基于道集流的地震数据并行输入输出方法
2014-12-11刘永江
刘永江,邵 庆
(1.中海油研究总院 技术研发中心 北京100027; 2.东北石油大学 计算机与信息技术学院,黑龙江 大庆 163318)
0 引言
随着地球物理勘探技术的发展,地震数据的采集密度越来越高、采集容量越来越大,一个三维地震的数据文件通常达到1012b级.针对高精度的三维地震数据,人们研究各种地震资料处理算法,大多以道集为单元进行数据处理[1-2].道集指在地震资料处理中,根据计算需要从地震数据体中抽取满足某种条件的一组地震道数据,如具有同一中心点的道数据组成的共CDP道集,其他还有共偏移距道集、共检波点道集等[3-4].
传统的地震资料处理软件是以地震道为单元进行计算的,一次为处理模块提供一个道数据或一组连续的道数据,无法集成复杂的道集处理模块[5].为了支持对道集处理模块的集成,文必龙等开发基于道集流的地震资料处理系统MPS(Marine Process System)[6].在地震资料处理作业流中,道集流模块之间以道集作为数据输入、输出单元进行数据传递.道集流方式为深海高精度复杂地震资料处理算法提供方便的数据输入、输出方法,但对数据I/O提出更高的需求,需要对数据按道集进行分选、拆分、收集和存储[7].在完成复杂数据操作的同时保证数据I/O速度,是基于道集流的地震资料处理平台需要解决的关键问题之一.文献[7-10]研究道集流的数据I/O功能和效率,通过虚拟内存映射[7]、统一数据存取[8-9]和数据存取流程优化[10]等技术提高道集的数据I/O效率;这些技术主要是通过数据函数接口提供数据存取,只是在局部对数据操作进行优化设计,没有形成系统化的机制,难以满足大规模地震资料处理在效率上的需求.
在分析三维地震道集流特点和集群环境存储设备特点的基础上,笔者提出一种多道集流并行数据服务架构,优化地震资料处理系统的并行数据存取效率,并在MPS上进行测试和集成.
1 地震资料处理数据服务
常规地震资料处理作业流程由数据输入模块、若干处理方法模块和数据输出模块,按执行顺序排列组成(见图1).从输入模块到输出模块的运行是在一个作业进程中通过循环完成的,每循环一次完成一个道数据的处理.在作业流程内部,输入模块、方法模块和输出模块以串行方式运行.在作业运行时,前一个模块的输出作为下一个模块的输入,构成地震数据流.地震资料处理的基本单元是地震道数据,处理方法模块从数据流中收集道数据,当道数满足处理方法模块的输入条件时,对数据进行计算并把数据返回数据流缓冲区.如此不断循环,完成数据处理任务.
为了在多节点的集群系统中进行并行计算,地震资料处理系统需要为各节点分配计算任务,将数据分为若干组,各计算节点或进程按照作业流程计算分配的数据组.在道集流模式下,如果只将数据输入、输出单元由单道改为道集,难以满足数据处理的要求,主要存在问题:
(1)道集数据输入慢.由于一个道集的数据在地震数据体中不一定是连续存放的,需要进行数据筛选,因此输入模块必须从地震数据体中收集道数据并构成道集.当地震数据体很大时,数据收集速度变慢.
(2)道集数据输出慢.由于各进程、各节点间的作业流是并行执行的,在数据文件并行读方面不存在问题,但在数据输出时易产生写冲突.在单道数据输出时,由于数据输出量小,操作系统内部利用缓冲和事务处理功能可以解决写冲突;但是在道集输出时,一个道集数据就很大,系统的写冲突机制协调的结果是各节点排队写数据,导致并行计算的结果以串行方式输出,产生数据输出瓶颈.
(3)难以处理多个道集.复杂的处理算法需要同时对多个道集进行计算,流程更加复杂,传统的作业流控制模式无法处理这种复杂的数据流.
