基于相似图片聚类的Web 文本特征算法
2014-12-02殷俊杰徐武平
方 爽,殷俊杰,徐武平
(武汉大学计算机学院,武汉 430072)
1 概述
随着互联网信息爆炸式的增长,由于图片在表达能力上相对于文字拥有的先天优势,已经被越来越多应用于信息的承载和内容的表达[1],各大搜索引擎公司如Google,Yahoo 和百度等都推出了图片搜索功能。
传统图像检索方式分为2 种:一种是基于文本的图像检索(Text-based Image Retrieval,TBIR),如文献[2-3]所述;另一种是基于内容的图像检索(Content-based Image Retrieval,CBIR),如文献[4]所述。因为前者技术比较成熟,所以目前主流搜索引擎均采用基于文本关键词的图像搜索技术。其在假设网页图片周边的文本可以表达图片本身内容的基础上,从Web 网页的相关文本中提取图像的关键信息,建立文本索引数据库,用户利用关键词进行检索[5]。然而当网页存在作弊、文本描述图片有偏差或页面分析对文本提取错误的情况下,都会出现图片和索引文本项不符的问题,其产生的根本原因是在倒排索引中某些关键词对应的图片链表中包含了实际与关键词没有相关性的图片,并最终反映到搜索结果当中。为解决上述问题,文献[6]提出了一种融合文本图像相关性关联的Web 图像多超图谱聚类方法,文献[7]提出了将基于文本的图像检索和基于内容的图像检索相结合的方法,文献[8-9]提出了2 种不同的图像检索结果重排序的方法。本文提出一种基于相似图片聚类的Web 文本特征算法,以解决图片和索引文本项不符的问题。
2 网页聚类信息的抓取
百度和谷歌等搜索引擎的网络爬虫已经在互联网上收集了数十亿张图片,并以图片内容相似性作了聚类,同一聚簇中的图片有相似的内容,每张图片对应一个来源网页。通过百度的以图搜图功能,在用户输入一张图片得到相似图片结果后,修改当前结果页面链接的URL 参数tn=baiduimagepc 为tn=baiduimagejson,即可得到一页检索结果的json 格式数据。通过分析结果页面的json 格式数据可以得到本聚类的大小(imgNum),聚类中每张图片的链接地址(objURLEnc),每张图片对应的来源网页的链接地址(fromURLEnc),每个来源网页的主站链接地址(fromURLHost)等聚类信息。
3 Web 文本特征分析
在获取聚类信息中的来源网页集地址(fromURLEnc)后,便可以对其中每个网页进行链接分析和HTML 标签解析,网页主视觉区域识别、词素切分、词性标注、停用词去除等Web 结构分析和Web 内容分析。
3.1 链接分析
