基于改进BP神经网络的脱机手写文字识别
2014-09-18焦微微巴力登
焦微微,巴力登
(新疆大学 电气工程学院,新疆 乌鲁木齐 830047)
近些年来,脱机文字识别在网络安全(验证码识别)、智能交通管理系统(车牌识别)等社会生活的各个领域发挥着重要作用。在文字识别的探索和研究过程中,学者和专家已经提出了许多有效的识别方法,例如模板匹配法、隐马尔科夫模型(HMM)、支持向量机(SVM)、神经网络法[1-4]等等。在这些方法中,神经网络具有很强的学习性和自适应性,而且具有其他传统方法不具有的并行处理能力[5]、容错能力和自学习功能,因此其在自动化控制、模式识别等领域已经实现应用并取得较好的效果。但是在实际应用中传统神经网络存在局部最优点、过拟合等现象,对其在文字识别中的应用造成一定的限制。
本文通过对现有各种文字分类系统深入研究,针对标准BP算法存在局部最优解、训练时间长、收敛速度慢等缺点,利用Levenberg-Marquardt(LM)算法对神经网络模型进行优化,并通过对手写数字和手写汉字的识别来验证该方法的有效性和可行性。
1 改进的BP神经网络算法
标准BP算法理论上讲虽然具有逼近任意非线性连续映射的能力。但是在实际应用中容易出现训练时间长、收敛速度慢、往往收敛于局部极小点等缺陷。所以在实践过程中基本上都要对标准BP网络进行改进。目前,改善标准BP网络性能的方法主要有以下两类[6]:第一,采用启发式信息技术,如加入动量项、采用自适应学习率;第二,采用数值优化技术,如牛顿法、共轭梯度法、Levenberg-Marquardt[7](LM)法。采用第一类方法虽然在一定程度上可以改进标准BP网络,但是却会出现训练速度慢和训练误差输出较大的问题。所以本文运用数值优化技术中的LM算法对标准BP神经网络进行改进。
LM算法是梯度下降法与Newton法的结合,也可以称为是Newton法的改进形式。LM算法既具有Newton法的局部收敛性,又具有梯度法的全局特性。LM算法是通过自适应调整阻尼因子来达到收敛特性,此外它所具有的更高迭代收敛速度的优点在很多非线性优化问题中求得了稳定可靠解。
本文采用的LM算法主要优化的是BP神经网络的权值和阈值,其迭代公式为
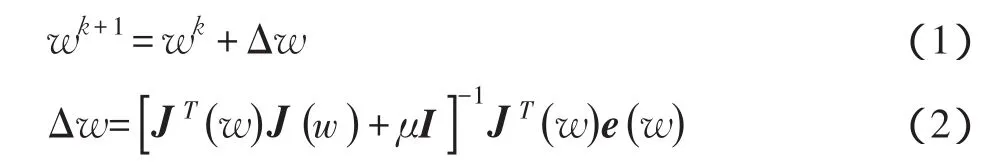
式中:e(w) 为实际输出与期望输出Yi的误差,即;I为单位矩阵;μ为小的正数(学习率);J(w) 为Jacobean矩阵,即
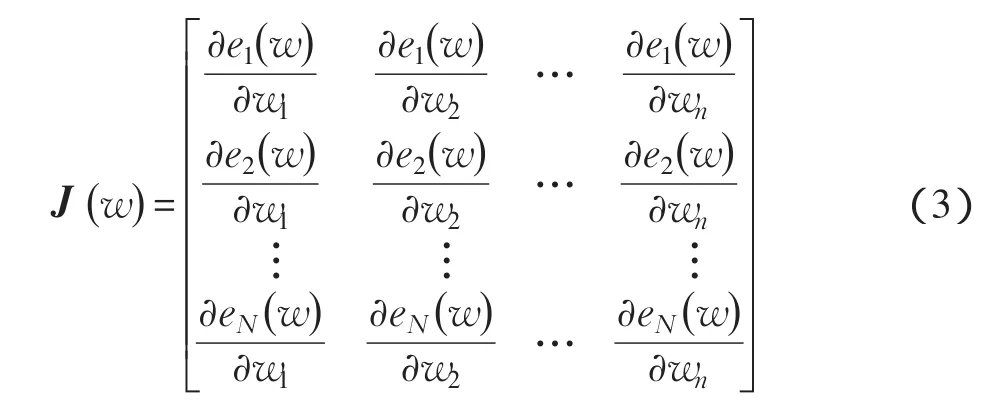
2 脱机文字识别系统
脱机文字识别系统[8]的整个过程主要分为文字图片的输入、预处理、特征提取和分类识别几个阶段,如图1所示。

图1 脱机文字识别系统的识别过程
2.1 预处理
预处理过程主要包括二值化、分割等。预处理不仅可以增强图像、减小噪声和失真,还有助于实现更高更精确的识别结果。优质的图像对神经网络模型的建立起到非常重要的作用。因此,在任何文字识别系统中,预处理[9]阶段的存在都是必不可少的。
