融合标签传播和信任扩散的个性化推荐方法
2014-12-02陈博文刘功申张浩霖郭弘毅
陈博文,刘功申,张浩霖,郭弘毅
(上海交通大学信息安全工程学院,上海 200240)
1 概述
近年来,互联网与信息技术高速发展,人们逐渐地从曾经信息匮乏的时代步入到了信息过载的时代[1]。在这个时代,对于信息消费者而言,从无数信息中寻找自己感兴趣的内容并非易事;同时对于信息生产者,让自己生产的信息从无数信息中脱颖而出被人注意同样是件困难的事情。而推荐系统则是实现信息消费者和信息生产者双赢的重要工具。目前,推荐系统已渗透到互联网的各种领域,电子商务网站(如卓越网的图书销售)、音乐网站(如豆瓣电台的歌曲推荐)、社区平台(如新浪微博的热门微博推荐)等都不同程度上使用了推荐系统。
基于内容的推荐和协同过滤推荐是如今使用最为广泛的推荐算法[2]之一。与基于内容的推荐不同,协同过滤无需计算物品特征描述或者用户记录的相似度,取而代之的是寻找与用户相似的用户群[3],然后经由这些用户预测此用户可能喜欢的物品。传统的协同过滤算法面临着用户-项目评分数据稀疏的问题,如果用户之间共同评分的项目很少,那么往往无法得到令人满意的推荐。
目前人们使用网络的方式已然发生了显著变化,互联网用户扮演起越发活跃的角色,不仅会向其他人展示自己的偏好,而且还会和志同道合且值得信任的用户建立信任联系。在庞大而复杂的网络中,一群个体相互之间类似,而与网络中其他个体不相似,则这些个体能构成一个社区[4]。美国著名的尼尔森调查机构调查了影响用户相信某个推荐的因素,结果显示,90% 的用户相信朋友对他们的推荐[5]。而由信任网络得到的推荐可以很好地模拟现实社会,因此,信任网络也可以在推荐算法中扮演重要角色,传统协同过滤算法中的用户间的相似度可以被信任网络中用户间的信任度替代。然而,由于用户数目的庞大,用户间的信任数据也不可避免地面临着数据稀疏的问题。
针对上述问题,本文提出一种融合标签传播和信任扩散的信任网络个性化推荐方法。由于每个用户都有属于自己的大社区,包括现实的和潜在的信任关系,因此利用标签传播算法得到每个用户独属的大社区。而在每个用户各自的大社区中,由于与其他用户的信任关系数据存在类似的情况,因此提出信任预处理算法,扩展用户的信任网络。此外,考虑到各个用户对其他用户的信任程度存在差异,提出信任扩散算法,对预处理算法得到的信任度做进一步区分,使得用户之间的信任程度更趋向差异化。
2 相关研究
近年来,已有不少研究将信任网络引入到推荐系统中。文献[6]提出一般信任传递算法,定义(d-n+1)/d为源节点与目标节点的预测信任度,其中,d是信任传递的最大距离;n代表源节点和目标节点间的最短距离。文献[7]在预测间接信任度时考虑源节点与目标节点间传递路径的总数。文献[8]除考虑社交网络关系中的friendship 外,还考虑了membership,即社群关系。文献[9]使用隐性信任网络,由用户-项目评分数据导出信任网络,从用户和用户对于特定项目两层次进行分析。