在互联网上,如果一个网页被很多其他网页所链接,说明它受到普遍的承认和信赖,其质量是有保证的(一般有专业的编辑,并且在网页发布前需要经过严格审核),文中把这样的网页看作“高质量”网页。而那些出现图文不符情况的网页,一般是故意作弊或者编辑水平较低,责任心不强的网页,其受到承认和信赖的可能性较小,文中称其为“低质量”网页。
PageRank 算法[10]是Google 用来标识网页质量的一种方法,并且Google 对外提供的API 可以通过输入网页URL 查询其PageRank值,本文直接引用了Google 的PageRank值来评价网页的质量。对来自同一聚类中高质量网页(高PageRank值)的特征文本提高其权重,对于来自低质量网页(低PageRank值)的特征文本降低其权重,以使得存在图文不符的网页对最终的特征文本贡献度很小,并且倾向于相信高质量网页中挖掘出的特征文本,一般对最终的结果有正向影响。
3.2 结构分析
在网页中,不同HTML 标签中的文本其权重是不同的。例如,文章标题标签中的文本比正文更重要。为了区别不同HTML 标签中文本的权重,经过HTML 解析后,本文将各HTML 标签归为以下类型:(1)页面标题(title,显示在Web 浏览器顶端的标题);(2)文章标题(主视觉域中的标题);(3)图片替换文本(Alt);(4)导航位置(当前网页所处的站点路径,例如:首页>学院新闻>教务);(5)网页关键词(meta keywords 标签);(6)精确相关文本(网页主视觉域中正文文本);(7)疑似精确相关文本(网页主视觉域中非正文文本);(8)普通相关文本(非主视觉域中文本)。
网页主视觉域的识别根据浏览器提供的API 接口确定,本文采用文献[11]方法抽取网页的正文文本。最后赋予每种不同类型HTML 标签中文本不同的权重,即可区分重要信息和一般信息。
3.3 文本分析
完成HTML 解析后,便可对每个标签中的文本作词素切分和词性标注,根据不同的粒度,切分结果有所不同。例如“中华人民共和国”,基本词切分结果为:“中华”,“人民”,“共和”,“国”;短语切分结果为:“中华人民共和国”,“中华人民”,“人民共和国”,“共和国”。
基本词切分结果由于切分粒度太细,分析出的高相关文本一般是出现频率很高但是没有区分度的词,往往不能反映图片的真实文本。例如,在图片内容为小提琴的网页中,“小提琴”这个词在基本词切分中会被切分为“小”和“提琴”。由于“小”是个高频词,最后很可能被识别为高相关文本,但是实际却与图片相关性很低。根据实验对比,取混排结果(由有序的基本词和短语构成)和短语结果的并集效果比较好。
