基于音频的视频拷贝检测
2014-10-20赵花婷王明敏
赵花婷,王明敏
0 引言
随着高速网络的普及,视频分享类网站取得了巨大的成功。大量的用户上传并分享数以亿计的视频,这些视频通常时长较短,并且有相当多的视频在内容上差异非常小,仅仅在清晰度、LOGO或字幕上略有不同。这类无意义的重复视频造成了不必要的冗余,给视频网站的运营者带来了巨大的存储成本。另一方面,有线电视运营商无论是为满足节目审查的需要,还是实现点播回看节目等方面的功能,均对于高效的视频的拷贝检测技术都有强烈的需求。因此,视频序列的拷贝检测具有很大的理论意义和应用价值。
一般而言,视频序列包括两部分的内容,即图像序列和音频序列。相当大的一类方法以检测图像的特征为基础。这类方法从图像序列中提取一种特征,从而为某个特定的视频片段赋予一个唯一的签名,然后通过某种特定的映射方法(如Hash)存储起来。
有研究者提出了视频指纹的概念并应用哈希函数进行视频认证。他们根据在时空区域上划分网格的亮度变化提出了一个时空指纹。基于离散余弦变换(DCT)提出了两个应用在视频上的哈希算法[1]。用序数度量(ordinal measure)方法[2]计算图像的匹配度的算法被应用在视频上[3]。上述方法的主要缺陷是在处理像插入商标、偏移或裁减这些在电视后期制作中经常出现的情况时不具有鲁棒性。
也有其他一些学者提出了基于数字水印技术的方法,通过在视频中植入图像水印或者音频水印来进行拷贝检测。然而这种方法需要在原始视频中植入水印,多被用作企业级视频产品的防盗版措施,并且在鲁棒性上也有不足之处。
[4]中以视频的音频特征为基础,使用计算机视觉方法对音频信息提取特征并建立音频特征库[4],具有存储小、准确度高、时效性强等诸多优点,针对性解决了广告检测问题。本文在文献[4]的基础上,提出了一种增强的算法,该算法不但有效地解决静音段下视频序列检测不准的问题,还进一步地将算法的应用对象扩展到一般短视频序列。
1 基于音频匹配的视频检测算法
一般情况下,音频相对于图像来说,是更加稳定的特征。本文的算法首先基于音频特征进行初步的视频拷贝检测检测,并对检测结果进行修正,我们在[4]中已完成该部分工作。尽管该方法可以得到准确的视频拷贝片段,相似的音乐却可能出现在不同的视频中,比如,电视剧的配乐出现在广告配乐中,这样就会导致误检。此外,静音段也会造成不正确的匹配。
本文主要利用图像特征来解决由音频匹配检测引起的问题,采取两种策略对容易被误检的片段进行处理(其中使用音频方法初步判定为目标序列的拷贝的视频片段称为候选序列):(1)对于处在候选序列或非候选序列内部的被误检的片段,本文采用平滑的方法来解决;(2)对于处于候选与非候选序列边界上的片段,由于这些片段可能会被误检,本文利用图像特征进行精确定位。不同于[5],本文采用图像特征辅助音频特征进行边界定位,实验结果表明利用简单的图像特征即可得到非常精准的边界。本文算法以[4]为基础,第一阶段提取待测视频流的音频信息,以音频作为视频流特征,将音频转化为图像;第二阶段以计算机视觉的识别技术解决音频拷贝检测问题;最后阶段在[4]的检测结果基础上,通过对静音段和边界使用图像特征切变算法确定最终的拷贝检测结果。具体流程如图1所示:

图1 视频拷贝检测算法框架
[4]中涉及的前两个阶段主要是采用文献[5]中音频匹配的算法进行视频拷贝检测,算法包括两部分:1.提取音频特征,建立和维护音频特征库;2.提取待测视频流中的音频特征,并在音频特征库中进行局部哈希检索。
1.1 提取频谱图的特征提取音频特征
该算法首先采用短时傅里叶变换(STFT)[6],以0.372秒的窗口和 11.6毫秒的步长将音频转化为时频域上的声谱图。STFT把频率在300HZ到2000HZ的音频信号映射到33个对数空间的带宽上。短时傅里叶变换可写作为公式(1):

