粒子群优化算法在Web内容挖掘中的应用与研究
2014-11-06李智勇
李智勇
(青海大学现代教育技术中心,西宁810016)
0 引言
Web数据挖掘的定义是:从Web文本和Web活动中抽取用户感兴趣的、潜在的、有用模式和隐藏的信息。Web文本挖掘常用的领域有分类、聚类、关联分析、Web主题发现与跟踪、预测分析、提取规则发现、Web内容变化规律检测、用户模型、频繁子结构发现、站点数据模式挖掘、数据集成等。
聚类算法取决于数据的类型、聚类的目的和应用,而粒子群聚类算法是基于粒子群定理实现的,同时研究表明简单的粒子群聚类算法在准确率和速度上和决策树、神经元算法是可以相媲美的。
1 粒子群优化算法(PSO)
在生物群体中个体间的竞争与合作等生物行为能产生的群体辨别能力,往往针对某些特定的问题可提供高效的解决方法。
PSO中粒子作为基本的组成单位,一个粒子代表解空间的一个候选解。设解向量为d维变量,则当算法迭代次数为t时,第i个粒子xi(t)可表示为Xi(t)=[xi1(t),xi2(t),xi3(t),…xid(t)]。其中xik(t)表示第i个粒子在第k维解空间中的位置,即第i个候选解中的第k个待优化的变量。粒子种群(population)由n个粒子组成,代表n个候选解。经过t次迭代产生的种群:pop(t)=[x1(t),x2(t),x3(t),…,xi(t),…,xn(t)]。其中:xi(t)为种群中的第i个粒子。它表示粒子在一次迭代中位置的变化即粒子在解空间的位移,Vi(t)=[vi1(t),vi2(t),vi3(t),…,vik(t),…,vid(t)]。其中:vik(t)为第i个粒子在解空间第k维的速度。适应度(fitness)函数。它由优化目标决定,用于评价粒子的性能即解的优劣,从而指导粒子群体的搜索过程。算法迭代停止时适应度最优的粒子即为优化搜索的最优解。在每一次迭代中,粒子通过跟踪两个“极值”,即个体极值pBest和全局极值gBest来更新自己。在找到这两个最优值后,粒子根据如下公式(1)、(2)来更新自己的速度和位置:

粒子群算法的基本步骤为:①种群初始化,随机给定种群的初始位置和初始速度。②粒子评价,对种群中的每一个个体计算其适应值(fitness value)。③根据适应值更新粒子的个体极值和种群的全局极值。④更新种群,根据迭代公式对每个粒子的位置和速度进行更新。⑤如果终止条件满足的话,就停止,否则转步骤②。
2 粒子群算法在Web内容挖掘中的应用研究
任何原始数据在计算机中都必须采用特定的数学模型来表示,文本数据当然也不例外。HTML语言描述的Web页面由普通文本和HTML标记构成。并且各个标记的级别是不一样的,标记的分布也有一定的规律,在使用习惯上也存在着差异。这些都是网页解析和内容提取可以利用的重要特征[3]。对于Web文档预处理,主要由以下几个步骤来完成:①解析HTML文挡,取出Web文档中的噪音;②Web文本分词;③剔除Web文档中的停用词;④特征选择;⑤生成向量空间模型,以用于进一步的Web文本聚类或其他文本挖掘工作。
在向量空间模型中,文本空间是由一组正交词条向量所组成的向量空间,每个文本表示为其中的一个范化特征向量

其中ti表示词条项,可以为词,也可以为词组,Wi(d)表示对应分量的权值。而特征项可以取字、词或短语,文本聚类算法也一般采用词作为特征项表示文本。这样这些正交词条向量就组成了一个文本向量空间,每个文本都可映射为此向量空间的一个向量:
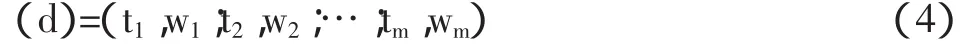
文本集合D中,di表示文本集合中的第i篇文本,ti代表文本集合中的一个特征项;t(fti,d)i表示特征项频率,定义为特征ti项出现在文本di中的次数;d(ft)i表示文本频率,定义为在文本集合D中出现过特征项ti的文本数;表示文本集合D中所有文本的总数;w(di,t)i表示特征项ti在文本di中的权重值,TFIDF权重则利用了各特征项在文本di中出现的局部特征项频数t(fdi,t)i,与在文本集合D中出现过的全局文本频数d(ft)i,进行综合加权。标准的TFIDF计算形式如下[4]:

