基于条件随机场的敏感话题检测模型研究
2014-09-29翟东海崔静静聂洪玉
翟东海,崔静静,聂洪玉,于 磊,杜 佳
(1.西南交通大学信息科学与技术学院,成都 610031;2.西藏大学工学院,拉萨 850000)
1 概述
敏感话题检测是网络舆情检测技术中的重要子课题,通过敏感话题检测能够将网络中涉及的暴力、色情和非法煽动等信息及时发现并监管,对于维护网络健康发展和社会稳定有着极其重要的影响。因此,敏感话题的检测对于及时把握舆情动态、积极引导健康的社会舆论有着重大的作用和意义。文献[1]提出的话题识别与跟踪算法能够发现和追踪文本流中的重要信息;文献[2]提出一种基于衰老理论(aging theory)的热点话题检测方法,可以有效发现一段时间内BBS上的热点话题;文献[3]提出和实现的双语Web内容过滤智能分类引擎,能够识别包含色情信息的中文和英文网页。文献[4]在动态知识库中构建了一颗动态层次语义树,随着敏感文本的不断到来,动态更新语义树。现阶段国内外对敏感话题检测的研究虽然已经取得了一定的进展,但是完全针对敏感话题检测的算法还有待完善,精确度也有待提高。
敏感话题通常包含态度倾向性,且具有一定的先验知识,因此,如何有效利用这些先验知识来判断网络文本的敏感性是敏感话题检测的研究难点和热点。在充分利用条件随机场强大的知识拟合能力的基础上,本文提出了一种基于条件随机场的敏感话题检测模型。首先介绍敏感话题类别和待测文档的表示方式,然后对敏感话题检测的条件随机场模型进行研究,在此基础上实现待测文档的的敏感性标注。
2 敏感话题检测模型
在文献[4]中,敏感话题被定义为不利于社会稳定的言论,一般包括暴力类、色情类和其他。敏感话题通常具有一定的先验知识,并且包含态度倾向性的特点,因此,敏感话题检测方法不同于传统的话题检测方法[5]。条件随机场是一种概率图模型,具有强大的知识拟合能力[6],可以将敏感话题的多个特征联合考虑,实现网络中敏感文本的快速发现。本文中敏感话题检测主要包括2个部分,网络文本的表示和敏感文本的识别,针对敏感话题已有的先验知识,结合CRFs模型,本文提出了基于CRFs的敏感话题检测模型。在获取网络文本后,结合敏感词汇库中的种子敏感词完成网络文本的表示,然后通过训练好的基于CRFs的敏感话题识别模型来对文本的敏感度进行估计,当敏感度的可信度超过阈值θ时,就可以判定该文本是否为敏感话题以及其所属敏感话题的类别。本文的整体实现框图如图1所示。

图1 基于CRFs的敏感话题识别框图
3 网络文本和敏感话题类别的表示
3.1 网络文本的表示
对通过特征提取后,在本文的CRFs敏感话题识别模型中,将待检测的文本表示为CRFs模型中的观察序列进行处理。在众多话题表示方法中,VSM(Vector Space Model)和 TF-IDF(Term Frequency Inverse Document Frequency)是一种非常有效的话题表示方式。由于敏感话题通常会涉及一些固有的敏感词汇,如“上访”、“拆迁”等,和一些包含态度倾向性的词汇,如“邪恶”、“屠杀”等,因此在对网络文本进行话题表示时,需要尽量将一些重要的敏感词汇和能代表作者态度的倾向词提取到特征词中。文献[7]在传统的TF-IDF公式中增加了倾向性因子来提高特征抽取的效率,本文借鉴这种思想,将该倾向性因子改造为敏感性因子。这样,文本中第i个词项(itemi)的权重(weighti)计算公式如下:
weighti=TF(itemi)·lb(IDF(itemi))·γi(1)其中,TF为词频;IDF为逆文档频率;γi为敏感性因子。文档中的第i个词项的敏感性因子γi被定义为该词语与敏感词汇库中各个种子词的点互信息(Pointwise Mutual Information,PMI)的平均值:

