基于SIFT,K-Means和LDA的图像检索算法
2014-12-02汪宇雷毕树生孙明磊蔡月日
汪宇雷 毕树生 孙明磊 蔡月日
(北京航空航天大学 机械工程及自动化学院,北京100191)
图像作为最基本、最重要的多媒体信息形式之一,凭借其表象直观、内容丰富的优势,已广泛地应用在众多领域,而快速准确搜索到所需相关图像已成为国内外信息检索领域的研究热点.
目前,已经存在的图像检索方法主要分为基于文本的方法和基于内容的方法[1].基于文本的方法首先对图像进行文本标注,然后将文本数据存入数据库,用户检索时是通过查询数据库中存储的文本信息来实现图像检索.基于内容的方法又可分为基于颜色[2]、纹理[3]、形状[4]、空间[5]等特征的方法,虽然提取特征不一样,但基本过程类似,均通过比较图像间的相同特征来判断是否相似,从而给出符合要求的搜索结果.由于局部视觉特征拥有优秀的紧凑性与鲁棒性,更多的系统采用基于兴趣点的局部特征进行图像检索[6-11].文献[7-8]中分别使用近似K-Means算法和对局部空间进行网格结构均分得到视觉词汇表,但这两种做法会忽略图像的语义部分.文献[9]提出使用隐马尔可夫模型(HMM,Hidden Markov Model)将图像语义和视觉特征整合以构建词汇表.文献[10]提出结合各类局部特征的颜色矩阵和Gabor特征进行检索.文献[11]提出通过比较各兴趣点局部泽尼克矩的欧氏距离来提取最优匹配点,然后以兴趣点的空间离散度计算图像匹配性.
以上这些研究成果更多地考虑在匹配过程中采用不同的算法比较兴趣点特征以提高检索速度和准确性,但在检索过程开始前,剔除大部分不相干图片也可以加快检索进程.针对这一点,本文在考虑图像语义的基础上提出一种新的图像检索方法:采用K-Means算法生成视觉词袋模型后利用潜在狄利克雷分布(LDA,Latent Dirichlet Allocation)算法将图片库进行预分类,用户提交待检索的图片后,先将其归类,最后在此类下采用特征点匹配方法检索到合适的图片.算法创新之处有2点:
1)通过LDA算法分析图像语义,将图库中相关性较大的图片自动归为一类,而不引入人为因素;
2)待检索的图片提取兴趣点特征后,经过计算可被归为合适的类别,后再进行匹配比对,由于不需要与所有图片进行对比,一方面减少检索时间,另一方面检索准确率和检索召回率都可提高.此算法可用于图像内容特征区别较明显的图像库检索工作.
1 基本框架
本文所提出的检索算法实现过程主要有两个阶段:
1)预备阶段中系统首先通过尺度不变特征变换(SIFT,Scale Invariant Feature Transform)特征提取算法提取图片库中所有图片的特征,然后采用K-Means聚类算法将所有特征聚类生成基本词库,最后采用LDA主体模型算法结合基本词库将图片库中图片按照各自本身内容进行分类,同时得到概率分配参数表;
2)实现检索阶段中,用户向系统提交待检索图片(用S表示),系统首先提取S图片特征,然后利用已生成的基本词库将S图片特征归类,用概率分配参数表归类S图片,最后在该类下采用SIFT特征点匹配算法寻找与S图片的最相似图片.
图1为整个检索算法的运行流程.
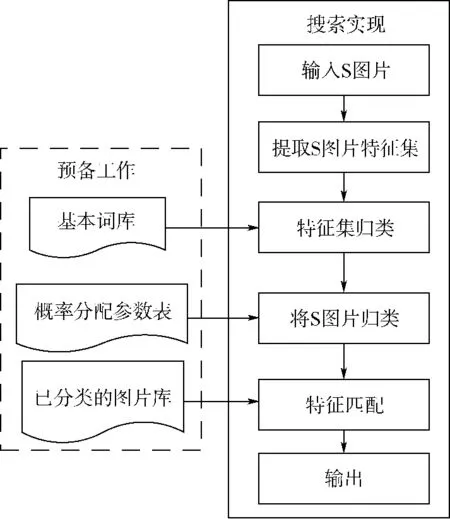
图1 图像检索流程Fig.1 Process of image retrieval
值得注意的是预备阶段可在搜索阶段之前进行,故预备工作阶段的运行时间与用户的访问时间无关.