本文的聚类方法使用的是向量空间模型。用文本中出现的词语来表示文本特征,必须以特征独立性假定为前提,也就是认为构成文本的各个词之间是相互独立的。从语料库中选出包括医疗、军事、体育、交通4类文章样本,每类30篇,共计120篇文章。
使用RostNat采集器,在全网中采集相关信息,将采集到的文档分别聚类保存,将其分离为单个文档。每个文档都表示为向量空间模型D,然后对其进行分词,进行词条化。进一步对分词进行处理,得到TDIDF权重值。将120篇文章作为文档文本集合D,集合中得每个文本di中的每个特征项目都有其自身的TFIDF权重值,显而易见的是若用所有的分词的权重值来表示该文本di,则di的维数随文本词汇的多少而确定。
为了使粒子保持运动惯性,使其有扩展搜索空间的趋势,以此探索新的区域。对基本粒子群算法的改进,即对速度更新方程加惯性权重w
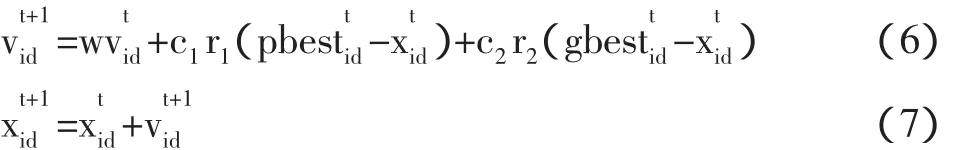
当种群大小很小的时候,陷入局部最优解的可能性很大;然而,群体过大将导致计算时间大幅增加。并且当群体数目增长至一定水平时,再增长将不再有显著的作用,本文设定种群大小为120。
惯性权重w描述了粒子上一代速度对当前速度的影响。w值较大,全局寻优能力强,局部寻优能力弱,反之,则局部寻优能力强,而全局寻优能力减弱。目前,采用较多的惯性权值是线性递减权值(linearly decreasing weight,简称LDW)策略,即

其中,Tmax为最大进化代数,wint为初始惯性权值,wend为进化至最大代数时的惯性权值。典型取值wint=0.9,wend=0.4。惯性权值w的引入使PSO算法的性能到了很大提高。每代粒子的适应度函数

来更新下一代数据的。其中pi表示属于某个类的样本数量,Nc表示类别的数量,mij则表示属于第i个类的第j个样本。
为了使文档可视化,表示为2维空间中可见的数据。必须为文档进行降维处理。本论文中所采用的降维方式为主成成分分析(PCA)方式,假设样本X1,X2,…,XN(Xi∈Rn,i=1,2,…N),则样本集所估计的协方差矩阵为:

事实上,这一组最佳投影轴应取Σ的d个最大特征值所对应的标准特征向量。将所有的30维数据通过PCA变换后得到2维数据。通过试验得知第一主成分和第二主成分的积累贡献率达到80%以上,所以本文取前两维作为聚类可视化的X维和Y维。对二维数据表示得的文档集合进行PSO,可以看到聚类的效果。
3 小结
本章通过对Web的内容挖掘的模型实现,实现对采集到的文档分别聚类保存。Web内容挖掘首先要获取内容,通过HML的文档树分析采用Map/Reduce进行原始数据清理,然后通过Hive对数据分析构建粒子群聚类模型,实现对样本数据的挖掘生成粒子群模型。使用RostNat采集数据,将采集到的文档分别聚类保存,将其分离为单个文档。生成的每个文档都表示为向量空间模型D,然后对其进行分词,词条化,根据特征进一步对分词进行处理,得到TDIDF权重值。通过实验仿真,提出参数修改方案,对PSO聚类效果进行实现,对于文本聚类的稳定性和收敛性的得到了较好的聚类效果。但对于其收敛性还没有得到彻底解决,对整个算法进行优化,提高了数据挖掘的效率。
[1]林士敏,田凤占.粒子群网络的建造及其在数据采掘中的应用[J].清华大学学报,2001,41(1):49-52.
[2]张学明,施法中.分布式并行Web数据挖掘系统的研究与实现[J].计算机工程与应用,2002,4(1):198-200.
[3]于满泉,陈铁睿,徐洪波.基于分块的网页信息解析器的研究与设计[J].计算机应用,2005,25(4):974-976.
[4]陈博.WEB文本情感分类中关键问题的研究[D].2008:49-53.