其中,N为敏感词汇库中种子敏感词的总数。在该计算方法中,最主要的是计算词语间的关联度,即通过计算特征词与敏感词汇库中种子词的点互信息PMI得到:

其中,p(word1&word2)表示word1和word2在语料中同时出现的概率;p(word1),p(word2)分别表示word1和word2在语料中独立出现的概率。
待检测文本d中的每个特征词项itemi由具有3个属性的三元组表示,这3个属性值包括该词项权重(weighti)、敏感性(polarityi)、词性(part-ofspeech,posi)。其中,敏感性(polarityi)的值等同于敏感性因子 γi,词性(posi)的获得方法参见文献[8]:

将所求得的待测文本d的特征项项依据其weight值的大小降序排列,并从中选取n个特征项组成一个特征词项序列用来表示待测文本:

3.2 敏感话题类别的表示
在CRFs敏感话题检测模型中,通过特征选择的方法,结合敏感词汇库,选取敏感文本中区分能力较强的敏感特征词项,从而将敏感话题的类别表示为CRFs模型中的状态序列。根据描述内容的不同将敏感话题库中的敏感话题分为若干类别{case1,case2,…,casek},并为每一类别选择一组最能反映该类别特性的特征词项,作为其状态序列:

4 特征函数的构造
经过3.1节和3.2节的步骤后,CRFs模型中的观察节点和状态节点就与待检测文档和敏感话题类别建立了对应关系。然而,CRFs中另一个非常重要的任务是如何针对特定的需求为模型选择合适的特征集合,并用集合中的特征来构造特征函数,用于敏感话题类别判定。
在构造特征函数之前,先在训练集中构造观察值序列即样本文档d′的真实特征集合b(item′x,i),所有i位置观察值item′x的真实特征。每个特征函数表示为观察序列真实特征b(item′x,i)集合中的一个元素,并为当前状态(状态特征函数)或前一个状态和当前状态(转移特征函数)定义一个特定的值(通常用0和1来表示)。例如状态特征函数抽取的具体过程如下:首先判断训练集中样本文档 d′={item′1,item′2,…,item′n}中的第 i个特征词项是否具有敏感特征,如人名;然后再判断该特征项是否为敏感词汇库中的种子词:

4.1 状态特征函数
4.1.1 关联度特征函数
敏感词汇的统计特征表明,文本的特征词表示序列中包含敏感词汇越多,该文本越有可能讨论敏感话题[9],因此,待测文档d属于某一敏感话题类别的判定问题就可以转化为待测文档中的特征词与敏感话题类别中特征词的相关度判定问题。而如果2个词在语料库中所处的语言环境总是非常相似,则认为这2个词的相关度很大。这样,可以将词间关联度作为评估文档和敏感话题类别相关度的一个特征。在CRFs模型中,待测文档和敏感话题类别中特征词之间的关联度特征函数形式如下所示:
其中,ε为词项间的关联度阈值,当2个词项之间的关联度超过一定的阈值时就可以判定它们是相关的;cor(·)为待测文档中的特征词与敏感话题类别中的特征词之间的关联度,计算方法如下:
其中,分子部分为待测文档中特征词与敏感话题类别的某个特征词的互信息;分母表示待测文档中特征词与敏感话题类别的所有特征词互信息的总和。
4.1.2 词项的属性特征函数
一般的,同一个词的不同词性会使该词具有不同的意义和不同的敏感性强度。通常情况下,命名实体和动词成为敏感性词汇的可能性要大于其他词性,同时,情感词汇也是敏感词汇的一个重要组成部分。因此,就可以利用词语的词性和它的情感极性以及在文本中的位置来构造属性特征函数。本文中用到的词项属性特征如表1所示。