因此,提出基于索引数据库的并行数据输入、输出架构,道集流并行数据流处理作业流程见图2.该架构具有特点:
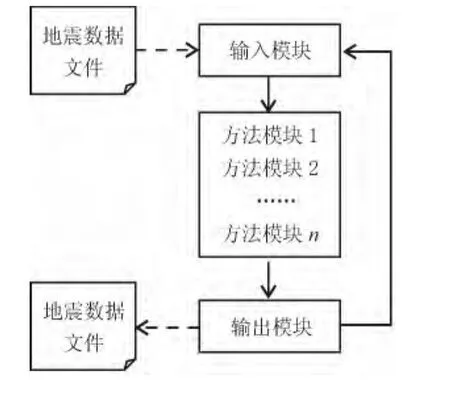
图1 常规地震资料处理作业流程Fig.1 Job flow in general seismic data process
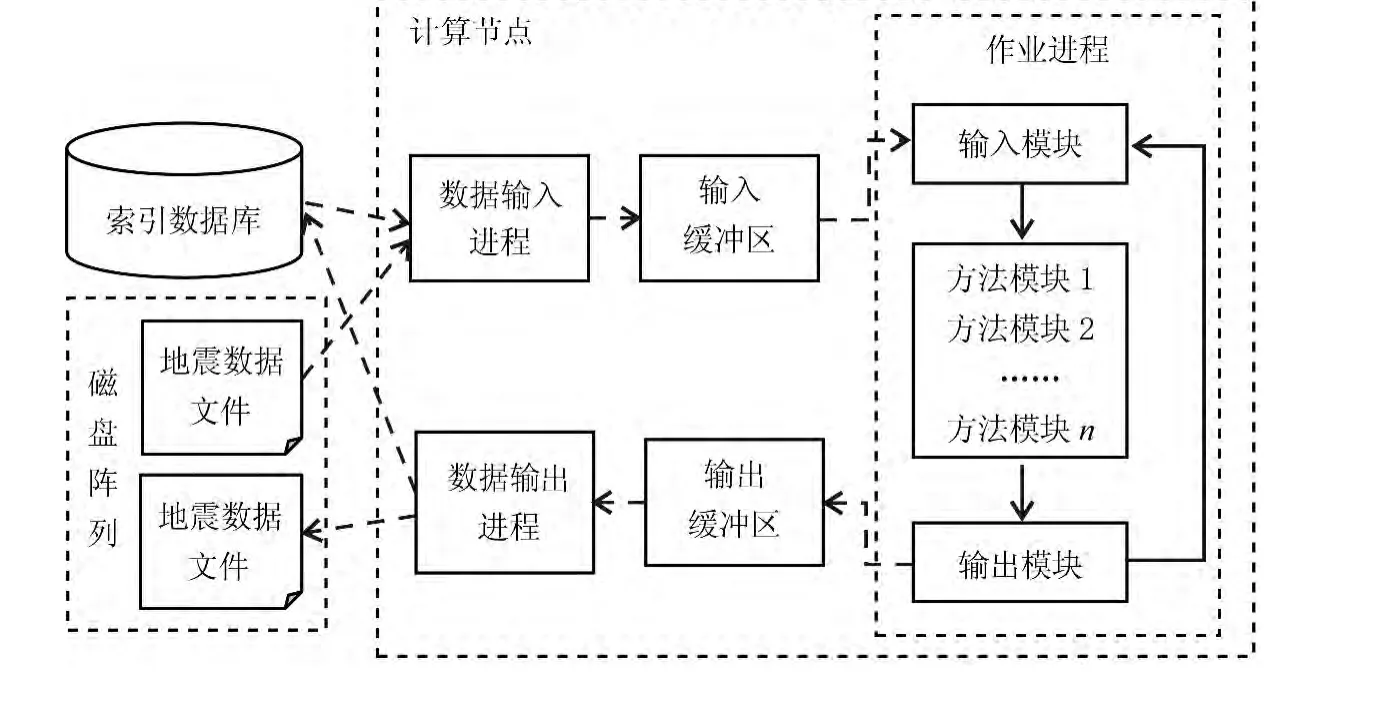
图2 道集流并行数据流处理作业流程Fig.2 Parallel data flow for trace gathers flow processing
(1)建立道头字索引数据库.道头字是抽道集的依据.索引数据库将道地震数据文件的道头字保存在数据表中,通过条件筛选和排序,得到道集中每一道的排序及其在地震数据文件中的道号.
