一种异构多核处理器启发式综合任务调度算法
2014-12-02李静梅韩启龙
李静梅,王 雪,韩启龙
(哈尔滨工程大学计算机科学与技术学院,哈尔滨 150001)
1 概述
多核处理器的产生为处理器性能的提升开辟了新的空间。如何将任务分配到具有不同计算性能的处理器内核上执行,从而获得最短的调度长度是影响异构多核处理器性能发挥的关键问题之一[1]。
任务调度问题是NP 完全问题,无法在多项式时间内获得最优解[2]。目前,应用最为普遍的任务调度算法为启发式任务调度算法,获得的是近似最优解[3]。启发式任务调度算法包括表调度算法、任务复制算法和聚簇算法[4]。单独应用一种启发式调度算法都存在适应面受限以及调度性能不高的缺点。所以,在实际应用中,往往在一个调度算法中结合多种启发式算法,借鉴各算法的优点,突破单一算法带来的性能瓶颈,提高调度效率。
基于以上研究背景,本文提出一种异构多核处理器(Multi-core Processor,CMP)启发式综合任务调度算法IHTSHMP(Integrated Heuristic Task Scheduling Algorithm for Heterogeneous Multi-core Processor)。该算法以表调度算法为基础,从任务调度全局出发,设定任务调度优先级,按照优先级构造任务调度列表。在调度过程中,利用任务复制技术进行调度优化。最后采用区间插入的方式将任务分配到处理器内核上执行,提高处理器利用率。
2 启发式任务调度算法分析
本文的研究成果是基于表调度算法和任务复制算法提出的一种改进的高效启发式综合任务调度算法。为更好地叙述本文的研究成果,现对表调度算法和任务复制算法进行分析,并着重分析其各自的优缺点。
2.1 表调度算法
通常将表调度算法的执行过程分为2 个部分:任务优先级排序和映射任务到目标处理器。首先依据优先级权值的大小将任务添加到任务调度列表中,其次根据设定调度规则依序将调度列表中的任务分配到相应的处理器内核上执行[5-6]。表调度算法是一种高效的启发式算法,具有算法实现简单、调度额外开销小和可预测性好等性能优势,在任务调度问题中应用广泛[7]。尽管表调度算法在性能提升方面有所裨益,但是优化过程缺乏针对性,单纯使用表调度技术很难得到理想的调度结果。表调度具体工作流程如图1 所示。

