基于列存储的MapReduce 并行连接算法
2014-12-02乐嘉锦
张 滨,乐嘉锦
(1.东华大学计算机科学与技术学院,上海 201620;2.浙江财经大学,杭州 310018)
1 概述
随着计算机技术和互联网的急速发展,特别是随着Web2.0 的发展,互联网上的数据量高速增长,现有技术对大数据的处理能力越来越无法胜任。伴随着待处理数据越来越多,当前已经不可能将大数据存储在一台或有限数目的服务器内,而且无法由数目有限的计算机来处理大数据的困境。因此,如何实现资源和计算能力的分布式共享以及如何应对当前数据量高速增长的势头,是目前数据管理、数据处理领域亟待解决的问题。
本文将大数据的特点描述为:大数据具有规模大、深度大、宽度大、处理时间短、硬件系统普通化、软件系统开源化特点。在MapReduce[1]分布式环境下,原有传统的关系运算,特别是数据的连接运算,在执行过程中产生大量的中间结果,从而导致大量的系统开销,执行效率低下。这已经成为影响大数据分析处理的瓶颈。
针对上述问题,本文提出一种基于列存储的MapReduce 并行连接算法,该算法在列存储系统中结合基于规则及基于代价的方式优化查询,给出一种MapReduce 平台上基于过滤器的多表连接算法,它能够同时对多个关系表进行连接,避免中间结果的产生,还能最大程度避免不必要的元组复制与数据传输。
2 相关工作
2.1 列存储技术
列存储[2]的概念可以追溯到20 世纪70 年代,早在1976 年,加拿大统计局开发实现了列存储数据库管理系统,并在80 年代广泛应用。这些系统对传统DBMS 底层存储进行修改,对关系表进行垂直分解,然而在查询初始时将查询涉及的列组装成行,使用面向行的查询执行引擎进行查询执行,其效率提高有限。随着企业对分析型查询需求的快速增长,对列存储的研究在近些年得到了快速提升。Monet DB[3]和C-Store[4]是其中有影响力的代表性成果。Monet DB 由荷兰国家数学和计算机科学研究院(CWI)研 究 开 发。C-Store 由 美 国 MIT,Yale,Brandeis 大学、Brown 大学以及UMass Boston 大学等多所大学联合研究开发,在存储结构、查询优化、压缩等各方面进行技术创新。
2.2 面向大数据处理的MapReduce 模型
2004 年,Google 研究员Dean J 和Ghemawat S 通过对网页数据存储和并行分析处理研究后,提出了MapReduce 计算模型,此后在ACM 等多个期刊上转载。MapReduce 计算模型为大数据分析处理问题的提供了一个新的有效解决方法和途径。
2008 年 底,Apache 的 Hadoop[5]项 目 作 为MapReduce 开源实现,迅速得到广泛关注和使用。Hadoop 的HDFS(Hadoop Distributed File System)是一种专门为MapReduce 设计的大数据分布式文件系统,处理大数据性能优越。
2.3 MapReduce 与数据库技术的结合
在并行数据库与MapReduce 模型相结合的理论研究方面,国外以耶鲁大学的研究团队在近3 年SIGMOD,VLDB 上发表了多篇关于在数据库领域的列存储的论文,2009 年、2011 年发表在VLDB 上的HadoopDB[6]研究为代表,在Hadoop 基础上提出了Hadapt[7]研究,它消除数据孤岛,在云环境中使用现有的SQL 工具,组织分析大量的“多层结构”数据。2011 年SIGMOD 上发表了新加坡国立大学和浙江大学研究的借助列存储技术实现MapReduce 框架下可扩展连接处理论文[8]。设计了Llama 这个在MapReduce 框架下的数据管理原型系统,在底层使用一个创新的文件存储格式:CFiles。2011 年VLDB上发表了威斯康星麦迪逊大学和IBM 研究员联合研发的基于列存储技术的MapReduce 框架论文[9],利用列存储技术对MapReduce 的改进,该论文阐述了列存储格式兼容Hadoop 复制和调度约束机制,证明列存储格式在实际工作负载条件下能加快MapReduce 任务处理速度;其次研究如何处理列存储遇到的复杂的数据类型。