(2)建立独立的数据输入、输出进程.数据输入、输出进程与作业进程并行运行,作业进程的输入、输出模块直接对数据缓冲区读写数据.由于在节点内实现并行数据输入、输出,能够大幅提高数据I/O效率,可以适应多道集的处理.
(3)设置独立的数据库节点.在集群环境中专门设置数据库节点,保证各并行节点共享索引数据库服务.由于每一个节点有多个核,可以支持集群环境中大规模并行访问数据库.
(4)设置专门的地震数据存储系统.在集群环境中建立磁盘阵列,用万兆级光纤网联接计算节点与磁盘阵列,保证节点并行存取速度.
2 索引数据库
地震数据存储通常由文件头、道数据和文件尾部分组成:SEGD、SEGY格式数据由文件头和道数据部分[11-12]组成,DHT格式数据由文件头、道数据和文件尾部分[13-14]组成.文件头描述地震数据采集参数,包括采样间隔、采集方式、数据编码格式和采集设备等全局性信息.文件尾包含一些与处理过程相关的信息.数据的主体是道数据,由若干地震道数据按一定顺序排列构成.每个道数据由一个道头字表和多个地震特性数据构成.道头字表由多个道头字构成,每个道头字表示道数据的一个特性,如道号、炮号、共深度点、叠加次数、炮检距、面元序号和三维inline号等.其中,道号是道在道数据集中序号,按1、2、3……进行编号.
道集流的基础是抽道集,即从地震数据文件中将符合条件的道数据提取出来,并按一定顺序排列.每个道集用三元组表示:
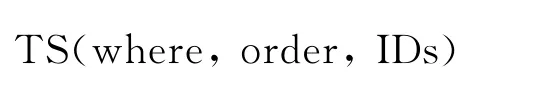
其中:
·where为道集筛选条件.where一般用1个或多个格式为“道头字 比较符 数值”的逻辑表达式进行
描述,如:“炮号=4”的道,“共深度点>5and共深度点<10”的道.
·order为道集排列方式.由一个或多个道头字组成,表示排序关键字.
·IDs为道集中所有道的道号集.
一个道集包含若干个道,各道在地震数据体中不一定是连续存存储的,其分布与输入数据的存储顺序及道集抽取方式有关.如当输入数据是炮序的,即按炮号为主关键排序(原始地震数据是按炮序排列的);如果按偏移距抽道集,道集中任何一个道都跨越所有的炮的道集,数据分布几乎跨越整个地震数据文件.每抽一个道集都要遍历一遍整个数据体文件,速度非常慢.

图3 道头字索引数据库ER主体结构Fig.3 Primary part of ER chart for database of trace head indexing
为了快速定位道集数据,设计道头字索引数据库,利用数据库的检索功能,快速筛选满足where条件道集信息,并按order条件进行排序,产生道集的道号集合IDs,输入、输出模块根据IDs条件直接在地震数据文件中定位读取数据.道头字索引数据库存储与地震工区相关的地震数据文件基本信息,以及每个地震数据文件的道头信息,其ER(Entity Relationship,实体关系)主体结构见图3.
工区表(Project)定义地震工区相关的信息.
地震数据文件表(SeismicDataFile)定义一个地震数据文件的相关信息,包括文件的路径和文件头中的主要信息.
道头信息表(TraceHead)定义道头字信息,道头字中的每一个关键字都对应一个TraceHead字段,每一道对应一条TraceHead记录.一个三维地震数据体包含的地震道多达千万条,为了提高数据检索效率,将不同工区地震数据的TraceHead分开建表,减少一个TraceHead表的数据记录数量.
通常情况下,在处理数据时一个工区只有一个地震数据文件.在地震数据采集过程中,有时将一炮或几炮的数据保存在一个文件里,在地震资料处理前需要将这些文件合并为一个大文件,不仅花费时间,占用很大的磁盘存储空间,而且对人工的分工操作和数据管理等也不方便.
提出虚拟地震数据文件的概念,在将多个实际的地震数据文件组织成一个新的地震数据文件时,并不生成新的数据文件体,只是在表SeismicDataFile中建立一条记录,在表TraceHead中增加一个文件号,记录每一道在哪个文件中的道号是多少;同时设计一张文件合并信息表MergeInfo,描述虚拟文件与各组成文件之间的组合关系.由于采用虚拟地震数据文件,避免人工合并文件,既可对单个文件进行处理,也可对整个文件进行处理.
