一种改进的分布式搜索引擎模型
2014-09-21钱立兵季振洲
钱立兵,季振洲,吴 昊
(哈尔滨工业大学计算机科学与技术学院,150001哈尔滨)
大规模文档数据使得分布式引擎的检索和查询都面临性能的压力,为了提高分布式搜索模型的性能,在索引合并和查询算法方面,很多学者开展了研究工作.针对索引合并,Heinz等[1]讨论了合并的索引构建方法及其相对于排序方法的优势;Büttcher等[2]研究了 Logarichmic 合并算法并验证该算法对于索引合并的高效性;Hao等 提出对索引压缩和查询预处理来优化文档排序.关于查询算法,document-at-a-time(DAAT)和termat-a-time(TAAT)是两种经典的算法[4-5];Turtle等[6]根据词项的最大得分策略(max score)优化了查询过程;Strohman等[7]使用预处理剪裁前k个最好结果的得分下界改进查询效率.然而,这些改进均建立在传统模型基础上,并没有改变传统模型自身的一些局限,如宏观上索引文档结构划分的无序性,用户全局性查询的盲目性以及系统扩展性不强等.
本文优化了传统分布式搜索模型的结构,按照文档主题对索引文档进行分类,提出高效、可扩展的并行分布式模型结构;以优化模型为基础,改进索引倒排表结构,并利用MaxScore策略,对堆排序进行优化,设计出针对索引节点的并行查询算法.
1 传统分布式搜索引擎
1.1 分布式搜索模型
分布式搜索引擎有沙漏模型、Map/Reduce模型、P2P网络模型等,其中,沙漏模型应用最为广泛.图1是经典的沙漏模型[8],系统包含前端应用展现层(processing of front,PF)、结果汇聚层(merge)和独立引擎层(search engine,SE).

图1 分布式引擎的沙漏模型结构
PF层主要处理不同业务需求,每一类应用都会根据该应用特征解析query,然后访问merge层.merge层起到承上启下作用,接受PF层传递的多个请求,向SE层多个独立引擎发送;合并各个引擎请求结果后发送给PF层.SE层是分布式引擎系统中的基础层,承担海选、相关性、精选等过程,是系统搜索核心过程.
1.2 分布式查询过程
PF层接收用户请求(query),经过词干提取、用户行为、查询意图[10-11]分析得到若干个特征词{q1,q2,…,qm},再由 merge 层将这些特征词转发到SE层的各个独立引擎.每个独立引擎根据特征词对其倒排表进行海选、普通排序、精排,堆排序得到各自Top N结果.merge层根据SE层的各个独立引擎所得到结果集,进行除重、过滤、相关性排序得到最终Top N个结果,返回用户.若独立引擎数为n,特征词数目为m,则用户一次请求在merge层会产生独立引擎查询次数m*n.
这种分布式查询过程使得整个系统处于繁忙状态.高并发用户请求,使得merge层的请求任务与结果合并任务成倍增加;同时索引节点的增加,也会导致merge层增加负载任务.因此,如何提高系统扩展性,适应高并发查询是搜索引擎研究的关键目标之一.
2 并行分布式搜索
2.1 并行模型提出
为了克服沙漏模型的不足,本文根据文档主题对文档集进行分类,建立分类索引.文档主题的分类方法是根据用户的请求,提取用户查询特征词,以特征词代表文档,按照二元分类方法的NN算法[12],计算各种类别模式下特征词的得分,与最低阀值比较,保留大于最低阀值的类别作为分类结果.特征词的提取按照文献[13]的词项权重为

式中:wt,d为词 t在文档 d 中权重;tft,d为词 t在文档d中的词频;N为文档总数;dft为出现t的所有文档数.
按照主题分类使得有些文档可能属于多个类别(跨类文档),对于这种跨类文档,可以采用简单的URL近似匹配,前提要对各个类别保存主体的URL前缀,具体做法是对跨类文档的URL分别匹配所属类别的URL集,保留URL匹配的最大文档,确定跨类文档最终只属于一个类别,按照单个类别建立索引.
图2是基于传统的分布式引擎所设计的可扩展的分布式模型.在merge层,按照文档主题建立1~M个类别的索引集,每个merge节点管理一类索引节点,例如merge1节点管理索引Index(1,1)~Index(1,c1)节点,使得查询请求所访问的索引节点具有针对性.