在国内对于大数据分析应用以及MapReduce 与数据库技术相结合技术研究,相对起步较晚。文献[10]指出面对大数据深度分析的挑战,关系数据库技术的扩展性遇到了前所未有的困难。MapReduce 技术具有简洁的模型、良好的扩展性、容错性和并行性,高性能。关系数据库技术和MapReduce 技术相互竞争、相互学习和相互渗透,促进了数据分析新生态系统的浮现。文献[11]提出了基于MapReduce 的关系型数据仓库并行查询方法,并设计了基于MapReduce的分布式关系数据库:ChunkDB。
综上所述,当前列存储系统在MapReduce 的分布式环境下的并行连接方向的研究还较少,对聚集运算缺少深入分析,方法也很局限,本文提出基于列存储的MapReduce 环境下数据查询中的并行连接算法,该算法结合分片聚集和启发式规则对连接进行优化,提高数据处理效率。
3 基本定义与符号
列存储在MapReduce 分布式环境实现示意图如图1 所示。
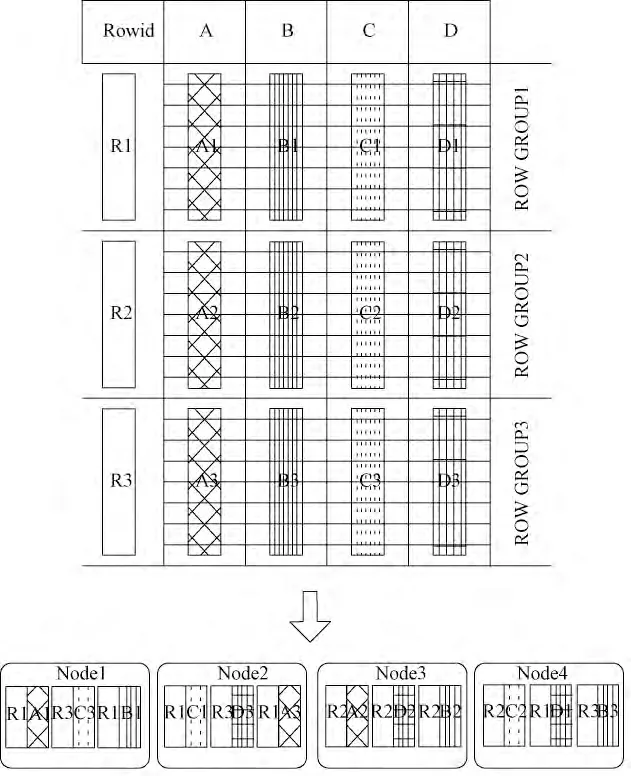
图1 列存储在MapReduce 分布式环境实现示意图
在MapReduce 并行计算环境下,列存储与行存储不同,其查询处理的操作对象,由原来的行或者行组,转变为分布式存储在每个节点上的列或水平划分后的列组,因此,查询执行投影操作转变为每个节点上的列的操作,效率很高。查询中的每个操作都相对独立,减少重复访问同表带来的I/O 浪费,这也为MapReduce 框架下查询的并行执行提供了必要条件。在行存储中,下推的目标对象是表,而在列存储中,下推的目标对象具体到某个列,每个列相当于一个由(rowid,value)组成的小表。在MapReduce 分布式环境下,小表又是分隔后存储在集群每台机器上。因此,在列存储的MapReduce 计算环境里,目标对象是分片小表。传统的集合运算包括并、交、差、广义笛卡尔积4 种运算。在此基础上,本文给出MapReduce 并行计算环境下,列存储系统的专门关系代数。
定义1 在基于列存储的MapReduce 并行环境下,设关系R 具有k 元属性A1,A2,…,Ak而属性Ai,i=1,2,…,k 分割后分布存储在m 个节点上,那么属性Ai 的分量就可以用Ai1,Ai2,…,Aim表示。即Ai的形式定义如下:
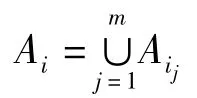
则关系R 的形式定义如下:

定义2(rowid) 为了重组列存储的行数据,每一列都要附加伪列rowid,形如(rowid,value)。
定义3 分布存储分量
设关系R 具有k 元属性,有n 个元组。将每列分量Ai,i=1,2,…,k;存在m 个节点上,则除去最后一个分量的元组数为t=n%m,其他每个分量的元组数都为t=n/m,其数据记为aji,j=1,2,…,t;令bj为aij对应的rowid 伪列,则这些切分后的数据分量的形式定义如下:
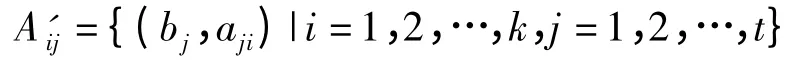
定义4 投影
由于是列存储,没有实际意义投影操作,只需把所有节点的列Ai1,Ai2,…,Aim并在一起就得到所需属性。

定义5 选择
属性Ai关于公式F 的选择操作的形式定义如下:
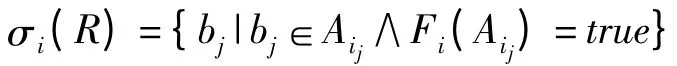
通过σi(R)可以得到满足公式F 对属性Ai的所有rowid。那么关系R 关于公式F 的选择操作形式定义为:

定义6 自然连接
设有2 个关系R 和S,R 和S 的公共属性是A1,A2,…,Ak,那么首先要把这些属性的分量组合起来,计算R×S,那么自然连接操作的定义为:

4 面向大数据的分布式计算模型
本节针对大数据分析处理,在MapReduce 分布式环境下,设计了基于列的分布式文件存储格式,数据的分布式加载以及利用协同定位方法对数据存储进行优化。
4.1 MCF 存储格式
针对MapReduce 分布式计算环境,本文在底层设计了一个新的文件存储格式MCF(MapReduce Column-store File),即基于MapReduce 的分布式列存储格式,其示意图如图2 所示。对于Facebook 设计的Hive[12]文件存储格式RCFile[13],它采用行存储,每个关系模式按照行组,存储在RCFile 中,而本文提出MCF 采用列存储,避免提取关系表中的无关属性,相对RCFile,其大数据查询效率提高明显。
在MCF 中,每一列都附加一个伪列rowid,每个块包含固定数量的记录,称为M 值。因为属性类型大小是可变的,每个逻辑块的多少n 不同。块存储在缓冲区。缓冲区的大小通常为1 MB。当缓冲区大小超出阈值或缓冲区中的记录数达到m 个,缓冲区刷新到HDFS 中。每块的起始偏移量被记录下来。使用MCPage 代表在文件系统的分区单位。在文献[15]中指出HDFS(Hadoop 分布式文件系统)中,每个输入的数据文件将切成块(HDFS Block),MCPage 存储在HDFS Block 中,从而MCPage 在不同的数据节点复制。在HDFS,默认MCPage 大小为64 MB。MCPage 包含多个数据块,由记录m 的值和每个记录的大小确定。
MCF 在表扫描通过避免没必要列值读取来优化读取,它在分布式集群环境下优于按行存储结构。同时,MCF 是基于列存储的压缩,因此,有很高的空间利用率。
4.2 数据分布式加载
本文提出按照MCF 文件格式,将数据通过分片方法构造分布存储分量A'ij,从而分别导入到每个MCPage 的数据块中。
在HDFS 中默认splitSize 等于HDFS blockSize的默认值(64 MB)。而InputSplit 是MapReduce 对文件进行处理和运算的输入单位,只是一个逻辑概念,每个InputSplit 并没有对文件实际的切割,只是记录了要处理的数据的位置和长度。
如果按照默认的顺序数据加载方法,必然存在一行记录被划分到不同的Block,甚至不同的DataNode。根据定义3,通过分析FileInputFormat 里面的getSplits 方法,某一行记录同样也可能被划分到不同的InputSplit。对输入的文档进行预处理,读取前N 行做为一个splits,通过重写FileSplit,定义一个split 的大小是1 KB 个字节,这样就可以将输入的文档进行分片。最终实现A'ij的构造。
4.3 协同定位优化策略
本文提出数据存储的协同定位策略,其示意图如图3 所示。对于那些数据量非常庞大的事实表,如lineorder 表,往往跨越许多的HDFS 块,通常在每个节点上分割存储,不做复制,而对于数据量相对较小的维表,如supplier,customer,part,date 表,协同定位优化策略将其在每个节点都复制一份,使得可以分布连接和聚集运算直接在本机运算即可,因此,大大减少了节点之间网络传送次数和时间,提高了4.1 节分布聚集效率,查询性能优化明显。

图3 协同定位优化策略示意图