词性标注模块可以对词素切分后的每个基本词或短语单元标注其在句子中的词性。在汉语中,名词、动词、形容词组成句子的主干,副词、数词、代词等所代表的意义并不大,助词、连词、代词、介词、拟声词等虚词只起修饰作用[12],因此,根据词性筛选词语是必要的。在实验中,对词性为语素字、数词、介词、前接成分、后接成分、连词、区别词、量词、代词、叹词、拟声词、习用语、标点符号、非语素字以及英文字符串进行了过滤。本文将词素切分后的结果标注为下列词性之一:形语素(形容词性语素),形容词,副形词(直接作状语的形容词),名形词(具有名词功能的形容词),区别词,连词,副语素(副词性语素),副词,叹词,方位词,语素(绝大多数语素都能作为合成词的“词根”),前接成分,成语,简称略语,后接成分,习用语,数词,名语素(名词性语素),名词,人名,地名,机构团体,外文专名(一般是全角英文专名),其他专名,拟声词,介词,量词,代词,处所词,时语素(时间词性语素),时间词,助词,动语素(动词性语素),动词,副动词(直接作状语的动词),名动词(指具有名词功能的动词),标点符号,非语素字(非语素字只是一个符号),语气词,状态词。
通过赋予每种词性不同的权值,例如给予名词、人名等较高的权重,代词、副词等较低的权值,就能够很好地反映语句的主干,提高文本挖掘的相关性。
停用词的去除比较简单,可以配一个停用词表,对于出现在其中的词或者某些特定词性的词,例如连词、介词、冠词,直接在切词后的结果中删除即可。
4 特征文本的权值计算
对同一聚类中的网页进行分词,然后对分词后的每个keyword 计算权值,再根据事先设定好的阈值或者排名的百分比,把keyword 分为高相关文本、一般相关文本以及不相关文本。
每个keyword 权值的计算主要参考以下方面:
(1)网页的PageRank值,PageRank值高的网页出现图文不符的概率很小,这类网页通常可信度更高,图文相关性更好。
(2)词频(删除停用词后),对于同一聚类出现频率较低的文本可能来自于少数低质量页面,与图片相关性不高。
(3)keyword 出现的HTML 标签,同一keyword出现在图片替换文本Alt 中一般比出现在正文中更重要。
(4)keyword 在句子中的词性,一般名词、形容词在句子中比较重要权值比介词、代词等高。
(5)keyword 所在网页的长度,网页长度越长keyword 可能获得的权重就越大,所以,keyword 的权值应该在某种程度上受到网页长度的影响。
(6)keyword 是否在主内容块中,一般商业页面常带有导航条和广告等与主题无关的内容,而主内容块才是与图片较为相关的部分,可给主内容块中出现的文本更高的权值。
对整个网页集中每个keyword 权值的具体算法如下:
