α优势关系下粗糙集模型的属性约简
2014-09-13韦碧鹏吕跃进李金海
韦碧鹏,吕跃进,李金海
(1.柳州职业技术学院 公共基础部,广西 柳州 545006; 2. 广西大学 数学与信息科学学院,广西 南宁 530004; 3.昆明理工大学 理学院,云南 昆明 650500)
波兰数学家Pawlak于1982年提出了粗糙集理论[1],它是一种处理模糊、不精确性以及不确定性的数学工具。近年来,由于它具有诸多优势,已经被成功地运用于数据挖掘、模式识别、数据处理、决策分析等领域[2-4]。然而,在现实生活中,由于噪声、测量数据的不完整性等因素,不完备信息系统依然广泛存在。而Pawlak提出的经典粗糙集并不适用不完备信息系统。这就有必要对它进行扩充以适用于处理不完备数据。目前,针对不完备信息系统缺失值的不同理解,对经典粗糙集的扩充研究有如下模型:Kryszkiewicz[5]提出了基于容差关系的粗糙集模型,把不完备信息系统中的缺失值看作是遗漏型的,即可以和任意的对象进行比较;Stefanowski等[6]提出了基于非对称相似关系和量化容差关系的粗糙集模型,把不完备信息系统中的缺失值看作是缺席型的;为了克服扩展模型的不足,王国胤[7]又给出了基于限制容差关系的粗糙集模型。这方面的更多研究,可以查看文献[8-10]。
在现实世界中,很多的信息系统其属性值域可能具有偏序性。此时,经典粗糙集方法显得无能为力。为了能够处理具有偏序关系的信息系统,Greco等[11]提出了基于优势关系的粗糙集模型,即运用优势关系代替等价关系。为了让优势关系下的粗糙集模型能够同时处理缺失值,Shao等[12]把不完备序信息系统中的缺失值看作是遗漏型的,提出了基于优势关系的不完备序信息系统,并讨论了属性约简和规则提取。针对文献[12]提出的优势关系过于宽松,容易将实际不满足条件的对象误判为同一个优势类,胡明礼等[13]通过引入一个阈值得到了广义扩展优势关系的概念,并对规则提取进行了重新考虑。此外,针对优势系统中缺失值是缺席型的情况,杨习贝等[14]提出了相似优势关系的粗糙集模型,并对属性约简做了研究。然而这并没有弥补文献[12]提出的优势关系过于宽松的缺陷,并且改进后的模型还容易将一些本属于同一决策类的对象误判为不同决策类。这在一定程度上会影响文献[12]提出的模型决策分析的效果。因此,Luo 等[15]进一步又给出了限制优势粗糙集模型,既可以避免文献[12]提出的优势关系过于宽松的现象,又不容易将一些本属于同一决策类的对象误判为不同的决策类。但文献[15]提出的限制优势关系在某些情况下又显得过于严格,例如:当2个对象在各属性下的取值为x=(4,3,2,1),y=(*,*,2,1)时,且各属性值域的最大值均为4,那么根据文献[15]提出的限制优势关系,对象x是不优于对象y的;可现实生活中,对象x优于对象y的可能性是非常大的,这有可能导致数据集中的决策规则没有充分提取。
基于此,本文在分析不完备序信息系统中现有的几种扩展粗糙集模型的基础上,提出了基于α优势关系的粗糙集模型,它既吸收了其他扩展模型的优点,又能有效克服它们的局限性,更有利于处理现实中的数据集。此外,基于α优势关系的粗糙集模型,给出了不完备序信息系统和序决策系统的区分矩阵属性约简算法,并表明了其区分矩阵只能运用属性集的幂集进行构造,而不能简单地运用单属性集进行构造。
1 基本概念

若存在一个属性a∈AT使得Va为空值(记作:f(x,a)=*),则称该信息系统是不完备的信息系统,记作:IIS;否则称为完备的信息系统。
定义1[11]设IS=(U,AT,V,f)是一个完备信息系统,对于∀A⊆AT,∀x,y∈U,有:
∀a∈A}



定义2[12]设IIS=(U,AT,V,f)是一个不完备信息系统,对于A⊆AT,∀x,y∈U,有
∀a∈A,f(x,a)≥
f(y,a)∨f(x,a)=*∨f(y,a)=*}


⊆X}

通过分析定义2,可以得出文献[12]在不完备序信息系统中提出的优势关系是以空值可以等于任意值为假设前提的,即认为空值可以优于任意值,同时又认为任意值可以优于空值,这显然不符合实际情况。例如:当x=(1,1,*),y=(1,1,4),z=(*,*,4)时,其中“4”表示属性值下最大的取值,“1”为属性值下最小的取值。根据定义2进行分析可得:

定义4[15]设IOIS=(U,AT,V,f)是一个不完备序信息系统,对于A⊆AT,∀x,y∈U,对象在属性集A下的限制优势关系为
∀a∈A,f(x,a)≥
f(y,a)∨(f(x,a)=maxVa∧f(y,a)=
*)∨(f(x,a)=*∧f(y,a)=minVa)}∪IU