表1 词项属性特征
4.2 转移特征函数的定义
在待测文档特征词序列的敏感性标注过程中,前一词项的敏感性标注对当前词项的敏感性标注是有影响的,因此,本文定义了词项间敏感性标注的转移特征函数,例如,当观察序列中的当前词项xt在中国机构名词典中,并且状态序列中前一词项的敏感性标记yi-1为极性词,当前词项的敏感性标记yi为敏感机构体时,特征函数应取值为1。本文中用到的转移特征模板如表2所示。

表2 转移特征函数
5 敏感话题检测的CRFs模型
5.1 CRFs模型
条件随机场是一种用于在给定输入节点值时计算指定输出节点值的条件概率的无向图模型,能够较好地解决序列标记问题。对于输入序列x和输出序列y,线性链式条件随机场模型可以被定义为[10]:

其中,tk是转移特征函数,对应于 CRFs模型中边〈yi-1,yi〉上的特征;sk是状态特征函数,对应于 CRFs模型中第i个位置上输入-输出节点的特征;vk和uk是特征函数的权值,通常将tk和sk写为统一形式fk;Z(x)是归一化因子。CRFs可以将模型中各元素自身的属性特征以及各元素之间的长距离依赖特征和重叠特征进行量化运用到模型中,因此,CRFs有强大的特征拟合能力,通过利用领域知识,能够获得全局最优标记[11]。
在本文中,待测文档中的每个特征项被依概率标注为敏感话题类别中的词项,其中,最大概率的状态序列采用Viterbi算法[12]获得。在Viterbi算法中,需要建立词项之间的关系矩阵,如某类别的关系矩阵见表3,aij表示第i个词和第j个词之间的关系(如上下文关系),若2个词之间无任何关系,则aij=0。

表3 词项之间的转移关系
5.2 CRFs模型的训练
CRFs模型的训练[11]是采用对数最大似然估计从训练集中估计每个特征函数的权重参数Λ={λ1,λ2,…,λn},对于训练集 D={〈x,y〉(1),〈x,y〉(2),…,〈x,y〉(i),…,〈x,y〉(N)},似然函数如下:

其中,第2项为高斯先验值,是一个用于平滑处理的特征参数,其方差为σ2。本文使用L-BFGS(Limited Memory Broyden-Fletcher-Goldfarb-Shanno)算 法 实现对目标函数的优化求解,L-BFGS可以被简单地看作一个黑盒优化过程,仅需要提供似然函数的一阶导数,则训练集的对数似然估计的一阶导数为:
其中,Ck(y,x)是表示y中各位置i上的特征函数fk的和,上式中前2项的差对应于特征的经验期望值与模型的期望值的差[fk]-EΛ[fk]N,第3 项为高斯先验值的导数。
5.3 文本的敏感性标记
设话题类别集合 case={case1,case2,…,casen},按上文所述建立CRFs的敏感话题检测模型,如图2所示,具体检测方法如下:
(1)获取待测文档,并表示为观察序列d={item1,item2,…,itemn},作为 CRFs模型的输入。
(2)在给定输入序列(观察序列)的条件下,计算每一个标记序列(状态序列)的概率,将具有最大概率的标记序列对应的类别标签作为待检测文档的候选话题类别casej。
(3)判断各候选话题类别对应的概率值,若大于阈值θ,则将该文档归入概率值最大的敏感话题类别中,若小于阈值,则认为该文档不是敏感话题。

图2 文档敏感类别标记流程
如果待测文档d的候选话题类别不止一个,则计算文档d与各候选话题类别特征向量之间的Hellinger距离,并将文档那个d归入距离最短的那个类别。
6 实验结果与分析
6.1 训练数据
实验采集2011年8月-2012年3月的国内各大新闻网站的100000个新闻网页(大多数是论坛和博客的帖子)作为本文实验的语料库,所采集的数据信息包括标题、内容、发布时间等,如表4所示。敏感话题类别采用 ODP(Open Directory Project)网站(www.dmoz.org)定义的16个大的主题类别,包含暴力、色情等,训练数据集是从语料库中选取的包含敏感性话题的20000个网页文本,它们被标注为16个敏感话题类别。

