语音声学参数自动标注/提取系统简介
2014-10-15周学文
周学文,呼 和
(中国社会科学院民族学与人类学研究所语音研究室,100081)
1 问题的提出
语音语料库建设是实验语音学基础研究的主要方向,在刻画(目标语)全面的语音特征、研究语音演化和语言亲属关系、发音机理和协同发音、濒危语言保护等方面具有重要意义,能够有力推动语音本体描写研究和言语工程研究。按照使用目的,语音语料库可分为面向基础研究和面向应用两大范畴,前者包括声学、语言产生、言语感知、韵律等,后者包括语音识别、语音合成、人机交互技术等。国际上主要的研究和发布语音数据库的机构有ELRA(欧洲语言资源协会)、ESCA/ISCA(欧洲/国际言语通讯协会)、LDC(语言数据联盟)和 Oriental COCOSDA等。欧洲共同体上世纪90年代初建立了基于欧洲7种语言的语音数据库研究计划“EUR-ACCOR”,目的是建立欧洲共同体7种语言的语音声学参数和生理参数数据库。国内也开发了大量规模和目的不一的语音数据库,如中国社会科学院语言所开发的汉语口语语音库、语音识别语音语料库RASC863、儿童语言习得语音库和中国英语学习者语音特征的数据库ESCCL等。除了中国社会科学院民族学与人类学所外,尚未有开发面向基础研究的中国少数民族语语音声学参数数据库的报道。
为了有效使用语音语料库,必须对其内容进行标注。根据语音语料库的内容和目标,语音标注分为音段标注和韵律标注,二者的标注内容有很大不同。广泛使用的标注系统有用于英语韵律标注的ToBI(Tone Break Index)系统和由此扩展而来的J-ToBI(日语)、K-ToBI(韩语)和C-ToBI(汉语普通话)等。C-ToBI系统的标注层次主要包括语调特性、停顿边界、强调与重音、拼音转写、调类号、汉字等,并不包含用于基础研究的语音声学参数的全部信息。目前语音学界也没有统一的语音声学参数的标注格式和标注系统,必须根据各自的研究目的开发各自的标注格式和标注系统。
为了摈弃传统小作坊式的语音声学研究方法以及缺乏统一标准、缺乏比较基准、缺乏数据延续性、缺乏全面性的弊端,自上世纪90年代初开始,中国社会科学院民族所语音研究室在国家自然科学基金、国家社会科学基金项目、教育部和社科院科研局的资助下,与少数民族地区大学和研究所合作完成了“藏语拉萨话语音声学参数数据库”(国家自然基金项目,1991年)[1]、“哈萨克语语音声学参数数据库”(国家自然基金项目,1992年)[2]、“蒙古语语音声学参数数据库”(自然基金项目,1992年)[3-4]等项目。2006年提出“中国少数民族语言语音声学参数统一平台”建设思路[5],在教育部的资助下,已完成了“藏、维、彝、鄂温克、鄂伦春、达斡尔等语言的语音声学参数数据库”[6],目前正在实施“锡伯语语音声学参数数据库”“土族语语音声学参数数据库”和“东部裕固语语音声学参数数据库”等的研制工作。