本文从Google 公开的API 接口查询聚类对应的每个网页的PageRank值。PageRank的取值范围是0~10。对于Google 未收录而导致查询不到PageRank值的网页,这类网页一般比较新,可能是刚刚发布的新闻类网页,对于这种情况文中采用一种简单有效的方法,取其PageRank值为整个站点PageRank的平均值。Google 未收录的原因也可能是这个网页不太流行(其质量也通常不高),对于这种情况默认其PageRank为0。
记网页j的PageRank值为PageRank(j),由于PageRank(j)的取值范围是0~10,因此,有必要对其归一化,经过实验对比,本文采用表1 的映射关系将PageRank(j)归一化为P(j)。
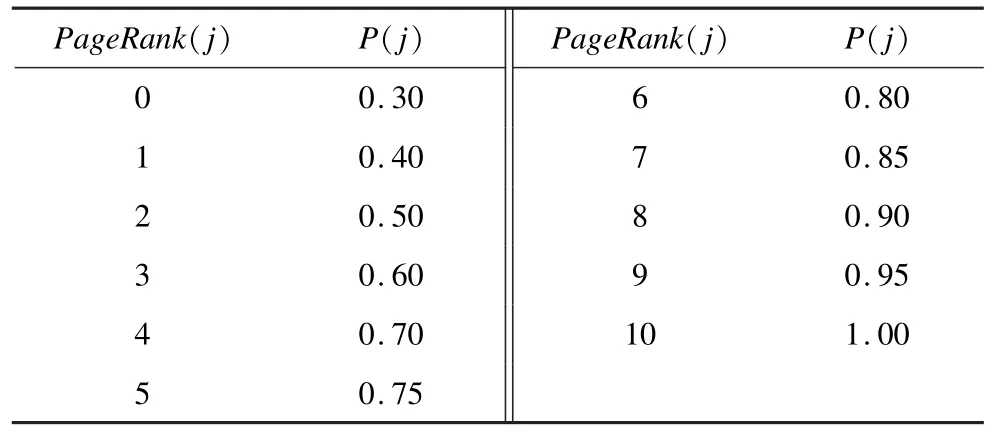
表1 PageRank 值与网页质量权重系数的映射
经过HTML 解析和词素切分后,文中将每个关键词i根据其来源的HTML 标签,赋予不同的权重,记为T(i),通过多组实验对比,算法中采用的HTML标签权重系数如表2 所示。

表2 HTML 标签的权重系数
同样在句子中不同语法成分对于句子意思表达的作用也是不同的,对切词后的每个词素单元i根据其不同的词性赋予不同的词性权重系数,记为S(i)。所以,关键词i在特定网页中的每次出现,其权值Wkw(i)计算公式为:

其中,α+β=1。通过上式,可以获得每个关键词在网页中每次出现的权值。假设关键词i在网页j中出现了n次,每次出现的权值分别为Wkw(i),那么其总的权值W′kw(i)计算公式为:
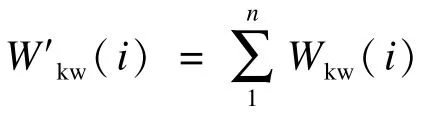
对于一个网页,应用上式对每个关键词进行权值计算是合理的。但是,考虑到相同的关键词可以出现在不同的网页中,而不同的网页长度不同,对于越长的网页关键词可能获得的权值也就越高。所以,一个关键词的权值在某种程度上受到网页长度的影响,文中用下面的公式表示网页长度对于关键词权值的影响:
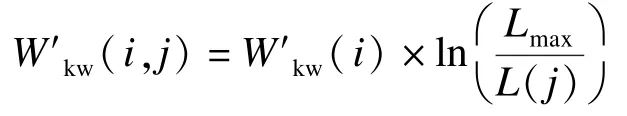
其中,W′kw(i,j)表示处理后的网页j中关键词i的权值;Lmax表示可索引最大网页的文本长度;L(j)表示当前网页j的可索引文本长度。对其归一化处理:

其中,W′kwmax(i,j)为当前网页j中关键词i总权值的最大值。
结合PageRank值可以进一步得到一个关键词在一张网页中获得最终的权值Wweb(i,j),其由基本权值Wkw(i,j)和链接权值P(j)按一定的比例重新构成:
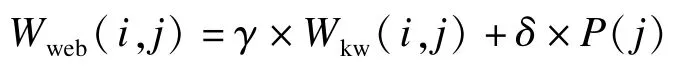
