基于层次聚类模型的矩形优化排样问题研究
2014-09-21王竹婷邹乐
王竹婷 邹乐
(合肥学院计算机科学与技术系,合肥 230601)
矩形优化排样问题是国内外制造业领域研究的热点问题之一。在这些行业的原材料切割工艺中使用优化后的排样方案,可以极大地降低成本,提高企业的经济效益。但该问题目前已被证明为一类NP完全问题,即随问题规模扩大,此类问题的计算复杂度呈指数级增长。如何在合理的时间范围内计算出优化的排样方案成为该领域研究的重点。
目前较常用于求解排样问题的算法主要有遗传算法[1](Genetic Algorithm,GA)、模拟退火算法[2](Simulated Annealing Algorithm,SA)、微粒群算法[3](Particle Swarm Algorithm,PSA)等通用型的智能优化算法,将这些算法与最下最左算法[4](Bottom-Left,BL),基于 BL 的填充算法[5](Bottom - Left Filling,BLF)、最低水平线法[6](lowest horizontal line,LHL)等作为解码方法相结合使用,可以得到较好的排样结果。但智能算法迭代次数多,时间复杂度较高,在求解大规模排样问题时的时间效率偏低。
为降低排样算法的时间复杂度,本文将凝聚的层次聚类模型[7]引入排样问题中,并给出两矩形件之间结合度的概念,按层次聚类的思想,将结合度较高的矩形件合并成矩形簇,最终将所有矩形件合并到一个簇中,排样结束。最后设计算法程序,引用标准数据集测试算法性能,测试结果表明本文所提出算法可有效求解大规模排样问题。
1 矩形优化排样问题描述
矩形件优化排样问题,就是在一张或几张给定长度和宽度的矩形板材上切割指定规格和数量的矩形零件,要求所消耗的原材料最少。为方便描述此类问题,本文只讨论原材料为单一板材的情况。设矩形板材的宽度为W,W是排样前就确定的原材料的最大宽度,高度为H。假设H的值可无限增大,待切割零件总数为n,第i个零件为Ri,Ri的长为li,宽为wi。将所有矩形零件排入板材内,注意零件和零件之间不允许重叠,排样过程结束后板材在高度方向上使用的越少,排样效果越好,公式(1)为该问题的目标函数。
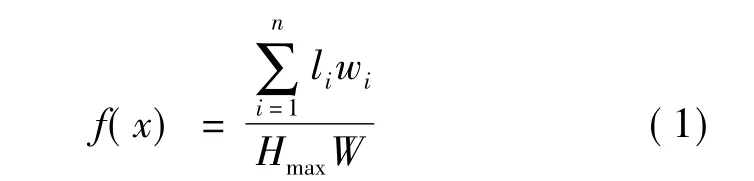
其中:Hmax为整个排样过程结束后所消耗的板材最大高度;f(x)为板材的利用率;f(x)的值越大排样效果越好。
2 层次聚类模型在矩形排样中的应用
2.1 凝聚的层次聚类算法思想
聚类算法是数据挖掘领域中的一项关键技术,可根据数据的特征属性,将具有相似特征的数据划分到同一个类别或簇内。聚类算法可以分为基于划分的方法、基于层次的方法、基于密度的方法、基于网格的方法和基于模型的方法。根据矩形排样问题的特殊性要求,本文重点研究凝聚的层次聚类算法。