图2 具有分类索引结构的分布式模型结构
依据图2建立的模型,分类查询过程如下:当应用层得到用户查询请求query后,经过分词得到查询关键词Keyword,由Keyword确定待查询的merge节点,被触发的merge节点查询本类索引节点,查找的结果返回到merge层,merge层合并本类索引节点的结果返回给应用层.
该模型的查询类别识别方法为:首先,应用层需要保存merge层各个类别模式的特征词和近义词,匹配用户查询Keyword;然后,应用层根据识别类别向所属的所有类别的merge层发送请求,被触发的merge节点再按照本节点的文档类别访问独立引擎层的索引节点.如图2所示,merge层只是被动接收应用层发送的请求,识别用户过程由应用层负责,这样能够提早识别出类别,避免全局查找.
2.2 索引倒排表的改进
上述建立的并行模型,对于倒排记录经常发生变化的文档集合,需要更好的索引结构.索引合并是检索系统的重要任务.一种优化归并的方法是采用跳表(skip list)[14]策略能够获得很好的性能,即在构建索引时构建一个跳表,当跳表指针的目标项小于另一个表的当前比较项时可以采用跳表指针直接跳过.如图3所示,对 t1=“Information”和t2=“Retrieval”进行合并,假如t1的指针移到17,t2的指针移到65,较小项为17.此时并不需要移动t1,而是检查跳表指针,此时为30,仍然比65小,t1直接跳到30,即跳过了21和24.
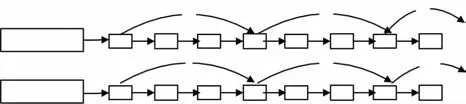
图3 带有跳表指针的倒排记录表
倒排记录经常发生变化的文档,使得倒排记录表指针频繁发生变化,从而丧失了跳表的性能.为了解决跳表结构的性能问题,对于较长的倒排表的词项设计一个位图(Bitmap)结构(考虑Bitmap结构本身的内存开销,较短的记录表无须设计Bitmap).Bitmap结构的存储顺序号与文档ID对应,若文档存在倒排记录表中,对应位标记为1,否则为0.例如:ID=1 027的文档记录在第1 027 bit存储位,即存储在Bitmap结构的第128 B的第3位(1 027=128*8+3).
如图 4所示,对 t1=“Information”、t2=“Retrieval”和 t3=“Organization”,对较长倒排列表的词项t1和t2建立Bitmap,t3链表长度较短无需建立Bitmap,先对t1和t2的Bitmap合并保存到中间的Bitmap merge中,再遍历t3得到记录表的文档号,添加到Bitmap merge,即得到合并结果.

图4 带有Bitmap结构的倒排记录表
本文针对较长记录表的选择依据设计了两种方法:1)采用固定常数γ,记录大于γ时建立Bitmap;2)设计一个可调参数λ(0<λ<1),设文档集数目N,L(t)为词项t的倒排表长度,当L(t)>λN时,建立Bitmap.两种方法中γ或λ需要通过根据内存容量情况去选择.
对于k个长度为L的记录表合并,普通算法采用多路合并,时间复杂度为O(L*k*lg k).采用Bitmap策略时,满足条件的倒排记录表建立Bitmap的时间复杂度为O(k*t),即k个Bitmap按位运算时间开销(t为两个Bitmap合并开销,通常为常量),提高了查询速度.空间上需要对每个较长记录表设计 N位的 Bitmap,即建立O(r*N/8)(r为满足建立Bitmap条件的记录表个数).在查询过程中,对多个查询词的请求,先对词项的Bitmap合并(对于不存在Bitmap结构的词项,按照正常的遍历方式得到文档号信息,然后加入到Bitmap结构中).在动态更新文档时,只需要添加或删除Bitmap中对应的文档号位置.较少的内存空间开销所带来倒排表合并的速度优势很重要,对较长链表直接进行位图合并,能够较好地提高查询速度.在实际应用中,根据内存开销允许的程度去选择γ或λ,对倒排记录表选择建立Bitmap结构,能够优化系统性能.
2.3 并行查询算法设计
针对文中设计的搜索模型,提出一种优化的并行查询算法.查询算法中的评分函数是依据Robertson 等[15]使用的 Okapi BM25.

