基于奇异值分解的自适应近邻传播聚类算法
2014-09-12王丽敏韩旭明
王丽敏,姬 强,韩旭明,黄 娜,3
(1.吉林财经大学管理科学与信息工程学院,长春 130117;2.长春工业大学软件学院,长春 130012;3.上海财经大学信息管理与工程学院,上海 200433)
基于奇异值分解的自适应近邻传播聚类算法
王丽敏1,姬 强1,韩旭明2,黄 娜1,3
(1.吉林财经大学管理科学与信息工程学院,长春 130117;2.长春工业大学软件学院,长春 130012;3.上海财经大学信息管理与工程学院,上海 200433)
针对近邻传播算法无法有效处理高维数据而导致聚类效果不佳的问题,提出一种基于奇异值分解的自适应近邻传播(SVD-SAP)聚类算法.通过引入奇异值分解,对高维数据进行重构、降维,消除冗余信息,并在此基础上采用非线性函数策略,自适应地调整阻尼系数,提高算法的聚类性能.仿真实验结果表明,与已有算法相比,该改进算法聚类精度更高,收敛速度更快.
近邻传播聚类算法;奇异值分解;非线性函数策略;阻尼系数
基于欧氏距离的相似性度量方法在处理低维数据时具有重要意义,但在高维空间中,由于高维数据存在稀疏性和空空间现象,导致欧式距离无法准确地度量数据点间的距离,且算法采用静态固定阻尼系数,无法自适应调节算法不同阶段的搜索性能.为了有效克服上述缺点,本文提出一种基于奇异值分解的自适应近邻传播聚类算法.一方面对高维数据进行重构、降维,降低信息冗余性;另一方面,在算法的迭代过程中采用非线性函数策略,自适应地调整阻尼系数,均衡算法的全局探索和局部搜索能力.仿真实验结果表明,本文提出的改进算法能有效降低高维数据中冗余信息的影响,提高聚类精度,加快收敛速度,提升聚类性能.
1 近邻传播聚类算法
近邻传播聚类算法不同于其他聚类算法,它是将所有样本点都作为潜在的聚类中心,通过循环迭代,每个样本点竞争聚类中心[1].其目的是得到最优的类代表簇,使类内样本相似度最大,类间样本相似度最小.
设样本数量为N的样本空间,任意两个样本点xi和xk间的相似度s(i,k)用负的欧氏距离度量,其值储存于N×N的相似度矩阵中,数学表达式为

矩阵对角线上的元素为偏向参数P,近邻传播聚类算法初始假设每个样本成为类代表点的可能性相同,即设定所有s(k,k)为相同值P,一般情况P值为相似度矩阵所有值的中位数.P值的大小影响聚类的个数,增大P值会增加类的数目,降低P值会减少类的数目,数学公式为

为找到合适的聚类中心xk,不断地从数据样本中搜集证据r(i,k)和a(i,k).r(i,k)表示样本点xi传递给样本点xk的信息,表示xi选择xk作为自己聚类中心的支持程度(吸引度);a(i,k)表示样本点xk发送给样本点xi的信息量,表示xi选择xk作为其聚类中心的适合程度(归属度);样本间通过归属度和吸引度两种消息不断传递更新,寻找到最优的聚类中心,其过程为

为避免近邻传播算法发生振荡,在信息更新过程中引入阻尼因子λ∈[0,1),分别对当前r(i,k)和a(i,k)的值与上一步迭代结果加权求和得到更新的r(i,k)和a(i,k),本文选取λ=0.5,更新公式为
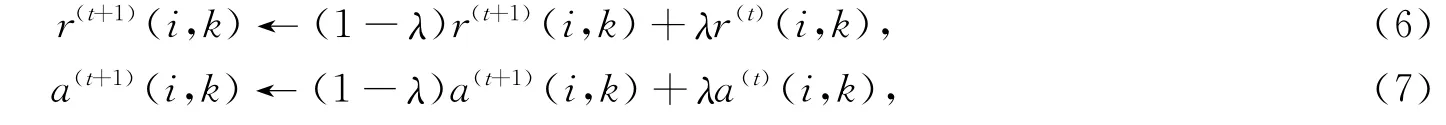
其中t表示当前迭代次数.当类代表点连续几步迭代过程中不发生变化或达到最大迭代次数时,近邻传播算法结束.