凝聚的层次聚类算法是一种自底向上的聚类策略。初始时,每一个对象为一个簇,每一个簇处于最底层;然后再计算每一对簇之间的相似度,选择相似度最高的两个簇,两两合并,这样便形成了新的一层;反复执行上述步骤,直到所有的对象合并成一个簇或满足终止条件,算法结束。
2.2 矩形件聚类算法相关概念
在矩形排样中,需要获得较高的利用率。排放位置相邻的两个零件在长度或宽度上越接近,那么,将这两个零件排放在一起造成的板材浪费面积越少。基于这一特征,本文给出了针对矩形排样问题的结合度和聚类的相关定义。
两矩形件之间的结合度:两个待排矩形件合并成一个新矩形后,在这个新矩形内部产生的利用率称之为结合度。
两矩形件之间的结合度最高为1,最低为0。结合度为1时,即两矩形件的在长度或宽度方向上完全相同,合并成一个矩形件后没有造成浪费;结合度为0时,则表示某矩形件与其自身结合。结合度越高,两矩形合并后产生的浪费面积越少,结合度越低,则浪费越多。此时,两矩形件不宜排放在一起。
矩形件聚类:两个或多个矩形件,在板材中按相邻位置进行无重叠的排放,形成一个面积更大的矩形件,本文将这一排样过程称之为聚类。聚类过程中注意,合并后形成的新矩形的长度和宽度不得超过板材的最大宽度W。
矩形簇:两个或多个矩形件聚类后形成的面积更大的矩形称为矩形簇。
按矩形件排放位置的不同,结合度较高的两个矩形件聚类分为4种方式:矩形件i和矩形件j,其中i不等于j,将矩形件i的长边与矩形件j的长边相邻接;矩形件i的长边与矩形件j的宽边相邻接;矩形件i的宽边与矩形件j的宽边相邻接;矩形件i的宽边与矩形件j的长边相邻接。按照这4种方式排放在一起的两个矩形件,又可形成一个新的矩形件,分别计算四种方式下形成的矩形簇的面积,选择面积最小的结合方式,作为最终聚类的方案。
2.3 层次聚类算法在矩形排样中的应用
在数据挖掘领域中执行聚类算法,需要根据数据的特征属性计算不同数据之间的相似度,再通过聚类算法将相似度高的数据划分到同一个类别中[8]。本文所处理的问题,也是通过聚类算法将不同规格的矩形件排放到一个合理的矩形簇中,也需要提取矩形件的相关特征属性,计算结合度,将结合度较高的矩形件合并到同一个矩形簇中。在聚类算法执行前,首先构建2种数据结构:矩形件特征矩阵和结合度矩阵。
(1)构建矩形件特征矩阵。对于有n个待排矩形件的排样问题,可构建一个n行5列的特征矩阵X,其中n行表示n个矩形件的特征向量,5列表示每一个矩形件的5个特征属性。如公式(2)所示,xi1表示编号为i的矩形件的长度;xi2表示该矩形件的宽度;xi3表示该矩形件或合并后形成的矩形簇的有效面积,如果一个矩形簇是由a、b两原子簇合并而成的,则xi3的具体数值为a、b两矩形件的面积之和;xi4表示形成的矩形簇的实际面积;xi5表示矩形簇内部的实际利用率,即xi3与xi4的比值。

