多核优化网络内容监测类系统的创新应用研究
2014-12-14周慧琴
周慧琴
(忻州师范学院,山西忻州034000)
0 引言
网络内容监测系统在功能结构、应用方向等方面与一般网络链路流量监测系统不同,网络内容监测系统从应用方面来说主要是对网络汇聚处的数据流量进行监测,而且网络内容监测系统的根本目的是对网络数据信息进行审查,扫描和识别网络信息的具体内容.网络内容监测系统的关键模块是负责与数据信息缓冲队列相关数据结构直接联系,从系统结构上来看其核心模块与数据信息匹配识别相关.网络内容监测系统与一般网络协议监测系统工作流程相似,但又存在着多种差异之处,因此,在对网络内容监测系统进行多核优化处理的过程中也会体现出很多特性特点,尤其是其优化结果能够真正达到提高网络性能的目的[1].由于网络内容监测系统能够将网络流量中包含的内容信息进行还原,并按照既定条件抓取网络流量中的特定内容信息,文章通过研究网络内容监测系统多核优化的问题,根据不同的网络协议类型,不断探索系统在审查网络数据信息方面的独特优势[2].
1 网络内容监测系统优化思路
(1)当网络内容监测系统(IRCMS)处于串行工作模式时,对其进行网络性能分析,通过实验在单核处理器平台上测试IRCMS系统的数据信息吞吐量性能,并根据相关指标分析IRCMS系统存在的性能瓶颈.
(2)当IRCMS系统运行于多核处理器平台时,逐个增加单核处理器的核心个数,测试系统吞吐量性能是否能够提高.
(3)综合分析处于多核处理器平台中IRCMS系统存在的性能瓶颈问题,针对具体问题提出多核性能优化策略.
(4)对完成多核优化之后IRCMS系统的数据信息吞吐量进行测试,与优化之前的吞吐量性能进行对比分析,得到性能提升比例.
(5)以IRCMS系统作为多核优化案例,分析应用了创新多核优化策略之后,IRCMS系统吞吐量性能提高的特点和规律.
2 网络内容监测系统性能实验分析
2.1 实验平台和实验流量
2.1.1 实验硬件平台
实验测评的硬件平台应用的是戴尔R710型号的多核服务器,服务器总共包含8个核心处理器(核心0至核心7),处理器采用的是Core微架构的Nehalem处理器.
2.1.2 实验软件平台
实验测评的软件平台选用的是CENT OS 5.3的 Linux发行版本,以及 Kernel 2.6.18操作系统内核;实验编译环境选用的是GCC 4.1.2编译器;系统测试工具为英特尔性能分析器.
2.1.3 实验业务流量
实验业务流量采用的是S市联通宽带网络出口链路的真实业务流量,如表1所示.

表1 实验业务流量情况Tab.1 Experimental traffic situation
2.2 IRCMS系统在单核处理器平台的性能实验
IRCMS系统在单核处理器平台中的吞吐量性能如表2所示.

表2 ITCMS系统单核处理器平台吞吐量性能分析Tab.2 Analysis of throughput performance of single core processor platform ITCMS system
2.3 IRCMS系统在多核处理器平台的性能实验
为了研究测评网络内容监测系统由单核处理器平台转移到多核处理器平台之后,网络性能是否能够得到扩展式提升,因此,对IRCMS系统运行于多核处理器平台中时的吞吐量进行性能测试[4-6].
