基于预测模型的传感器网络近似数据采集算法*
2014-09-13吴中博徐德刚屈俊峰
王 敏,吴中博,徐德刚,屈俊峰,吴 钊
(湖北文理学院数学与计算机科学学院,湖北 襄阳 441053)
基于预测模型的传感器网络近似数据采集算法*
王 敏,吴中博,徐德刚,屈俊峰,吴 钊
(湖北文理学院数学与计算机科学学院,湖北 襄阳 441053)
基于模型的数据采集技术可以有效抑制不必要的数据传输,节省能量开销,已经在传感器网络中得到广泛应用。对传统基于模型的数据采集进行了改进,提出基于卡尔曼滤波器的近似数据采样算法ADCA。ADCA可以在一定误差范围内有效获取数据。空间相近的节点被组织成簇,簇头和成员分别建立卡尔曼滤波模型,并保存对方的镜像模型。簇头节点可以为成员节点产生近似的数据,所以用户查询可以通过簇头来回答。实验表明ADCA具有较好的性能。
预测模型;传感器网络;近似算法;数据采集
1 引言
在传感器网络中,大量传感器节点自组织形成网络,节点采样后通过多跳的方式将数据传回基站。节点都是电池供电的,而且由于部署环境复杂,一般难以更换电池,节约能量、延长传感器网络生命周期成为传感器网络研究的热点问题。节点的能量开销包含计算代价、通信代价、采样代价等,其中通信消耗能量远远高于其他的能量消耗,所以我们在设计算法时以最小化通信开销作为目标。研究人员在路由协议、事件监测算法、网内聚集等算法、近似数据采集等很多层面都提出了算法,以减少节点的通信开销。
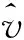
对于类似的技术,每个节点单独估计其采样。我们注意到,临近的节点之间具有空间相关性,它们往往具有相似的变化趋势。我们提出近似数据采集算法ADCA(Approximate Data Collection Algorithm),ADCA算法的目标是在阈值范围内有效预测节点的采样。ADCA算法利用卡尔曼滤波器,利用先前的预测值和当前的采样值来预测下一个采样值。预测采样时利用了节点的空间相关性,节点的采样值是在变化的,但是对于具有空间相关性的不同节点而言,他们之间的差是相对稳定的。为了利用空间相关性,我们把节点组织成簇,每个簇有一个簇头,簇头负责估计其采样值和节点采样之间的差。
论文组织如下,第2节介绍相关工作,第3节介绍卡尔曼滤波器,第4节介绍我们的算法,第5节是实验,最后是总结。
2 相关工作
传感器网络包含了大量的节点,将所有数据收集上来是不现实的,会导致节点浪费过多能量,对原始数据进行数据聚集然后再进行传送,可以避免传送大量的原始信息所带来的通信开销。在数据聚集方面,文献[1]提出了TAG(Tiny Aggregation)算法。TAG算法在网内构造树结构,数据从叶子节点沿路由树向基站节点传送,中间节点不断进行聚集计算得到部分聚集值,最后根节点得到最终的聚集值。文献[2]采用多路径传输算法对TAG算法进行了改进,对于距离基站较远的节点采用路由树结构,降低网络能量开销;对于距离基站较近的节点采用多路径路由,可以有效降低数据丢失率。
另外一个比较简单的减少通信开销的方法是采用时间抑制方法,节点仅当其采样发生变化后才传输数据。这种策略适合于环境比较稳定的情况。然而,节点的采样会随着时间的变化而变化。当节点采样变化比较剧烈时,节点将频繁发送采样数据到基站,其能量将很快消耗殆尽。
大多数的应用不需要高度精确的数据,所以开发了一些近似的数据采集技术。为了估计节点采样,Madden S R[3]提出了PAQ(Probabilistic Adaptable Query)算法。PAQ算法基于静态的自回归的时间序列模型,提出了一种动态的自回归模型来进行采样值的预测:
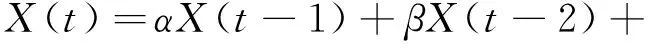
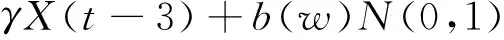
(1)
其中,b(w)N(0,1)表示零均值和标准差的高斯白噪声。为了比较精确地进行采样预测,需要合适的α、β、γ,PAQ需要很长的学习过程以建立静态数据模型。
文献[4]介绍了Snapshot查询方法。节点可以和邻居合作,选择一个代表性节点的集合。代表性节点使用线性回归来预测他们邻居节点的采样。为了保持代表性节点的集合,作者假设每个节点知道他的邻居的采样值。所以,节点必须周期性地广播其采样给邻居,这将会消耗过多的能量。由于代表性节点在非广播周期不知道其他节点的采样,所以不能保证误差范围。
3 卡尔曼滤波器
有许多方法被用来预测传感器节点的采样值,例如线性回归、贝叶斯网络方法等。卡尔曼滤波器也是常用的一种算法,用来解决离散数据的线性滤波问题。卡尔曼滤波器可以用在很多场合,例如信号处理、模式匹配等。文献[5]提出了一种自适应容积卡尔曼滤波算法,构造了一组噪声统计估计器对噪声的统计特征进行实时估计,在测量异常时利用修正函数对滤波过程进行修正,可以有效提高滤波估计的精度,并对滤波发散有较好的抑制能力。文献[6]针对无线传感器网络数据融合时的丢包问题,对传统扩散卡尔曼滤波进行了改进,并给出了丢包问题的改善方案。文献[7]在基于接收信号强度RSSI(Received Signal Strength Indication)测距、三边测量法初始定位的基础上,提出以接收信号强度为观测量,将无迹卡尔曼滤波UKF(Unscented Kalman Filter)应用到节点精确定位中。
卡尔曼滤波器是由数学方程估计的内部状态系统使用一个预估-校正型的估计,如图1所示。
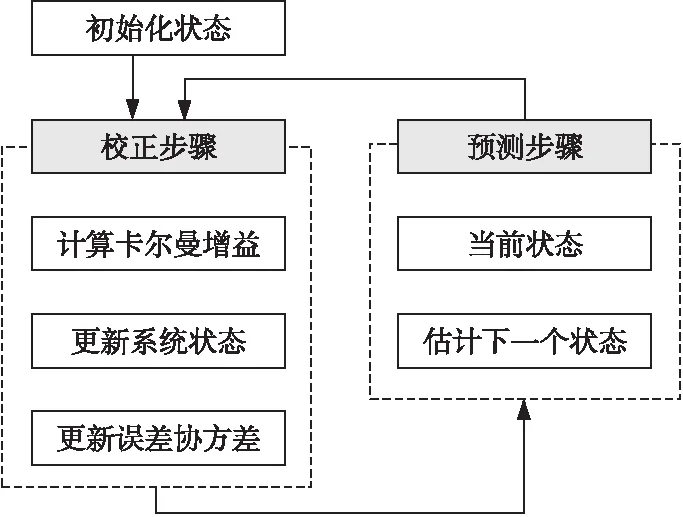
Figure 1 Model of Kalman filter图1 卡尔曼滤波模型
在卡尔曼滤波器中,系统模型用公式(2)和公式(3)表示:
(2)
zk=Hxk+vk
(3)
其中,公式(2)表示处理模型。
(4)
(5)
在离散的卡尔曼滤波器中,公式(4)预测未来采样。公式(5)是对估计的修正。n×m矩阵Kk被称为卡尔曼增益。
(6)
(7)
然后,后验误差估计协方差用公式(8)导出:
(8)
卡尔曼滤波器不存储之前的数据集,为了在k时刻预测下一个采样,卡尔曼滤波器仅仅需要k时刻的测量值和k-1时刻的预测值。
4 ADCA算法
传感器节点能量有限且无法进行远距离的传输,因此传感器节点在部署时密度会比较高。位置相近的传感器节点感知的数据也会比较相似,它们之间存在着空间相关性[8~10]。这一节,介绍我们提出的ADCA算法。ADCA算法将节点组织成簇,通过空间关系监视节点采样。对于传感器节点而言,通信开销远远大于计算开销,所以我们不考虑计算开销。假设所有节点具有相同的通信距离c,簇头通过多跳和基站通信。
假设簇头CH有两个成员n1和n2。在之前的工作中,每个节点保持它们自己的模型,独立预测未来采样。如图2所示,虚线表示估计值,实线表示实际采样值。如果估计值和实际值的差别高于实现规定的阈值,n1和n2将他们的采样传给簇头。在簇头收集了成员的采样值后,其将所有数据传给基站,上述描述中需要至少三条消息。n1和n2各发一条消息给簇头,簇头发一条消息给基站。
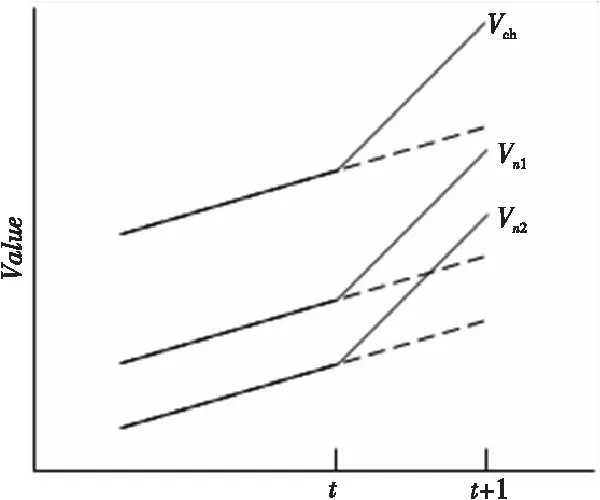