式中:N为文档集数量;Nt为包含词项t的文档数;ft,d为词项t在文档d中出现次数;k1(默认是1.2)用来调节TF的饱和度;b(默认是0.75)用于归一化文档长度;ld为文档d词条数;lavg为文档集中所有文档平均词条数.
算法中设计3类数据结构:词项(term)堆用于管理查询词项{t1,t2,…,tm},追踪每个查词项项t的下一个文档;Bitmapmerge结构(位图结构)用于存储倒排表合并后文档ID的存在状态;result堆用于维护当前找到的Top k个搜索结果.采用线程池(thread pool)分配和管理3类数据结构,每个线程都有独立的3种结构,线程初始化时构建3类数据结构,3种结构都是随着当前用户的查询词项加入,查询结束后清空.
如图5所示,对于查询词集合 queryterms={“computer”,“science”,“technical”},启动线程池中的线程1,建立3个元素的term堆,分配一个Bitmap merge,同时分配含Top k的result堆(按得分建立小根堆).term堆中每个词项连接的文档按照ID排序,result堆在运行中保存当前最好的k个文档,根节点是当前第k个最好的文档,当找到一个新文档比根节点分数高时,利用新文档替换根节点,进而调整堆结构.
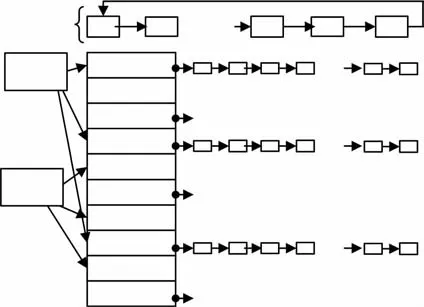
图5 线程池结构与并行查询方法示例
根据turtle和flood的maxscore策略优化查询过程,式(2)中 TF得分贡献不超过 k1+1=2.2(k1取默认值1.2),即词项总得分不超过2.2lg(N/Nt).改进的查询算法采用了此种技术优化查询过程.
在支撑多核的硬件平台下,设计thread pool结构管理并行执行的线程.倒排记录表作为所有查询线程的公共访问资源,查找过程不会改变公共资源,因此对倒排列表的访问本身存在高度并发访问优点.由于线程本身开启和切换存在开销,尽可能使分配的线程任务饱满,而不是分配过多的任务量轻的线程.
对于搜索引擎业务,设请求任务并发数为n/s,线程最大处理任务数为Cmax,为了避免过多的轻量线程开销,要求每个线程至少处理任务数为Cmin,线程池最多数目为p(由硬件限制,一般为核数2倍最优),实际开启线程数Pnum.当n≤Cmin*p时,Pnum=n/Cmin,即开启n/Cmin个线程;当Cmin*p<n≤Cmax*p时,开启的线程数Pnum=2*p/(Cmin+Cmax);当n>Cmax*p时,线程处于超负载情况,充分利用硬件资源,开启Pnum=p个线程.通过实验测得Cmin=2,Cmax=6,即任务数小于2时,属于轻量线程;任务数大于6时,属于超负荷线程.

图6 对堆排序裁剪的一种多线程并行查询算法
通过上述计算得到开启线程数Pnum,得到如图6所示的MMSH算法,每次处理n个请求queryList[1…n]:每个线程平均处理任务数n/Pnum.每个线程调用改进的堆排序裁减MSH(max score heap)算法处理请求任务,如图7所示.