尽管通过二十多年的语音声学研究工作建立了一些少数民族语音声学参数语料库并积累了丰富的研制经验,但是声学参数采集工作仍然非常艰难。这是因为仅仅依靠手工标注和采集,一方面,工作量大,错误率高,效率低,无法保证实验方法和实验数据的可重复性,更无法实现语音声学研究工作的规范化和标准化;另一方面,由于声学特征定义及其提取方法和标准难以统一等原因,导致了语言之间难以相互比较,研究成果无法相互借鉴的后果。为了避免上述弊端,必须解决语音声学参数数据库研制工作的自动化问题,语音声学参数自动标注和提取是首先要解决的问题。
2 方法与步骤
针对以上问题,必须设计出全面稳妥的解决思路。经过分析和讨论,解决方法分三个方面:
第一,设计完备合理的标注文件。该文件必须能够存储和计算得到全部的声学参数,包括功能性参数和声学特征参数,并且方便用户操作。
第二,开发自动标注软件。用户只需要在标注文件选定少量位置,执行该软件就可得到所有声学参数,用户只需要校对、修改和确认。
第三,开发自动提取软件。系统可一次性将所有已标注的文件经逐个计算,得到所有参数后存入到一个文本文件中,然后用户导入EXCEL就完成了声学参数库的建立。
标注文件和自动标注/提取系统是在语音学界广泛使用的语音分析平台Praat 5.2.23版本上开发的[7],音标编码使用改进的 SAMPA-C编码,所有使用Praat进行语音分析和语音声学语料库建设的用户均可使用本系统。
3 语音声学参数自动标注/提取系统
语音的声学特征是实验语音学主要的研究成果,语音声学特征参数是描写和刻画语音的音素(元音、辅音)、音段(音节、词等)和超音段的重要手段,比如元音音色主要由其前三个共振峰决定,对声调语言,音高值及其变化决定了调类和调值,VOT(Voice Onset Time)可以较好区分塞音与塞擦音中的塞/塞擦、送气/不送气、清音/浊音等特征,谱重心可以区分某些擦音等①每个声学特征的具体含义,可参考相关的实验语音学书籍。
3.1 功能性字段集和声学特征参数集的设计
完整而系统的功能性字段和声学特征参数集是实现语音声学参数自动标注/提取以及开发参数查询统计平台的重要前提。通过二十几年的努力,中国社会科学院民族所语音研究室已探索出统一的11个功能性字段和36个声学特征参数。这些特征集具有确定性、唯一性、全面性和权威性等特点,能够涵盖所有少数民族语言的语音特征。其中,功能字段用于查找、统计和分类每一种语言、每一个词、每一个音节中每一个音段的每个声学参数,因此必须包含足够的信息量。功能性字段分词层、音节层、音段层、发声类型层和声调类型层等5层11个字段,如表1所示。
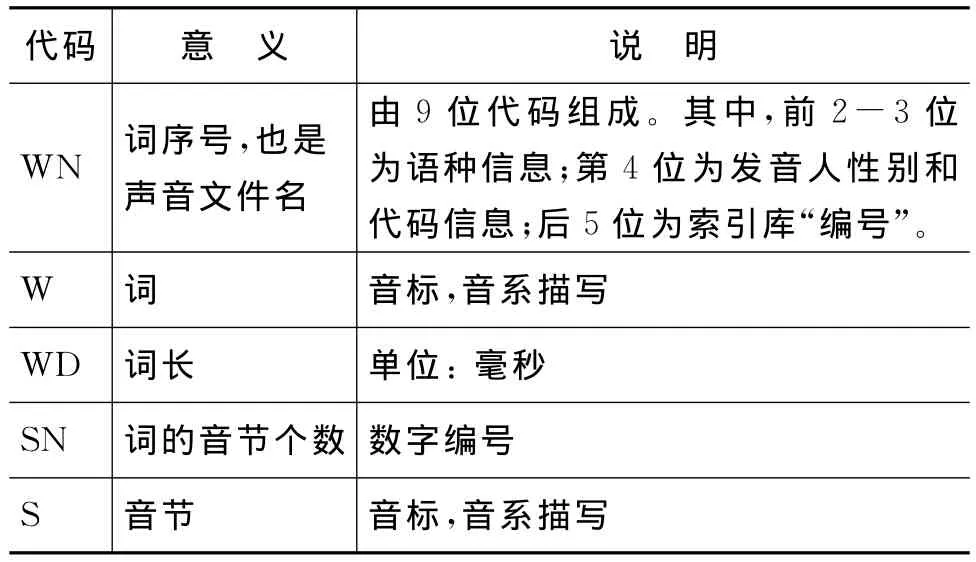
表1 功能性字段集

续表
