认知无线电中实现最优传输的在线学习方法
2014-09-18蒋和松陈春梅
张 娟,蒋和松,江 虹,陈春梅
(西南科技大学特殊环境机器人技术四川省重点实验室,四川绵阳621010)
近年来无线设备(智能手机和平板电脑)的普及导致了对更多频谱带宽需求的急剧增加,可供分配的频谱资源越来越少,造成目前频谱资源紧张,但另一方面,无线频谱的利用率却相当低。根据文献[1-2],被分配的频谱中超过90%的频谱利用率严重不足。动态频谱接入(Dynamical Spectrum Access)技术的出现,解决了大量的频谱利用不足和频谱短缺之间的矛盾。动态频谱中最有前途的实现方式是认知无线电(Cognitive Radio,CR)。频谱共享是认知无线电系统中有效利用空闲频隙以提高频谱利用率的关键技术。
目前国内外研究人员已经提出了多种频谱共享模型,文献[3-4]分别研究了基于图着色和生物学的启发式算法,文献[5-6]分别提出了基于经济学的拍卖机制和博弈论,文献[7]提出了跨层优化的频谱共享模型,这些模型在某种意义上都可以让非授权用户共享授权用户的频带而不对授权用户造成有害干扰,但并没有针对具体的信道模型分析传输过程中的参数配置。文献[8]考虑了参数未知情况下的非贝叶斯感知问题,通过在线学习达到近似对数后悔值,但没有考虑不同通道状态下的最优传输。文献[9-10]考虑了GE(Gilbert-Elliot)衰减信道中最小化传输能力和延迟,通过单门限策略离线分析各种参数。
针对上述问题,本文提出了一种基于未知Gilbert-Elliott信道模型的最优传输在线学习方案:基于POMDP对网络信道建模,将K臂赌博机算法转化为K步信道保守策略,并采用UCB算法求解及UCB-Tuned算法优化。
1 系统模型
假设在授权用户网络中,每个信道只有两种状态S,即二值的Gilbert-Elliott马尔科夫链,如图1所示。当S=1时,表示当前信道空闲;当S=0时,表示当前状态忙碌。该图中λ0为信道的状态从忙到空闲的转移概率,(1-λ1)为信道的状态从空闲到忙碌的转移概率。

1.1 POMDP模型
在POMDP中,非授权用户(SU)须利用现有的部分信息、历史动作和立即回报值来进行策略决策。如图2为POMDP模型的框架[11],b为信念状态,是状态集合S中所有状态的概率分布。SU处于某一状态s的概率为b(s),且有 ∑s∈S
b(s)=1,则所有可能的信念状态构成的信念空间表示为B(S)={b:∑s∈Sb(s)=1,∀s,b(s)≥0},根据文献[11]信念状态为求解最优动作策略A*的一个充分统计量。模型描述为:1)状态估计器(SE):P×A×B(S)→B(S),其中P为置信概率,即状态估计器(SE)负责根据上一次动作和信念状态以及当前观察更新当前的信念b;2)策略π:B(S)→A,即在当前信念状态b下使用策略π从而选择动作a,其回报为r(b,a),表示为r(b,s)=∑s∈Sb(s)r(s,a)。