图7 MSH算法
MMSH算法的核心处理是MSH算法,如图7所示,通过对堆排序的剪裁,在保证结果一致性情况下,优化了查询性能.MSH算法能够保证算法的结果与堆排结果一样,但速度要快很多,这是因为一旦发现某个文档不可能为前k个结果,立即被忽略.
3 实验与讨论
硬件资源:IBMX360f服务器,16核处理器、16 G内存;通过商业引擎Ha3+hadoop技术,分别构建如图1的分布式引擎的沙漏模型(Search1)和如图2改进的分布式引擎(Search2)架构.通过比较改进模型和传统模型的查询算法效率和系统吞吐量,说明设计的有效性.
1)实验环境搭建.为了实验条件的一致性,两种结构均使用8个节点服务器.Search1和Search2都使用4个索引节点,2个merge节点,2个PF节点.
2)实验数据.借助于商业引擎的Hadoop集群抓取得到50 G文档数据;查询请求时根据查询日志,得到1万查询query,作为query集.
3)实验方式.通过脚本程序对query集定时请求系统,模拟用户访问,访问数由实验进行调节.
4)查询语法.分类索引建立后,需要额外产生类别属性category,在应用端识别出本次查询的category,语法如:category=3&&query=”MP3”&&hit=10&&…,其含义为查询类别3的merge节点,查询词为MP3,用户感兴趣的前10条文档信息等.
Search 1的merge层采用集中方式,索引按照文档划分;Search2进行分类和动态化处理,按照多个节点的非集中方式管理.由于索引结构的不同,导致二者查询方式很大差异,使得查询速度相差较大.同时,实验将要验证并行查询算法对高并发任务的有效性.
3.1 merge层负载
为了验证改进的模型结构,在不同并发请求情况下,对Search1和Search2两种结构的merge层负载进行试验.图8和图9分别记录多个并发query的merge层节点的CPU和内存平均开销,实验中设置返回用户Top 100个结果,随着请求并发数增多,内存和CPU变化明显.CPU开销与并发数几乎是线性增大,Search2的merge节点CPU占用率约为Search1的75%.merge层节点的内存开销主要对所属类别索引节点的查询中间结果的缓存,并发任务越多,Search1和Search2之间的内存开销相差越大,其原因是未分类Search1使得各个索引节点返回结果数以索引节点数的倍数增大,花费更多内存开销.
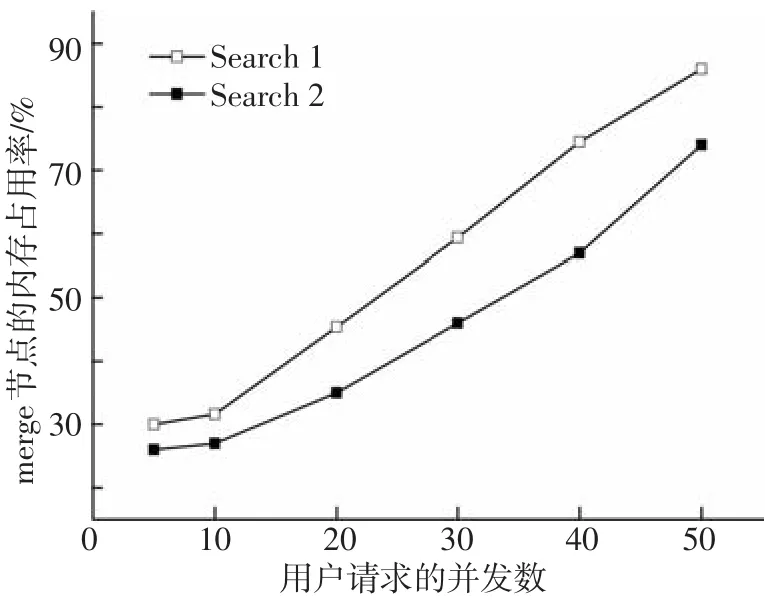
图9 Search1和Search2在不同并发数query的平均内存占用率
由于传统分布式模型对各个索引节点查询结果需要进行多次合并、排序等工作,使得merge成为系统的瓶颈,query的并发数直接影响merge节点性能;而改进分布式模型根据索引类别,按照各类查询的merge节点处理查询信息,具有很强的针对性,从而减少merge节点的负载.
3.2 搜索节点的并行查询性能
为了验证MMSH算法优越性,实验中采用Search2模型.由于在倒排表索引不能完全存入内存情况下,TAAT算法不需要磁盘访问,优势高于DAAT算法,而文中实验侧重讨论此种情况下MMSH算法优势,为此MMSH算法只与TAAT算法进行比较.在相同的并发用户请求和多线程执行下,从搜索引擎层的平均搜索时间和吞吐量两个方面比较二者性能.实验中两个重要参数是:线程数p和参数Top k(用户选取前k个结果,k=10是系统默认值).
图10中,通过比较MMSH算法和TAAT算法的平均查找时间可以看出,MMSH算法具有明显的优势,从图10可以看出,多线程体现并行查询的优越性,平均查找时间几乎随着线程数目增大,下降趋势明显.当线程数达到一定数量时,线程本身存在开销,如继续开启更多线程,会降低系统性能,如实验中开启64个线程效果没有32线程好.这是由于在搜索过程中,改进算法中利用MaxScore排除不必要计算过程,从而提高了查询速度.
图11的系统吞吐量是指整个搜索引擎层平均每秒钟所能够处理的merge层发送的请求数,而不是单个引擎的吞吐量.对于merge层发送的每一类请求,需要多个搜索节点并行搜索,然后把各种结果汇总到对应的merge节点.从图9可以看出,在线程数达到32前,多线程技术几乎能够得到线性的加速比;TAAT算法在吞吐量方面落后于MMSH算法,体现了MMSH算法优越性.线程数为32时,MMSH算法和TAAT算法的性能优于64个线程数情况,这是由于过多的线程数导致线程开启和切换的开销较大.