声学特征参数负载着音段所有的声学特征信息,是观察了解音段特征及其变化的密钥,是语音描写研究的基石。为了对不同语言音段或超音段特征之间进行比较研究,需要设计一套统一的声学特征参数集。表2为元音声学特征集及其定义,表3为辅音声学特征集及定义,表4为韵律特征集及其定义。

表2 元音声学特征集及其定义

表3 辅音声学特征集及其定义

表4 韵律特征集及其定义
3.2 自动标注软件
为了对声学参数进行标准化标注和自动提取以及减少人工标注的随意性,在提出八层标注文件结构(请见表5)的同时,制订了归一化的标注标准和标注点。该结构涵盖了音段和超音段主要声学特征。标注方法如下:在Praat环境下将标注文件与语音文件同时打开后,用户按照统一的标注标准和方法,选定少量标注位置,执行自动标注软件,系统就能把具体值自动标注到所选位置上,用户只需校对、修改和确认即可。有了该系统,语音实验人员可以把主要精力集中到语音特征的分析和比较上,不再为手工填写大量数据而发愁。这样既减少工作量,又降低错误率。表5为标注文件结构。
下面简单解释表5中每层的填写内容、选点规则及取值含义。
第一层为音素层,采用音素记音法,以实际发音为准,用SAMPA-C码标注。如果实际发音为目标语言的非典型变体,则该层的音标与第二、三层的音标可能不同。
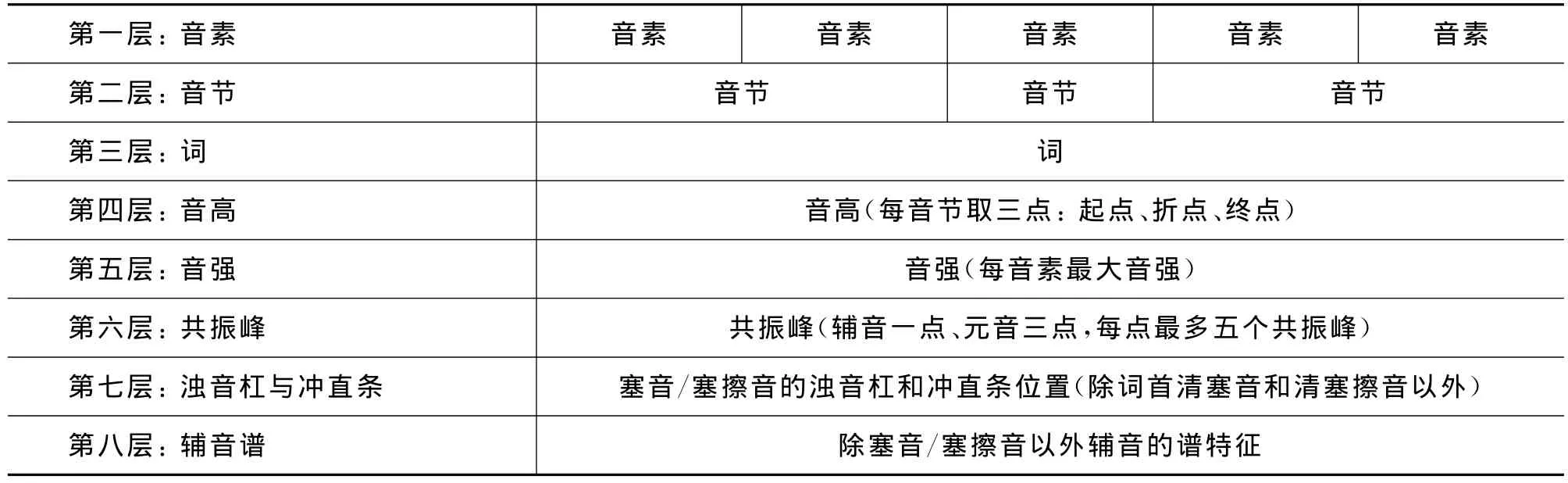
表5 八层标注文件结构(以一个3音节5音素词的标注结构为例)
第二层为音节层,采用音位记音法,根据目标语言的音位系统,用SAMPA-C码标注。
第三层为词层,也采用音位记音法,根据目标语言的音位系统,用SAMPA-C码标注。
第四层为音高层(韵律层)。该层的标注方法:以音节为单位,每个音节自动取音高曲线的起点、折点和终点等三点,如果没有折点,则取起、终两点。其中,折点为音高曲拱的明显转折点,既包括H-LH型,也包括L-H-L型以及音高斜率的剧变点。至于斜率的剧变如何定义,阈值是多少,目前由用户根据经验判断和选择,在该软件的升级版本中将会由系统自动实现。
第五层为音强层,以音素为单位,每个音素取一点。其中,对元音,选其最大音强;对塞音和塞擦音,选其冲直条上的音强。因为该处音强可以表征冲直条的强弱;对其他辅音,如擦音、鼻音、边音等,选辅音的前三分之一处的音强,因为该处辅音已达到了发音的目标位置。本软件已实现音强的自动标注功能。
第六层为共振峰层,对元音,如果共振峰呈水平走向,则可以只选一点,即目标点,否则选元音起始(前过渡)、目标和结尾(后过渡)等三点;对塞音和塞擦音,选冲直条上的共振峰;对其他辅音,如擦音、鼻音、边音等,选辅音的前三分之一处的共振峰。因为该处辅音已经达到了目标位置;无论元音,还是辅音,系统对每个点自动提取最多5个共振峰。本系统采集共振峰的依据是LPC分析线,因此为了确保共振峰参数的准确性,用户标注共振峰位置时应尽量避免LPC分析线上的野点(错误)。为了校对和确认系统自动采集的参数值,用户必须提前掌握目标语言音位系统和每个音段大致的声学表现,特别是共振峰模式。另外,用逗号代替所缺省的共振峰。如共振峰串 ,660,,2 200,系统解释为F2=660,F4=2 200,F1和F3空缺。共振峰点的自动选择问题,已在该软件中解决。