文献[10]提出了标签传播算法(Label Propagation Algorithm,LPA),用已标记节点标签信息去预测未标记节点标签信息。文献[11]提出的算法使用标签传播在大范围网络中探测区域结构,该算法是近线性时间的。文献[12]提出了用户-商品二部图推荐算法,也称作物质扩散算法,这个算法的过程就是模拟了物质在空间中扩散即能量发生变化的过程。文献[13]提出了用户-商品-标签三部图推荐算法,使用了之前的物质扩散算法并利用标签信息进行推荐,大幅提高了算法的推荐性能。
3 融合标签传播和信任扩散的个性化推荐
一般情况下,可以用有向图来表示信任网络,用户由节点来表示,而边就可以表示为用户间的信任关系。在本文所使用的Epinions.com 数据集中,用户关系数据“22605 42915 1”表示为用户节点“22605”信任用户节点“42915”(数据集中信任关系全是用“1”表示,无差异)。本文的个性化推荐旨在有效处理信任关系数据稀疏的问题,在对用户之间的信任关系数据进行扩展的同时,将信任进一步差异化,举例来说,A同时信任B和C,但A对B的信任度可能与A对C的信任度不同。本文个性化推荐方法的架构如图1 所示。将用户项目评分数据与用户之间信任数据作为整个架构的输入,并且用字典来表示数据,分别为用户信任关系字典和用户项目评分字典;个性化推荐架构核心为经由基于标签传播的大社区发现模块得到每个用户独属的大社区,在大社区内通过信任预处理模块和信任扩散模块得到新的用户信任关系字典,接着使用用户项目评分字典进行协同过滤,得到预测评分值。该架构的输出为用户的推荐列表。
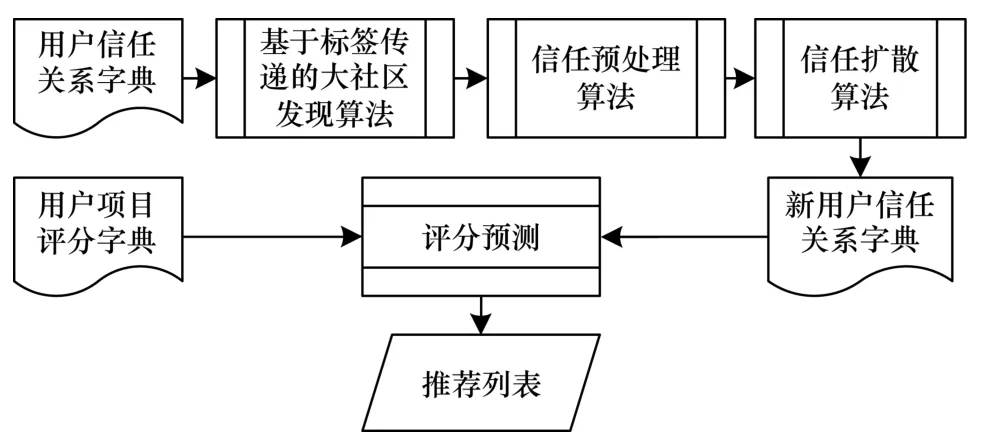
图1 个性化推荐方法架构
3.1 基于标签传递的大社区发现算法
在庞大的信任网络中,总是存在着由兴趣爱好或行业领域或内容主题等组成的大社区。但是每个用户信任或者被信任的用户是有限的,因此,有必要为用户发掘独属于自己的大社区。大社区的邻居们总能或多或少地对用户提供一些帮助,推荐用户可能喜爱或者感兴趣的东西。本文扩展标签传递算法去发现用户各自的大社区。
用户的标签可以代表用户所属的兴趣爱好、行业领域或者是关注的内容主题。如果一个用户关注了其他用户,也就代表着此用户可能与其关注的人有共同爱好或者属于同一领域。标签传递的意义在于,在一个用户关注的所有用户中,标签出现次数最多的用户代表该用户也可能有此爱好或是属于此领域;具有相同标签的用户则能构成一个大社区,这个大社区能够表达用户最显著的特征。
基于标签传递的大社区发现算法步骤如下:
(1) 使用用户信任关系字典进行迭代,得到用户A的信任列表以及被信任列表,然后获得信任用户的信任列表以及被信任用户的被信任列表,可以设定迭代层数来控制用户的关系网大小,得到关系网用户集合U。
(2) 发现用户A的1-派系,此派系中所有用户相互关注:遍历用户A所信任的用户,得到同时也关注用户A的用户列表,在这个列表中寻找相互关注的用户列表U′,并且将此列表的所有用户赋予标签L0。使用1-派系的目的是为了减小标签传递算法得到社区的随机性。