图10 搜索引擎层使用TAAT算法和MMSH算法平均查询时间

图11 搜索引擎层使用TAAT算法和MMSH算法时系统吞吐量
从图10、11的Top k,可以看出启动相同的线程数目,k越大,查询时间越长,吞吐量越小,并且MMSH算法优于TAAT算法,即系统开销越大.这是因为用户Top k中的k选择,直接影响查询过程中待计算的文档得分数量,导致系统性能差异.由于MMSH算法使用maxscore的提前打分策略,同等条件下,可以提高系统性能.
4 结论
1)根据文档主题特征,对索引进行分类,设计分类查询方法,解决查询盲目性.
2)对较长倒排记录表设计Bitmap结构,有效降低倒排表合并的查询时间复杂度,实现快速的倒排合并工作.
3)利用maxscore策略和多线程方法,在查询过程中建立词项堆、结果堆和Bitmapmerge结构,能够提前结束查询打分,从而优化了倒排表查询算法.
[1]HEINZ S,ZOBEL J.Efficient single-pass index construction for text databases[J].Journal of the American Society for Information Science and Technology,2003,54(8):713-729.
[2]BÜTTCHER S,CLARKE C L A.Indexing time vs.Query time trade-offs in dynamic information retrieval systems[C]//Proceedings of the 14th ACM International Conference on Information and Knowledge Management.New York,NY:ACM,2005:317-318.
[3]HAO Y,SHUAID,TORSTEN S.Inverted index compression and query processing with optimized document ordering[C]//Proceedings of the 18th International Conference on World Wide Web.New York,NY:ACM,2009:401-410.
[4]MANNING C D,RAGHAVAN P,SCHÜTZE H.An introduction to information retrieval[M].New York,NY:Cambridge University Press,2009:124-136.
[5]BÜTTCHER S,CLARKE C L A,CORMACK G V.Information retrieval implementing and evaluating search engine[M].Cambridge,MA:MIT Press,2010:137-173.
[6]TURTLE H,TOMPA F W.Query-evaluation:strategies and optimization[J]. Information Proceeding &Mangagement,1995,31(1):831-850.
[7]STROHMAN T,TURTLE H,CROFT W B.Optimization strategies for complex queries[C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,NY:ACM,2005:219-225.
[8]BARROSO L A,DEAN J,HOLZLE U.Web search for a planet:the google cluster architecture[J].IEEE Micro,2003,23(2):22-28.
[9]王晓春,李生,杨沐昀,等.查询会话中的用户行为分析[J].哈尔滨工业大学学报,2011,43(5):76-78.
[10]靳岩钦,张敏,刘奕群,等.搜索引擎用户查询的广告点击意图分析[J].哈尔滨工业大学学报,2013,45(1):124-128.
[11]黎玲利,王宏志,高宏,等.XML数据流上Top-K关键字查询处理[J].软件学报,2012,114(4):1561-1577.
[12]李晓明,闫宏飞,王继民.搜索引擎——原理、技术与系统[M].2版.北京:科学出版社,2012:253-282.
[13]易明.基于 Web挖掘的个性化信息推荐[M].北京:科学出版社,2010:93-110.
[14]STROHMAN T,CROFT W B.Efficient document retrieval in main memory[C]//Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.New York,NY:ACM,2007:175-182.
[15]ROBERSTON S,ZARAGOZA H,TAYLOR M.Simple BM25 extension to multiple weight fields[C]//Proceedings of the Thirteenth ACM International Coference on Information and Knowledge Management.New York,NT:ACM,2004:42-49.