地震资料处理系统首次加载地震数据文件时,通过对地震数据文件进行一遍扫描获取道对信息,在索引数据库中建立索引数据表;此外,在处理作业输出数据时也创建索引数据表.为了提高数据库操作效率和适应并行数据操作,采取策略:
(1)按常用关键字对表TraceHead建立索引,每个关键字对应一个索引.
(2)采用事务锁机制,保证数据操作的一致性.在数据处理过程中,各节点同时进行创建、插入和查询同一条记录的概率高,对一些特定的操作采用事务锁可以保持数据的一致性.
(3)利用数据库连接池和批量加载技术,减少进程与数据服务器的通讯次数.在数据处理过程中打开和关闭数据库时,在数据库服务器和客户端交换数据库管理信息,连接池只在客户端首次连接数据库时打开数据库,中间再有打开和关闭数据库时只返回连接信息,不再进行实际连接.向数据库中插入一条记录时,也有客户端与服务器之间的多次通讯,虽然每次操作的时间很短,但上千万次数据操作累积起来占用的时间很多;因此将向数据库中插入的数据先缓存在本地磁盘文件中,在完成数据处理后一次性向服务器进行批量加载,可大幅提高数据库操作速度.
3 并行数据输入输出
3.1 节点间
在地震资料处理系统启动各节点的分控程序时,向分控程序传递该节点要计算的道集范围,并启动数据输入、输出进程(见图2).因此,节点间的数据并行操作主要体现在数据库查询、数据读和数据写的并行方面.
各节点同时查询或写数据库时,数据库服务器本身具有多用户并发操作控制机制,为每个节点派发一个线程处理相应的数据请求;在各节点抽道集时,操作系统和磁盘阵列可以很好地处理并行只读操作,以避免产生冲突.
在各节点输出数据时将产生写冲突问题,因为磁盘系统对同一个数据块一次只允许有一个写操作,提出3种并行输出方式:
(1)文件锁方式.一个节点在写数据时,将数据文件加上锁,其他节点的进程要写数据时将被阻塞,在该节点写完数据时直接释放锁.文件锁方式本质上是一种串行写操作,效率很低.只有在数据量不大或用户在调试模式下工作时,才用文件锁方式.
(2)随机写方式.根据已知的输出道数和道长字节数,预先生成一个足够大的空文件,各节点只针对本节点写入的数据块进行操作.由于磁盘系统允许随机并行写操作,因此不产生冲突.随机写方式只适合输出道集可预先计算的情况.
(3)独立输出文件方式.各节点输出各自的文件,相互不干扰,利用提出的虚拟地震数据文件的概念,将独立的文件组织成一个虚拟地震数据文件,数据文件共享一个TraceHead表.这种方式输出效率最高,并且适合各种情况.
3.2 节点内
在一个计算节点中只有一个数据输入进程和一个数据输出进程,负责该节点多个作业进程的统一输入、输出.节点内的数据输入、输出并行指输入进程、输出进程和作业进程同时运行.
在数据输入进程与作业进程之间通过数据输入缓冲区进行数据协同.数据输入进程为根据任务清单进行抽道集,将道集数据放入数据输入缓冲区;作业进程由数据输入模块从缓冲区中按顺序读取道集,交给计算模块处理.当节点中有多个作业进程并行运行时,各进程从缓冲区的道集队列中获取道集,并行数据输入流程见图4.
在输入进程与作业进程并行运行过程中,需要协同控制缓冲区.数据输入进程不断地往缓冲区中存入道集,当缓冲区满时,需要等待缓冲中的道集被作业进程读出;当向缓冲区存入一个道集时,需要通知正在等待的作业进程.作业进程的输入模块不断从缓冲区中读入道集,当缓冲区空闲时,需要等待缓冲的道集被数据输入进程存入道集;当从缓冲区读出一个道集时,需要通知正在等待缓冲区的数据输入进程.由于可能有多个进程同时从缓冲区读道集,因此需要对道集缓冲进行全局性控制.