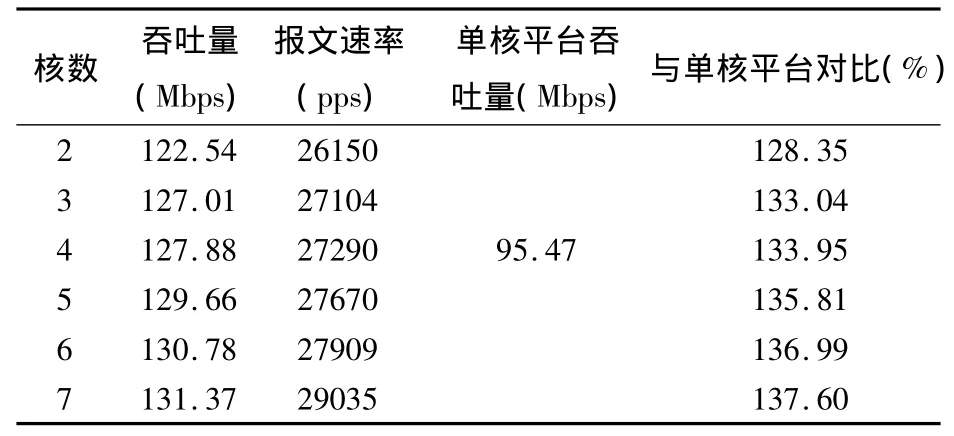
表3 ITCMS系统多核处理器平台吞吐量性能分析Tab.3 Analysis of throughput performance of multi-core processor platform ITCMS system
表3中,当IRCMS系统在2个核心的多核处理器平台运行时,吞吐量性能是在单核处理器平台运行的128.35%,但是,IRCMS系统性能提升只是通过单纯增加实验硬件配置得到的,吞吐量性能提升的幅度只限于30%左右.随着核心数量的不断增加,IRCMS系统的吞吐量性能没有明显幅度提升,由此,能够得到的结论是,IRCMS系统吞吐量性能提升并不具有良好的扩展性.而且,由表3数据分析可以表明,单纯地增加核心处理器的硬件数量,网络内容监测系统的吞吐量性能不能够得到大幅度提升,因此,只能通过优化软件系统提高网络内容监测系统的网络性能.
3 网络内容监测系统多核平台性能优化策略
3.1 应用三级流水线并行方式
多核平台性能优化中的流水线并行方式是有效的优化方法,是由处理器执行并行命令引鉴的,流水线并行方式是将系统的不同部分分为多个执行阶段,它们之间的耦合程度非常低,再将这些部分命令并行执行.本文对IRCMS系统进行多核性能优化实验,采用的就是由其本身特性决定的三级流水线并行方式.在IRCMS系统中,功能线程分为F1、F2和F3三种,当运行于单核处理器平台时仍然保持串行工作模式,本文根据主体功能线程的本身特点,分为多个不同的流水线结构单元,从而形成三级流水线并行的方式,再将三个不同的单元分别置于多核处理器平台的核心处理器中,以便能够同时得到数据信息资源进行计算.应用三级流水线并行方法进行多核优化之后,能够有效保证每个流水线的单元完成的是真正的并行处理[7].
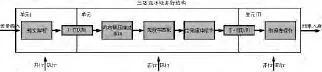
图1 三级流水线并行结构示意图Fig.1 three level pipeline parallel structure schematic diagram
3.2 计算流水线单元之间的资源配置比例
3.2.1 流水线单元之间硬件资源配置比例
本文多核优化性能实验中采用的多核平台共包含8个核心处理器,只有核心0的作用限于数据流量的输入,其他的7个核心处理器都用作于IRCMS系统的多核性能优化处理.流水线单元之间硬件资源配置比例,是要根据单元之间的功能的重要性,以及计算的具体需求,将不同的核心分配于不同的流水线阶段中,使得并行处理策略能够更加有针对性.因此,以图1的方式完成了流水线结构划分之后,能够明确计算需求最为密集的部分是第Ⅱ单元,当多核处理器平台增加了新的计算核心时,根据优先分配的原则发配到第Ⅱ单元使用.
3.2.2 流水线单元之间线程数量的匹配
当完成分配计算核心之后,需要对流水线单元线程数量进行比例配置,由于流水线单元线程的基于核心运行和执行系统任务的最小单位,因此,如果需要调节软件系统在每个阶段处理数据信息的速度,或者对不同模块运行造成的开销进行调节,可以通过增加和减少流水线单元线程数量来完成.而且,在对某个流水线单元的线程数量进行配置时,通常情况下要比投入的计算核心数量大,或者与投入的计算核心数量相等,由此才能够真正保证计算资源的充分利用.
3.3 应用结合 Linux调度的固定调度方式
固定调度指的是在充分利用核心处理器的亲和性前提下,将单元线程与特定计算核心通过关联使其运行于此计算核心之中,不会随意发生跳转.本文IRCMS系统的多核平台性能优化采用的结合Linux调度的固定调度方式,将IRCMS系统中的部分线程进行固定,另一部分线程由Linux将两部分结合共同完成调度任务.应用结合Linux调度的固定调度方式与传统的固定调度方式比较而言,灵活性有了明显提高,但是需要基于流水线单元资源配比之上才能应用[8].
3.4 对队列结构和衔接方式进行优化
3.4.1 对队列结构进行优化
对于某个队列来说,当这个队列的共享线程数量过多,就会引起队列之间的同步竞争,甚至出现严重的串行化情况.因此,如果要降低由于共享造成队列之间竞争的程度,需要以最大限度将队列局部化,将共享资源进行分解,以此达到减少队列的线程数量.