(3) 图分割
1) 在用户集合U中,除了U′中赋予L0,其余用户x都赋予标签x,Lx(0)=x,这些用户的标签都是唯一的。
2) 设置t=1。
3) 以随机模式访问U中所有用户。
4) 对于任意x∈U:

其中,k为用户A关注的用户数;函数f返回用户x所关注的人标签出现频次最高的标签(为了避免标签来回震荡,m代表在一轮计算中,计算用户x的标签时,有m个用户x关注的用户标签已更新)。
5) 如果每个用户的标签都是他关注的所有人的标签出现频次最高的标签,那么停止迭代,否则t=t+1,回到步骤3)。
(4) 通过图分割,得到与用户A标签相同的用户群,从而获得独属于用户A的大社区用户列表CA。
3.2 信任预处理算法
在独属于每个用户的大社区中,都是些志同道合或是值得信任的用户,但由于大社区中的用户真实的信任关系有限,因此大社区的信任网络也不可避免地面临着信任关系数据稀疏的问题,所以,对大社区的信任网络进行新的信任关系的预测是很有必要的。在用户信任关系字典中,如果用户A信任用户B,则表示为D[A][B]=1,反之,则为D[A][B]=0,无值则表示信任不明确[14]。假如用户A信任的用户相当一部分信任用户B,从一定程度上表明A和B存在一定相似性[5],未来B信任的人A也有可能信任,所以,可以将协同过滤思想应用于用户信任关系字典。对于用户Ui,在其独属的大社区CUi中,同时包含与有Ui有信任关系的成员集合CUi1和没有信任关系的成员集合CUi2,对于∀B∈CUi2,可以计算用户A和成员集合CUi1的相似度,得到相应的邻居集合,接着可以依据邻居集合中的用户对B的评价来预测A对B的评价。
(1) 用户相似度计算
用户Ui对用户Uj相似度可以定义为:用户Ui信任的用户集合与信任用户Uj的用户集合的用户交集数和用户Ui信任的用户的总数之比。此处相似度的含义是用户Ui关注的用户中,有多大比例也关注了用户Uj。其中,用户Ui信任的用户集合由TUi表示,而信任用户Uj的集合由TRUj表示。但是,如果用户Ui关注的用户中极少数关注了用户Uj,则不足以表明他们存在相似性,因此应当设定阈值x,只有用户Ui关注的用户中同时关注用户Uj的数量大于等于x,才可计算两者之间的相似度。
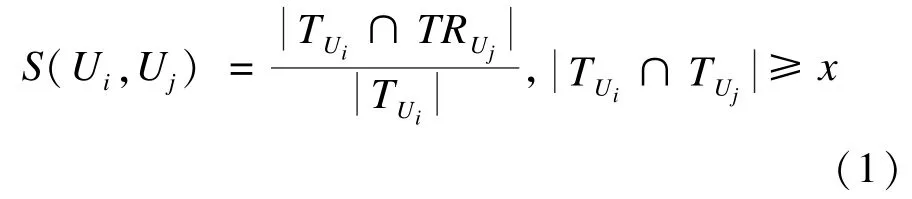
S(Ui,Uj)≠S(Uj,Ui),Ui和Uj之间的相似度不可逆。
(2) 用户信任度预测
获取用户Ui大社区内有信任关系的、并且能够计算得到相似度的用户作为邻居用户集合,CUi1′为邻居用户中信任Uj的用户子集,CUi2为Ui大社区CUi内无信任关系的用户集合。则Ui与Uj之间信任度表达式W(Ui,Uj) 如下:
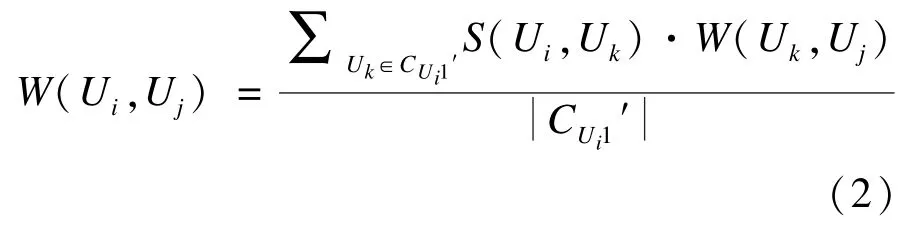
其中,Uj∈CUi2。
3.3 信任扩散算法
传统的扩散算法是应用在用户-商品二部图或者用户-商品-标签三部图上;本文则是对扩散算法进行改进,应用于用户-用户二部图上,称之为信任扩散算法。