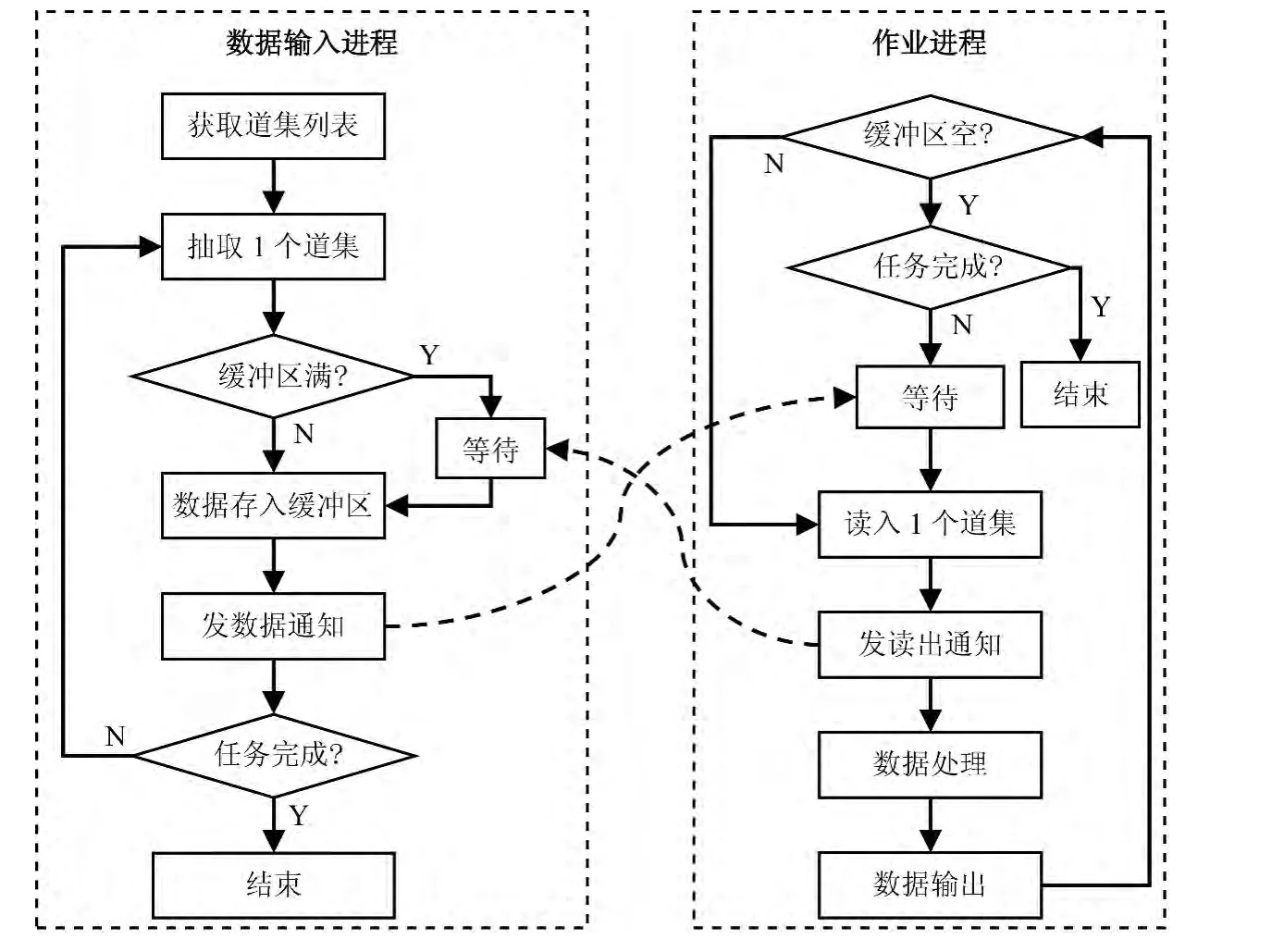
图4 并行数据输入流程Fig.4 Work flow for parallel data input
采用信号量控制缓冲区和道集数据,给出统一的信号量、初始化、P操作和V操作定义,实现数据输入进程与作业进程间的控制通讯.数据输出流程与数据输入流程相似.