3.4.2 对衔接方式进行优化
衔接方式指的是线程和队列之间互相进行访问.通过对衔接方式进行优化,能够合理分配进行系统工作,具体优化步骤如下:
如图2所示,在第I单元中,F1线程是与Ⅰ-Ⅱ队列相互连接的,同时应用了报文连接分发的方式.网络源地址、网络目的地址、网络源端口、网络目的端口和网络协议的报文使用的是同一个连接.F1线程将此报文的连接传送到Ⅰ-Ⅱ相同的队列中,由此,F2线程可以在第Ⅱ单元中对同一个连接的报文内容信息进行扫描和审查,得到的匹配结果具有较强的相关性,使得系统管理员能够尽早发现问题所在.
在第Ⅱ单元中,F2线程与Ⅰ-Ⅱ队列、F2线程与Ⅱ-Ⅲ队列之间采用的是相同的一对一处理固定衔接方式.
在第Ⅲ单元中,F3线程与Ⅱ-Ⅲ队列之间的衔接应用的是轮询访问的衔接方式,F3线程对每一个匹配结果的缓冲队列进行轮询访问,并将其结果存储到数据库中[9].
将对队列结构和衔接方式进行优化进行综合分析之后,得到IRCMS系统的多核优化队列结构图,其队列数量能够根据投入的计算核心数量,以及流水线单元之间的现场配置比例关系进行灵活变化.
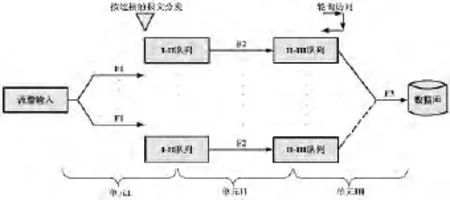
图2 IRCMS系统多核优化队列结构图Fig.2 multi-core queue structure diagram of IRCMS system
通过对队列结构和衔接方式进行优化,能够有效的将队列线程局部化,真正降低了线程数量过多而造成的队列竞争程度.
4 网络内容监测系统多核平台性能优化效果
在IRCMS系统应用了上一章节提出的多核平台性能优化策略进行多核优化之后,称之为AIRCMS系统.
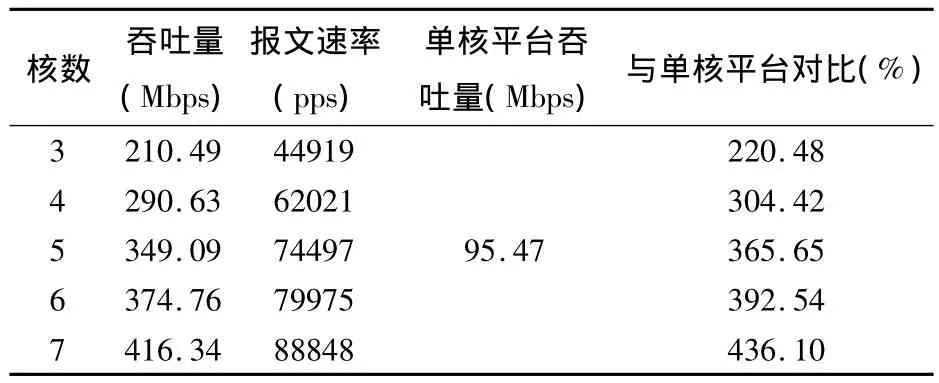
表4 AIRCMS多核处理器平台的吞吐量Tab.4 The throughput of AIRCMS multi processor platform
当实验投入了3个核心处理器时,AIRCMS系统的吞吐量性能随着核心数量的增加而明显大幅度提高.当投入了7个核心处理器时,AIRCMS系统的吞吐量性能能够达到416.34Mbps,与投入单个核心处理器的吞吐量性能相比较而言,吞吐量性能提高了436.10%,图3给出了AIRCMS系统在采用了多核优化策略之后,与未采用多核优化策略的系统吞吐量性能变化情况[10].

图3 多核优化策略应用前后系统吞吐量性能对比图Fig.3 The system throughput performance comparison chart of multi core optimization strategy before and after
本文提出的多核优化策略需要投入的计算核心为3个.由此在图3中,采用多核优化策略进行优化之后的AIRCMS系统的性能折线图并没有计算核心为2时的吞吐量性能点.对于没有采用多核优化策略的IRCMS系统来说,为了能够与AIRCMS系统性能提升的扩展性进行对比,因此,记录了核心2至核心7的吞吐量性能数据信息.