信任网络中有信任关系和被信任关系,有些信任关系式对称的,是双向信任关系;也有许多信任关系是非对称的,仅是单向信任关系。Epinions.com网站上用户可以对某物品写评论(review),而其他用户可以对评论进行反馈评分(review rating)。有调查显示,大多数人认为对于一件商品最为可靠的信息来源是和他们相似的一群人[15]。在Epinions.com 网站中,评论者(reviewer)如果撰写了一篇评论(review),又或者是向别人进行推荐,那么和这个评论者志趣相投的用户通常会觉得这篇评论很有价值,并且有极大可能相信该评论者未来撰写的评论或者去购买该评论者所推荐的物品,即信任该评论者[16]。每一个人都会对某些事物产生兴趣,只是各人表现方式不同,有些人会写关于自己感兴趣事物的评论,有些人会阅读别人的评论并且进行反馈,展现出自己感兴趣的方面。写下评论的评论者大多希望得到其他用户的反馈,他们希望能够从反馈的那些用户中寻找与自己爱好类似领域的用户,并阅读这些用户的评论或者进一步关注他们推荐的事物,即对评论反馈者产生信任[17]。所以,如果当用户A对用户B的评论赞同或是对他买的物品感兴趣时,那么A信任B,而且这个信任关系可以在给A做推荐的时候做出贡献;同样B被A信任,从一定程度上来说,A与B也存在一定相似性,对于被信任者B来讲,A对其信任,也能使得A 的某些决策给B做推荐的时候做出贡献[18]。
用户-用户二部图如图2 所示,从中可知,A,B,C,D信任用户总数为2,1,2,3。

图2 用户-用户二部图
将二部图转为信任推荐贡献字典,如表1 所示。其中,行和列表示为不同的用户,而值则表示用户间的推荐贡献。
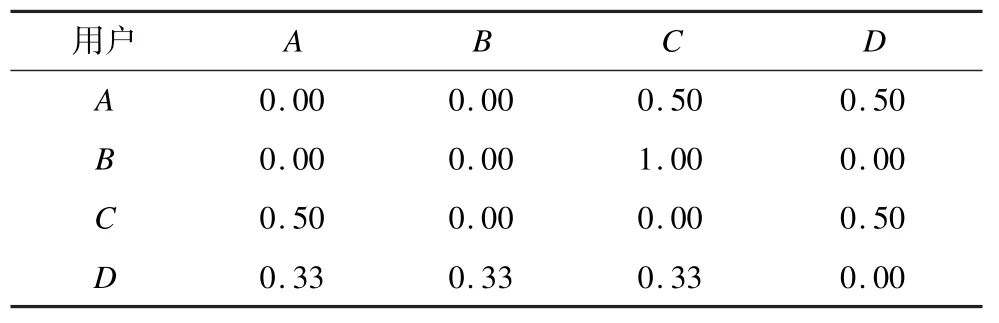
表1 信任推荐贡献字典
如表1 中的第2 行所示,由二部图可知A信任C,D,则A,B,C、D在给A做推荐时贡献为0.00,0.00,0.50,0.50。同样的,如表1 第5 行所示,二部图可知D信任A,B,C,则A,B,C,D在给D做推荐的时候贡献为0.33,0.33,0.33,0.00。上文提到,Epinions.com 数据集中信任关系全是用“1”表示,表1 只是在假设所有信任值均1 的前提下进行的推荐贡献字典输出,因此,3.2 节信任预处理算法扩展得到的某些预测信任值虽不等于1,并不会影响信任推荐贡献字典的生成。
本文考虑一般的用户信任关系二部网络G(X,X′,E),X和X′代表用户节点,由x1,x2,…,xn和x1′,x2′,…,xn′各自表示,X′是X的拷贝,均是用户节点集合[12];而E则为表示信任关系的边。每个用户节点xi(二部图左侧)对于他信任的用户节点xj′(二部图右侧),在xj′处标注xi对xj′的信任值(这里的信任值由3.2 节信任预处理算法得到)。接着将xi信任的所有用户节点的信任值进行累加,并且得到xj′处标注的值和信任累加值之比,即经由信任扩散过程后,xj′给xi做推荐时的贡献值。
进一步推广,假设Ui信任m个用户,信任集合为M,对于用户Uj,其给Ui做推荐的贡献值为:

同时,由用户-用户二部图可知,A,B,C,D被信任用户总数为2,1,3,2。将二部图转为被信任推荐贡献字典,如表2 所示。行列均表示用户,值代表了用户间的推荐贡献。如表2 中的第4 行所示,由二部图可知,C被A,B,D信任,则A,B,C,D在给C做推荐时贡献为0.33,0.33,0.00,0.33。
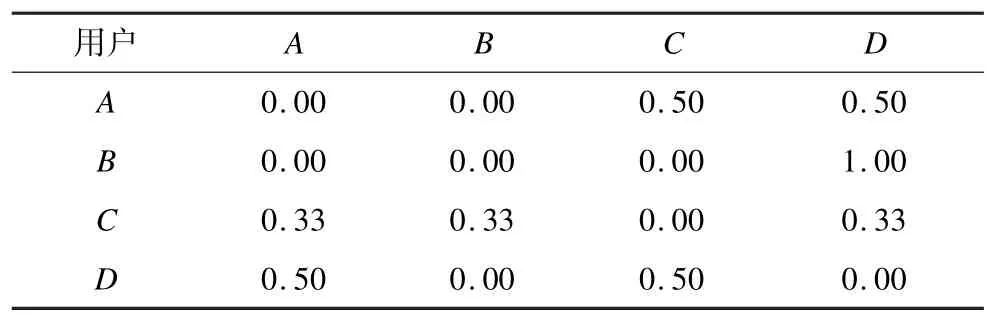
表2 被信任推荐贡献字典
与之前类似,考虑一般的用户信任关系二部网络G(X,X′,E),X,X′和E代表意义不加赘述。每个用户节点xi′(二部图右侧),对于信任他的用户节点xj(二部图左侧),即xj信任xi′,在xj处标注xj对xi′的信任值(这里的信任值由3.2 节信任预处理算法得到)。接着将所有信任xi′的用户节点对xi′的信任值进行累加,并且得到xj处标注的值和信任累加值之比,即经由信任扩散过程后,xj给xi′做推荐时的贡献值。
进一步推广,假设Ui被n个用户信任,被信任集合为N,对于用户Uj,其给Ui做推荐的贡献值为:

本文3.2 节信任预处理算法预测了用户之间的信任值,扩展了信任网络。对于用户Ui来说,在其独属的大社区CUi1中,原来有信任关系的成员集合CUi1将扩展为CUiNew,并且将之前的2 种推荐贡献情况混合考虑,引入调节因子λ,则扩散后的用户信任度为:

其中,Uj∈CUiNew;λ为引入的调节因子,其取值范围为[0,1]。
3.4 用户项目预测评分
经过基于标签传递的社区发现、信任预处理和信任扩散算法,得到了新的用户信任关系字典,接着将用户信任度取代传统协同过滤的用户相似度,并且以用户信任度为权重。然后,依据用户的信任用户集合对项目的评分来预测目标用户对目标项目的评分。这里使用最常用的评分预测公式[19]:
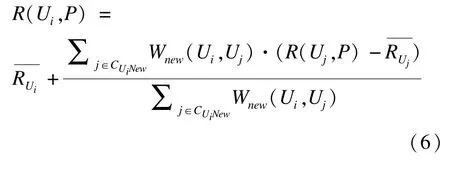
4 实验结果及分析
4.1 数据集
本文使用的是来源于Epinions.com 的数据集[6],在Epinions.com 的用户评论平台上,用户不但可以表达他们喜欢某个物品,而且还能声明一般情况下会信任某些用户及其观点。整个数据集由49 290 个用户、139 738 个项目、487 181 条用户信任数据以及664 824 条用户-项目评分数据组成。随机选取整个数据集的80% 作为训练集,20% 作为测试集。经实验,设定信任预处理算法中的阈值x设为3。
4.2 度量标准
平均绝对误差(Mean Absolute Error,MAE)是常用的推荐质量评价标准之一,MAE 通过衡量预测评分值与实际评分值之间的差距来计算准确率,MAE 值越小则准确率越高。MAE 的计算公式如式(7)所示,其中,是所有预测评分个数;dp是预测评分值;dt是实际评分值。

4.3 实验结果
4.3.1 调节因子实验
在3.3 节的信任扩散算法中,λ的取值为[0,1]。本文将λ的值从0 到1 以步长0.05 增加。随机选取得到1 份训练集和测试集,应用本文的个性化推荐算法共做21 次实验,结果如图3 所示。