并行数据输入、输出机制能够适应多道集处理的需要.一般情况下,作业流程一次循环只处理一个道集,但在复杂的地震资料处理算法中,一次计算需要用到多个道集流的数据,需要启动多个输入进程.
通过数据并行输入、输出机制,能够提高地震资料处理效率(见图5).假设输入一个道集的时间为T1,执行一次处理流程所用时间为T2,输出一个道集的时间为T3,共有n个道集需要处理.
在串行模式下,完成全部资料处理的时间Ts为

在并行模式下,在完成一个道集的输入后才能启动作业流,在完成一次作业流后才有输出,在完成所有处理后还要完成最后一次处理的输出.在不考虑多个作业流并行及数据缓冲区等待的前提下,在并行模式下完成全部资料处理的时间为

式中:T4为输入、作业和输出迭加执行的时间,即各迭加部分最长部分的时间.一般情况下作业计算占用的时间明显多于输入、输出占用的,因此T4取为(n-1)T2.
为了提高并行速度,即减少Tp,最直接的方式是减少T4的开销.因此,在同一节点内,采用多核并行执行作业进程的核数越多,每一个核的循环次数就越少,T4越小.如果作业流程的处理模块很少、处理开销小于数据输出的时间时,T4的开销变为输出道集的时间.为了提高作业处理效率,可以减少作业流并行数,增加输出进程的并行数.通过调整不同进程的并行数,保持作业执行时间与数据输出时间的平衡,以实现处理效率的最优化.
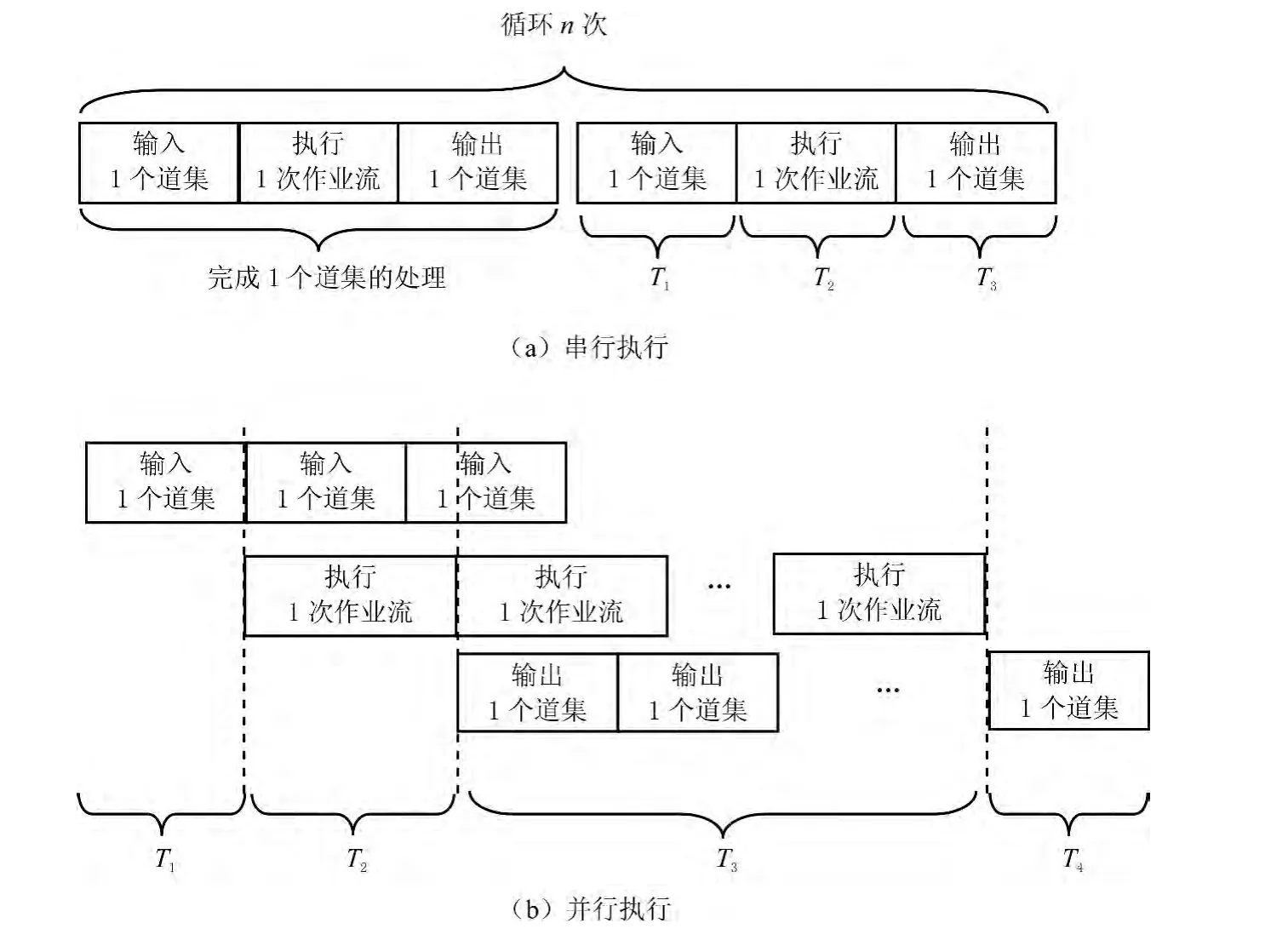
图5 地震资料处理时间序列Fig.5 Time series in seismic data process