2 预备工作
执行检索功能前,系统需要一定的预备工作,产生必要的基础文件——基本词库、概率分配参数表和已经分类的图片库.此3份文件通过特征库建立、基本词库建立和图片分类3个步骤生成.
2.1 特征库建立
由于本文实现的检索功能是基于本地计算机的,故需准备一些图片作为将来的搜索对象.这些图片构成图片库P,用pm表示其中任意一张图片,D表示图片总量,则图片库集合为
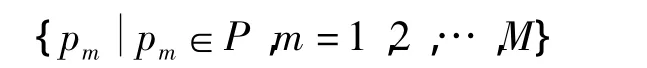
将来的搜索工作便是基于此库寻找与用户提交的图片相匹配的图片.
建立特征库即是提取图片库中所有图片的有效特征.本文选择的是基于兴趣点特征的SIFT[12]特征检测技术.建立具体实现过程是通过SIFT特征检测算法依次读入图片库P中所有图片并生成特征库Q.图片pm对应生成特征集fm,则特征库集合为
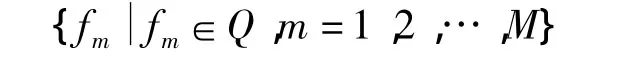
每个特征集文件是对应单个图像文件的特征向量集:

其中Nm表示第m个特征集文件包含Nm个特征向量,则特征库中特征向量总数:
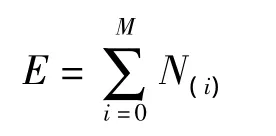
由于每张图片内容不一样,一般每个特征向量集中所包含的特征向量总数和具体值都不一样.
2.2 基本词库建立
特征库可视为特征向量的集合,这些特征向量集对应图片的基本信息,为了简化生成的特征库,需要将这些特征向量进行归类.由于这些特征向量是基于欧式空间的128维向量,K-Means算法作为一种基于距离和划分的聚类算法,可以在欧式空间中对这些特征向量进行归类[13].
特征库中所有特征向量经过K-Means算法聚类后生成基本词库H,用wk表示其中任意一个基本单词,V表示基本单词总数,则基本词库集合表示为
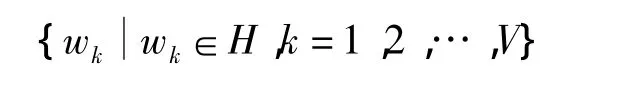
由此整个特征库分成了V簇,而每个基本单词实际上也是基于欧式空间的128维向量.由于所有属于第k簇的特征向量可被基本单词wk所替代,故第m特征集可转化为
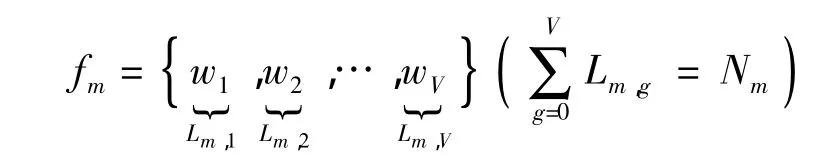
其中Lm,g表示第g个基本单词在第m个特征文件中所出现的频次,且按照K-Means算法的要求,V应小于E,即基本单词总数小于特征向量总数,故整个特征库得到了简化.虽然此步骤损失了图像存储精度,但它是图片分类的决定性步骤.
经过特征库建立和基本词库建立两步骤之后,图片库P转化对应的单词组合文本库T,其集合为
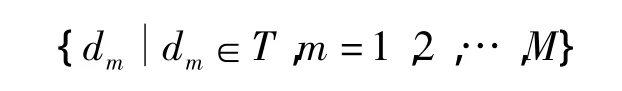
每个文本文件dm所含信息为每个单词在对应特征向量集fm出现的频次,即
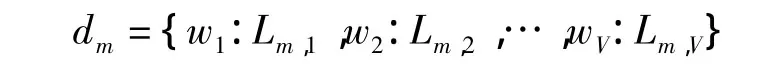
由于单词组合文本替代了难以描述化的图片,系统便可依据此文本库将对应的图片识别分类.
