
[15]LI Shuanghu,ZHANG Fenghai.New index for clustering validation [J].Computer Engineering and Design,2007,28(8):1772-1774 (in Chinese).[李双虎,张风海.一个新的聚类有效性分析指标 [J].计算机工程与设计,2007,28(8):1772-1774.]