Figure 2 Example of model based data collection图2 基于模型的数据采集示例
我们对此进行了改进。簇头将其采样广播给成员,成员如果不反馈,簇头就知道他们依然保持空间相关性,这样就只需要发送两条消息。
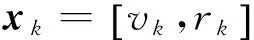
(9)
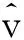
如图3所示,簇头节点CH具有卡尔曼滤波器KFch,用于估计vch。每个成员节点也保持KFch。每个成员ni节点同时还具有卡尔曼滤波器KFdni,以估计其采样和簇头采样之间的差dni。

Figure 3 Kalman filter in cluster图3 分簇下的卡尔曼滤波器

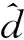
□
5 实验
在这一节,验证所提出算法的效率,比较ADCA、PAQ、Snapshot方法的性能。用OMNET++仿真平台来模拟算法过程,实验设置如下,传感器网络包含100个节点,部署在100m×100m的区域。基站部署在区域的中央,节点的通信距离是20m。实验数据采用合成的数据集。我们使用正弦函数构造,为每个地点的节点分配[0.0,50.0]的数值,具有相同x坐标的节点具有同样的值,然后我们模拟波浪从左往右垂直移位。为了测量不同环境下的能量消耗,我们使用三种误差范围0.2、0.1和0.05。
节点传输m-bit的消息给距离c外的节点将消耗:
(10)
接收消息将消耗:
(11)
其中,Eelec表示发送或接收单元消耗的能量,ξamp表示发送放大器消耗的能量。实验中将Eelec设置为50nJ/bit,将ξamp设置为100pJ/bit/m2。
图4展示了不同算法的能量消耗情况。总的来说,随着误差范围的增加,需要传输的数据减少了,能量的消耗也变少了。图5展示了误差范围为0.1的情况下,传感器网络运行至第一个节点失效时的情况。图5中左图表示100个节点的情况,右图表示500个节点的情况。Snapshot算法中节点必须周期性地广播其采样给邻居,这将会消耗过多的能量,所以它表现出的性能最差。PAQ算法基于自回归模型,需要一个很长的学习阶段。当数据相对稳定时,PAQ算法可以精确地估计未来采样值。然而,我们的数据集中,节点采样随着时间的变化在不断变化,所以PAQ算法的表现也不如ADCA算法。相比较而言ADCA算法表现出了更优异的性能。
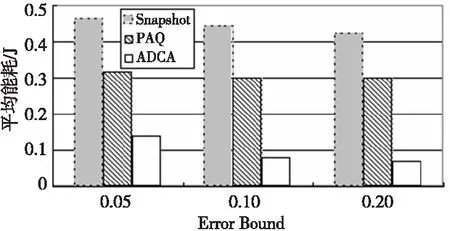
Figure 4 Average energy consumption图4 平均能量消耗
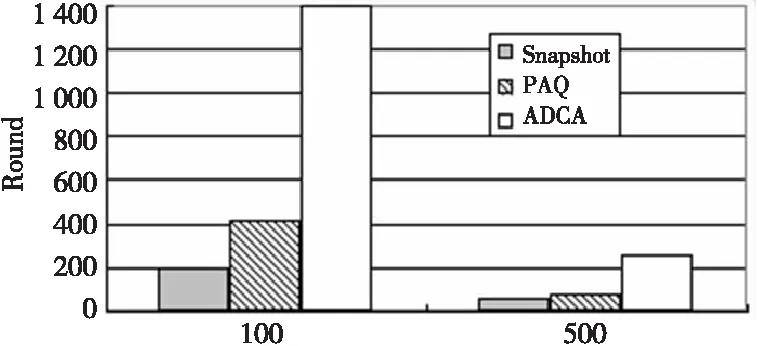
Figure 5 Rounds of first sensor failure图5 第一个节点失效时数据采集的轮数
6 结束语
本文对传统基于模型的数据采集进行了改进,提出基于卡尔曼滤波器的近似数据采样算法ADCA。ADCA算法将空间相近的节点组织成簇,簇头和成员分别建立卡尔曼滤波模型,并保存对方的镜像模型。簇头节点可以在成员节点不传输数据的情况下预测其采样,从而大大降低通信开销,实验表明ADCA具有较好的性能。
[1]MaddenSR,FranklinMJ,HellersteinJM,etal.TAG:Atinyaggregationserviceforad-hocsensornetworks[J].ACMSIGOPSOperatingSystemsReview, 2002, 36(SI):131-146.