2 算法描述
2.1 奇异值分解
奇异值分解是一种重要的矩阵分解,在信号处理[14]、图像去噪[15]、统计学[16]和数据处理[17]等领域应用广泛.奇异值矩阵适用于任意一个矩阵.对于任意一个矩阵A,设ATA的特征值为λ1≥λ2≥…≥λr≥λr+1=…=λn=0,则称σi=( i=1,2,…,r)为矩阵A的奇异值,r为A的秩.存在m阶行正交矩阵U和m阶列正交矩阵V,使得其中该分解过程即为矩阵A的奇异值分解.
2.2 基于奇异值分解的降维过程
首先,对于一个原始数据Am×n,其中m为样本数,n为维数(属性),在MATLAB中运用函数(U,S,V)=svd(A)返回一个与A大小相同的对角矩阵S,两个正交矩阵U和V,且满足A=USVT.其中:U为m×m阵;V为n×n阵.奇异值在S的对角线上,非负且按降序排列.
其次,根据求得的S矩阵,选取合适的k个分量,即从矩阵U中选取k个特征向量,记为Ur,矩阵大小为m×k,对于一个n维的向量A,即可降到k维.再利用奇异值分解的逆过程得到原矩阵A的近似矩阵,将矩阵和原矩阵A对应的元素加和求平均,即可得到降噪后的数据矩阵A′.
对于选取分量个数k,本文根据错失率(error ratio)判定,即错失率不大于10%即可接受,表示为
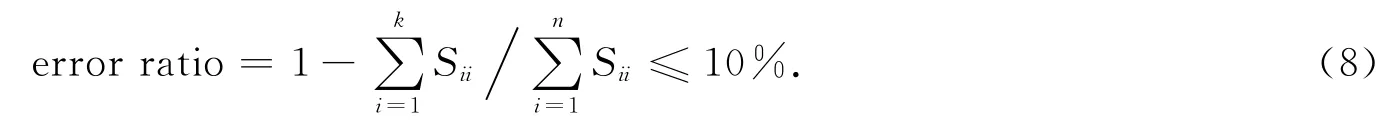
本文设定一个降维自由度矩阵Pn×k,该矩阵是列正交矩阵,则A′m×k=m×nPn×k即为基于奇异值分解的矩阵降维表示.
2.3 自适应动态阻尼策略
阻尼系数是近邻传播聚类算法的输入参数,选择不同的阻尼系数会对算法的全局搜索和局部搜索能力产生不同的影响,进而影响算法的收敛性能.传统的近邻传播聚类算法在迭代过程中,阻尼系数始终是静态固定值,无法动态地调节算法在不同阶段的搜索性能.针对上述问题,本文引入非线性函数策略,提出自适应动态阻尼策略,使该算法在迭代过程中阻尼系数不再是静态固定值,而是自适应的动态改变值,从而更好地提升算法在不同阶段的搜索能力.
自适应动态阻尼策略中阻尼系数动态改变初始值为λs,最终值为λe,最大迭代次数为tmax,当前迭代次数为t,函数策略改变点的迭代次数为tc,则自适应动态阻尼策略为
本文设定初始值λs=0.4,最终值λe=0.9,tc=100,当0≤t≤tc时,λ∈[0.4,0.9],策略函数为凹函数,因此λ以缓慢的速度增长,可保证算法初期以全局搜索为主,加快收敛速度;当tc<t≤tmax时,λ∈(0.9,1),确保算法后期主要进行局部搜索,避免发生震荡.
2.4 SVD-SAP算法流程
算法1 SVD-SAP算法.