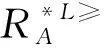
⊆X}


2 α优势关系的粗糙集模型
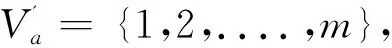
定义6 设IOIS=(U,AT,V,f)是一个不完备序信息系统,对于∀a⊆AT,∀x,y∈U,对象在属性a下的取值为Va={a1,a2,...,am},并且a1 从定义6中得知,在单属性下,2个对象优于的程度在0和1之间。当对象x在属性a下取值完全小于对象y的取值时,用数值0来表示对象x劣于对象y的程度,即概率;当对象x在属性a下取值完全大于对象y的取值时,用数值1来表示对象x优于对象y的程度。然而,当对象x和对象y有一个缺失值时,且对象在属性下取值的多样性,使得很难确定2个对象的优于程度;根据概率的含义,即在m个数中,有n个数优于一个确定数值的概率为n/m,得出定义6,2个对象中有一个为缺失值时它们的优于程度。当2个对象都为缺失值时,没有根据可以判别它们之间优于程度,因此,运用1/m概率来表示,意味着优于程度很小。 定义7 设IOIS=(U,AT,V,f)是一个不完备序信息系统,对于A⊆AT,∀x,y∈U,则对象x在属性集A下优于y的概率为 通过定义7,可以得出不完备序信息系统各个对象的优势类如下: 定义8 设IOIS=(U,AT,V,f)是一个不完备序信息系统,对于A⊆AT,∀x,y∈U,有 性质1 设IOIS=(U,AT,V,f)是一个不完备序信息系统,则α优势关系满足如下性质: 3)当B⊆A⊆AT时,∀x∈U, 性质2 设IOIS=(U,AT,V,f)是一个不完备序信息系统,对于A⊆ 三者优势关系满足如下性质: ⊆X}= 定义10表明了基于α优势关系的不完备序信息系统的属性约简保持的是对象的α优势类不变的最小属性组成的集合。基于此,下面给出其优势区分矩阵构造的方法: 定义11 设IOIS=(U,AT,V,f)是一个不完备序信息系统,对于∀x,y∈U,有 根据对以往知识的了解,区分矩阵的构造是可以仅仅在单元素下进行。但是,在α优势关系的粗糙集模型中,这样的构造是不成立的,如 假设基于α优势关系的优势区分矩阵可以如下构造: 在α优势关系的不完备序信息系统中,若添加决策属性d,则不完备序信息系统可以转变为IODS=(U,AT∪{d},V,f)情形,其中属性d也是一个准则,称之为决策属性,d∉AT且*∉Vd,则称IODS为不完备序决策系统。 从定义13中可以得出,基于α优势关系的不完备序决策系统的属性约简保持α优势关系的协调性不变的最小子集。下面给出其优势决策区分矩阵构造的方法。 定义14 设IODS=(U,AT∪{d},V,f)是一个不完备序决策系统,对于∀x,y∈U,有 例1 下面给出一个不完备序决策系统,其中U={1,2,3,4,5},AT={a,b,c}为条件属性,d为决策属性,且对象在单个条件属性a、b、c下最大的取值分别为4、3、3,最小值都是1。运用表1给出的不完备序决策系统来分析文献[12]提出的优势关系、文献[15]提出的限制优势关系以及本文提出的α优势关系之间的性能;并计算α优势关系不完备序信息系统与决策系统的属性约简。 表1 不完备序决策系统 1)把表1中的决策属性去掉,不完备序决策系统转化为不完备序信息系统,分析三者优势关系之间的关系。 ① 根据定义2,可得文献[12]提出的优势关系下,各个对象的优势类为: ③ 令α=0.6,根据定义8,可得α优势关系下,各个对象的α优势类为: 根据定义得出三者优势关系下各个对象的优势类,在文献[12]提出的优势关系下,对象4的优势类为对象2、4,然而在条件属性c下,由于对象4取得最大值,因此,对象2优于对象4的可能性是非常之小;另外,对象5的优势类为对象2、3、4、5,然而在条件属性a下,对象4优于对象5的可能性也是非常之小。因此,可以说文献[12]提出的优势关系划分的粒度过大了。在文献[15]提出的限制优势关系下,对象3的优势类为对象3,然而对象2优于对象3的可能性是非常之大。因此,说明了文献[15]提出的限制优势关系划分的粒度过细了。然而,在α优势关系下,设定确定的α取值,各个对象的优势类就不会出现上述的情况;可以看出,α优势关系吸取了上述两者优势关系的优点,丢弃了两者的缺陷,更加符合实际情况,更有利于去处理现实生活中存在复杂的不完备序信息系统。 2)不完备序信息系统的属性约简 根据定义11,结合α优势类,可以得出不完备序信息系统的优势区分矩阵如表2。 表2 优势区分矩阵 故Δ*≥=(a∨b∨c)∧(a∨b)∧a∧c∧(a∨c)∧(a∧b)∧(b∨c)=abc,即该不完备序信息系统的属性约简为abc。 3)不完备序决策系统的属性约简。 由于各个对象在决策属性下的优势类如下: 根据定义14,可以得出不完备序决策系统的优势决策区分矩阵如表3。 表3 优势决策区分矩阵 由于现实中处理的数据很多是不完备的,且存在偏序性,因此研究处理这种复杂数据情况的粗糙集方法是很有实际意义的。本文通过对现有优势关系的分析后提出了α优势关系及其相应的粗糙集模型,以使得对不完备序信息系统的数据分析更加合理。此外,在基于α优势关系的粗糙集模型上,给出了不完备序信息系统的优势区分矩阵以及不完备序决策系统的优势决策区分矩阵,从而实现了属性约简,同时也表明了区分矩阵只能运用属性集的幂集进行构造,而不能运用单个属性集进行构造。 需要指出的是,在α优势关系的基础上,还可以进一步研究不协调不完备序决策系统的属性约简算法,这是本文的下一步工作任务。 参考文献: [1]PAWLAK Z. Rough sets [J]. International Journal of Computer and Information Sciences, 1982, 11(5): 341-356. [2]张文修,吴伟志,梁吉业,等.粗糙集理论与方法[M].北京:科学出版社, 2001: 14-19. [3]李金海,吕跃进.决策系统的快速属性约简算法[J].电子科技大学学报, 2007, 36(6): 1237-1240. LI Jinhai, LÜ Yuejin. Quick attribute reduction algorithm on decision system[J]. Journal of University of Electronic Science and Technology of China, 2007, 36(6): 1237-1240. [4]覃丽珍,姚炳学,李金海.基于信息量的完备覆盖约简算法[J]. 