一种新的基于LRU的大流检测算法
2014-09-18张毅卜夏靖波任高明
张毅卜,夏靖波,孙 昱,任高明
(空军工程大学信息与导航学院,陕西西安710077)
网络流是由相同属性的数据分组组成的集合,由于其在网络运营管理、计费等方面的巨大应用,所以基于流的网络测量不断受到重视。IETF(Internet Engineering Task Force)推荐的流测量方法是在测量设备中维护一个流表,为每个流保存一个流记录,但是当前网络中流的数量十分巨大,而目前的半导体技术并不能提供容量足够大的快速存储器SRAM来记录每个流的信息,因此实现IETF的方法十分困难。已有研究显示,网络中的流大小呈重尾分布,即少量的大流产生了网络中大部分的流量,而对于网络运营管理、计费等相关应用而言,只需要获取大流的流量信息就足以满足应用需求[1]。现有的大流检测算法普遍存在准确率不高的问题,不能满足实际应用需求。因此,如何更有效率地检测大流成为了网络流量测量中的一个热点问题。
1 研究现状
LRU算法是目前大流检测算法中时空效率较高的一种,它最早由Smitha等人提出[2],其基本思想是:设置一个用于保存流记录的固定大小的缓存,保持最新到达的数据分组所属流记录位于缓存顶部,而最久未到达的数据分组所属流的记录位于缓存的最底部。当有新流到达且缓存已满时,淘汰最久未更新的流来为新流腾出存储空间。由于大流持续时间长且分组到达速率高,所以其总能排在缓存的上部,从而以较大的概率留在LRU缓存中。该类方法处理速度快,识别效率高,硬件实现简单,但当有大量小流突发到达时,会造成某些大流被替换出LRU缓存,从而引起漏检。
为了进一步优化LRU算法,降低其漏检率,张果等人提出的基于分层多粒度最近最久未使用的流量统计算法[3],将多级LRU表“串联”在一起来降低原算法漏检率,该算法的实质是牺牲存储空间来换取测量精度的提高。考虑到高速缓存资源有限,文献[4]和文献[5]在原有单级结构的基础上提出采用两级结构来检测大流,其相同之处在于第一级结构都采用LRU算法,在第二级结构的设计中,文献[4]采用LEAST淘汰策略(当有新流到达且缓存已满时,流量大小最小的流被淘汰),文献[5]仍然采用LRU淘汰策略。实验表明,这两种算法对大流的检测效果较好而且性能接近,因此本文所提算法将与文献[5]中的LRU2-V2算法进行对比。文献[6]提出了一种基于LRU和SCBF的大流检测算法,但是该算法仅适用于检测大流,并不具备大流流量统计功能。文献[7]所提出的基于滑动窗口的LRU算法在判断的基础上需要进行抽样,处理过程较为繁琐,且滑动窗口的设置也较为复杂。
为了进一步降低LRU算法的大流漏检率并提高其对大流流量的测量精度,本文提出了一种基于LRU和CBF两级结构的大流检测算法。算法在时间窗口内将大流检测的筛选和过滤分开处理,然后对时间窗口进行刷新,此举最大限度地运用了LRU算法和CBF的优点,缓解了LRU和CBF的处理压力,达到了较好的效果。本文首先对该算法进行介绍,然后从理论上分析影响该算法性能的因素,并给出最佳的参数设置方式,最后通过实验验证该算法的有效性。
2 LRU-CBF算法
2.1 算法思想
由于大流持续的时间相对较长并且占用的带宽较大,因此在相同的时间内经过链路的流量往往较其他流而言更大。若将测量时间分为若干个时间窗口,在任一时间窗口内,一个流经过链路的流量达到预先设定的阈值,那么这个流可能是大流。这一步过滤出大流的工作由CBF来完成,顺利通过CBF的流将被记录在LRU缓存中进行进一步筛选。在这个过程中,CBF并不需要存储流关键字等信息,故能克服其需要缓存容量过大的缺点,由于CBF可以阻挡大量的小流进入LRU缓存,所以该算法的大流漏检率也将极大地降低。
2.2 算法描述
算法结构如图1所示。