表4 词项属性特征列表
6.2 测试数据集
为了测试本文方法的有效性,仍采用在线网页作为测试数据集,抽取2012年4月-2012年8月的100000个网页作为测试数据集。
6.3 评价标准
在本文中,敏感话题检测的评测标准采用信息检索中广泛使用的准确率(Precision)和召回率(Recall)及 F 度量值[13],算法如下:
其中,准确率Precision是正确标记文本和标记文本总数的比值;召回率Recall是正确标记文本和实际正确标记文本总数的比值。
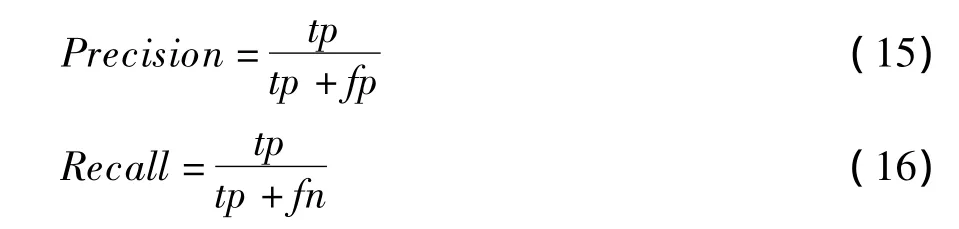
其中,tp为属于敏感话题且被正确标记的文本数;fp为不属于敏感话题但被标记的文本数,即错误标记数;fn为属于敏感话题但未被标记出的文本数,即漏检文本数。
6.4 结果分析
为了能够客观地评价本文提出的基于CRFs的敏感话题检测模型的效果,根据训练数据集与测试数据集的不同关系,本文实验分别采用了封闭测试和开放测试来进行评测,并且以贝叶斯模型为对比实验,双方均以敏感词作为文本的特征项。据此,本文一共做了4组敏感话题检测实验,前2组为封闭测试的基于CRFs的敏感话题检测模型与贝叶斯模型2种方法的测试结果,后2组为开方测试的基于CRFs的敏感话题检测模型与贝叶斯模型2种方法的测试结果,结果如表5和图3所示。