图1 表调度流程
2.2 任务复制算法
任务复制算法是指在任务调度过程中按照设定条件,将符合条件的任务冗余地复制到处理器内核上,减少核间依赖任务的通信时延[8]。任务复制技术可有效缩短任务整体的完成时间,在本质上是一种牺牲空间来换取时间收益的方法。任务复制的关键在于如何选择复制的任务。根据复制任务的个数,可以将任务复制算法分为单复制[9]和多复制[10]2 种,前者仅复制对当前任务开始时间影响最大的节点到处理器内核,后者复制多个符合条件的前驱任务。
在多核处理器系统中,利用任务复制将通信时延较大的核间开销转化为核内开销,缩短了任务执行长度。由于使用任务复制技术需要对任务前驱节点进行搜索和对节点信息进行存储,因此任务复制算法可能会增加调度算法的时间复杂性和空间复杂性,若使用不当会造成系统性能的下降。截至目前,任务复制算法虽然具有复杂性高的缺点,却因其在减少通信开销时间方面的贡献而被广泛应用于任务调度算法中。
3 IHTSHMP 算法
本文针对现有启发式任务调度算法存在的缺点与不足,提出一种异构CMP 启发式综合任务调度算法IHTSHMP。IHTSHMP 算法采用表调度为主要思想将任务调度分为优先级排序和任务分配2 个阶段。首先利用全局调度优化思想,设定优先级权值,并以此为依据构建任务执行列表。其次在任务分配阶段利用任务复制技术复制任务的关键前驱节点,并以区间插入式的分配方式将任务分配到处理器内核上执行,进一步优化任务调度效率。
3.1 调度模型
调度模型包括任务模型和处理器模型,假设任务数为N,处理器内核数为M。
(1)任务模型
为分析任务间的依赖关系,采用图论中的有向无环图(Directed Acyclic Graph,DAG)来表示任务的执行属性及依赖关系。
DAG 任务图G=(V,E,τ,c)为一个四元组。其中,V 为长度为N 的任务节点集合;元素ni表示集合中的第i 个元素,0≤i≤N -1;E 为任务图中有向边的集合,表示任务之间的依赖关系;τ 为任务执行时间的集合,元素τ(ni,pu)表示任务ni在内核pu上的执行时间,在DAG 任务图中表现为节点的权值;c 为依赖任务之间通信时延的集合,元素cij表示任务ni和nj之间的通信时延大小,在DAG 任务图中表现为有向边的权值。如图2 所示为一个具有10 个节点的DAG 任务图。
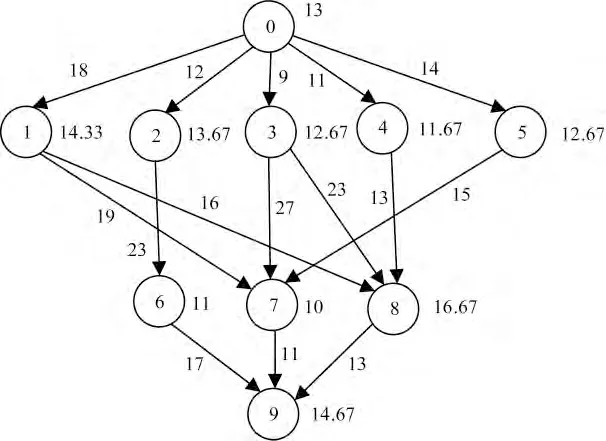
图2 具有10 个节点的DAG 任务图
在DAG 任务图中,对于任意任务ni都有直接前驱节点集合prep(ni)、关键前驱节点fprep(ni)、后继节点集合succ(ni)、在任意核pu上的最开始时间est(ni,pu)和最早完成时间eft(ni,pu)5 个重要属性。其中,est(ni,pu)和eft(ni,pu)的定义分别如式(1)、式(2)所示。在式(1)中,p_avail 为处理器内核可利用时间,即处理器可以接受并执行任务的开始时间。
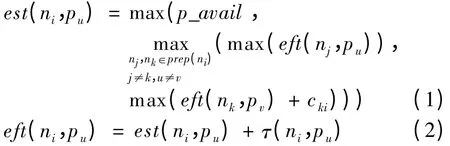
(2)处理器模型
本文的研究平台是异构多核处理器,假设处理器结构为片上全相连网状结构,任意2 个内核之间可以直接通信。定义处理器内核集合P,集合元素pu为第u 个内核,1≤u≤M。
3.2 优先级计算
关键路径是DAG 任务图的最长路径,是获得任务图最短调度长度的瓶颈所在,所以对关键任务的合理调度也显得尤为重要。IHTSHMP 算法首先在调度的各个环节都赋予关键路径节点最高优先级。此外,针对现有表调度算法中依据任务的局部信息定义任务优先级,致使后续的关键任务无法优先调度的问题,本文算法提出一种以优先级权值weighti定义任务优先级的方式。优先级权值的选取充分考虑到整个任务图拓扑结构,定义为任务在当前格局下向后关键路径的执行时间,并按权值降序排序任务优先级。优先级权值weighti的计算方式如式(3)所示:

其中,cp_value(ni)的定义如式(4)所示;ncp表示当前任务节点的直接后继关键路径节点。
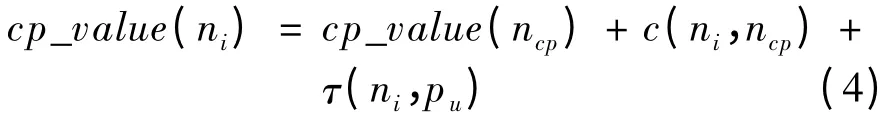
3.3 任务分配
为简化算法复杂度,选择任务完成时间最早的处理器内核为目标处理器内核。在此基础上,IHTSHMP 算法采用任务复制的分配思想和区间插入的分配方式对任务分配阶段进行优化。使用多复制的任务复制技术,循环判断任务是否满足复制条件。若复制关键前驱节点可以提早任务的最早开始时间,则复制其到处理器内核上,更新任务的关键前驱节点。判断不采用任务复制情况下的任务最早完成时间est(ni)和采用任务复制2 种情况下的任务最早完成时间est2(ni)。若est(ni)>est2(ni),则复制关键前驱节点到处理器内核。est2(ni)的计算方法如式(5)所示。
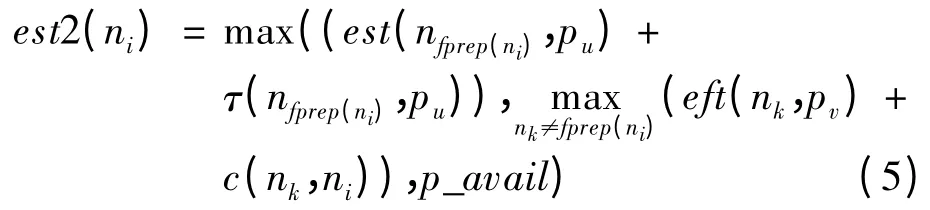
任务复制过程如图3 所示。区间插入是指在任务分配时,将任务分配到2 个已调度任务之间的处理器内核空闲时间段上。它是提高处理器利用率的有效手段。特别地,将处理器内核最后一个任务完成且可执行新任务的时间作为一个处理器空闲区间的开始时间,其结束时间为∞。

图3 任务复制过程
若满足式(6),则将任务分配到该空闲时间段上执行。

其中,Spaces和Spacee分别为处理器内核空闲时间段的开始时间和结束时间。
4 性能测试
将本文算法与基于关键前驱复制的CPFD(Critical Path Fast Duplication)算法[11]和选择性任务复制的表调度STDH(Selected Task Duplication for Heterogeneous System)算法[12]在同等条件下进行模拟实验。为进一步进行性能验证,本文引入调度长度比率(Schedule Length Ratio,SLR)和加速比speedup 作为算法性能评估参数。
(1)关键路径是DAG 任务图的最长路径,是任务调度长度的瓶颈所在。SLR 反映了任务图相对于关键路径的执行情况。SLR 的计算公式rSLR如式(7)所示。

其中,makespan 表示任务图的调度长度,即任务映射图中最后一个任务的完成时间;CP 为各关键路径节点在各处理器内核上平均执行开销之和。关键路径作为任务图中最长的一条执行路径,是整个任务调度长度的瓶颈所在,SLR 越小则证明任务调度算法的性能越好。
(2)加速比speedup 反映的是程序的并行化执行程度。定义为任务的串行执行时间与任务图实际调度长度的比值,加速比越大则证明算法并行化程度越高,调度性能越好。speedup 的计算方式如式(8)所示。
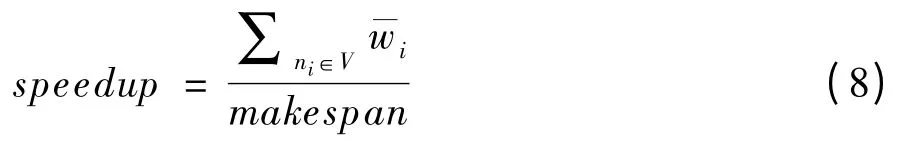
本文采用随机任务图作为测试用例,对算法性能进行验证。为控制产生任务图的形状和大小等属性,对任务图的参数取值范围进行设定。设定任务图中任务个数N={20,30,40,50,60,70,80,90,100};任务图中节点的最大出度α={1,2,5,10,100};任务图中任务的通信时间与执行时间比值参数CCR={0.1,0.5,1.0,5.0,10.0};任务在不同处理器内核上执行时间差异度参数β={0.1,0.5,1,1.5,2}。通过对以上参数的设定,产生1 125 组任务图类型。从每组类型中随机地选择10 个任务图,此时可以生成11 250 个任务图。对产生的11 250 个任务图在模拟平台上进行调度,评测算法性能。
将IHTSHMP 算法与已有CPFD 算法和STDH 算法分别在不同任务数和不同通信计算比率(Communication Computation Ratio,CCR)的情况下对3 种算法的speedup 和SLR 性能进行对比分析。得到算法在不同任务数情况下的平均speedup 和平均SLR 结果对比图,分别如图4 和图5 所示;不同CCR情况下的平均speedup 和平均SLR 结果对比图,分别如图6 和图7 所示。
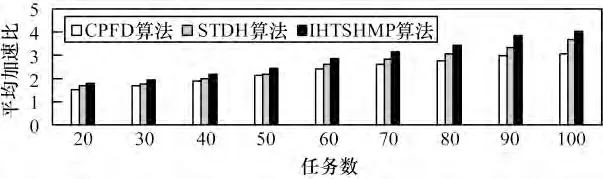
图4 不同任务数下的平均加速比对比