(2)构建结合度矩阵。该矩阵用来存储n个矩形件两两之间的结合度,这是一个n行n列的矩阵,矩阵中cij=cji,都表示矩形件i和矩形件j之间的结合度,其中cii=0,该矩阵也可以写成上三角或下三角的形式,如公式(3)所示。

(3)层次聚类算法的具体执行流程:
步骤一,相关数据初始化:对于有n个矩形件的排样问题,首先对n个矩形件进行1到n的编号,初始化矩形件集合{R1,R2,…,Rn};生成特征矩阵,记录每个矩形件的长、宽、有效面积、实际面积、利用率。初始时,每个矩形簇为原子矩形件,因此有效面积与实际面积相等,利用率为1,即100%;同时,构建结合度矩阵;
步骤二,从结合度矩阵中选择相似度高的矩形件两两合并。比如,要找与矩形件i结合度最高的矩形,可以搜索结合度矩阵的第i行中所有数值{ci1,ci2,…,cin},如果 cij最高,则将矩形件 i和矩形件j合并,将矩形件集合中Ri和Rj删除,并加入合并后的矩形簇,最后将结合度矩阵中与i和j相关的所有结合度修正为0;一轮聚类过程结束后,n个矩形件合并成n/2个矩形簇,令n=n/2,并对各矩形簇重新编号;
步骤三,根据新形成的矩形件集合,重新构建特征矩阵和结合度矩阵;
步骤四,重复执行步骤二、三,直至n变为1,算法结束。
3 仿真实验
笔者用C++编写了求解矩形排样问题的层次聚类算法,利用文献[9]提供的标准数据集进行测试。文献[9]按照板材的规格和矩形件的数量不同将数据集分成7组,每组3个算例,如表1所示,每个算例都有最优解。表1中,第2行为每组算例中矩形件的个数,第3行为每组算例中板材的宽度,第4行则为最优解所对应的板材高度,即当利用率为100%时所消耗的板材高度。
为验证层次聚类算法求解矩形排样问题的有效性,编写了遗传算法(GA)程序,并采用最低水平线搜索算法(LHLS)作为解码方法,将其跟本文所提出的算法共同进行仿真实验,对比实验结果,从排样效果和时间效率上验证本文所提算法的有效性。测试结果记录如表2所示。
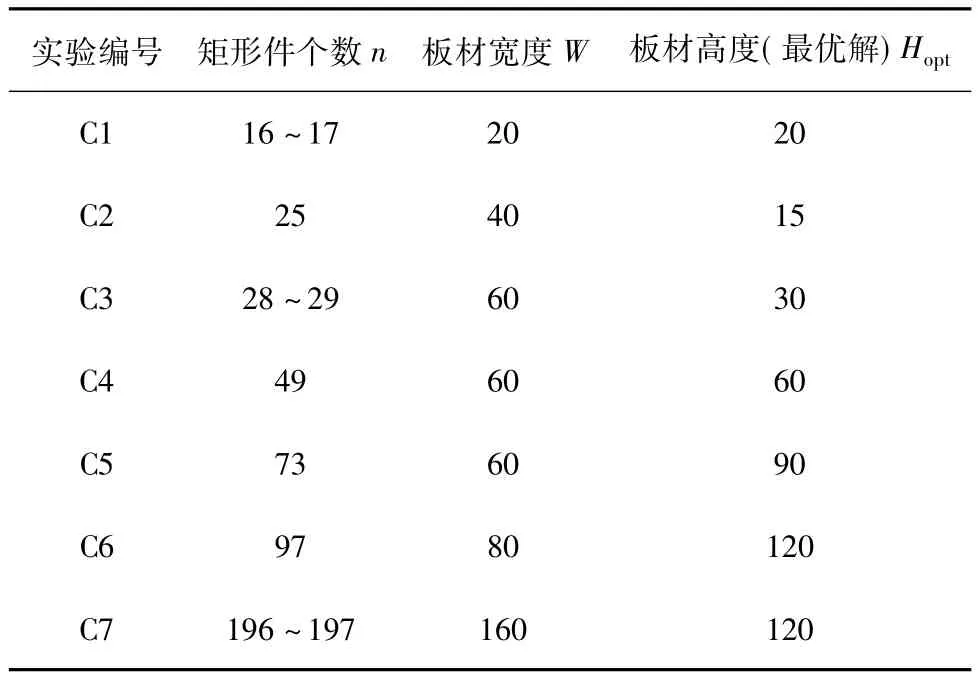
表1 实验数据
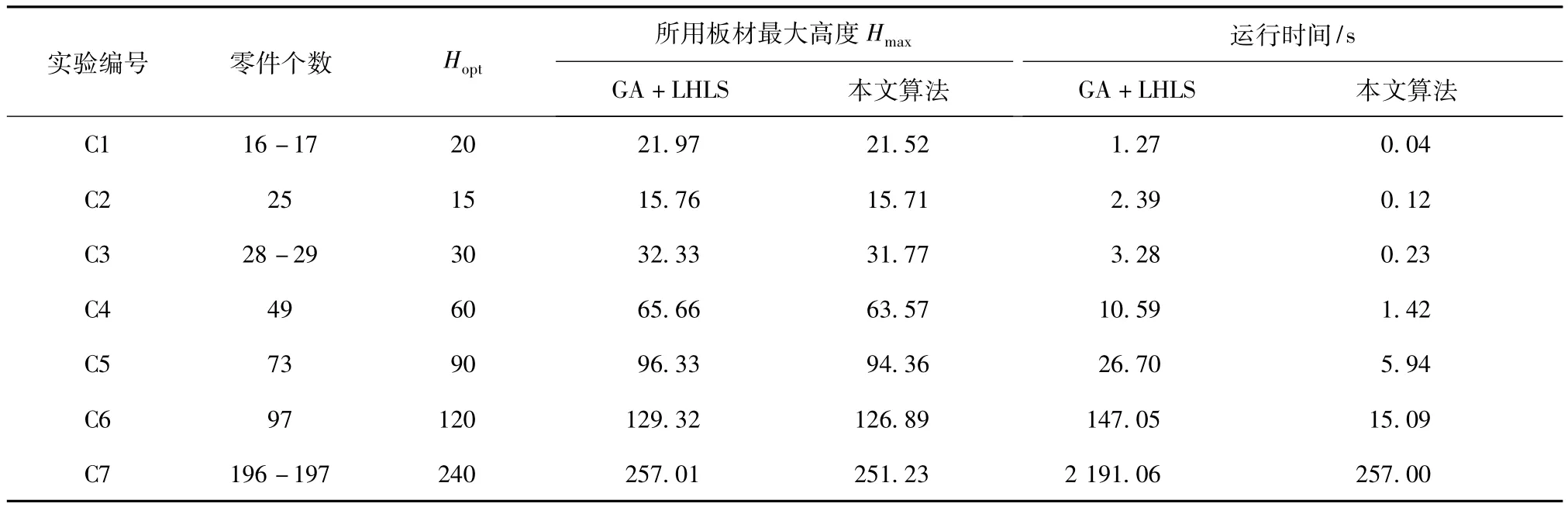
表2 GA+LHLS和本文算法的测试结果
表2中,第4列和第5列分别为GA+LHLS算法和本文算法执行完成后所使用的板材高度,与第3列中所列出的最优解板材高度对比,与最优解越接近,排样效果越好;第6列和第7列分别为GA+LHLS算法和本文算法计算每组算例所消耗的平均时间,消耗的时间越短,说明算法的时间复杂度越低。因此,表2中的测试结果证明,本文算法在排样效果和时间效率上均优于GA+LHLS算法,尤其在时间效率表现较为突出。