图2 POMDP模型示意图
1.2 基于POMDP的信道建模
假设当前信道为Gilbert-Elliott信道,即具有二值状态的马尔科夫链,当S=1时,表示当前信道处于空闲,对于SU而言信道状态较好,能够成功地高速传输数据;当S=0时,表示当前信道忙碌,对SU而言信道状态较差,SU只有以较低的速率传输才能成功。转移概率为
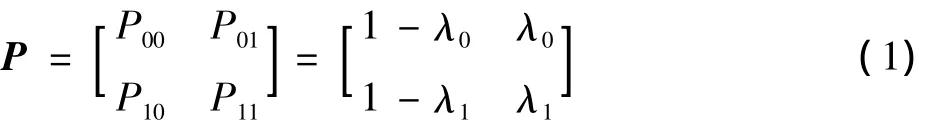
令α=λ1-λ0,假设信道为正相关,则α>0。
在每一次时隙的开始,SU需要做出动作选择:
1)保守发送(SC):SU低速数据传输。在该动作下,不管当前信道处于何种状态,SU传输数据均能取得成功,并取得回报R1。因此,在该动作下SU不能对信道状态进行学习。
2)激进发送(SA):SU高速数据传输。如果信道状态好,SU高速数据传输获得成功,并得到回报R2,且有R2>R1;如果信道状态差,高速数据传输将导致很高的错误率和丢包率,并获得惩罚值C。因此,在该动作下SU可以通过学习获得信道下一时刻的状态。
当保守发送时,信道的状态并不能直接观察,因此本文将该问题建模为POMDP模型。根据文献[11]信念状态为求解最优动作策略A*的一个充分统计量,因此该POMDP模型为在给定所有历史的动作和观察的情况下信道状态好的条件概率,表示为b=Pr[St=1|Ht],Ht为第t时隙前所有动作和观察的历史信息。激进发送时,SU能够学习信道状态。因此信道状态好时,信念为λ1,信道状态差时,信念为λ0。期望回报表示为

式中:bt为t时刻信道状态好时的信念;At为t时刻采取的动作。
2 信道状态未知的K臂赌博机在线学习算法
最典型的多臂赌博机问题为:对一个拥有K个手臂(multi-arms)的赌博机,赌博者要从这K个手臂中选择一个手臂进行操作来获得奖励(reward),该奖励从与该手臂相关的分布中得出,赌博者不知道每个手臂奖励分布期望值的大小。在一个特定的时间段内,赌博者只能操作一个手臂,赌博者要尽快找到使自己获得最大奖励的手臂,并且进行赌博[10,12]。
2.1 K步保守策略结构建模
K步保守策略结构模型如图3所示,激进发送失败后,在接下来的K个时隙保守发送数据。如图在马尔科夫链中有K+2个状态,状态0表示激进发送失败后重新返回到保守发送。状态K-1表示在保守发送K个时隙后,下一步将进入激进发送。如果第K个状态的激进发送成功,则进入到SA状态,否则回到0状态继续K步保守发送。如果状态一直保持在SA,表示信道状态一直处于好的状态即S=1,由式(1)可得,连续激进发送的概率为λ1;由于保守发送K步后才能激进发送,因此当0≤i<k时,状态从i到i+1的概率为1。
在K+2个状态中,每个状态对应一个信念和动作,信念和动作决定了期望总的折扣回报,因此有K+2种不同的折扣回报。K臂赌博机建模参数设置:
1)保守发送(SC):总能发送成功,获得的回报为R1;

图3 K步保守策略
2)激进发送(SA):发送成功时获得的回报为R2(R2>R1),发送失败时得到的惩罚为C;
3)不同K步保守发送建模为多臂赌博机的不同的臂。如K=2,即臂(Arm)为2,表示保守发送2次后再激进发送。
2.2 K步保守策略面临的挑战
当信道的传输概率未知时,在寻找最优K步保守策略面临两个挑战:1)臂无穷;2)为了获得总的折扣回报,臂需要被不断地选择直到时间无穷。为了解决这两个问题,本文寻找近似最优的臂(OPT-ε-δ)替代最优臂。通过近似最优的臂(OPT-ε-δ)替代最优臂,从而解决将系统建模为K臂赌博机策略的臂无穷和时间无穷的两个挑战。
2.3 UCB算法
UCB(Upper Confidence Bound)算法是一类解决多臂赌博机算法的总称,UCB根据目前获得的信息,配合上一个调整值,试图在利用(exploitation)和探索(exploration)之间达成平衡的ExE(Exploitation vs.Exploration)问题。
大致上来说,每一次运行时,UCB会根据每个臂目前的平均收益值(亦即其到目前为止的表现),加上一个额外的参数,得出本次运行此臂的UCB值,然后根据此值,挑选出拥有最大UCB值的臂,作为本次运行所要选择的臂。其中,所谓额外参数,会随每个臂被选择的次数增加而相对减少,其目的在于让选择臂时,不过分拘泥于旧有的表现,而可以适度地探索其他臂。UCB公式[13-14]表示为