2.2 特征提取
特征提取的目的是从原始数据中抽取出用于区分不同类型的本质特征。特征向量选取的好坏对识别结果同样会造成很大的影响。因此所提取出的特征必须具有良好的可靠性、区别性、相互独立性和不关联性。另外为了减少识别系统的负担,特征维数也要适当控制。
2.3 基于LM-BP神经网络的识别分类
由于LM-BP算法主要改变的是BP网络的权值和阈值,所以改进前后BP神经网络的结构没有发生变化,所以本文选用的BP神经网三层,其中输入层神经元数为14;根据隐含层神经元个数大约为输入层神经元个数的2倍关系[10],取28作为隐含层的节点个数。
其中LM-BP算法具体步骤如下:
1)给出训练误差允许值ε、常数μ0和β(0<β<1),以及初始化权值和阈值向量w0,并且令k=0,μ=μ0;
2)将提取出的特征向量输入到BP网络中,并计算网络的输出;
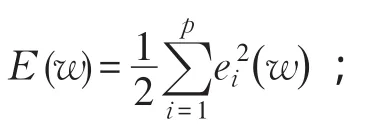
4)计算Jacobean矩阵J(wk);
5)计算权值和阈值的变化率Δw;
6)若E(wk)<ε,转到步骤8);
7)用式(1)更新权值和阈值向量,并计算E(wk+1)。若E(wk+1)<E(wk),则令k=k+1,μ=μβ,转到步骤3);否则μ=μ/β,转到步骤5)。
8)满足终止条件,迭代结束。
3 仿真实验与结果分析
3.1 手写数字识别网络
以图2中的手写数字为训练对象,对BP神经网络及LM算法优化后的BP网络(LM-BP网络)进行训练,得出图3和图4所示的训练曲线,其中训练目标精度为0.01。

图2 手写数字图像
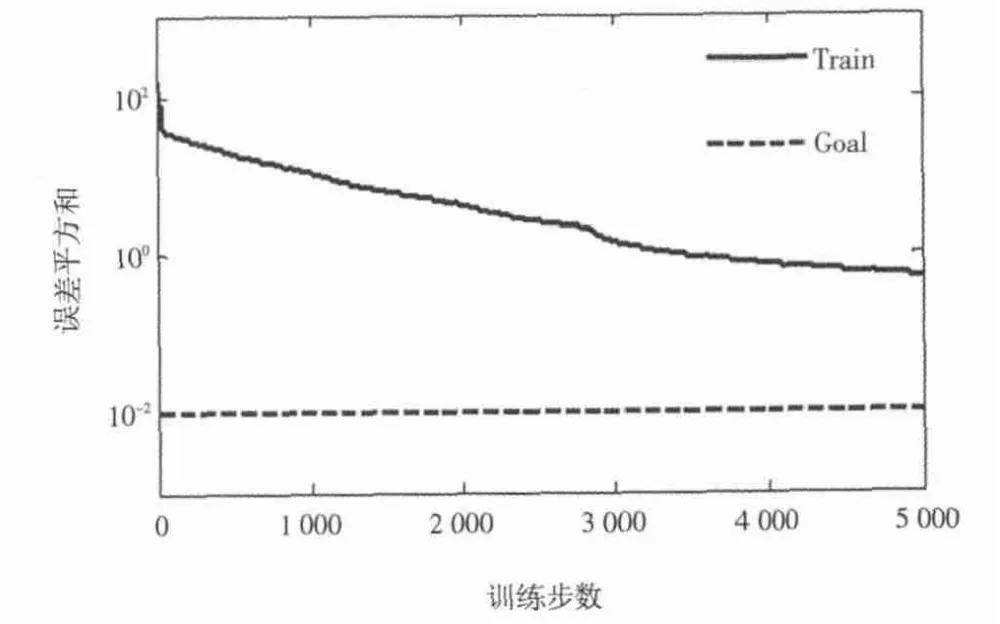
图3 BP网络训练曲线
从图3可以看出,BP网络经过5 000步才完成训练过程达到收敛,训练曲线一直都是缓慢下降,收敛速度很慢,而且最终训练误差为0.511,未达到训练误差目标精度。图4中LM-BP网络到7步时,训练误差为0.005 81,已经达到误差目标精度,收敛速度较快。所以,LM-BP算法不仅加快了收敛速度,而且产生的误差也很小,是一种可行的BP网络改进算法。

图4 LM-BP网络训练曲线
3.2 手写汉字识别网络
如图5所示的手写“新疆大学电气工程学院”为训练对象,对改进前后神经网络的性能进行对比,同样可以得出LM-BP算法的收敛速度比标准BP算法要快很多,误差也小很多。从表1中列出的识别率比较还可以看出,LM-BP算法的识别率要高于标准BP算法,所以改进算法确实有效可行。

图5 手写汉字图像
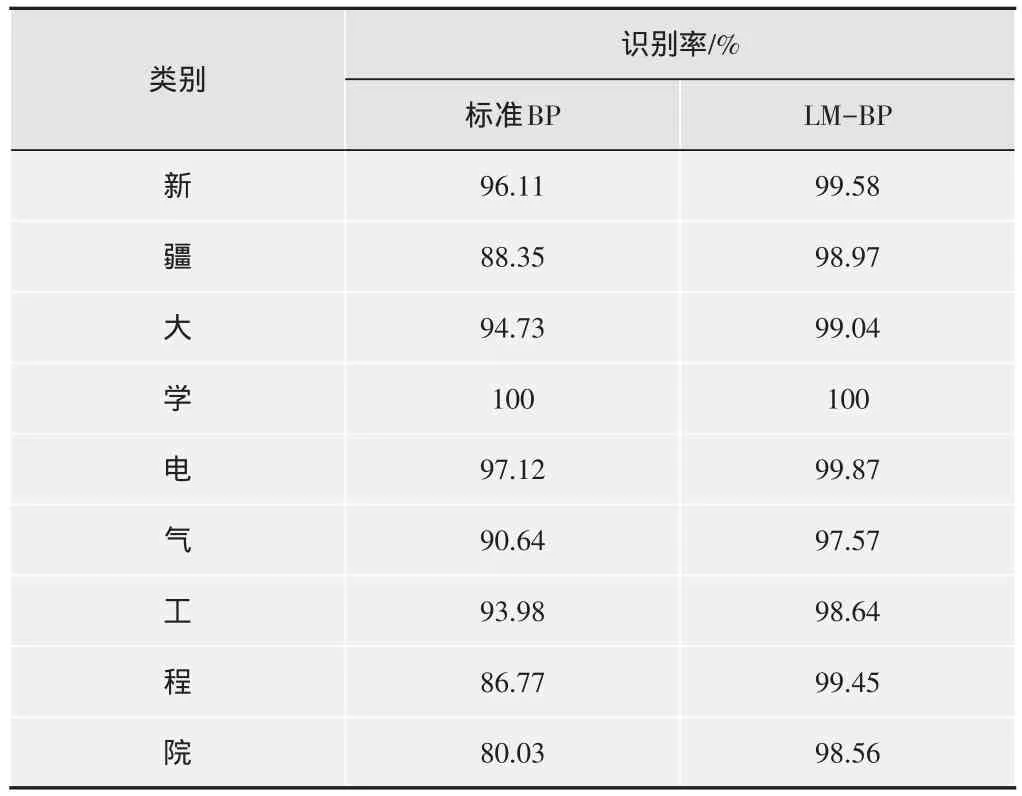
表1 两种算法的识别率比较
4 结论