5 基于列存储的MapReduce 并行连接算法
本节对与基于列存储的MapReduce 并行连接算法从分片聚集和子连接的启发式优化2 个方面,阐述了算法的具体实现。
5.1 分片聚集方法
基于列存储的MapReduce 并行连接算法,其示意图如图4 所示。为了充分调用集群所有机器的计算资源,实现数据的并行连接,在查询计划执行的Map 阶段,本文提出分片聚集方法。
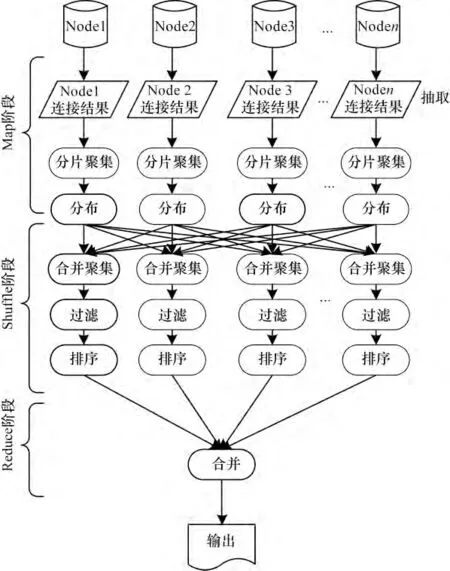
图4 并行连接查询计划示意图
(1)抽取:按照定义6 并行连接操作,在集群中的多个机器上分别执行完之后,得到子连接结果,传给分片聚集阶段。
(2)分片聚集:在这个阶段,对每个子连接结果计算聚集。从而利用分片方法来减少数据量。提高并行计算能力。而且在多查询任务时,分片聚集结果还可以重用。
(3)分布:对前阶段的结果,按照查询语句的分组条件,被重分配到各个分组中。这使所有具有相同的查询字符串的结果分配到到同一个Map 任务。从而完成GROUP BY 字句要求的对查询结果进行分组实现。
(4)全聚集:每个分区即每个Map 任务,通过合并计算具有相同的查询字符串的查询结果,从而得到最终聚集结果。例如:得到count (*)结果。
(5)过滤:通过过滤掉HAVING 字句中的组条件,例如:count(*)>50,计数小于50 的将不会传入Reduce 阶段。
(6)排序:调用hadoop 的排序算法,本文使用TeraSort 算法,对剩余的结果按照ORDER BY 字句的要求分别并行排序。
(7)合并:每个Reducer 进行合并操作对所有分区排序的结果的合并在一起,输出最终结果。
(8)输出:最终的结果是输出为MCF 文件。
5.2 子连接的启发式优化方法
在并行连接过程中,对于每个节点本地执行的连接任务,本文利用前期研究成果[14]:启发式优先方法对关系运算进行优化。
本文启发式优化的基本思想是:首先执行最具限制性的选择和连接操作。具体优化策略为:尽可能早地执行选择操作;尽可能早地执行投影操作;同列谓词的下推能尽早减少所需处理的元组数目。而由于同表列的rowid 唯一且一致,优先执行同表列的连接能有效减少中间结果的规模,因此Map 阶段产生的中间结果之和较小的计划一般是最优的。基于启发式优化的查询计划示意图如图5 所示。

图5 基于启发式优化的查询计划示意图
6 实验验证
本文实验采用课题组开发的基于列存储的MapReduce 大数据并行处理原型系统 HCMS(Hadoop Column-store Management System)为算法测试平台,采用国际通用的SSB 测试数据集,对算法进行测试,从而验证其高效性和可扩展性。
6.1 实验环境
本文系统验证要求与原有单机环境不同,对计算机数量有更高要求。实验系统运行在课题组实验室选取的50 台普通计算机组成测试集群,每个节点:4 核CPU,4 GB 主存,1 块500 GB SATA 硬盘,每台机器的操作系统都是Redhat Linux 6.1。网络环境为1 GB 以太网交换机组成的局域网。本文实验使用的软件,如表1 所示。其中,DBMS3.0 为课题组前期列存储数据库研究成果。

表1 实验软件环境
实验规划每个Datanode 分配6 个map 任务和2 个reducer 任务。HDFS 数据块大小设置为256 MB,MapReduce 查询执行器使用全局内存大小设置为1 GB。
测试节点从10 个节点开始增加到50 个,记录每个测试数据集合和测试查询语句执行时间和日志。每次测试完后,需要对集群HDFS 重新格式化。
6.2 测试数据集