4 测试
文中基于道集流的地震数据并行输入、输出方法在中国海洋石油总公司开发的海上地震资料处理系统MPS中得到应用,与商业地震资料处理软件Foucs在同一集群环境中进行对比,MPS的应用效果优于Focus的.MPS和Focus的测试数据I/O速度结果见表1,其中测试序号1~3分别表示3种测试情况:1表示有数据输入,同时加载一个处理方法模块;2表示有数据输入和数据输出,同时加载一个处理方法模块;3表示只有数据输入和数据输出,不加载任何处理方法模块.
在相同条件下,MPS的处理速度要快于Focus的.当计算节点数增加时,MPS的速度提高幅度比Focus的明显,主要原因是MPS在数据I/O上采用多文件输出,避免并行数增加时数据输出竞争的现象.
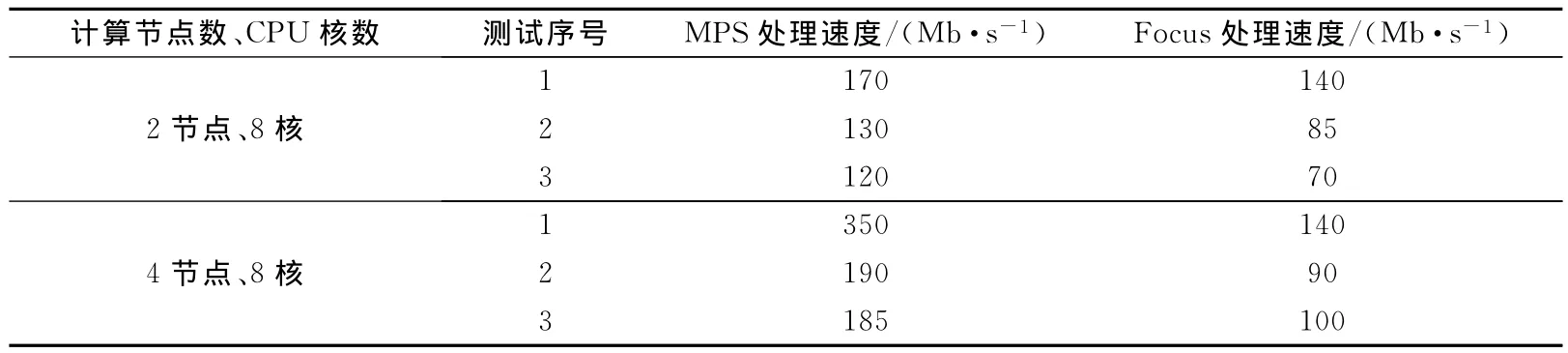
表1 MPS与Focus的效率测试结果Table 1 Comparison of data I/O efficiency in MPS and Focus
此外,测试MPS在采用不同CPU核数进行地震资料处理时的输入﹑输出效率,结果见表2.在有输入﹑输出和处理方法模块时,平均数据处理速度近150Mb/s.当并行CPU核数达到40左右时,即使再增加CPU核数,也不能提高数据处理速度.这是因为随着并行数提高,进程对磁盘I/O、网络带宽开始形成竞争,再提高速度需要通过硬件升级提高网络带宽和磁盘I/O并发效率.测试序号1的速度随核数增加提高得明显,表明磁盘阵列能够很好地处理数据的并行输入,影响数据I/O效率的重点是数据的并行输出.