2.3 图片分类
提高图片检索效率最关键步骤在于图片分类.由于图片主体往往存在一个主题,比如天空、建筑、道路或者商场等等,而主题模型理论能够发现文本中使用词语的规律,并且把规律相似的文本联系到一起[14],故本文采用已经应用到邮件、科技文献摘要、新闻稿等各类文本上的主题模型理论将图片按照其潜在性的主题进行分类.本文采用主题模型理论中的LDA模型[15]对图片库进行无主题分类.
LDA为3层贝叶斯模型,由单词(word)、文本(doc)、主题(topic)组成,其模型结构如图2所示.
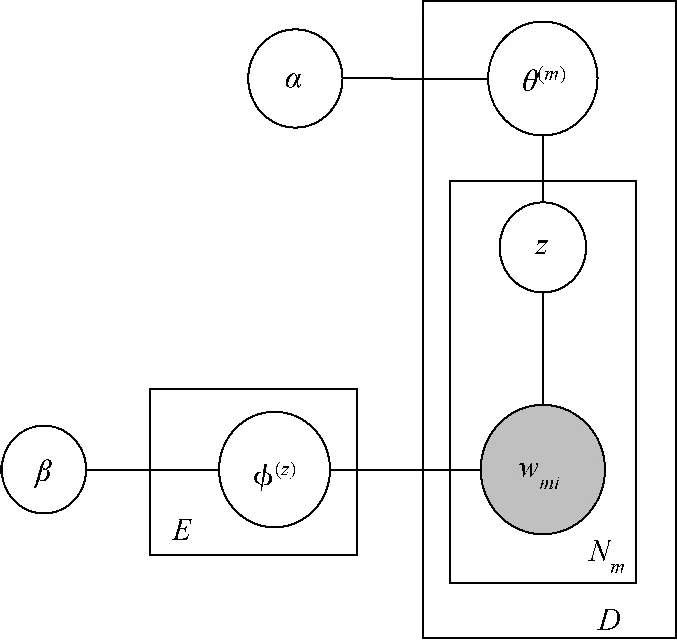
图2 LDA主题模型Fig.2 LDA topic model
将LDA模型应用于本算法提出的单词组合文本库T,其生成过程如下:
1)设定图片库主题总数F,参数α和β;
2)对于每个主题,从参数为β的Dirichlet先验分布中抽样,并作为1个多项分布φ(z),此步骤重复F次;
3)对于每个特征集合文本,从参数为α的Dirichlet先验分布中抽样,并作为1个多项分布θ(m),为了生成文本dm中每个单词wmi,需从多项分布中抽取一个主题,然后根据此主题对应的多项分布抽取一个单词,重复Nm次后便生成文本dm,由于每个文本没有相互关系,只需重复M次,便可生成整个文本库T.
LDA主题模型的目标是根据已有的单词组合文本库(每个word是可观察到的)重建θ(m)和φzmi(第m个文本中第i个单词所对应的topicwords多项式分布).经推导可得到第m篇文章中第i个单词生成第z个主题的概率,如式(1)所示.