上式中2 种因素都起到了影响关键词权值的作用,同时又把各自的影响限定到一定的范围内,其系数γ+δ=1,本文取γ=0.7。
假设聚类k中有m张相似图片,即有m张对应的网页,对每张网页计算上式就可以求得一个关键词i在本聚类中的权值:

计算出一个聚类中所有关键词的权值,并归一化处理可得:

其中,W′clustermax(i)为本聚类中最大的关键词权值。这样就可以根据一定的阈值或者权值的百分比排名来划分高相关文本,一般相关文本以及低相关文本。
5 实验结果与分析
本文随机选取了15 个图片聚类,图片内容包含娱乐明星、电影海报、政治人物、动物、建筑、风景、数码产品、运动、游戏、热点事件、乐器。设定高相关文本的权重阈值为0.8,一般相关文本的权重阈值为0.4,权重低于0.4 的为低相关文本。表3 和表4 分别给出了百度、谷歌和本文算法得到的高相关文本和关键词权值计算结果。
通过对比图片内容的人工评估以及对比百度识图文本猜测和谷歌文本猜测可以看出,本文提出的基于相似图片聚类的Web 文本特征计算算法的结果是令人满意的。其中15 个图片聚类中百度搜索结果出现图文不符的有3 项,分别是第2 项、第3 项、第14 项;谷歌搜索结果中图文不符的有2 项,分别是第4 项和第11 项,而且第13 项结果也不准确,并且谷歌搜索部分结果中如第8 项、第10 项、第13 项给出的中文形式最相关文本词语内部有分隔符,容易使表达结果出现歧义,如第10 项结果中倩女和幽魂与第12 项的桂纶镁和线人意义是完全不一样的,前者只能作为一个完整词语才有意义,而后者是2 个毫不相关的词语。本文算法中只有一个聚类(序号5)的高相关文本分析结果不是很理想,人工评估这种图片的内容是“战斗机”或者“AC-130”等,但是算法计算出的高相关文本却是“壁纸”。造成这种情况的原因是由于大量引用这张图片的网页出现“壁纸”关键词导致其权重很高。对于这种情况,可以对高频出现,但是没有区分度的关键词降低权重。对于这个聚类,权值大于0.2的相关文本见表5。
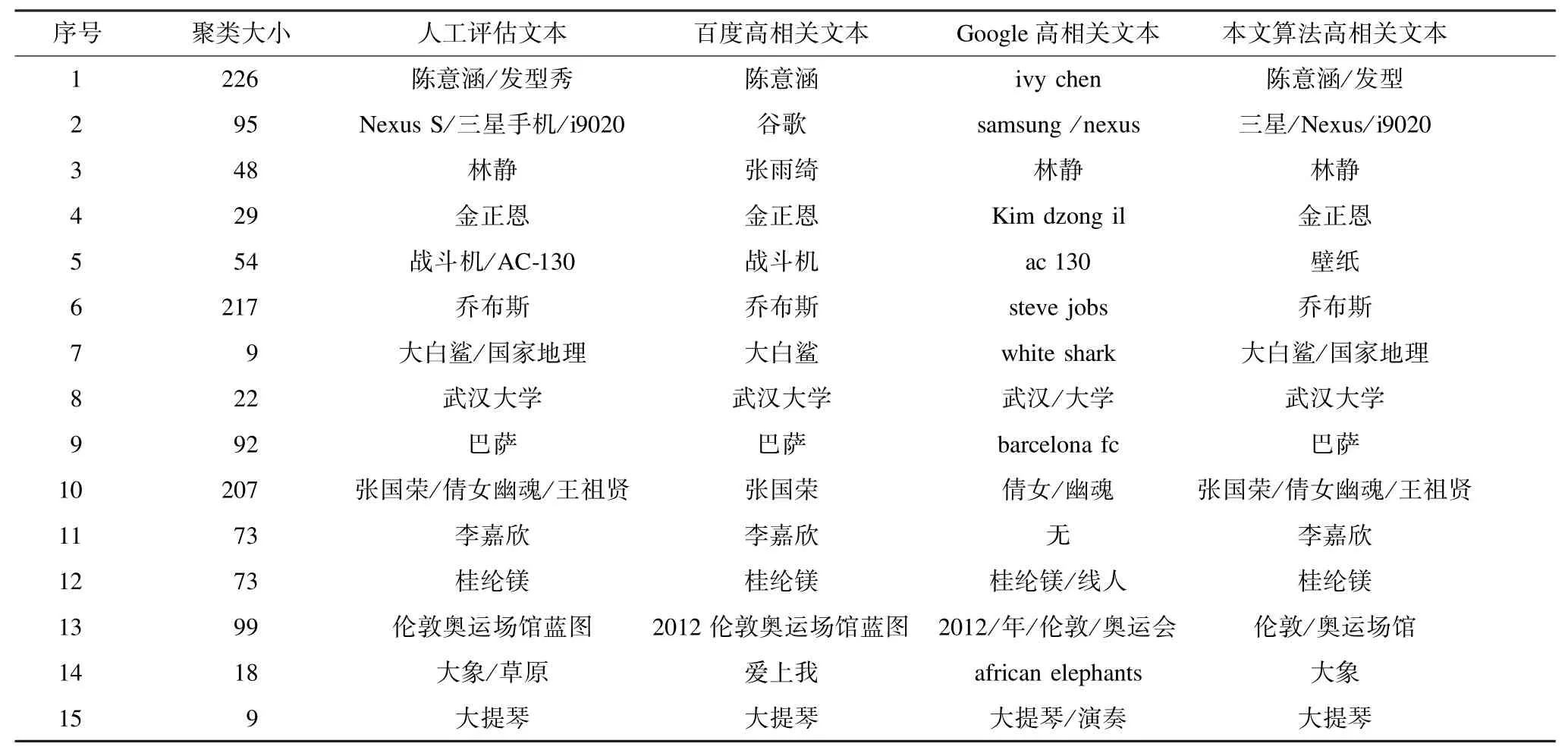
表3 随机选取15 个聚类的文本分析结果
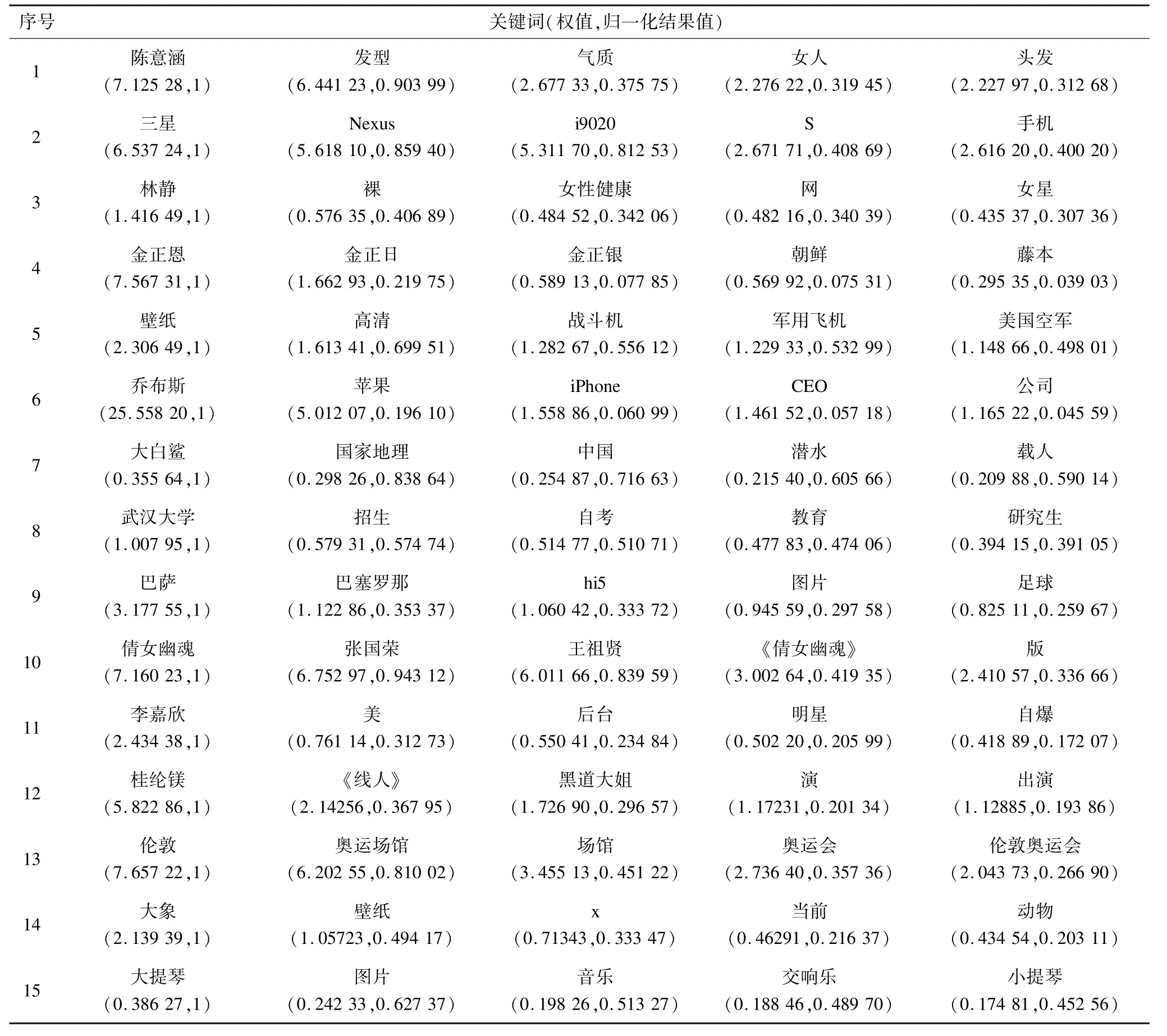
表4 每个聚类前5 位关键词权值及归一化结果

表5 聚类权值
6 结束语
本文给出解决现有图片搜索引擎中图文不符问题的新思路,在现有文本特征分析方法的基础上,提出了一种基于相似图片聚类的Web 文本特征算法。实验结果表明,该算法能够有效提高图片搜索结果的相关性。同时通过在建立倒排索引的过程中提高高相关文本的权重,降低低相关文本的权重,不仅可以进一步提高图片搜索质量,还可以给出以图搜图功能的文本提示,即猜测用户输入图片的内容。下一步工作是针对不同类型网页在内容组织上的差异,将网页类型因素加入到特征文本分析过程中,通过建立不同的HTML 标签权重解析模型,进一步提升特征文本分析的准确性。