第七层为塞音/塞擦音的冲直条和浊音杠层,对词首清塞音/清塞擦音,因冲直条与词的左边界重合,故不标注。但要标注词首浊塞音/浊塞擦音的冲直条,不标注其浊音杠起始点(其浊音杠起始点与词的左边界重合);对非词首塞音/塞擦音要标注冲直条和浊音杠。其中,如果标注一点,系统则认为是冲直条(清)。如果标注两点,系统则认为:第一点为浊音杠,第二点为冲直条(浊)。这些点的具体含义解释均由系统自动判断,用户只需标注具体位置即可。在该软件的升级版本中,将能够实现全自动标注。
第八层为辅音谱层,系统自动计算除塞音/塞擦音以外辅音的谱特征,包括谱重心(单位赫兹)、相对于谱重心的谱偏移量(单位赫兹)和偏离度(低于谱重心的谱与高于谱重心的谱之比)。该层参数是根据熊子瑜博士的提议新增加的。主要用于描写辅音特征,特别是擦音、鼻音、边音等的谱分布区别特征。通过实验比较,最后选定从辅音中间三分之一部分中提取辅音谱,这样能够最大程度地反映该辅音的谱特征并减少其前后音素的影响。通过东部裕固语少量词的实验,发现该语言擦音[s]和[ʃ]的谱重心差别较大,可以达到1 500赫兹。其中前者约为7 000赫兹,后者为5 500赫兹左右。
在以上八层标注层中,前三层(音素、音节和词),采用界面层(interval tier)标注,后五层采用点层(point tier)标注。
图1为对东部裕固语Sk_h@n一词进行自动标注的界面。界面中的参数都是自动提取的。

图1 自动标注软件版本1.0运行界面
3.3 自动提取软件
在运行上述自动标注软件后,每个声音文件(发音词)都形成一个同名的文本标注文件(TextGrid)。自动提取软件将对这些标注文件进行批量自动处理,最后生成一个文本文件(.txt),只需要手工几步即可导入EXCEL表格,就生成了用户声学参数库。图2为自动提取软件的运行界面。
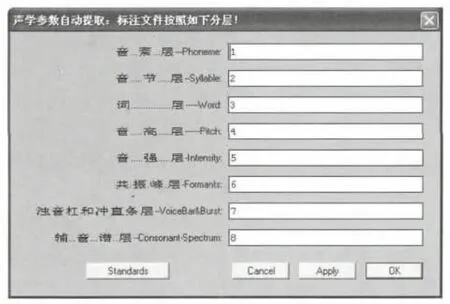
图2 自动提取软件运行界面
自动提取软件是一款高效而稳定的软件,它主要完成如下工作:(1)根据SAMPA-C码定义,判断音素的元音/辅音属性。如果是辅音,还要判断其清/浊,塞音塞擦音/非塞音塞擦音属性;(2)根据音节内音素的组合,判断音节类型并得到类型号,音节位置和数量,词/音节/音素长度,将音高值赋予音素,将共振峰值串(可能有逗号分隔的缺省值)分解得到F1-F5,并根据元音/辅音属性,分别赋予各自的共振峰,将音高赋予音节的属性;(3)根据第七层的冲直条和浊音杠标记,与第一层的音素进行匹配,根据词首/非词首、清/浊属性,将各个标记解释为冲直条或浊音杠,计算得到GAP、VOT和音长,再赋值给音素;(4)第八层将计算得到的辅音谱特征值赋予辅音等等。