式中:¯Xi是第i个臂到目前为止的平均收益;ni是第i个臂被测试的次数;n是所有臂目前被测试的总次数。使式(3)取得最大值的臂将是下一个被选择的臂。前项即为此臂的过去表现,即利用值(exploitation);后项则是调整参数,即探索部分(exploration)。
而UCB-TUNED是相对于UCB实验较佳的配置策略。UCB-TUNED的公式为

使式(7)取最大值的臂将是下一个被选择来测试的臂。
3 算法比较及仿真分析
本节分析对比了两种最优传输的方法,一种是文献[11]提出的最优传输门限策略的离线算法,另一种是本文提出的基于K臂赌博机在线学习算法。
3.1 最优传输门限策略的离线算法
根据文献[11]单门限最优策略建立的仿真环境如表1所示。假设信道是正相关的,所以λ1≥λ0,λ1的取值如表1所示,λ0(1)≤λ1≤0.99,根据文献[11]计算出不同运行的时隙数(1:10 000)范围下的V(λ0)的最大值。在不同λ0、λ1计算出对应的保守发送的最优时隙数(0,1,2,3,4)。

表1 门限结构最优策略参数设置
算法步骤如下:
步骤1:初始化参数R1,R2,C,β,λ0,λ1,Kopt;
步骤2:定义变量Karray存放满足条件的λ0,λ1,ρ以及Kopt;
步骤3:


根据以上算法步骤得出仿真结果如图4及表2所示。

图4 门限结构最优策略的期望折扣总回报

表2 门限结构最优策略
由图4及表2可得如下结论:
1)当 λ0=0.01,λ1=0.06 时,随着运行时隙n的增长,在n→∞ 时,Tn(λ0)→λs,那么总是保守发送,Kopt→∞;
2)当 λ0=0.61,λ1=0.66 时,表示信道状态较好,总是激进发送,Kopt=0;
3)当λ0=0.16,λ1=0.91时,得到Kopt=4 ,表示保守发送4个时隙后,再次激进发送,在该策略下,得到的总的折扣回报最大。
4)通过单门限最优策略,在不同的信道状态下(λ0和λ1不同取值)离线获得对应的最优K步传输值。
3.2 信道状态未知的在线K臂赌博机学习算法
本文提出的在线K臂赌博机学习算法,具体仿真环境设置如表3所示。考虑到本算法的收敛性,故总的运行时隙设为T×inter=109。ε=0.02和δ=0.02分别用于解决臂无穷和时间无穷的问题。为了更精确地获取最优臂,本文取值TMAX=100,KMAX=30。
算法步骤如下:
首先,初始化参数 λ0、λ1,T,TMAX,armnu,ts,NI,由于本算法是基于POMDP模型未知信道状态下的在线学习方

表3 在线K臂赌博机学习算法参数设置
法。故根据λ0和λ1产生信道的随机状态states,每个臂在产生动作后,根据观察到的状态获取一个回报或惩罚;其次,初始化各个臂的UCB值,最后,根据

选择最大的UCB或UCB-Tuned作为当前的最优臂,并运行当前最优臂。
根据以上算法步骤得出仿真结果如图5~图8所示。

图5 相同信道状态下的最优臂
如图5所示为通过UCB算法,获得同一个λ0=0.36和λ1=0.91信道状态下所有臂的表现,其中当臂为1时是该信道状态下的最优臂,随着运行时间增加,臂1被选中运行的时间比趋向于1,而其他臂的使用率趋向于0,从而找到最优臂。同样的方法可得到其他λ0和λ1对应的最优臂。
图6所示为通过UCB算法,获得不同的λ0和λ1信道状态下对应最优臂的收敛性,从图中可见,随着时间的增加,最优臂被选中运行的时间比逐渐趋于1。

