基于复杂网络理论的中文文本聚类算法
2014-11-15李培
李 培
(西安邮电大学,西安,710061)
0 引言
在信息时代的今天,信息的极大丰富也带来了信息处理的极大困难,无论是信息的存储、查询或是检索,或多或少都需要对信息进行前期的分类,在浩如烟海的众多信息中,文本信息占据了绝大多数,同时,很多其他类型信息的重要内容都体现在其文本的部分,可将转换为文本,因此,最终的问题归咎於文本分类问题。而这些繁杂的信息往往没有明确的分类标准和归属类别。传统的按照已有的类别进行分门别类的分类技术已经被聚类技术所取代,聚类算法可以将文本信息根据其特点自动地划分类别,分成合适数目的几类,使其具有类中相似和类间相异的特点。
本文主要针对在中文文本聚类中普遍存在的对潜在语义考虑不足、文本特征表示不够准确且对于海量数据处理效率低下这三个方面,提出了一种基于图的中文文本聚类算法,采用基于小世界网络模型提取关键字作为文本特征进行文本表示,并辅以基于《知网》的语义相似度算法来计算文本相似度。可以达到处理大规模海量数据、精简的表示文本并考虑中文语义的目的,使得聚类性能更好。
1 基于小世界网络模型提取关键字的文本表示方法
简单文本聚类算法就是将数据聚类的算法应用到文本集合,研究这种类型的文本聚类算法主要考虑对文本进行数据表示、特征选择和提取,将文本集合表示成特征矩阵的形式。为了将文本集合表示为特征矩阵,需要对文本进行建模。在建模时,需要考虑文本和在文本中出现的词,可以把文本看成是词的集合,也可以看成是词的某种序列。最常见的模型是向量空间模型(VSM),即文本表示为T = (t1,t2,…,tn),分量ti是各个词条。根据常识可以知道,在中文的语句中,描述简单的内容就需要相对较多的词条。因此,直接由分词结果构成的向量空间模型数据量往往存在过大的问题,对后期的处理和聚类带来了很多问题,降低了实际应用的价值,增加了复杂度。
但是,我们也知道在日常生活中常常会用某篇文章的一些关键词语来描述该文章的主题,大家都认可关键词语能够反映出其所对应的文章的主要内容。由于一篇文章的关键词语与其分词得到的大量词条相比是非常少的,所以采用关键词语来作为文本特征表示文本可以作为一个大大降低算法复杂度和难度,同时又不影响算法准确性的最佳选择。
这里。我们对传统的文本表示方法进行改进,用文本的关键词语集合来表示文本。同时,利用复杂网络理论中的小世界网络模型来获取关键词语。
小世界网络理论是复杂网络中的一个经典理论,它集中体现了在我们日常生活中随处可见的小世界现象,即聚合效应,在很多构成网状结构的问题中都有应用。我们在对文本进行研究的同时也发现了文本中的各个词条之间通过其语义连接形成的结构图恰恰是网状结构,而且文本中的关键词语还存在明显的小世界现象。
具体算法如下:
Step1:对中文文本进行中文分词,这些分词词条就构成了小世界网络图的各个结点。
研究和改革无机化学课程教学不但可以从源头提高化学教师的素养,而且为解决新课程实施中的问题提供根本保障.“实践+反思=教师成长”已经成为共识.一些发达国家纷纷建立实习实训基地,目的是让学生在实地观察、体验教学及与指导教师的交流中获得实践性知识,在不断实践反思的过程中形成技能.这为无机化学课程改革提供理论支持和可操作的教学策略.
Step2:构图:即连接各个结点。结点之间是否有连接的判断是基于连接范围因子。符合要求的结点之间通过连接就形成了边。从而由单个的词条变成了词条网络G1。
Step3:对于上一步产生的词条网络得到其最大连通图G2,从而构成文本的语义结构关系图,并验证其小世界特性。
Step4:计算语义结构关系图G2中每个结点的平均路径变化量和平均簇系数变化量集合△L和 △C。
Step5:根据集合△L和 △C,将集合中排名靠前的p%个元素取出形成候选关键词。
Step6:合并候选关键词形成最终的关键词集合。
按照上述的算法处理文本,以一篇与体育有关的新闻报道为例,经过六步的处理,最终得到关键词集合为:{中国、甲A联赛、足球、比赛},我们可以将该报道的文本T1表示为KeyWord(T1)={中国、甲A联赛、足球、比赛},与新闻报导原文的内容比照,关键词组成的向量集合可以比较准确的表示文本内容。
2 基于《知网》语义相似度计算的文本相似度计算
在前面的分析中,我们认可了使用向量空间模型来表示文本的方法,但是不管是由分词直接构成向量集合,还是采用上一节中提到的文本关键词来构成向量集合,再后续的文本相似度计算中,都会把向量空间集合中的各个分量作为独立的分子来进行处理,也就是各个词语之间没有任何的联系。但众所周知,中文语义丰富多彩,很多词语可以表达相近或是相似的含义,而一个意思也可以有各种说法,也就是说构成向量空间的各个分量之间不是完全独立没有联系的,各个词语分量之间有可能存在近似的关系,同时,在计算文本相似度时,不同文本之间不同的分量也可能存在相似的情况,如果将这些相似的分量在计算时都作为不同的独立特征项对待,势必导致明明相似度很高的两个文本计算之后得到低相似度的结果,而使得相似度精度大大降低,从而影响后续的文本聚类结果。