图1 算法结构图
本算法分为两级,第一级为LRU,第二级为CBF。如果一个分组到达且在LRU中发现对应的流记录,那么将该分组大小累加到这条记录中并将其置于LRU缓存的顶部,如果该分组对应的流记录不在LRU表中,那么它将被哈希函数映射进CBF中,其分组大小将累加到相应的计数器里。如果此时这些计数器的值都不小于CBF中设定的阈值,那么该分组对应的流将被记录到LRU中。CBF在时间窗口结束时会自动刷新,即将所有计数器清0,最后当测量时间结束时,LRU中符合大流定义的流将被读出并保存。具体的算法步骤(伪代码)如下所示:

3 算法分析
3.1 算法准确性分析
首先分析该算法消除漏检的条件。当一个可能的大流f通过CBF进入LRU队列或者已经记录在LRU队列中的某个流f的分组到达时,该流f将被置于LRU队列的首部。如果接下来到达的分组均不属于流f,那么该流在LRU队列中的位置将不断向队尾移动并最终被淘汰。现在考虑当流f位于LRU的队列首部且LRU队列长度已达最大值时,连续到达多少个不属于流f的分组,流f将恰好被移出LRU队列。设一共需要x个不属于流f的分组,则可列出方程如

式中:T1为CBF中用于判断流是否进入LRU的阈值;PT1表示一个分组属于字节数小于T1的流的概率;PCBF为CBF的误正率;a和b为修正因子;N为LRU队列的最大长度。当到达x个分组时,其中有xPT1个属于字节数小于T1的流,从理论上说,这些小流无法通过CBF,因此不会对LRU中流f的位置造成影响。但是由于CBF存在“误正”的原因,即不属于同一个流的分组在CBF中可能被映射到相同的位置,因此如果恰有小流分组和某个大流的分组“误正”在一起,或者某些小流的分组“误正”在一起超过了CBF中设定的阈值T1,那么将会有小流进入LRU中影响到流f的位置。xPT1PCBF表示发生“误正”的分组个数,因为发生“误正”的分组对应的流并不会全进入到LRU中,所以再乘以一个修正因子a(0<a≤1)表示最终对流f的位置造成影响的小流分组的个数。同理,x(1-PT1)表示属于其他流的分组的个数,这些分组中的一部分可能会在LRU中找到对应的流记录,而这些流记录将被依次置于LRU队列的首部,导致流f向队尾移动,另一部分可能使其对应的流通过CBF进入到LRU中造成了流f的后移。显然,这些分组并不会都影响到流f的位置,因此再乘以一个修正因子b(0<b≤1)。当LRU队列的最大长度为N时,处于队列首部的流f向队尾移动N个位置将恰好移出该队列,故方程的右边为N。根据式(1),可得


因此通过设置合适的T1,T2的取值,可以将大流的测量误差控制在一个较低的水平内。
3.2 参数设置
如果给定的缓存容量为C,l1和l2分别为CBF和LRU队列中每一项的字节数,那么CBF和LRU的长度如何设计才能发挥出该算法的最大性能是值得考虑的问题。假设用于LRU的缓存容量占总缓存容量的比例为α,那
即对于一个位于LRU队列首部的流而言,只要连续到达的x个分组中有1个分组属于该流,那么该流就不会被淘汰。由于大流持续的时间较长,分组数较多,故x越大,就越有可能在这x个分组中出现属于该大流的分组从而使之不被淘汰,因此,提高x的值将降低该算法的大流漏检率。
下面讨论当测量时间结束时,若一个大流被成功检测到,则它的流量大小测量误差情况。设某个大流第一次出现时,它在对应的时间窗口内经过的流量为T'。若T'≥T1,则该流第一次出现时就将通过CBF,如果该流不被漏检的话,则最终它的流量大小可以精确测得。若T'<T1,此时该流在这个时间窗口内将不被检测到,如果该流的实际流量为T,LRU中用于判断是否为大流的阈值为T2,那么最终流量大小的测量误差至少为T'/T,由于T'<T1,T≥T2,故么LRU队列的最大长度为
经证实,早期功能锻炼有利于重症患者的恢复[11]。10月13日,患者神志清楚,病情允许在床上进行活动,肌力评估为Ⅲ级。终止锻炼标准同上。锻炼从大关节开始:上肢屈伸10次/组,每日两次;下肢屈膝蹬腿10次/组,每日两次;床上端坐位10 min/次,每日两次。每日对肌力进行评估并记录。机械通气第5天起以主动运动为主,被动运动为辅。主动运动:拉皮筋锻炼;床上端坐位15 min/次,每日两次;上肢屈伸10次/组,每日两次;下肢屈膝脚尖内收10次/组,每日两次;屈膝蹬腿10次/组,每日两次;直腿抬高、支腿外展5次/组,每日两次。