本文将基于LM-BP神经网络算法分别用于脱机手写数字和脱机手写汉字的识别,通过LM算法优化BP网络的阈值和权值,很好地弥补了标准BP算法存在的收敛速度慢、训练时间长、训练误差大的缺陷。从实验结果可以看出,本算法除了获得较短的训练时间、较快的收敛速度和较小的训练误差之外,还提高了脱机手写汉字的识别率,为下一步的研究奠定了基础。此外,本方法同样适用于其他文字的识别,例如维吾尔语、蒙古语等。但是在本次研究中训练集的类别还是过于少,且数字和汉字只能分别进行识别。接下来的工作就是尽量克服这一缺点,并采用更为合适的特征提取方法,为大字符库的识别研究做准备。
:
[1]陈玮,曹志广,李剑平.改进的模板匹配方法在车牌识别中的应用[J].计算机工程与设计,2013,34(5):1808-1811.
[2]KESSENTINI Y,PAQUET T,HAMADOU A B.Off-line handwritten word recognition using multi-stream hidden markov models[J].Pattern Recognition Letters,2010,31(1):60-70.
[3]SHANTHI N,URAISWAMY K.A novel SVM-based handwritten tamil character recognition system[J].Pattern Analysis and Applications,2010,13(2):173-180.
[4]KALAICHELVI V.Application of neural networks in character recognition[J].International Journal of Computer Applications,2012,12(52):183-192.
[5]张玲,张鸣明,何伟.基于BP神经网络算法的车牌字符识别系统设计[J].电视技术,2008,32(S1):140-142.
[6]龚立雄,姜建华.基于L-M算法的BP神经网络模型机械加工误差预测模型[J].机床与液压,2013,41(11):67-71.
[7]孟博,李荣冰,刘建业,等.基于改进反向传播算法的跨音速攻角步长修正研究[J].系统工程与电子技术,2010,32(12):117-119.
[8]BARVE S.Optical character recognition using artificial neural network[J].International Journal of Advanced Research in Computer Engineering&Technology,2012(4):131-133.
[9]PERWEJ Y.Machine recognition of handwritten characters using neural networks[J].International Journal of Computer Applications,2011,12(14):196-204.
[10]杨淑莹.模式识别与智能计算——Matlab技术实现[M].北京:电子工业出版社,2011:147-157.