鉴于以上原因,我们的文本相似度计算时就必须要考虑词语之间的语义相似度。我们参考文献提出的基于《知网》的词汇语义相似度计算算法,并采用了该算法所提供的DLL进行词语语义计算,从而降低相似词语对文本相似度的影响。
具体的文本相似度计算方法,在参考传统的度量两个距离的欧氏距离、余弦函数等的计算公式,提出了基于《知网》语义相似度计算的文本相似度计算算法。
具体算法如下:
Step1:文本T1表示为KeyWord(T1)={wi|wi表示T1`的第i个关键字 };文本T2表示为KeyWord(T2)={wi|wi表示T2`的第i个关键字 };
Step2 查找Keyword(T1)和KeyWord(T2)集合中词语相似度大于阈值的词语数量N。
Step3 计算N占关键词语的比率作为文本相似度的度量标准。
该算法就是通过发现两篇文本中关键词语的语义相似性,默认,如果两篇文本中的大部分关键词语相似或是相同,则两篇文本就是相似的。
3 算法验证及分析评价
我们采用文本集合{474.txt,476.txt,477.txt,7117.txt,7118.txt,8219.txt,8221.txt}来验证这种基于复杂网络理论的中文文本聚类算法。其中Q表示图的Q值表示图经过簇合并后的新的Q值。,在这个文本集合中,文本的命名代表了其不同的分类,其中凡是数字4开头的文本内容属于交通类,数字7开头的文件属于医药类,数字8开头的文件属于体育类。上述文本均取自课题组使用网络爬虫程序得到的新闻网页。
首先,对以上7篇文本进行分词,按照小世界网络模型提取关键字来表示各个文本。
其次,采用《知网》提供的计算接口程序,计算各个文本之间的文本相似度。
最后,将文本相似度达于阈值的文本之间建立连线。构成文本聚类的初始状态图。
具体参数设置:文本相似度阈值为0.18,词语相似度阈值为0.92。
构图过程是:按照文本的顺序将其序号作为其编号,结点0和结点1的相似度为0.667,则在0、1结点之间加边;结点0和结点2的相似度为0.333,则在0、2结点之间加边;结点1和结点2的相似度为0.333,则在1、2结点之间加边;结点3和结点4的相似度为0.333,则在3、4结点之间加边;结点5和结点6的相似度为0.2,则在5、6结点之间加边。其余结点之间相似度低于阈值,则不存在边。
基于图的聚类算法的处理过程如下:以“{结点,结点,…}”形式表示簇。初始化各个簇为 {0}、{1}、{2}、{3}、{4}、{5}、{6};通过计算各种合并组合的 Q值,得出簇1、簇2合并之后会使得Q值的增量最大,故选择合并簇1和2,而簇结构变为:{0}、{1,2}、{3}、{4}、{5}、{6};接下来,按照同样的标准,合并0和1,簇结构变为:{0,1,2}、{3}、{4}、{5}、{6};继续按照同样的标准,合并簇3和4,簇结构变为:{0,1,2}、{3}、{4}、{5,6};继续按照同样的标准,合并簇1和2,簇结构变为:{0,1,2}、{3,4}、{5,6},最终=0,聚类过程结束。
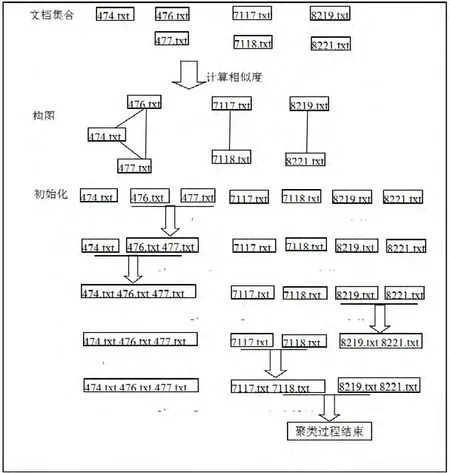
图1 基于复杂网络的文本聚类算法图解
根据上述图解的聚类过程,可以清晰地看到,最终,文档编号第一位相同的文本被归为一类,即,聚类结果与我们已知的文本分类情况完全相符。
通过分析算法执行的步骤可以分析该算法的复杂度:根据贪婪算法的原理,每次合并应该沿着使Q增大最多或者减少最小的方向进行,也就是进行合并运算的算法复杂度为。每次合并以后,对相应的元素更新,并将与簇相关的行和列相加,相关运算的算法复杂度为。因此,该算法总的算法复杂度为对于稀疏网络则为。通过理论分析可以看到该算法的复杂度是具有可行性的。
4 结论
本文主要针对在中文文本聚类的算法进行了研究,基于目前对该问题的研究现状,针对已有算法存在的不足寻找解决方案。其中将中文文本的语义特征通过基于《知网》的语义相似度算法引入到文本聚类中,充分体现了中文文本聚类算法有别于其他语言的不同之处。并利用先进的复杂网络的相关理论中与图相关的算法解决大规模海量数据聚类的效率问题。在理论研究的基础上,又通过实际的中文文本集合数据进行实际应用的测试,验证了其算法的有效性,特别是可行性。基于以上的研究,说明该基于复杂网络理论的中文文本聚类算法是可以应用于各类实际应用中。当然,该算法在细节上还有很多可改进的空间,我们会在今后继续深入研究,将该算法进一步完善优化。
[1]周雅夫,马力,董洛兵.基于SMW理论提取复合关键字系统的设计与实现.西安邮电学院学报,2007(5):82~85.
[2]Watts,D.J.and S.H.Strogatz,Collective dynamics of'small-world' networks.Nature.1998 Jun 4,1998.VOL 393: p.440-442.
[3]刘群,李素建.基于《知网》的词汇语义相似度计算.第三届汉语词汇语义学研讨会.台北: 2002.