图3 不同λ 值的准确率比较
可见,在进行信任扩散时,λ在0.95 和0.05 时准确率最差。而当各占50% 左右时准确率最好。若信任用户(被信任用户)被赋予较大权重,被信任用户(信任用户)权重很小时,相对于只考虑信任用户(被信任用户)时来说,准确率要下降很多,原因可能是:新添加的权重很小的被信任用户(信任用户),导致相当多的新用户信任度数值很小,引入了噪声,影响了准确率。在λ为0.5 左右时准确率最好,原因可能是同时考虑信任用户和被信任用户,是将所有和目标用户有直接关联的全盘考虑进去,可能在类似Epinions.com 的交流平台上,信任者可以给被信任者做决策时提供相当可观的贡献。
4.3.2 准确率实验
基于初始信任网络的算法是指直接使用默认的用户之间的信任数据,不进行扩展和差异化,以用户信任度替代用户相似度进行协同过滤,本文以only_trust 表示该方法。基础信任扩散算法是指直接使用默认用户之间的信任数据,并且使用本文3.3 节算法,进行协同过滤,本文以only_diff 表示该方法。文献[6]使用简单信任传递模型,得到的预测信任度(d-n+1)/d,d为最大信任传递距离,n为源节点和目标节点的最短距离,本文以prop_trust 表示该方法,且d设置为2,将得到的用户信任度进行协同过滤。将本文提出的推荐方法以lp_pre_diff 表示且λ取0.5,与prop_trust,only_trust 以及only_diff 方法进行比较。随机选取得到5 份训练集以及测试集用来实验,实验结果如图4 所示。每次实验使用一份训练集和测试集,并且对4 种推荐方法的准确率进行比较。
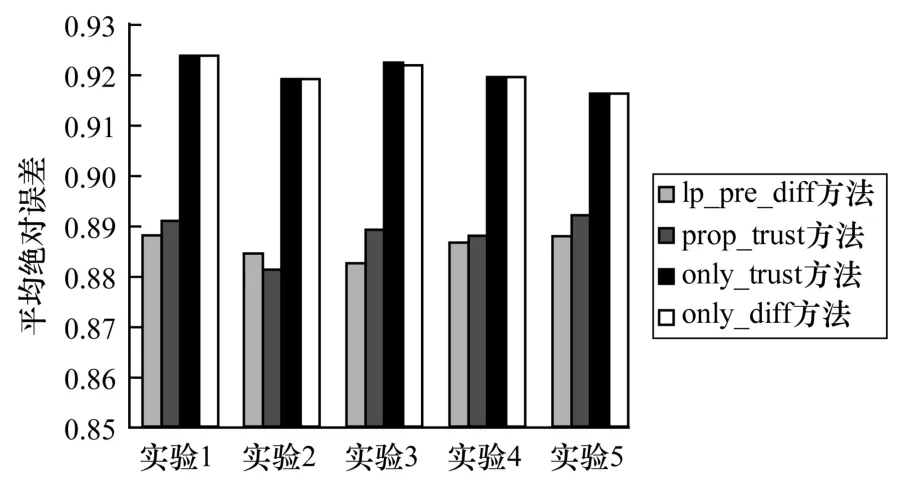
图4 不同推荐方法的准确率比较
从实验结果可知,本文方法和prop_trust 方法[6]准确率明显高于only_trust 和only_diff 方法,原因可能是only_trust 和only_diff 方法所使用的用户信任关系数据都是原始的,较为稀疏,无法得到可靠的推荐。除去实验2,本文算法均好于prop_trust 方法。原因可能是本文算法通过大社区提取、预处理和信任扩散等一系列方法扩展信任网络并且将信任差异化,在预测目标用户对某用户信任度时,考虑到了目标用户所在大社区内的大多数和某用户有关联的用户群的意见,因此相对合理;不过,用户所属的大社区中提供建议的用户较多,因此预测处的信任关系仍然可能没有那么可靠,在最后预测项目评分的时候使最后得到的准确率降低。
5 结束语
基于信任网络的推荐方法面临信任数据过于稀疏的问题,导致推荐效果不理想。本文提出改进方法,得到属于各个用户的大社区、扩展用户信任网络并且使信任度差异化,一定程度上解决了数据稀疏的问题。实验结果表明,改进后的算法具有较高的准确率。下一步工作是将隐性信任引入到推荐系统中,从而更好地解决数据稀疏问题,提高准确率。
[1]项 亮.推荐系统实践[M].北京:人民邮电出版社,2012.