图5 不同任务数下的平均SLR 对比

图6 不同CCR 下的平均加速比对比
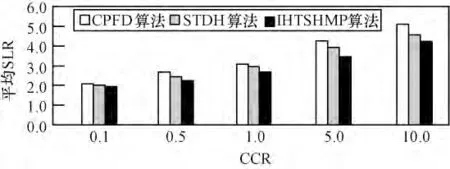
图7 不同CCR 下的平均SLR 对比
由图4 和图5 所示,在不同任务数的情况下,IHTSHMP 算法始终保持较高的调度性能,与CPFD 算法和STDH 算法相比,IHTSHMP 算法加速比speedup约分别提高17.20%和9.81%,调度下界比SLR 约分别降低15.40%和8.15%。由图6 和图7 所示,在不同CCR 下,IHTSHMP 算法性能较为平稳,与CPFD 算法和STDH 算法相比,加速比speedup 约分别提高16.35%和9.08%,调度下界比SLR 约分别降低14.53%和8.10%。由实验结果对比分析可知,IHTSHMP 算法有效优化任务调度性能。
5 结束语
本文提出一种异构CMP 架构下的启发式综合任务调度算法。该算法综合2 种启发式算法完成任务调度过程,克服了现有算法中存在的不足,提高调度效率,在优先级权值设定时,充分考虑任务拓扑图结构,提高了全局调度效率;在任务分配时,采取了对于减少依赖任务通信延迟有效的多任务复制技术和对于提升处理器利用率有效的区间插入方式,进一步优化调度。性能测试结果表明,本文算法能有效减少任务调度长度,充分发挥异构CMP 的优势。
[1]李静梅,张 博.基于混合粒子群优化的CMP 线程调度方法[J].计算机工程,2012,38(20):113-115.
[2]Ullman J D.NP-complete Scheduling Problem [J].Journal of Computer and System Sciences,1975,10(3):384-393.
[3]梁洪涛,袁由光,方 明.一种基于任务全局迁移的静态调度算法[J].计算机研究与发展,2006,43(5):797-804.
[4]Prashanth C,Ranga S.Algorithms for Task Scheduling in Heterogeneous Computing Environments [D].Alabama,USA:Auburn University,2006.
[5]Palmer A,Sinnen O.Scheduling Algorithm Based on Force Directed Clustering [C]//Proc.of the 9th International Conference on Parallel and Distributed Computing,Applications and Technologies.[S.l.]:IEEE Press,2008:311-318.
[6]邢建生,王永吉,刘军祥,等.一种静态最少优先级分配算法[J].软件学报,2007,18(7):1844-1854.
[7]Hwang R,Gen M,Katayama H.A Comparison of Multiprocessor Task Scheduling Algorithms with Communication Costs[J].Computer & Operations Research,2008,35(3):976-993.
[8]林剑柠,吴慧中,陈学勤.基于任务复制的网格任务调度算法[J].计算机科学,2006,33(6):89-92.
[9]何 琨,赵 勇,黄文奇.基于任务复制的分簇与调度算法[J].计算机学报,2008,31(5):733-740.
[10]Darbha S,Agrawal D P.Optimal Scheduling Algorithm for Distributed-memory Machines[J].IEEE Transactions on Parallel and Distributed Systems,1998,9(1):87-95.
[11]Ahmad I,Kwok Y K.On Exploiting Task Duplication in Parallel Program Scheduling[J].IEEE Transactions on Parallel and Distributed Systems,1998,9(9):872-877.
[12]孟宪福,刘伟伟.基于选择性复制前驱任务的DAG 调度算法[J].计算机辅助设计与图形学报,2010,22(6):1056-1062.