计算机科学, 2012, 39(10): 235-239. QIN Lizhen, YAO Bingxue, LI Jinhai. Complete algorithm for covering reduction based on information quantity[J]. Computer science, 2012, 39(10): 235-239. [5]KRYSZKIEWICZ M. Rough set approach to incomplete information systems [J]. Information Sciences, 1998, 112: 39-49. [6]STEFANOWSKI J, TSOUKIAS A. On the extension of rough sets under incomplete information[C]//Proceedings of New Directions in Rough Sets, Data Mining and Granular-Soft Computing. Berlin: Springer, 1999: 73-81. [7]王国胤. Rough集理论在不完备信息系统中的扩充[J]. 计算机研究与发展, 2002, 39 (10): 1238-1243. WANG Guoyin. Extension of rough set under incomplete information systems[J]. Journal of Computer Research and Development, 2002, 39 (10): 1238-1243. [8]LIANG J Y, QU K S. Information measures of roughness of knowledge and rough sets in incomplete information systems[J]. Journal of System Science and System Engineering, 2001, 24(5): 544-547. [9]GRZYMALA-BUSSE J W. Characteristic relations for incomplete data: a generalization of indiscernibility relation[C]//Proceedings of Rough Sets and Current Trends in Computing. Berlin: Springer, 2004: 244-253. [10]杨习贝, 杨静宇, 吴陈, 等. 不完备信息系统中的集对分析方法[J]. 计算机科学, 2007, 34(4): 171-174. YANG Xibei, YANG Jingyu, WU Chen, et al. Set pair analysis in incomplete information systems[J]. Information Science, 2007, 34(4): 171-174. [11]GRECO S, MATARAZZO B, SLOWINGSKI R. Rough sets theory for multicriteria decision analysis[J]. European Journal of Operational Research, 2001, 129(1): 1-47. [12]SHAO M W, ZHANG W X. Dominance relation and rules in an incomplete ordered information system [J]. International Journal of Intelligent Systems, 2005, 20: 13-27. [13]胡明礼, 刘思峰. 基于广义扩展优势关系的粗糙决策分析方法[J]. 控制与决策, 2007, 22(12): 1347-1351. HU Mingli, LIU Sifeng. Rough analysis method of multi-attribute decision making based on generalized extended dominance relation[J]. Control and Decision, 2007, 22(12): 1347-1351. [14]YANG X B, YANG J Y, WU C, et al. Dominance-based rough set approach and knowledge reductions in incomplete ordered information system[J]. Information Sciences, 2008, 178: 1219-1234. [15]LUO G Z, YANG X B. Limited dominance-based rough set model and knowledge reductions in incomplete decision system[J]. Journal of Information Science and Engineering, 2010, 26: 2199-2211.


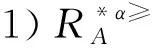
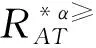

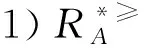


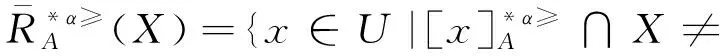


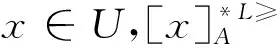
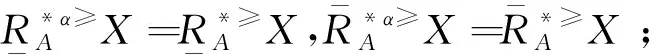
3 基于α优势关系粗糙集模型的属性约简
3.1 不完备序信息系统的属性约简
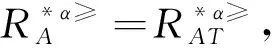


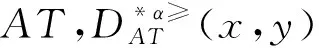

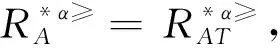

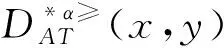
3.2 不完备序决策系统的属性约简




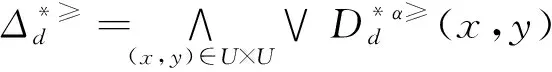
4 实例分析





5 结束语