[2]Lü L,Medo M,Yeung C H.Recommender Systems[J].Physics Reports,2012,519(1):1-49.
[3]Segaran T.集体智慧编程[M].王开福,译.北京:电子工业出版社,2009.
[4]Rajaraman A,Ullman J D.大数据:互联网大规模数据挖掘与分布式处理[M].王 斌,译.北京:人民邮电出版社,2012.
[5]Jannach D,Zanker M,Felfernig A.推荐系统[M].蒋 凡,译.北京:人民邮电出版社,2013.
[6]Massa P,Avesani P.Trust-aware Collaborative Filtering for Recommender Systems[C]//Proceedings of CoopIS,DOA,and ODBASE Book Subtitle OTM Confederated International Conferences.Agia Napa,Cyprus,[s.n.],2004:492-508.
[7]陈晓诚.基于信任传播模型的协同过滤算法研究[D].广州:中山大学,2010.
[8]Yuan Quan,Chen Li,Zhao Siwan.Factorization vs.Regularization:Fusing Heterogeneous Social Relationships in Top-N Recommendation[C]//Proceedings of the 5th ACM Conference on Recommender Systems.New York,USA:ACM Press,2011:245-252.
[9]O’Donavan J,Smyth B.Trust in Recommender Systems[C]// Proceedings of the 10th International Conference on Intelligent User Interfaces.New York,USA:[s.n.],2005:167-174.
[10]Zhu Xiaojin,Ghahramani Z.Learning from Labeled and Unlabeled Data with Label Propagation[R].Pittsburgh,USA:Carnegie Mellon University,Technical Report:CMU-CALD-02-107,2002.
[11]Raghavan U N,Albert R,Kumara S.Near Linear Time Algorithm to Detect Community Structures in Largescale Networks[J].Physical Review E,2007,76(3).
[12]Zhou Tao,Ren Jie,Medo M.Bipartite Network Projection and Personal Recommendation [J].Physical Review E,2007,76(4).
[13]Zhang Zike,Zhou Tao,Zhang Yicheng.Personalized Recommendation via Integrated Diffusion on User-itemtag Tripartite Graphs[J].Physica A:Statistical Mechanics and Its Applications,2010,389(1):179-186.
[14]Kantor P B,Ricci F,Rokach L.Recommender Systems Handbook[M].Berlin,Germany:Springer,2010.
[15]Edelman R,Williams E.Edelman Trust Barometer[EB/OL].[2014-01-15].http://www.edelman.co.uk/trustbarometer/2007.
[16]Hill S,Provost F,Volinsky C.Network-based Marketing:Identifying Likely Adopters via Consumer Networks[J].Statistical Science,2006,21(2):256-276.
[17]张 宇.在线社会网络信任计算与挖掘分析中若干模型与算法研究[D].杭州:浙江大学,2009.
[18]定明静.基于信任网络的推荐技术研究与应用[D].成都:电子科技大学,2013.
[19]Resnick P,Lacovou N,Suchak M.GroupLens:An Open Architecture for Collaborative Filtering of Netnews[C]//Proceedings of ACM Conference on Computer Supported Cooperative Work.New York,USA:ACM Press,1994:175-186.