[2]MaddenSR,FranklinMJ,HellersteinJM,etal.TinyDB:Anacquisitionalqueryprocessingsystemforsensornetworks[J].ACMTransactionsonDatabaseSystems(TODS), 2005, 30(1):122-173.
[3]TuloneD,MaddenSR.PAQ:Timeseriesforecastingforapproximatequeryansweringinsensornetworks[C]∥EuropeanWorkshoponWirelessSensorNetworks, 2006:21-37.
[4]KotidisY.Snapshotqueries:Towardsdata-centricsensornetworks[C]∥Procofthe29thInternationalConferenceonDataEngineering(ICDE), 2005:131-142.
[5]AoZhi-gang,TangChang-chun,FuCheng-qun,etal.Multi-sensoradaptivecubatureKalmanfilterdatafusionalgorithm[J].ApplicationResearchofComputers, 2014, 31(5):1312-1315.(inChinese)
[6]NieWen-mei,LuGuang-yue.ImproveddiffusionKalmanalgorithmwithpacket-droppinginwirelesssensornetworks[J].JournalofXi’anUniversityofPostsandTelecommunications, 2013, 18(4):9-12.(inChinese)
[7]DuJuan-juan.ApplicationofunscentedKalmanfilteralgorithmtonodelocalizationinwirelesssensornetworks[J].JournalofNanjingUniversityofPostsandTelecommunications(NaturalScience), 2013, 33(1):84-90.(inChinese)
[8]JindalA,PsounisK.Modelingspatiallycorrelateddatainsensornetworks[J].ACMTransactionsonSensorNetworks, 2006, 2(4):466-499.
[9]WangC,MaH,HeY,etal.Adaptiveapproximatedatacollectionforwirelesssensornetworks[J].IEEETransactionsonParallelandDistributedSystems, 2012, 23(6):1004-1016.
[10]FatchB,GovindarasuM.Energyminimizationbyexploitingdataredundancyinreal-timewirelesssensornetworks[J].AdHodNetworks, 2013, 11(6):1715-1731.
附中文参考文献:
[5] 敖志刚, 唐长春, 付成群,等. 多传感器自适应容积卡尔曼滤波融合算法[J]. 计算机应用研究, 2014, 31(5):1312-1315.
[6] 聂文梅, 卢光跃. 无线传感器网络中丢包扩散卡尔曼算法的改进[J]. 西安邮电大学学报, 2013, 18(4):9-12.
[7] 杜娟娟. 无迹卡尔曼滤波在无线传感器网络节点定位中的应用[J]. 南京邮电大学学报(自然科学版), 2013, 33(1):84-90.
WANGMin,born in 1982,MS,lecturer,CCF member(E200037518M),her research interests include database, and sensor network.

吴中博(1980),男,湖北襄阳人,博士,副教授,CCF会员(E200027710M),研究方向为数据库、数据挖掘和传感器网络。E-mail:rucwzb@163.com
WUZhong-bo,born in 1980,PhD,associate professor,CCF member(E200027710M),his research interests include database, data mining, and sensor network.
Anapproximatedatacollectionalgorithmbasedonpredictionmodelinsensornetworks
WANG Min,WU Zhong-bo,XU De-gang,QU Jun-feng,WU Zhao
(School of Mathematics and Computer Science,Hubei University of Arts and Science,Xiangyang 441053,China)
The model-based data collection technology which can inhibit unnecessary data transportation and save energy effectively has been widely applied in sensor networks. We improve the traditional model-based data collection technology and put forth an approximate data collection algorithm based on the Kalman filter,called ADCA, which can collect data effectively within a given range of error.In ADCA,sensor nodes are organized as clusters.Cluster header and cluster members build the Kalman filter respectively and save their mirror models.Cluster header can produce approximate data for cluster members,so some user queries can be answered by cluster header.Experiments show that ADCA has good performance.
prediction model;sensor network;approximate algorithm;data collection
1007-130X(2014)11-2148-05
2014-06-25;
:2014-08-29
国家自然科学基金资助项目(61202046)
:吴中博(rucwzb@163.com)
TP274
:A
10.3969/j.issn.1007-130X.2014.11.016

王敏(1982),女,山西晋城人,硕士,讲师,CCF会员(E200037518M),研究方向为数据库和传感器网络。E-mail:meiwen1982@qq.com
通信地址:441053湖北省襄阳市隆中路296号湖北文理学院数学与计算机科学学院
Address:School of Mathematics and Computer Science,Hubei University of Arts and Science,296 Longzhong Rd,Xiangyang 441053,Hubei,P.R.China