实验采用国际通用的星型模式基准SSB[15]中定义的测试数据集进行大数据处理的实验验证,生成的星型模式下的真实数据集和基于MapReduce 的大数据并行处理原型系统考虑的大数据测试目标相吻合。
实验将用SSB 提供的数据产生器DBgen 生成了SSB 的数据集实例。每个实例数据集的大小是用增量因子控制的,记为SF,选用SF=1,数据集大小为1 GB,初始lineorder 表数据量为6 000 000 行,如表2 所示。实验逐步增加SF,生成数据集从10 GB,100 GB 到1 TB。分别记录每次测试结果。

表2 实验测试数据
6.3 实验结果与分析
实验1 各个测试语句性能对比
选取SSB 的连接语句测试Q1.1,简单聚集任务测试Q2.1 以及复杂聚集任务测试Q3.1 和Q4.1 作为基础测试语句,在全部节点都启用的条件下,通过对100 GB 数据分别测试10 次,计算平均值,其结果如图6 所示。
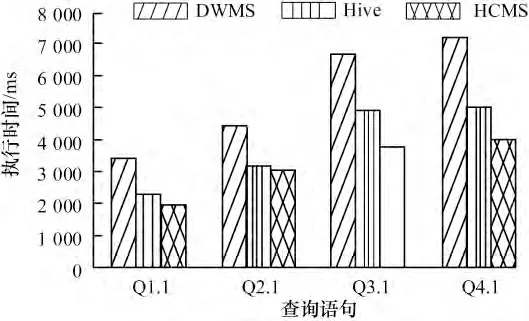
图6 各个测试语句性能对比图
由于采用了分片聚集算法,在聚集任务Q3.1 和Q4.1,特别是复杂聚集任务,本文算法优化明显。
实验2 数据量变化下性能对比
选取SSB 的Q2.2 作为基础测试语句,在全部节点都启用的条件下,通过对10 GB,100 GB 和1 TB数据分别测试10 次,计算平均值,其性能对比图如图7所示。测试系统,在大数据条件下的运行负载能力。从图7 中可看出,当数据量增加时,DWMS 执行时间增长明显,而Hive 和HCMS 则较平缓,充分验证了并行执行的优越性。当负载增大到1 TB 时,HCMS性能比Hive 提高26.2%,由此充分验证了同时使用MCF 列存储结构和分片聚集能更大提升并行连接的有效性,使得查询效率更高。
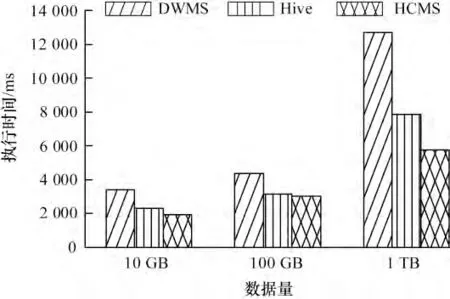
图7 数据量变化下性能对比
实验3 集群数量变化下性能对比
选取SSB 的Q2.2 作为基础测试语句,选择100 GB数据,通过对集群Datanode 节点数从10 个、20 个、30 个、40 个,增加到50 个,重新格式化后,分别测试10 次,计算平均值,其性能对比如图8 所示。列存储数据仓库管理系统DWMS 不是并行分布式系统,本次测试实验中未使用。

图8 集群数量变化下性能对比
由图8 可以看出,随着运算节点数目的增加,HCMS 比Hive 执行时间不断减少,从10 个节点的相差15.8%,减少到50 个节点的26.3%。从而验证了算法性能优化明显。另一方面也证实了算法的可扩展性。
7 结束语
基于列存储的MapReduce 并行连接算法分析了MapReduce 并行环境列存储连接与单机环境列存储的区别,根据面向大数据的分布式计算模型“大而化小,分而治之”的设计思路,从而为大数据查询分析处理提供了有效的解决方案。本文算法在面向大数据的分布式计算模型基础上,利用协同定位实现存储优化。从分片聚集和子连接启发式优化2 个方面构造了并行连接算法的具体实现。实验结果证明,该算法有效地减少了MapReduce 过程的中间数据和不必要的I/O 开销。此外,由于利用了模型的可扩展性特点,无论在执行时间还是负载能力上,都有较好的性能表现,明显提高了大数据运算的效率。下一步的工作重点将转向列存储的MapReduce 连接索引技术的研究,对适用于列存储的MapReduce 各种索引进行分析,使MapReduce 大数据查询性能得到进一步的优化。
[1]Dean J,Ghemawat S.MapReduce:Simplified Data Processing on Large Clusters[C]//Proc.of OSDI'04.San Francisco:[s.n.],2004:137-150.