CBF的最大长度为


式中:k为CBF所使用的哈希函数的个数,n为在一个时间窗口内到来的流的总数量。将式(4)~(6)带入式(2)中,得

CBF在一个时间窗口内的最大误正率[8]为
由于x越大,算法的漏检率越低,因此将x视为α的函数,问题将转换为一个简单的数学问题,即在一个一元函数中,自变量α为何值时,函数x取得最大值。下面先确定式(7)中其余各个参数的取值。
根据式(3)可知,若大流首次出现时未通过CBF,则其流量的测量误差不高于T1/T2,可以设置(T1/T2)≤ε(例如ε=1%),将该误差控制在一个较低的水平,此时,有T1≤εT2。由于大流通常被定义为占链路容量超过一定比例的流,设链路容量为V,故大流阈值T2=βV(β通常取0.01%,0.1%,1%等值)。综上,知T1≤εβV。因为PT1(0<PT1
<1)表示一个分组属于字节数小于T1的流的概率,所以当T1选定时,PT1可由历史信息统计得到。
若已经进入CBF的流的数量为n',哈希函数的个数k=mln2/n',此时 CBF 的误正率取得最小值[9],但是在一个时间窗口内n'是不断变化的,所以k将依据经验值确定。式(7)中参数l1,l2的取值可由对CBF,LRU的设计得到,参数a,b由经验值确定,缓存空间C由系统分配。
计算出使x最大的最佳值α后,根据式(4)和(5)可以得到LRU队列的最大长度N以及CBF的长度m。
4 实验验证
本文实验所用流量数据来自于MAWI工作组和CADIA组织在互联网骨干链路上通过全流量采集得到,数据描述如表1所示。

表1 数据集描述
4.1 实验参数
测量时间τ=10 s,将Trace-1中的大流阈值T2设为链路容量的0.1%,Trace-2中的大流阈值T2设为链路容量的0.01%。测量误差ε设为1%,T1取上限值,即T1=εT2。时间窗口的长度W取下限值,即W=τT1/T2。CBF的每一项只包含一个2 byte的计数器,故l1=2;LRU每一项包括流关键字13 byte(采用五元组),流大小计数器4 byte(可以记录最大值为4 Gbyte的流),指针8 byte(用以实现双向链表以加快LRU队列的访问速度),故l2=25。参数a=0.2,b=0.8,哈希函数个数k=3,当缓存容量C给定时,由式(4)、(5)、(7)分别确定N,m,α的取值,如表2所示。
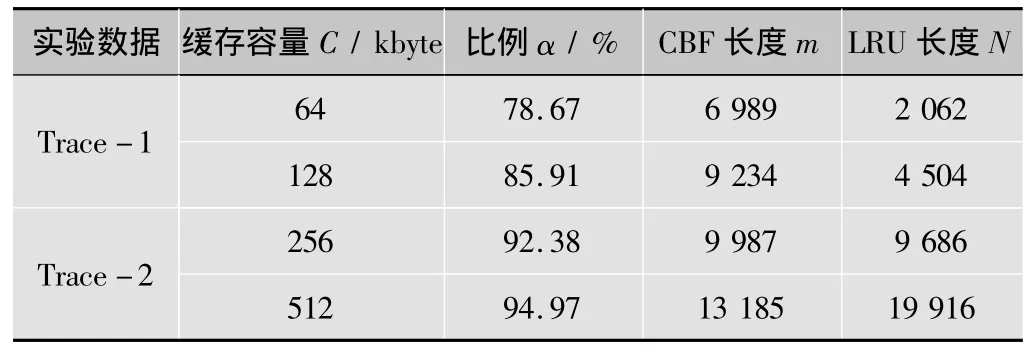
表2 缓存容量分配
4.2 实验结果对比与分析
将本文所提算法与 LRU算法、文献[5]提出的LRU2-V2算法进行对比,算法优劣的评价指标为大流漏检率和大流流量测量的平均误差,为了保证公平性,三者均使用相同的缓存容量,实验结果如表3所示。