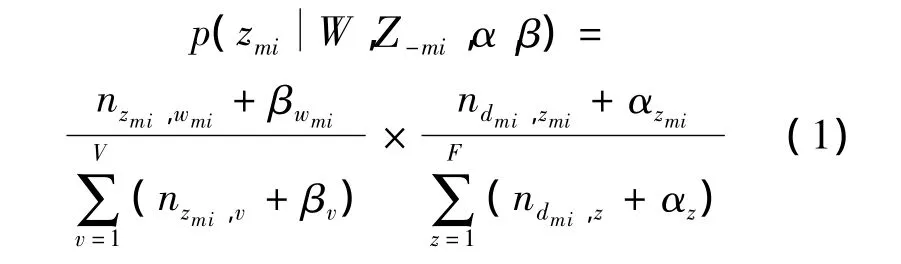
LDA模型迭代计算成功后,每个单词的主题即得到明确分配,故可得到 θmz和 φzv矩阵:θmz表示文本m生成主题z的概率,即条件概率m),其符合多项分布:
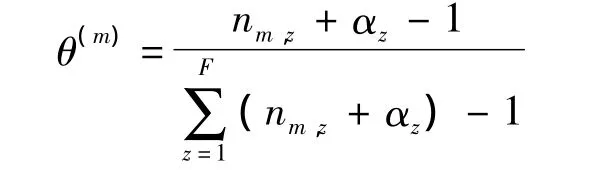
nm,z表示文本m与主题z的所有共现次数;φzv表示在主题为z时,生成单词v的概率,即条件概率,其符合多项分布:
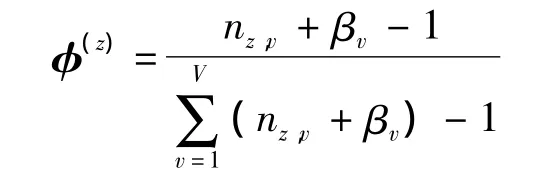
nz,v表示主题z与单词v的所有共现次数.通过比较概率值可确定文档所在主题,继而可将相对应图片划分到相同类别中,而φzv矩阵所含数据即是主题概率分配参数表的数据源.为使算法可通过编程实现,α设定为50/V,β设定为0.1,两者均不随模型中的参数变化.
3 检索实现
预备工作完成后,可得到基本词库、概率分配参数表和已经分类的图片库3份基础文件,搜索的执行过程将以此为基础,经过特征集提取、特征集归类、图片归类和特征匹配4个步骤完成.假设用户需在本地搜索图片S的相似图片,整个搜索过程如下.
1)特征集提取.
与特征库建立过程类似,系统读入S图片,采用SIFT特征检测算法生成S图片特征集fS.
2)特征集归类.
预备工作中第2步骤已生成针对整个图片库P的基本词库H,由于一般情况图片库中图片数量较多,故本文提出如下假设:
假设1 单张图片的引入不会造成原图片库整个特征向量集在128维欧式空间产生严重畸变.
基于此假设,S图片特征集的简化可直接在基本词库H的基础上进行.具体执行方案是利用欧式距离作为判别准则,以穷举法为查找方法,循环查询fS中所有特征向量,找到与基本词库H特征向量最近的单词,然后用此单词替代特征向量,查询完成后,统计每个单词词频,生成与S图片对应的文本文件dS,其内容为

其中 Sv,V表示wV在 dS的词频.
3)图片归类.
预备工作中第3步骤生成的主题概率分配表是针对系统中已经存在的图片库进行迭代生成的,由于图片数据量较大,且具有一定的普遍性,故本文提出如下假设:
假设2 单张图片的引入不会造成主题概率分配表数据的大范围变化.
基于此假设,S图片可以采用分配表的数据进行分类,采用式(2)进行计算.
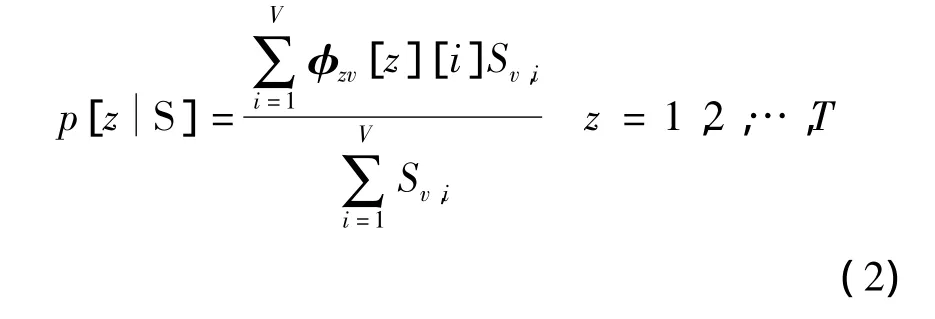
计算S图片生成各个主题的概率后可确定S图片属于每个主题的概率,假设z*为概率值最大的类别,一般将S图片划分到z*类中.