[2]Abadi D J,Madden S R,Hachem N.Column-stores vs.Row-stores:How Different Are They Really?[C]//Proc.of ACM SIGMOD'08.Vancouver,Canada:ACM Press,2008:967-980.
[3]Stonebraker M,Abadi D J,Batkin A,et al.C-store:A Column-oriented DBMS [C]//Proc.of VLDB Conference.Trondheim,Norway:[s.n.],2005:553-564.
[4]Boncz P,Zukowski M,Nes N.MonetDB/X100:Hyperpipelining Query Execution[C]//Proc.of CIDR'05.Asilomar,USA:ACM Press,2005:251-264.
[5]Blanas S,Patel J M,Ercegovac V,et al.A Comparison of Join Algorithms for Log Processing in MapReduce[C]//Proc.of ACM SIGMOD International Conference on Management of Data.Indianapolis,USA:ACM Press,2010:975-986.
[6]Abouzeid A,Bajda-Pawlikowski K,Abadi D J,et al.HadoopDB:An Architectural Hybrid of MapReduce and DBMS Technologies for Analytical Workloads[C]//Proc.of VLDB Conference.Lyon,France:[s.n.],2009:922-933.
[7]Bajda-Pawlikowski K,Abadi D J,Silberschatz A,et al.Efficient Processing of Data Warehousing Queries[C]//Proc.of ACM SIGMOD International Conference on Management of Data.Athens,Greece:ACM Press,2011:1165-1176.
[8]Lin Yuting,Agrawal D,Chen Chun,et al.Llama:Leveraging Columnar Storage for Scalable Join Processing in the MapReduce Framework[C]//Proc.of ACM SIGMOD International Conference on Management of Data.Athens,Greece:ACM Press,2011:961-972.
[9]Floratou A,Patel J M,Shekita E J.Column-oriented Storage Techniques for MapReduce.The VLDB Journal,2011,4(7):419-429.
[10]覃雄派,王会举,杜小勇,等.大数据分析——RDBMS与MapReduce 的竞争与共生[J].软件学报,2012,23(1):32-45.
[11]师金钢,鲍玉斌,冷芳玲,等.基于MapReduce 的关系型数据仓库并行查询[J].东北大学学报:自然科学版,2011,32(5):626-629.
[12]Thusoo A,Sarma J S,Jain N,et al.Hive——A Warehousing Solution over a Map-reduce Framework[C]//Proc.of VLDB Conference.Lyon,France:[s.n.],2009:1626-1629.
[13]He Yongqiang,Lee R,Yin Huai,et al.RCFile:A Fast and Space-efficient Data Placement Structure in MapReducebased Warehouse Systems[C]//Proc.of International Conference on Data Engineering.Hannover,Germany:IEEE Press,2011:1199-1208.
[14]严秋玲,孙 莉,王 梅,等.列存储数据仓库中启发式查询优化机制[J].计算机学报,2011,10(34):2018-2026.
[15]O'Neil P,O' Neil B,Chen Xuedong.Star Schema Benchmark Revision3[EB/OL].(2010-02-09).http://www.cs.umb.edu/~poneil.