输入:数据集Tm×n={x1,x2,…,xm},相似度矩阵S(i,j),迭代次数tmax;
输出:各聚类中心点,Silhouette有效性指标,迭代次数,消耗时间.
1)初始化r(i,k)=0,a(i,k)=0;
2)对数据矩阵进行奇异值分解,用函数(U,S,V)=svd(A)返回一个与A大小相同的对角矩阵S;
4)根据错失率条件选取分量个数k,则A′m×k=m×nPn×k即为基于奇异值分解的矩阵降维表示;
5)利用AP原理,AP中的r(i,k)和a(i,k)按如下规则更新:
令t=0,λs=0.9,λe=0.5,使用式(9)更新阻尼系数;
for t=1to tmax
r(t+1)(i,k)←(1-λ)r(t+1)(i,k)+λr(t)(i,k)//动态阻尼系数更新R
a(t+1)(i,k)←(1-λ)a(t+1)(i,k)+λa(t)(i,k)//动态阻尼系数更新A
t=t+1;
结束.
3 仿真实验与分析
实验环境:处理器为Inter(R)Pentium 2.9GHz,4Gb内存,500Gb硬盘,操作系统为Windows XP专业版,编程语言为MATLAB 2012b.
3.1 实验数据
为了验证SVD-SAP算法的可行性和有效性,本文选取UCI数据集中wine,glass,ecoli和pima数据进行仿真实验,并引入对聚类结构有良好评价能力的Silhouette有效性指标作为聚类质量评价标准对聚类效果进行判断,数据信息列于表1.

表1 UCI数据集Table 1 Data sets of UCI
3.2 实验结果与分析
仿真实验对AP,K-means和SVD-SAP算法分别在4个数据集上进行测试,因为已知各数据集的分类情况,所以根据此先验知识调节并确定偏向参数P,使两种算法都达到标准的聚类数,再比较三者的聚类精度和迭代次数,实验结果分别列于表2和表3.
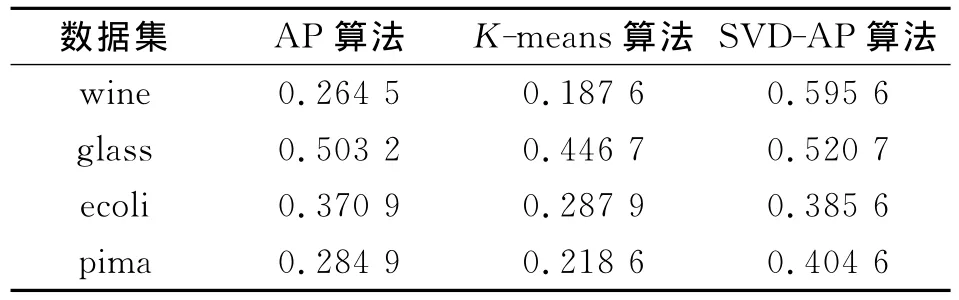
表2 聚类精度对比Table 2 Comparison of clustering accuracy
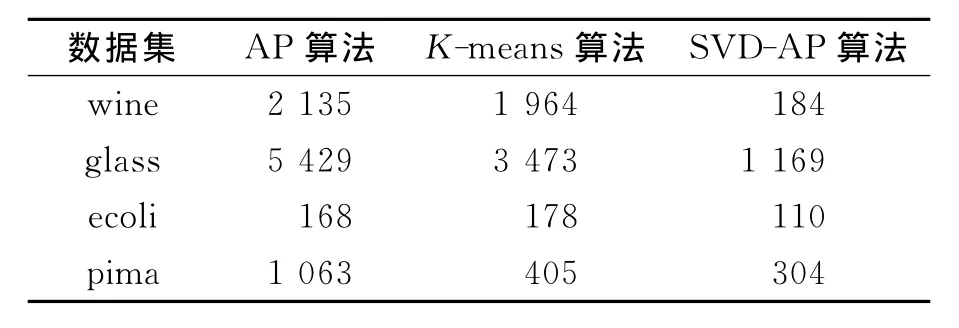
表3 迭代次数对比Table 3 Comparison of the number of iterations
由表2和表3可见,3种算法在聚类类数都达到标准聚类的情况下(控制变量的作用),SVD-SAP算法的聚类精度在数据集wine和pima上有明显提高,在迭代次数上优势更突出,表明改进的算法不仅能显著降低高维数据的信息冗余性,提高聚类精度,且在迭代过程中能自适应地应用动态阻尼策略,合理地调节算法的全局搜索和局部搜索,在不发生震荡的前提下,加快收敛速度.如在wine数据集上,SVD-SAP算法的迭代次数仅为传统近邻传播聚类算法的1/10以下,也远低于K-means算法.虽然在glass数据集上三者的聚类精度相差较小,但在迭代次数上差距较大,表明基于奇异值分解的自适应动态阻尼策略能对高维数据去噪、降维,不仅降低冗余信息的影响、提高聚类质量,且在一定程度上改善了聚类的结构和算法搜索方式,提升了算法效率.
