基于程序访存行为的片上网络能耗优化方法*
2014-12-10褚廷斌黄乐天
褚廷斌,黄乐天,阎 波
(电子科技大学,四川 成都 610036)
0 引言
通信瓶颈和能耗密度的爆发性增长是现代的单片多核处理器(CMP)设计面临的两项重大挑战。片上网络(NoC)是一种高度灵活、可扩展性极强的片上互连方式,可极大地提高通信带宽,有效缓解片上通信瓶颈问题[1]。相比传统总线而言,片上网络虽然提高了传输带宽,然而其能耗问题并没有根本解决。如MIT的RAW多核处理器以及Intel的80核Teraflop芯片,其片上网络的能耗约占整个芯片能耗的 30~40%[2-3];在 2011年计算机辅助设计国际会议上,Chris Malachowsky,Nvidia的创始人之一,指出未来芯片内数据交换的能量消耗将远远超过计算操作的能量消耗[4]。因此,对片上网络的能耗进行有效的管理和优化,提高片上通信的能量效率,对于整个芯片的性能有着极其重要的意义。
此前面向NoC的能耗优化主要采用分布式电压频率调控,这样可以提高DVFS的自由度,然而这样的设计带来了极大的硬件复杂度,并且由于不同频率域间的同步,增加了片上通信的延时和能耗开销[5]。
SHANG L等人展开了NoC领域DVFS研究的开创性工作,他们根据一段时间内链路的流量大小对每条链路进行电压频率调节[6];MISHRA A K等人提出了对每个路由器的电压频率调节方法,通过监测路由器输入缓存中的数据包大小以及上游路由器的拥塞情况来改变每个路由器的电压频率[7];GUANG L等人提出了一种层次化的片上网络能耗管理架构,主要是通过监测每个路由器的缓存信息来设置电压频率,即当缓存占用率超过(低于)预先设定的阈值,就提高(降低)一个电压频率等级[8]。
然而这些方法都忽略了这样一个事实,即CMP上程序对于NoC的服务需求并不总是跟网络的流量相关。如图1所示,程序 Blacksholes比Radiosity的网络平均注入率更高,然而NoC频率对程序Radiosity的性能影响更大,说明不能单纯通过网络流量大小来调节NoC的频率。此外,基于NoC互连的CMP系统中片上缓存是按地址行交替分布在不同缓存块中,导致不同节点的数据访问流量较为平衡,分布式的控制对于CMP这种架构并不十分有效[9]。
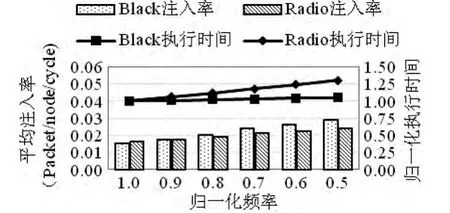
图1 程序性能与NoC频率、网络流量大小关系
因此对于面向CMP的片上网络能耗优化更适合于全局控制的方法。然而将NoC作为一个整体进行控制,需要一种有效的全局监控手段,同时需要适当的监测参数以准确地反映出程序对于NoC的服务需求,然后再根据合适的DVFS控制算法进行电压频率的设置。
1 系统设计
1.1 系统整体结构
如图2所示,一个典型的基于NoC互连的CMP系统主要包括处理器及其私有缓存、片上路由器以及LLC(Last Level Cache)Bank。LLC在逻辑上是一个整体,属于全局共享缓存,然而在物理上它们分布在不同的节点,各个节点通过网络接口与路由器相连。

图2 系统整体架构
在本文设计的系统中各节点均配置一个本地代理监测单元(Local Agent),用于收集每个节点的性能参数。而独立的功耗管理单元(Power Management Unit,PMU)负责将各个本地代理收集到的性能参数进行分析和计算,并最终控制片外的电压调节模块(VRM)和时钟模块(PLL)来改变NoC的电压和频率。
1.2 性能参数采集
在CMP中,程序的执行时间主要包括处理器执行时间以及访存延时。NoC作为访存的通信介质,其工作频率的大小直接影响访存延时,那么程序的平均访存次数反映了其对于NoC的服务需求大小。因此,每个本地监测通过3个性能计数器收集程序的访存信息,包括私有缓存缺失计数器、LLC缺失计数器以及指令计数器。当每个控制周期到达时,本地监测单元负责将监测的性能参数打包发送给PMU所在的节点,然后重置性能计数器。
2 控制算法描述
PMU负责将每个路由节点的信息进行处理,把所有的缓存缺失数相加并除以总的指令数,计算平均每指令产生的缓存缺失数 MPI(Miss Per Instruction)。
通过对大量应用程序的训练测试,得到不同MPI和NoC频率下程序的性能损失,如图3所示。不难看出,当MPI值很小时,NoC频率对程序的性能影响很小,因此可以降低NoC频率以节省能耗。