其中x(t)是原始音频数据信号,w(t-τ)是窗函数,X(t,ω)是 w(t - τ) x(τ)的傅里叶变换。窗函数随时间t滑动,原始信号只留下窗函数截取的部分做最后的傅里叶变换。经此得到时频域的声谱图。
接着采用一组滤波器对声谱图进行滤波编码,要求编码后的数据不但保留了足够的信息用于区分不同源的音频,又能对同源音频提供鲁棒的响应。为满足上述要求,这里使用Viola Jones提出的Haar小波滤波器[7]。
对声谱图使用计算机视觉的匹配算法解决声谱图匹配的问题,即解决了音频对应视频流的匹配问题。正如大多数图像匹配问题一样,需要对声谱图提取局部特征,这里采用Haar特征。用于提取Haar特征的滤波器在频带位置、带宽和时长上都不尽相同,使得候选滤波器的数量大约有25000个之多。
为从众多候选滤波器中选出最佳滤波效果及最佳数量的滤波器,该算法设计了一种非对称boosting方法[8],选出M (=32)个最优的滤波器及其相应阈值。进而使用分类器来判定两段音频是否来自于同一段音频(即是否同源)。分类器定义为公式(2):

其中x1,x2表示两段音频对应的声谱图,当x1,x2同源时y =1,反之y=-1。分类器H由M个弱分类器hm(x1,x2)及对应可信度cm组合而成。每个弱分类器包含一个滤波器 fm及阈值tm,使得公式(3):
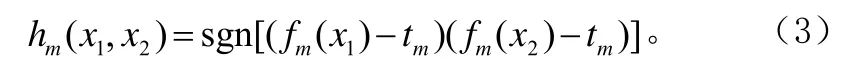
这样,当采样空间足够大时,至少有一半的负样本会被错误的判为匹配。为此采用一种非对称成对boosting算法,其只对错误匹配的正样本在迭代过程中更新权重,并把正样本和负样本的权重分别各自归一化到 0.5.所有M个弱分类器hm(x1,x2)的线性组合得到最终的强分类器H(x1,x2)。分类规则为公式(4):

当该弱分类器的错误率εt为0.5时,表示其对最终结果没有贡献,应该被丢弃。
经不对称boosting方法后,获得M个滤波器 fm及阈值tm,可针对每帧滑动窗口计算出一个M比特的特征描述子。以该特征描述子的集合构建音频特征库。
1.2 检索匹配
在该阶段对实时视频流以相同的方法得到其特征描述子。为音频特征库建立标准哈希索引[9],然后用输入视频的特征描述子在特征库中进行相似性最近邻检索[10]。
对于待测视频的音频信息,按时间顺序截取前m秒音频,对其进行图像化,特征描述子提取,以此在音频库中检索,根据检索结果对该m秒视频进行候选或非候选序列的标记;此后,在音频信息相邻下个m秒做同样操作,直至音频序列的末尾。本文参照[4],设置m为3秒,以保证音频匹配算法的稳定。
2 边界精确定位
在上一阶段,我们得到了候选与非候选序列的粗糙边界。但是由于非同源视频的音乐在一些情况下可能具有相似性以及静音段的出现,导致采用音频特征匹配后的结果存在误检的情况。本阶段将对这些粗糙边界做进一步地精确定位。
2.1 静音段段问题
由于不不同视频均有可可能出现静音,此此时无法通过音音频信息对视频进进行分析,所以在静音段处容易易误检,如图2所示:

图2 静音段段对应与不同视频频序列
静音段段会在不同的视视频中出现,其中中左列上下两幅幅分别为wav声声波图,其中红红色方框中的是静静音段;右侧上上下分别为与左侧侧 wav声波中静音段相对应的的视频序列。从从图中可以看出,同为静音段,却对应不同的视频序列。对于于这些由静音段造造成误检的情况况,本章将给予一一定的策略进行行处理,从而消除静静音段造成的误误检。
2.1.2 静音音段检测
获得WAV格式的音音频信息,首先先截取一段查询询音频,将该音频转转换成单通道,然后对频率进进行下采样,如此此得到样本。然后后对得到的样本本统计其功率和,从而得到该查查询片段的能量值值为公式(5):

其中PPk表示第将k个个的功率,共有s个个样本。该能量量值E与阈值threshhold比较,判断断该查询片段是是否为静音。经经过大量测试发现现,threshold=0.001即可将音音频中原有的静静音段检测出来,又不至于对非非静音段造成误误检。
2.1.3 静音音段处理
事实上上,静音段存在在于2种位置:内容连续的视频频序列中,不同源源视频序列的边边界处。非同源视视频序列中的静静音段很容易被误误检为候选片段段,如此会影响视视频拷贝检测结结果的准确率。为为了消除静音段段造成的误检,本本文采用以下策策略对静音段进行行处理。如表11所示:

表1 静音段处理方法
表1中中左图红色段表表示静音段,左上上图中绿色段代代表静音段前后同同源视频序列;左下图中绿色段段和蓝色段分别别表示非同源视频频序列。对两种种不同的情况分分别做出以下处理:
2.2 边界定定位
只利用音频特特征精确定位边边界主要有以下下几个难点:(1)边界界处出现相似的的音频导致视频频序列无法正确确分割边界,(2)视频频边界处截取的的3秒音频段中中包含静音段,这这类视频序列的匹匹配很容易出错错。
为此,本章节节采用图像特征来来解决精确定位位视频序列边界的的问题。由于非非同源视频序列边边界处前后两帧帧的图像特征通常常具有剧烈切变变,我们据此来来判断边界位置所所在。统计图像特特征切变的方法法有很多,例如如:镜头分割方方法、聚类法、差分分法等。本文是是在边界静音段段内寻找最大切变变,采用最常规的的差分法即可满满足实用要求。该方法的目标标为公式(6):
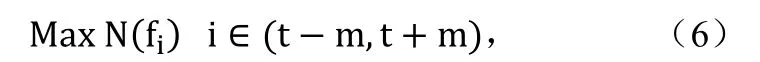
这里只需计算算从第t-m帧帧到第t+m帧之之间的相邻两帧图图像能量的变化化值即可,其中中m取值为45(不不同m值对边界定定位的影响将在在实验结果部分分给出,详见表表 3)。最后判定图图像能量变化值值最大的地方即即为最后的边界界。
为了加速处理理过程,首先将将图像的尺寸缩小为20×20,然后后计算缩小后的的图像的能量值值,图像能量值的的计算方法如下公公式(7):

其中Ei表示第第i帧的能量值,n表示整幅图的的像素点个数,gi表表示像素j的灰度度值。
采用该方法进进行边界微调后后的效果图如图3所示:

图3 边界微调前后的的定位结果比较
其中第一行是是一组视频图像像流;第二行中红红线所示位置是修修正音频匹配结结果后得到的边边界,蓝线所示位位置是边界微调之之后得到的边界界。从图中可以以看出,尽管经过过音频定位后得到到的边界已经非非常接近实际边边界,但是仍然存存在误差。本文采采用图像特征进进行边界微调之之后,边界结果与与真实值相吻合。。
3 实验结果
本文的实验是是在广告视频数数据集上进行的的。该数据集共包含含约11000条短短视频,平均时时长大约为14秒秒,该视频集组成成了本文的样本本库。本文所用的测试视频和样样本库中均为mppeg2-ts格式的实实时视频。
本文采用引文文[11]中的方法计计算查准率和查查全率,其中:
查准率 = 检检测到的正确时长长/检测到的总时长(8)
查全率 = 检检测到的正确时长长/标准总时长(9)
基于音频匹配配阶段处理后,我我们会得到很多多错检的片段,本文文采用类似处理理静音段中表 11第一行的方法法在合并候选序列的同时对这些候选序列夹杂的噪声即错检片段进行修正。第一行表示的是修正错检片段后的查准率和查全率如表2所示:

表2 视频拷贝检测各阶段检测结果
由于音频匹配而错检的片段不仅存在于同源视频序列的内部,也可能存在非同源视频序列之间。针对这一类型的片段,本文利用图像特征对边界进行微调。表2中的第二行表示的是采用图像特征进行边界精确定位之后的查准率和查全率。
从表2中可以看出,在利用图像特征进行边界微调之后,查准率和查全率都有所提高。由于经过边界微调之后,在非同源视频边界处的误检片段会被修正,提高了正确检测结果的时长,根据公式(8)、(9)可知,查准率和查全率也随之提高。
在利用图像特征进行边界微调时,在已有检测边界基础上,搜索真实边界的前后搜索的阈值范围非常关键。如果阈值偏小,则检测范围不会包括真实边界;如果阈值偏大,则可能会包括同源视频内部镜头切变带来的剧烈变化,如此得到的边界可能不会是真实边界。本文选取了6个阈值,在3个小时长度的测试数据上进行实验,得到了不同的阈值对应的最小误差帧数、最大误差帧数和平均误差帧数,结果如表3所示:
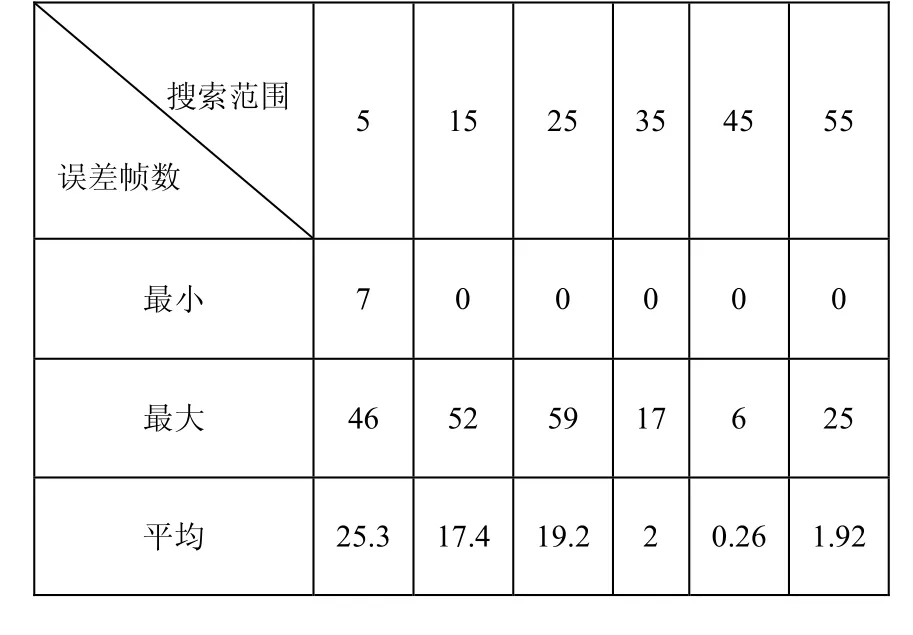
表3 边界搜索范围阈值与误差帧数的关系
当阈值偏小时(如15帧),搜索范围可能无法覆盖真实边界,仍然造成误检;当阈值偏大时(如55帧),搜索范围内或将把连续视频内部的正常镜头切变作为非同源视频序列边界,造成误检。当阈值取45时,得到的边界平均误差最小,可作为搜索范围的参考值。
4 总结
本文提出的长视频中的短视频拷贝检测算法,可以很好地应用在广告检测中。该算法分为3个阶段:首先,提取视频流的音频分量,将音频信息转化为图像信息用作提取特征;其次,提取音频图像特征,进行初步的匹配检测,得到一个粗糙的检测结果;最后,采用图像特征对粗糙结果进行精确边界定位。我们主要采取两种策略精确定位边界:(1)对于同源视频序列内部的被误检片段,采取平滑的策略,将这些误检片段归类为该同源视频。(2)对于边界处的片段则利用视频的图像特征进行边界定位。实验结果表明,经过这两种方法处理后,我们可以准确地得出边界。
[1]Coskun B,Sankur B, etal.Spatio-temporaltransform-based video hashing.[J]IeeeTrans- actions on Multimedia,8(6):1190-1208, 2006.
[2]BhatD and Nayar S.Ordinal measures for imagecorrespondence.[J]ieee Transactions on PatternAnalysis and Machine Intelligence, 20(4):415-423,1998.
[3]Mohan R.Video sequence matching.In Int.Conference on Audio, [c]Speech and SignalProcessing,1998.
[4]赵花婷,王明敏.一种基于音频匹配的广告检测算法[J].计算机与现代化,2014 Vol.0(2):1-5.
[5]丁汝一,杨宁,董道国.音视频相结合的广告检测算法[J].计算机工程与应用,2012,48(22)184-188.
[6]JURADOF, SAENZJ R.Comparison between discrete STFT and wavelets for the analysis of power quality events.[J]Elect.Power Syst.Res.vol.62, no.3,pp.183-190.2002.
[7]SCHAPIRER, SINGERY.Improved boosting algorithms using confidence-rated predictions.[J]Machine Learning,37(3), 1999.
[8]VIOLAP, JONES M.Rapid object detection using a boosted cascade of simple features[C].Proceedings of Computer Vision and Pattern Recognition, 2001.
[9]GIONISA, INDYKP, MOTWANIR.Similarity search in high dimensions via hashing[C].In Proceedings of International Conference on Very Large Databases, 1999.
[10]INDYKP, MOTWANIR.Approximate nearest neighbor-towards removing the curse of dimensionality[C].Proceedings of Symposium on Theory of Computing,1998.
[11]ZIBERT J, et al.The COST278 Broadcast News Segmentation and Speaker Clustering Evaluation - Overview Methodology, [c]Systems, Results.Interspeech 2005.