由图3可以看出,IRCMS系统的吞吐量性能应用了多核优化策略之后有了明显提高,能够随着投入计算核心的数量增加而持续升高.当没有应用多核优化策略时,IRCMS系统的吞吐量性能不能够随着计算核心数量的增加而明显提高.因此,如果需要网络内容监测系统在充分利用硬件资源的前提下,网络性能能够有显著性提高,必须有针对性将多核优化策略应用于软件系统中.
5 网络内容监测系统多核优化加速比分析
(1)定义多核优化加速比指标
指标多核优化加速比记作Sr,指的是综合考虑了并行执行开销之后的系统理论加速比,而系统理论加速比是多核优化加速比的基础.
(2)多核优化加速比公式
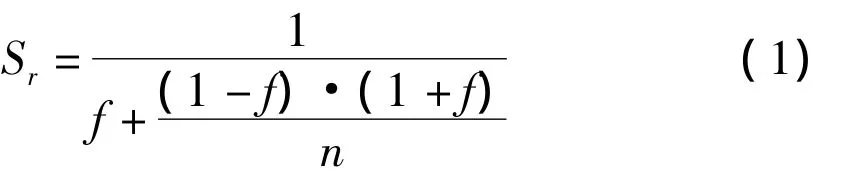
上述公式(1)中,f作为串行比例;n作为投入到系统运行计算的核心数量;fr作为并行执行开销与并行执行计算时间之比.表5给出了当投入不同的核心数量时,串行比例f的变化情况.
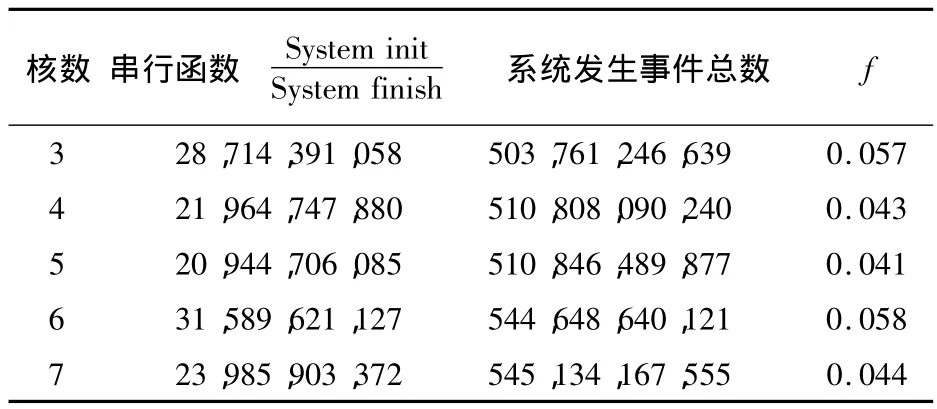
表5 投入不同的核心数量时f的变化情况Tab.5 The function changes when input different number of cores
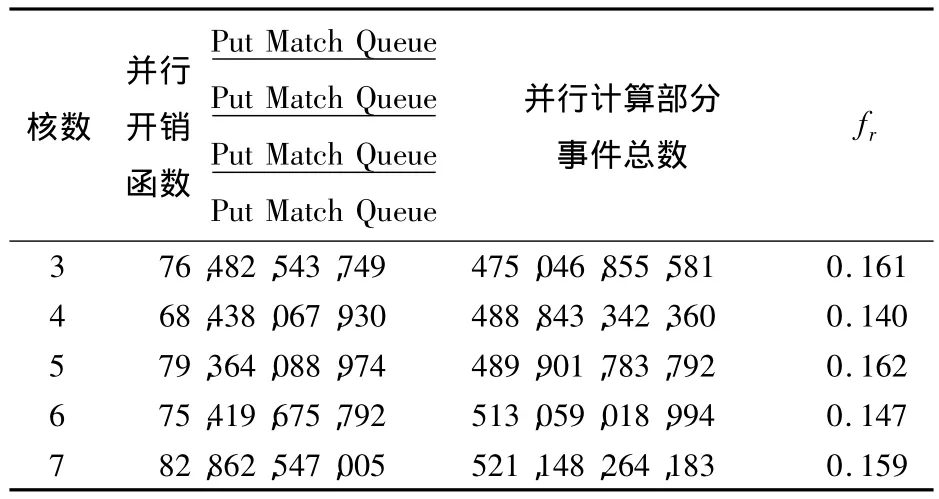
表6 并行执行开销与并行执行计算时间之比frTab.6 The ratio frof parallel execution overhead and parallel execution of computation time
根据公式(1),计算AIRCMS系统的多核优化加速比指标,如表7所示:

表7 AIRCMS系统多核优化加速比Tab.7 The AIRCMS system kernel optimization speedup
将AIRCMS系统的多核优化加速比指标与实际吞吐量性能提升比例进行对比,如图4所示.