图3 MPI、NoC频率与性能损失关系
可通过一个简单的基于查找表的DVFS控制方法实现对NoC频率的控制,实现这一方法最为关键的是确定不同电压频率等级间MPI值的分割边界。利用支持向量机(SVM)算法将两种频率下的数据点进行最大间距分割,很容易得到两种频率之间的分界值(如图3)。采用同样的方法可以确定其他频率之间的分割边界。最终的控制表如表1所示。
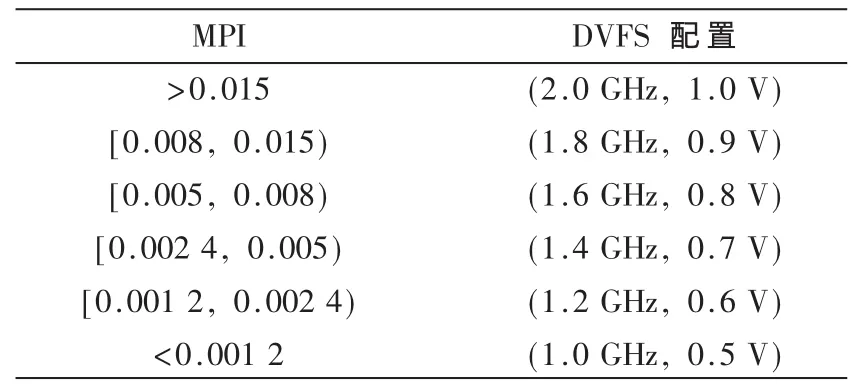
表1 DVFS控制表
根据不同的应用场景和平台配置,采用同样的方法可以训练出不同的控制表,以满足不同场合中对性能与能耗的不同需求。该表可以被编程下载到PMU内部保存,PMU将计算出的MPI值进行查表即可得到对应的NoC电压和频率。由此可见,该控制方案十分简单,可快速地对程序的访存行为变化进行自适应调节,进而对NoC的能量效率进行优化。
3 实验和结果分析
3.1 实验平台
为了评估和验证提出的全局DVFS方案,本文采用基于SimpleScalar的全系统仿真平台构建图2所示的片上多核系统。该平台集成的PoPNet和ORION可模拟片上网络的时序行为,并统计其能量消耗。此外,可通过设置不同的配置参数以模拟不同微体系结构的CMP系统。本次实验中主要的配置参数如表2所示。

表2 仿真器配置参数表
3.2 性能与能耗结果分析
为测试控制算法性能,从PARSEC和SPLASH2测试集中选择了6个典型的并行程序,通过仿真器分别对这6个应用程序进行了详细的时序与能耗仿真,实现并比较了下面3种不同的DVFS方案:
(1)BaseLine:无 DVFS,NoC运行在最高频率,作为其他方案的比较基准;
(2)Global DVFS:本文提出的基于程序访存行为的全局DVFS方案;
(3)Local DVFS:GUANG L等人提出的分布式 DVFS方案,监测路由器输入缓存的占用大小设置电压和频率,在每条链路中添加了同步缓存并增加了一级流水线延时。
图4显示了不同DVFS方案下片上网络的归一化(以BaseLine为1)能量消耗情况。从图中可以看出,GUANG L采用的分布式DVFS方案可以达到平均约30%的能量节省,而全局DVFS方案所达到的能量节省约45%,比分布式的方案可节省能量15%以上。

图4 不同程序的归一化能耗
图5比较了不同方法下程序的归一化执行时间。不难看出,由于对NoC的频率调节,程序的执行时间会或多或少地增加,分布式的方案造成程序执行时间的增加约为8%,而全局DVFS方案平均增加了仅5%的执行时间。

图5 不同程序的归一化执行时间
4 结论
本文提出了一种用于片上网络能耗优化的全局DVFS方案,通过监控平均每指令产生的缓存缺失数来动态调节片上网络的电压和频率。实验结果表明,该方案可以达到平均45%的能耗节省,而仅仅带来约5%的性能损失。相比于分布式控制方案,全局控制方案实现简单,软硬件代价低,对能耗的优化效果更加明显,在未来的片上多处理器设计中具有很高的实用价值。
[1]DALLY W J,TOWLES B.Principles and practices of interconnection networks[M].Morgan Kaufmann,2003.
[2]WANG H,PEH L S,MALIK S.Power-driven design of router micro-architectures in on-chip networks[C].In MICRO,2003:105-116.
[3]VANGAL S,HOWARD J,RUHI G,et al.An 80-tile 1.28TFLOPS network-on-chip in 65 nm CMOS[C].In Proc.Solid-State Circuits Conf.,2007:98-589.
[4]ABTS D,MARTY M R,WELLS P M,et al.Energy proportional data center networks[C].In ISCA,2010:338-347.
[5]ROTEM E,MENDELSON A,GINOSAR R,et al.Multiple clock and voltage domains for chip multi processors[C].In MICRO,2009:459-468.
[6]SHANG L,PEH L,JHA N K.Power-efficient interconnection networks:dynamic voltage scaling with links[J].IEEE Computer Architecture Letters,2002,1(1):6.
[7]MISHRA A K,DAS R,EACHEMPATI S,et al.A case for dynamic frequency tuning in on-chip networks[C].In MICRO,2009:292-303.
[8]GUANG L,NIGUSSIE E,RANTALA P,et al.Hierarchical agent monitoring design approach towards self-aware parallel systems-on-chip[J].ACM Trans.Embedd.Comput.Syst.,2010,9(3):1-25.
[9]CHEN X,XU Z,KIM H,et al.In-network monitoring and control policy for dvfs of cmp networks-on-chip and last level caches[C].In NOCS,2012:43-50.