4)特征匹配.
在S图片所属类别z*中存在有多幅图片,需通过特征匹配方法寻找最匹配图片.本文首先选用SIFT特征点作为依据,欧式距离作为准则进行匹配操作,然后搜索z*每张图片中每个特征向量到S图片中每个特征向量的距离.若采用线性扫描,也称为穷举搜索的方法,依次计算其中每个特征向量的距离将会十分耗时.因为实际数据都会呈现簇状的聚类形态,本文采用Beis和Lowe提出的BBF[16](Best-Bin-Fist)的kd-trees近似算法,利用该算法搜索SIFT特征点的最近邻点时,可以以更高的概率搜索到精确的最近邻点.kd-trees近似算法匹配标准为欧氏距离最小值与次最小值的比值在一定阈值内时,即可认为配准成功,在本文算法中选取此阈值为0.45.
4 实验结果
本文采用Corel图像库作为测试集进行实验.图片库总共1000幅图片,均分为10个类别.实验设置聚类数为20,聚类数设置过少不能达到很好的分类效果,而聚类数过多会导致聚类过程非常缓慢.另外由于图片库主题数为10,故设置算法中LDA分类数为10.由于在实际检索系统中,用户一般只关心排序靠前的结果,因此这里取前60个结果作为有效检索结果进行比较.
该实验用来对比的方法有2个,基于兴趣区域的方法和基于兴趣点最小覆盖圆的方法[17].图3和图4展示了不同返回图像数目时,3种算法间平均正确率和平均召回率的比较结果.
从图3和图4显示的对比结果中不难看出,正确率和召回率均明显优于文献[17]提出的两种算法,且在返回图像数目越少时算法优越性越明显.具体原因有两点:
1)由于要检索的图片只与已经无监督分类的同类图片进行比对,减少了不相关图片的干扰,故返回图像数目较少时准确率较高;
2)算法的局限性使得一些主题特征不是很明显的图片会被错误分类,这就导致在返回图像数目过多时,准确率与召回率的减少速度大于另外两种算法.

图3 图像检索结果平均正确率比较Fig.3 Average accuracy comparison of retrieval result
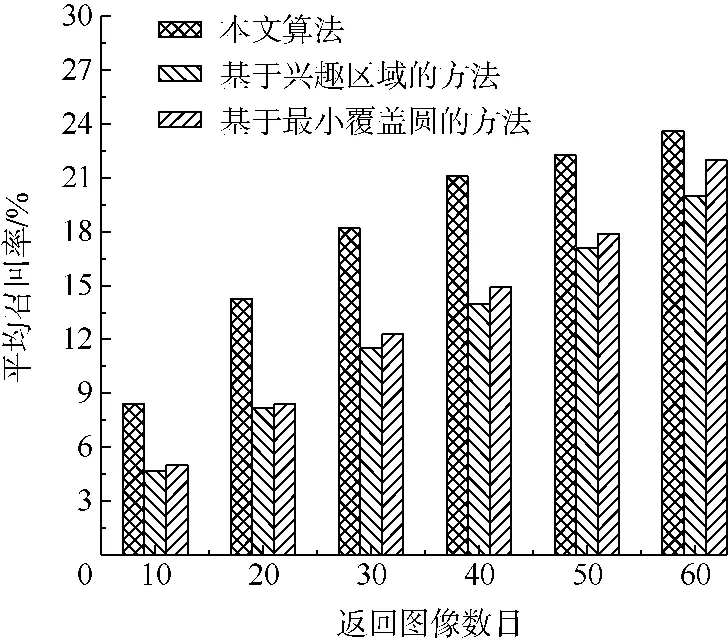
图4 图像检索结果平均召回率比较Fig.4 Average recall rate comparison of retrieval result
5 结论
本文在综合分析SIFT,K-Means和LDA的基本原理基础上提出了一种新的图像检索算法,经实验验证表明:
1)算法可实现较为优异的检索性能,例如返回10张结果条件下算法检索正确率83.15%,召回率8.42%,在60张下正确率39.33%,召回率24.61%;
2)算法提出单张图片的引入不会造成原图片库的特征向量集和主题概率分配发生严重畸变的两个假设在一定范围(待检索图片与原图库特征类似)内是成立的;
3)算法的预备工作使检索范围由原先整个库缩小至某个子类中,虽使召回率有所损失,但检索时间得到较大的缩短;
4)可预估对于特征较接近的图片库,比如人脸库,图片预备工作会产生较大的分类误差,且可能进一步影响检索性能.