表3 实验结果对比
从表3中可以看到,LRU算法的漏检率和平均误差都比较大,不能满足实际的应用。LRU2-V2算法的各个评价指标都比较小,与LRU算法相比具有明显的优势,而本文所提出的LRU-CBF算法要优于LRU2-V2算法。与LRU2-V2算法相比,LRU-CBF算法的不同点在于使用了CBF作为小流过滤器,由于CBF仅作为过滤器使用时消耗的存储空间很小,故在同等存储空间的条件下,可以有更多的存储资源用于LRU,因此对大流的检测效果更佳。通过实验对比,证明了LRU-CBF算法不仅能有效降低大流漏检率,同时还提高了大流流量的测量精度。
5 结束语
由于网络庞大,使得网络流量测量过程中所需采集的数据量巨大[10],这为网络流量的测量带来了巨大挑战,大流检测问题正是基于这一现状提出的。现有的基于LRU的大流检测算法大多存在漏检率较高的问题,无法满足实际的应用需求,故本文采用了一种CBF与LRU两级结构的大流检测算法。该算法使用CBF来进行第一步过滤,滤除网络中数量众多的小流,滤出可能的大流,而使用LRU对滤出的大流做进一步筛选。在存储资源相同的条件下,该算法的大流漏检率低,对大流流量的测量精度高,因此能更好地应用于实际的网络流量测量当中。
:
[1] ZHANG Y,BRESLAU L,PAXSON V,et al.On the characteristics and origins of Internet flow rates[C]//Proc.ACM SIGCOMM.Pittsburgh:[s.n.],2002:309-322.
[2] SMITHA A,KIM I,Reddy ALN.Identifying long term high band width flows at a router[C]//Proc.HiPC.Berlin:Springer,2001:361-371.
[3]张果,陈庶樵,张震,等.基于MGLRU的IP流统计算法[J].计算机工程,2010,36(17):140-146.
[4]王风宇,云晓春,王晓峰,等.高速网络监控中大流量对象的提取[J].软件学报,2007,18(12):3060-3070.
[5]裴育杰,王洪波,程时端.基于两级LRU机制的大流检测算法[J].电子学报,2009,37(4):685-691.
[6]谢冬青,周再红,骆嘉伟.基于LRU和SCBF的大象流提取及其在DDoS防御中的应用[J].计算机研究与发展,2011,48(8):1517-1523.
[7]张娟娟,高仲合,马兆丰.基于滑动窗口的LRU大流检测算法[J].通信技术,2012,45(10):684-691.
[8]杨家海,吴建平,安常青.互联网络测量理论与应用[M].北京:人民邮电出版社,2009.
[9]胡广昌.基于Bloom Filters流抽样算法的研究[D].曲阜:曲阜师范大学,2010.
[10]朱庆弦,张杰,张骏温.网络管理技术的发展趋势[J].电视技术,2005,29(12):54-56.