图7所示为通过UCB-TUNED算法,同一个λ0和λ1信达状态下,所有臂的表现,与图5 UCB算法相比较,收敛速度更快。
图8所示为通过UCB-TUNED算法,不同的λ0和λ1信道状态下,臂的收敛性与图6 UCB算法相比较,收敛速度更快。
3.3 算法对比分析
本节对比了文献[11]提出单门限最优策略和本文提出的在线K臂赌博机学习算法,从图4可以看出当λ0=0.36和λ1=0.91时,通过最优策略得到最优K步值为1。从图5得到,当λ0=0.36和λ1=0.91时,利用本文提出的最优在线K臂赌博算法,同样得到最优传输K步值为1。并且从图5还可以得到当t=109s时,算法收敛,但收敛速度较慢。为此本文通过UCB-TUNED算法,提高了收敛速度。从图7和图8可得知,在t=108s时,算法收敛。
4 结论
当前信道最优传输大都是基于完全知识对信道建模,本文针对认知无线电环境不完全可知情况下,将信道建模为部分可观测马尔科夫过程,提出了基于多臂赌博机的最优传输在线学习方法。仿真分析表明,在信道不完全可知情况下的多臂赌博机在线学习算法与单门限最优离线传输策略相比,同样能获得最优K步策略。同时,本文通过UCB-TUNED方法改善了最优传输的K步保守策略的收敛性。
:
[1] WANG B,LIU K J R.Advances in cognitive radio networks:a survey[J].IEEE Journal on Selected Topics in Signal Processing,2012,5(1):5-23.
[2]许瑞琛,蒋挺.基于POMDP的认知无线电自适应频谱感知算法[J].通信学报,2013(6):49-56.
[3] TAN L,FENG Z,LI W,et al.Graph coloring based spectrum allocation for femtocell downlink interference mitigation[C]//Proc.IEEE Wireless Communications and Networking Conference.Cancun,Quintana Roo:IEEE Press,2011:1248-1252.
[4] HE Z Q,NIU K,QIU T,et al.A bio-inspired approach for cognitive radio networks[J].Chinese Science Bulletin,2012,57(28):3723-3730.
[5] ZHANG W,MALLIK R K,LETAIEF K B.,Cooperative spectrum sensing optimization in cognitive radio networks[C]//Proc.IEEE International Conference on Communications.Beijing:IEEE Press,2008:3411-3415.
[6]邱晶,周正.认知无线电网络中的分布式动态频谱共享[J].北京邮电大学学报,2009,32(1):69-72.
[7]吴春德,潘志文,尤肖虎.一种认知无线Adhoc网络跨层最优频谱共享方案[J]. 南京邮电大学学报,2009,29(3):83-87.
[8] DAI W H,GAI Y,KRISHNAMACHARI B,et al.The non-Bayesian.restless multi-armed bandit:a case of near-logarithmic regret[C]//Proc.IEEE International Conference on Acoustics,Speech and Signal Processing.Prague:IEEE Press,2013:2940-2951.
[9]许瑞琛,蒋挺.一种认知无线电周期数据传输优化机制[J].电子与信息学报,2013,35(7):1694-1699.
[10] ZHAO Q,TONG L,SWAMI A,et al.Decentralized cognitive MAC for opportunistic spectrum access in ad hoc networks:a POMDP framework[J].IEEE J.Sel.Areas Commun.,2007,25(3):589-600.
[11]江虹,刘从彬,伍春.认知无线网络中提高TCP吞吐率的跨层参数配置[J].物理学报,2013,62(3):494-501.
[12]陈亚琨,赵海峰,穆晓敏.认知无线电中基于感知信息量化的合作频谱感知[J].电视技术,2012,36(17):106-109.
[13] LAOURINE A,TONG L.Betting on Gilbert-Elliot channels[J].IEEE Trans.Wireless Communications,2010,9(2):723-733.
[14]衡玉龙,黄天聪,冯文江,等.有限用户数多认知网络部分信道共享性能分析[J].电子与信息学报,2013,35(2):267-272.
[15] TEKIN C,LIU M.Approximately optimal adaptive learning in opportunistic spectrum access[C]//Proc.IEEE International Conference on Computer Communication.Orlando,FL:IEEE Press,2012:1548-1556.
[16]章坚武,李峥.一种新的认知无线电频谱感知算法[J].电视技术,
2010,34(S1):153-155.