[1]吴 昆.基于视觉特征的垂直搜索研究[D].武汉:华中科技大学,2009.
[2]谢 同.基于文本的Web 图片搜索引擎的研究与实现[D].成都:电子科技大学,2007.
[3]谢东升.基于文本的图片搜索引擎的研究[D].上海:同济大学,2007.
[4]邵 刚.基于内容的图像检索技术研究与系统实现[D].大连:大连理工大学,2005.
[5]郭 军.Web 搜索[M].北京:高等教育出版社,2009.
[6]Wu Fei,Han Yahong,Zhuang Yueting.Multiple Hypergraph Clustering of Web Images by Mining Word2Image Correlations [J].Journal of Computer Science and Technology,2010,25(4):750-760.
[7]Zhang Xiaoming,Li Zhoujun,Chao Wenhan,et al.Improving Image Tags by Exploiting Web Search Results[J].Multimedia Tools and Applications,2013,62(3):601-631.
[8]Duan Lixin,Li Wen,Tsang I W H.et al.Improving Web Image Search by Bag-based Reranking [ J].IEEE Transactions on Image Processing,2011,20(11):3280-3290.
[9]Yang Linjun,Hua Xiansheng.Prototype-based Image Search Reranking[J].IEEE Transactions on Multimedia,2012,14(3):871-882.
[10]Brin S,Page L.The Anatomy of a Large-scale Hypertextual Web Search Engine[J].Computer Networks and ISDN Systems,1998,30(1-7):107-117.
[11]王志琪,王永成.HTML 文件的文本信息预处理技术[J].计算机工程,2006,32(5):46-48.
[12]石春刚.中文文本聚类中的特征提取[D].天津:南开大学,2006.