表2 不同核数时MPS并行处理性能测试结果Table 2 Test result for MPS Parallel processing performance with difference core
5 结束语
基于道集流的地震数据并行输入﹑输出方法集成数据库技术、进程并行控制技术、海量数据文件存取技术,能够有效地适应基于道集流的地震资料处理,对海量三维地震资料处理有较高的数据存取效率;由于采用独立数据输入、输出进程,在数据存取方面具有较好的可扩展性,可支持多道集流的处理模式,以及不同处理作业流程下的优化配置.
(References):
[1]Brahim Abbad,Bjorn Ursin,Didier Rappin.Automatic nonhyperbolic velocity analysis[J].Geophysics,2009,74(2):1-12.
[2]Fu Liyun.Wavefield interpolation in the Fourier wavefield extrapolation[J].Geophysics,2004,69(1):257-264.
[3]Pang Tinghua,Lu Wenkai,Ma Yongjun.Adaptive multiple subtraction using a constrained L1-norm method with lateral continuity[J].Applied Geophysics,2009,6(3):241-247.
[4]陈生昌,王汉闯,陈林.三维 VSP数据高效偏移成像的超道集方法[J].地球物理学报,2012,55(1):232-237.Chen Shengchang,Wang Hanchuang,Chen Lin.A hight efficient super-gather migration method for 3DVSP data[J].Chinese Journal of Geophysics,2012,55(1):232-237.
[5]胡学庆.集群环境下海量数据存储管理技术的研究[D].大庆:东北石油大学,2010.Hu Xueqing.Research of massive data storage and management in cluster environment[D].Daqing:Northeast Petroleum University,2010.
[6]文必龙,胡学庆,刘永江.海量数据跨盘存储机制的设计与实现[J].郑州轻工业学院学报:自然科学版,2010,25(3):46-48.Wen Bilong,Hu Xueqing,Liu Yongjiang.Design and implementation of massive data across storage devices[J].Journal of Zhengzhou University of Light Industry:Natural Science Edition,2010,25(3):46-48.
[7]文必龙,宗文栋.海量并行处理系统的大数据读写接口优化研究[J].郑州轻工业学院学报:自然科学版,2012,27(3):28-31.Wen Bilong,Zong Wendong.Research on interface optimization for reading and writing large data of massive parallel processing system [J].Journal of Zhengzhou University of Light Industry:Natural Science Edition,2012,27(3):28-31.
[8]Xiao Bo,Wen Bilong.Unified format definition for bulk data[C]//Proceedings of 2011International Conference on Electronic and Mechanical Engineering and Information Technology.EMEIT 2011:2571-2575.
[9]Liu Yongjiang,Wen Bilong.Unified format definition for seismic data[C]//Proceedings of 2011International Conference on System Design and Data Processing.ICSDDP 2011:205-208.
[10]文必龙,赵满,刘永江.虚拟地震数据文件并行访问策略[J].计算机系统应用,2013,22(4):211-15.Wen Bilong,Zhao Man,Liu Yongjiang.Parallel access virtual seismic data file[J].Computer System Application,2013,22(4):211-115.
[11]SEG Technical Standards Committee,SEG-D,Rev 3.0,SEG Field Tape Standards[S].Society of Exploration Geophysicist,2012.
[12]SEG Technical Standards Committee,SEG Y rev 1Data Exchange[S].Society of Exploration Geophysicist,2002.
[13]冯翔.基于hadoop的地震数据分布式存储策略的研究[D].大庆:东北石油大学,2013.Feng Xiang.The research of seismic data distributed storage strategy based on Hadoop[D].Daqing:Northeast Petroleum University,2013.
[14]赵满.地震数据并行访问策略的研究[D].大庆:东北石油大学,2012.Zhao Man.The research of parallel accessing strategies for seismic data[D].Daqing:Northeast Petroleum University,2012.