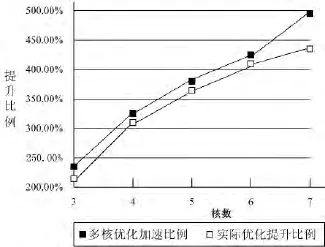
图4 AIRCMS系统多核优化加速比指标与实际吞吐量性能提升比例对比Fig.4 The ratio index of AIRCMS system kernel optimization speedup comparison with the actual throughput performance
对AIRCMS系统串行开销比例f,以及并行执行产生的新的开销比例fr进行测量计算,能够得到AIRCMS系统的多核优化加速比指标值数.图4中,多核优化加速比计算的吞吐量提升比例与系统吞吐量提升比例基本相同,但是在折线图的后半部分出现了明显差异,当计算核心的数量6和7时,系统吞吐量性能的提升已经开始落后于多核优化加速比例的提升.这是由于当计算核心的数量为6和7时,IRCMS系统中有两路F1线程同时运行于流水线第I单元部分,从而降低了系统吞吐量性能的提升比例,因此与多核优化加速比计算的吞吐量性能之间存在一定距离.总之,当IRCMS系统应用了本文提出的多核优化加速策略之后,吞吐量性能的提升幅度与多核优化加速比计算过后得到的理论吞吐量性能提升幅度基本相同.
6 结论
由于网络内容监测系统存在着严重的网络性能瓶颈,主要体现于报文数据的压缩、译码和传输,以及关键字匹配等方面.尤其是当网络内容监测系统需要完成关键字匹配工作时,其开销能够占据到系统总体开销的一半之多.本文选择了自主研发,且具有代表性的IRCMS系统,对IRCMS系统在多核处理器平台上的网络性能进行优化,根据IRCMS系统的实际情况提出了一套多核平台性能优化策略,并将其应用于IRCMS系统中进行评测,得到了AITCMS系统的吞吐量性能,将其与未应用多核优化策略的ITCMS系统的吞吐量性能进行对比分析,当投入的计算核心数量为7时,系统吞吐量性能的提升是之前的436.10%.因此,本文提出的多核平台性能优化策略能够使网络内容监测系统将集中于某一点的制约吞吐量性能的因素平均分配于多个资源中,从根本上提升了网络内容监测系统的整体性能,具有良好的现实意义和应用前景.
[1]赵林海,李晓风,谭海波.基于CACTI的分布式ORACLE监控系统的设计与实现[J].计算机系统应用.2010,19(09):134-138.
[2]陈晓霞,任勇毛,李俊,张潇丹.网络测量与分析研究综述[J].计算机系统应用.2010,19(07):244-249.
[3]宋焱淼,皇安伟,穆源,王芳.基于OWAMP的网络性能测量技术[J].计算机工程.2009,35(14):138-141.
[4]陈松,王珊,周明天.分层的互联网综合测量管理系统的研究[J].计算机工程与应用.2009,45(14):07-09.
[5]马维旻,曾宇胸,杨永平.一种分布式的宽带网络测量系统[J].计算机系统应用.2011,20(02):09-13.
[6]张潇丹,李俊.一种基于云服务模式的网络测量与分析架构[J].计算机应用研究.2012,29(02):725-729.
[7]程帆,王晓明.P2P网络中基于分组的成员管理方案[J].计算机工程.2012,38(01):256-257.
[8]Tierney B,Boote J,Boyd E,et al.Instantiating a Global Net work Measurement Framework[R].LBNL Technical Report LBNL-1452E.2009.
[9]Zurawski J,Boote J,Boyd E,et al.Hierarchically federated registration and lookup within the perfsonar framework(short paper,poster session)[C].Tenth IFIP/IEEE International Symposium on Integrated Network Management,2007.
[10]Guido R Hiertz,Dee Denteneer,Zang Yunpeng,et al.The IEEE 802.11 universe[J].Communications Magazine,IEEE.2010,48(1):62-70.
[11]Bo Xing,Seada K Venkatasubramanian.An experimental study on Wi-Fi Ad-Hoc mode for mobile device-to-device video delivery[C].Brazil:IEEEINFOCOM Workshops,2009:1-6.