该软件具有一定的灵活性,可以处理二音高值/三音高值、有缺省值的共振峰值串、一点/三点共振峰、自动判断冲直条或浊音杠、处理输入的多余空格和回车符等。
4 语音声学参数自动标注/提取系统的意义和作用
目前自动标注/提取软件已投入使用,并得到了语音声学实验研究者们的赞同和认可。该系统具有标准统一、数据完整、简单高效、可校对、能容错的特点。与手动采集声学参数相比,能够减少大量的填写数据的工作量,减少人工标注的随意性,既减少工作量,又降低错误率,能够有效提高语音声学参数库研制效率,确保实验方法和实验数据的可重复性。
在上述工作的基础上,系统将实现冲直条和浊音杠位置的自动标注,进一步提高自动化程度,并逐步实现语音声学参数数据库研制工作的全面自动化目标,从而推动语音声学参数数据库研制和语音声学实验研究工作的规范化和标准化。
[1]鲍怀翘,徐昂,陈嘉猷.藏语拉萨话语音声学参数数据库[J].民族语文,1992,(5):10-20.
[2]Huai-qiao BAO.An acoustic parameter database of speech sound of Kazakh and harmony theory of vowel[C]//Oriental COCOSDA'99,Second International Workshop on East-Asian Language Resources and E-valuation,May 13-14,Taipei,Taiwan,1999:82-86.
[3]呼和,鲍怀翘,陈嘉猷.关于“蒙古语语音声学参数数据库”[J].Journal of the altaic society of korea,ISSN 1226-6582,1998,12:201-210.
[4]呼和,陈嘉猷,郑玉玲.蒙古语韵律特征声学参数数据库[J].内蒙古大学学报(哲学社会科学汉文版),2001年,21:39-43.
[5]周学文,郑玉玲,呼和.“中国少数民族语言语音声学参数平台”简介[C]//COCOSDA2009,北京,2009年8月,2009:24-128.
[6]Huhe,Zhouxuewen,Wurigexiletu,Hasiqimuge.A-coustic parameter databases of daur,evenki,oroqen nationalities[C]//COCOSDA2011,台湾,2011:78-82.
[7]熊子瑜.Praat语音软件使用手册[M].北京:中国社会科学院语言研究所,2004.
[8]李爱军,陈肖霞,孙国华,华武,殷治纲.CASS:一个具有语音学标注的汉语口语语音库[J].当代语言学,2002,(2).