综上所述,本文针对近邻传播聚类算法在处理高维数据时出现的聚类精度不高、搜索性能低下问题,基于奇异值分解的思想,提出了一种基于奇异值分解的自适应近邻传播聚类算法.该算法显著提升了处理高维数据的能力,有效降低了冗余信息对聚类过程的影响,提高了聚类质量.同时,通过自适应动态地调节阻尼系数,合理改善了算法不同阶段的搜索性能,最终实现了在全局搜索和局部搜索上的近似最优.仿真实验结果表明,所提出的改进算法具有聚类精度高、收敛速度快等优势.
[1] Frey B J,Dueck D.Clustering by Passing Messages between Data Points[J].Science,2007,315:972-976.
[2] 唐东明,朱清新,杨凡,等.一种有效的蛋白质序列聚类分析方法[J].软件学报,2011,22(8):1827-1837.(TANG Dongming,ZHU Qingxin,YANG Fan,et al.Efficient Cluster Analysis Method for Protein Sequences[J].Journal of Software,2011,22(8):1827-1837.)
[3] 王骏,王士同,邓赵红.特征加权距离与软子空间学习相结合的文本聚类新方法 [J].计算机学报,2012,35(8):1655-1665.(WANG Jun,WANG Shitong,DENG Zhaohong.A Novel Text Clustering Algorithm Based on Feature Weighting Distance and Soft Subspace Learning[J].Chinese Journal of Computers,2012,35(8):1655-1665.)
[4] Yang C,Bruzzone L,Guan R C,et al.Incremental and Decremental Affinity Propagation for Semi-supervised Clustering in Multispectral Images[J].IEEE Transactions on Geoscience and Remote Sensing,2013,51(3):1666-1679.
[5] Xu B,Hu R,Guo P.Combining Affinity Propagation with Supervised Dictionary Learning for Image Classification[J].Neural Computing and Applications,2013,22(7/8):1301-1308.
[6] 唐东明,朱清新,杨凡,等.基于仿射传播聚类的大规模选址布局问题求解[J].计算机应用研究,2010,27(3):841-844.(TANG Dongming,ZHU Qingxin,YANG Fan,et al.Solving Large Scale Location Problem Using Affinity Propagation Clustering[J].Application Research of Computers,2010,27(3):841-844.)
[7] Saracli S.Performance of Rand’s Cstatistics in Clustering Analysis:An Application to Clustering the Regions of Turkey[J].Journal of Inequalities and Applications,2013(1):1-9.
[8] 李丽娟,宋坤,赵英凯.基于仿射传播聚类的ARA发酵过程建模[J].化工学报,2011,62(8):2116-2121.(LI Lijuan,SONG Kun,ZHAO Yingkai.Modeling of ARA Fermentation Based on Affinity Propagation Clustering[J].CIESC Journal,2011,62(8):2116-2121.)