为使本文提出的算法能处理各种类型的图片,仍需要优化预备工作和检索实现过程的各项参数.
References)
[1] Rui Y,Huang T S,Chang S F.Image retrieval:current techniques,promising directions,and open issues[J].Journal of Visual Communication and Image Representation,1999,10(1):39-62
[2] Younes A A,Truck I,Akdag H.Image retrieval using fuzzy representation of colors[J].Journal of Soft Computing,2007,2(3):287-298
[3] Bhuiyan S M A,Adhami R R,Khan J F.A novel approach of fast and adaptive bidimensional empirical mode decomposition[C]//IEEE International Conference on Acoustics,Speech and Signal Processing.Piscataway,NJ:IEEE,2008:1313-1316
[4] Yang X,Latecki L.Affinity learning on a tensor product graph with applications to shape and image retrieval[C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway,NJ:IEEE,2011:2369-2376
[5] Jégou H,Douze M,Schmid C.Improving bag-of-features for large scale image search[J].International Journal of Computer Vision,2010,87(3):316-336
[6] Zakariya S M,Ali R,Ahmad N.Combining visual features of an image at different precision value of unsupervised content based image retrieval[C]//Proceedings of International Conference on Computational Intelligence and Computing Research.Piscataway,NJ:IEEE Computer Society,2010:110-113
[7] Philbin J,Chum O,Isard M,et al.Object retrieval with large vocabularies and fast spatial matching[C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway,NJ:IEEE,2007:1-8
[8] Tuytelaars T,Schmid C.Vector quantizing feature space with a regular lattice[C]//Proceedings of IEEE International Conference on Computer Vision(ICCV).Piscataway,NJ:IEEE,2007:1-8
[9] Ji R,Yao H,Sun X,et al.Towards semantic embedding in visual wordbulary[C]//Proceedings of IEEE International Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway,NJ:IEEE,2010:918-925
[10] Jian M W,Chen S.Image retrieval based on clustering of salient points[C]//2nd International Symposium on Intelligent Information Technology Application.Piscataway,NJ:IEEE,2008:347-351
[11]符祥,曾接贤.基于兴趣点匹配和空间分布的图像检索方法[J].中国激光,2010,37(3):774-778 Fu Xiang,Zeng Jiexian.A novel image retrieval method based on interest points matching and distribution[J].Chinese Journal of Lasers,2010,37(3):774-778(in Chinese)
[12] Lowe D G.Object recognition from local scale-invariant features[C]//Proceedings of the Seventh IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE,1999:1150-1157
[13]周爱武,于亚飞.K-Means聚类算法的研究[J].计算机技术与发展,2011,21(2):62-65 Zhou Aiwu,Yu Yafei.The research about clustering agorithm of K-Means[J].Computer Technology and Development,2011,21(2):62-65(in Chinese)
[14] Wei X,Croft B W.LDA-based document models for ad-hoc retrieval[C]//Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,2006:178-185
[15] Blei D M,Ng A Y,Jordan M I.Latent dirichlet allocation[J].Journal of Machine Learning Research,2003(3):993-1022
[16] Beis J S,Lowe D G.Shape indexing using approximate nearestneighbour search in high-dimensional spaces[C]//Proceedings of IEEE Society Conference on Computer Vision and Pattern Recognition(CVPR).Piscataway,NJ:IEEE,1997:1000-1006
[17]齐恒.基于内容图像检索的关键技术研究[D].大连:大连理工大学,2012 Qi Heng.The research of key techniques in content-based image retrieval[D].Dalian:Dalian University of Technology,2012(in Chinese)