表5 CRFs模型与贝叶斯模型的实验结果对比

图3 CRFs模型与贝叶斯模型的实验结果对比
从表5和图3中可以看出,同样是概率模型,由于基于CRFs的敏感话题检测模型考虑了所有词语间的相关性,能够将更多的信息纳入到文本中来,因此,在F度量值、准确率(Precision)和召回率(Recall)上取得了更好的效果。
为了分析特征对CRFs模型的影响,本文实验对不同的特征数量进行了实验,基于CRFs模型的敏感话题检测的F值随CRFs模型中特征数量的变化趋势见图4。由图4可知,随着选择特征数量的增加,F值不断增加,算法有效性提高,当特征数量超过一定值后(num(features)>14)后,F值先是变化不大,然后有所下降,因为特征的引入带来了一定的噪声,系统的效率也会随特征的增加而不断降低。
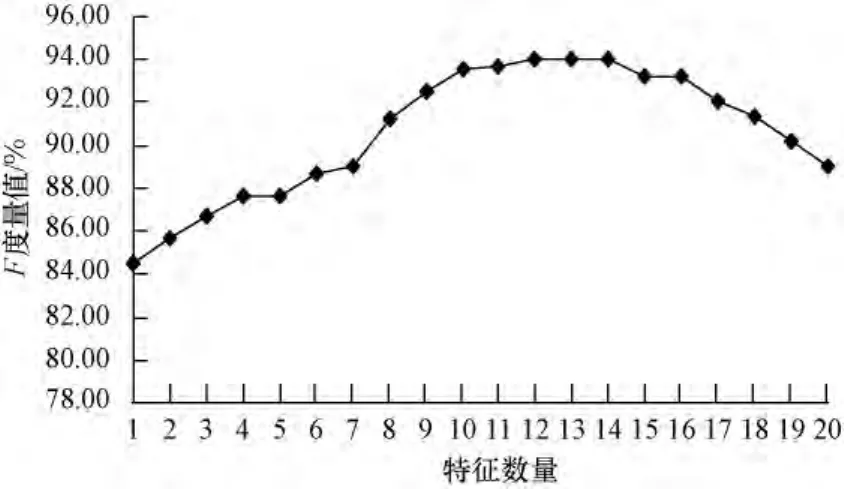
图4 CRFs模型中特征数量对F值的影响
7 结束语
本文在充分分析敏感话题特点的基础上,提出了基于条件随机场的敏感话题检测模型。在文本表示方面,本文利用了敏感性因子加权的特征词提取方法;在敏感性检测时,充分分析了敏感话题所具有的敏感性特征,利用条件随机场概率图模型对各种敏感特征知识进行拟合和推断。最后通过实验证明,该方法与传统的贝叶斯方法相比,在敏感话题识别方面具有较好的性能,下一步将考虑时间因素对敏感话题检测的影响,并在此基础上对条件随机场模型进行扩展。
[1]Wayne C L.Multilingual Topic Detection and Tracking:Successful Research Enabled by Corpora and Evaluation[C]//Proc.of Language Resources and Evaluation Conference.Athens,Greece:[s.n.],2000:1487-1494.
[2]Zheng Donghui,Li Fang.Hot Topic Detection on BBS Using Aging Theory[C]//Proc.of International Conference on Web Information Systems and Mining.Shanghai,China:[s.n.],2009:129-138.
[3]Lee P,Hui S,Fong A C M.An Intelligent Categorization Engine for Bilingual Web Content Filtering[J].IEEE Transactions on Multimedia,2005,7(6):1183-1190.
[4]Zhao Liyong,Zhao Chongchong,Pang Jingqin,et al.Sensitive Topic Detection Model Based on Collaboration of Dynamic Case Knowledge Base[C]//Proc.of the 20th IEEE International Workshops on Enabling Technologies:Infrastructure for Collaborative Enter-prises.Athens,Greece:[s.n.],2011:156-161.
[5]Zhao Liyong,Li Aimin.A Novel System for Sensitive Topic Detection and Alert Assessment[C]//Proc.of the 8th International Conference on Fuzzy Systems and Knowledge Discovery.Shanghai,China:[s.n.],2011:1751-1755.
[6]Settles B.Biomedical Named Entity Recognition Using Conditional Random Fields and Rich Feature Sets[C]//Proc.of the International Joint Workshop on Natural Language Processing in Biomedicine and Its Applications.Stroudsburg,USA:[s.n.],2006:1279-1288.
[7]刘 霁,周亚东,高 峰,等.一种基于文本语义的网络敏感话题识别方法[J].深圳信息职业技术学院学报,2011,9(3):33-37.
[8]李军辉,周国栋,朱巧明,等.中文名词性谓词语义角色标注[J].软件学报,2011,22(8):1725-1737.
[9]Budanitsky A,HirstG.Evaluating Word Net-based Measures of Lexical Semantic Relatedness[J].Computational Linguistics,2006,32(1):13-47.
[10]Lafferty J,McCallum A,Pereira F.Conditional Random Fields:Probabilistic Models for Segmenting and Labeling Sequence Data[C]//Proc.of the 18th International Conference on Machine Learning.San Francisco,USA:Morgan Kaufmann Publishers Inc.,2011:282-289.
[11]周俊生,戴新宇,尹存燕,等.基于层叠条件随机场模型的中文机构名自动识别[J],电子学报,2006,34(5):804-809.
[12]Viterbi A J.Error Bounds for Convolutional Codes and an Asymptotically Optimum Decoding Algorithm[J].IEEE Transactions on Information Theory,1967,13(2):260-269.
[13]Wikipedia.Information Retrieval[EB/OL].(2013-07-05).http://en.wikipedia.org/wiki/Information_retrieval.