4 结语
本文提出了一种全新的矩形排样算法,引入了凝聚的层次聚类算法思想,定义了矩形件结合度的概念;自底向上执行聚类算法,将结合度高的矩形件两两合并成一个矩形簇,最终将所有矩形件合并到一个簇中;设计算法程序,运用相同的数据集测试本文提出的算法与遗传算法的性能,测试结果表明本文算法可以得到较好的排样结果,并且时间效率尤为突出,适合于求解大规模排样问题。
[1]蒋兴波,吕肖庆,刘成城.一种用于矩形排样优化的改进遗传算法[J].计算机工程与应用,2008(22):244-248.
[2]蒋兴波,吕肖庆,刘成城.求解矩形件优化排样的自适应模拟退火遗传算法[J].计算机辅助设计与图形学学报,2008(11):1425-1431.
[3]王珊珊.混沌离散微粒群算法在矩形排样中的应用[J].计算机工程,2010,(23):174-176.
[4]L iu D,Teng H.An Improved BL Algorithm for Genetic Algorithm of the Orthogonal Packing of Rectangles[J].European Journal of Operational Research,1999,112:413 -420.
[5]Andrea Lodi.Two Dimensional Packing problems:A Survey[J].European Journal of Operational Research,2002,141:241-252.
[6]贾志欣,殷国富,罗阳,等.矩形件排样的模拟退火算法求解[J].四川大学学报:工程科学版,2005,37(4):134-138.
[7]周兵,王和兴,王翠荣.一种基于GiST的层次聚类算法[J]. 计算机工程,2008,34(9):58-60.
[8]Fayyad U,Piatesky S G,Smyth P.The KDD Process for Extracting Useful Kowledge form Volumes of Data[J].Communication of the ACM,1996,39(11):27 -35.
[9]Hopper E,Turton B C H.An Empirical Investigation of Meta-heuristic and Heuristic Algorithms for a 2D Packing Problem[J].European Journal of Operational Research,2001,128(1):34 -57.