[9] 王伟涛,王宝善.基于聚类分析的多尺度相似地震快速识别方法及其在汶川地震东北端余震序列分析中的应用[J].地球物理学报,2012,55(6):1952-1962.(WANG Weitao,WANG Baoshan.Quick Identification of Multilevel Similar Earthquakes Using Hierarchical Clustering Method and Its Application to Wenchuan Northeast Aftershock Sequence[J].Chinese J Geophysics,2012,55(6):1952-1962.)
[10] Fujiwara Y,Irie G,Kitahara T.Fast Algorithm for Affinity Propagation[C]//Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence.Menlo Park,California:AAAI Press,2011:2238-2243.
[11] Givoni I,Chung C,Frey B J.Hierarchical Affinity Propagation[J/OL].2012.http://arxiv.org/ftp/arxiv/papers/1202/1202.3722.pdf.
[12] 冯晓磊,于洪涛.基于流形距离的半监督近邻传播聚类算法[J].计算机应用研究,2011,28(10):3656-3658.(FENG Xiaolei,YU Hongtao.Semi-supervised Affinity Propagation Clustering Based on Manifold Distance[J].Application Research of Computers,2011,28(10):3656-3658.)
[13] 王羡慧,覃征,张选平,等.采用仿射传播的聚类集成算法 [J].西安交通大学学报,2011,45(8):1-6.(WANG Xianhui,QIN Zheng,ZHANG Xuanping,et al.Cluster Ensemble Algorithm Using Affinity Propagation[J].Journal of Xi’an Jiaotong University,2011,45(8):1-6.)
[14] Capozzoli A,Curcio C,Liseno A,et al.Multi-frequency Planar Near-Field Scanning by Means of Singular-Value Decomposition(SVD)Optimization[J].IEEE Antennas &Amp,2011,53(6):212-221.
[15] Ajit R,Anand R,Arunava B,et al.Image Denoising Using the Higher Order Singular Value Decomposition[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(4):849-862.
[16] Vannieuwenhoven N,Vandebril R,Meerbergen K,et al.A New Truncation Strategy for the Higher-Order Singular Value Decomposition[J].SIAM Journal on Scientific Computing,2012,34(2):A10271052.
[17] Makbol N M,Khoo B E.Robust Blind Image Watermarking Scheme Based on Redundant Discrete Wavelet Transform and Singular Value Decomposition[J].AEU:International Journal of Electronics and Communications,2013,67(2):102-112.
(责任编辑:韩 啸)
WANG Limin1,JI Qiang1,HAN Xuming2,HUANG Na1,3
(1.School of Management Science and Information Engineering,Jilin University of Finance and Economics,Changchun130117,China;2.School of Software,Changchun University of Technology,Changchun130012,China;3.School of Information Management and Engineering,Shanghai University of Finance and Economics,Shanghai 200433,China)
Aiming at the problem that affinity propagation algorithm has a difficult to deal with highdimensional data,the authors put forward an selfdaptive affinity propagation algorithm based on singular value decomposition.With the aid of singular value decomposition introdued,the highdimensional data were reconstructed and dimensions were reduced to eliminate the redundant information,based on which,a nonlinear function strategy was adopted to adjust the damping factor adaptively and improve the clustering performance of the algorithm.Experimental results show that the proposed algorithm has obviously better clustering performance than the traditional algorithm on clustering accuracy and the number of iterations.
affinity propagation clustering algorithm;singular value decomposition;nonlinear function strategy;dampingfactor
TP301
A
1671-5489(2014)04-0753-05
近邻传播(affinity propagation,AP)是一种基于欧式距离为相似度的快速、有效聚类算法.近邻传播聚类算法的优点是不需要事先确定聚类个数,而将所有样本点作为潜在的类代表点,并通过不断迭代得到最优的聚类中心[1],因此,被广泛应用于基因序列[2]、文本聚类[3]、图像处理[4-5]和设施选址[6]等领域[7-9].目前,关于该算法及相应的改进算法已有许多研究结果,如Fujiwara等[10]通过在算法迭代过程中删减不必要的信息交换,在不损失聚类结果准确率的基础上,大幅度提升算法的收敛速度,提出一种快速高效的近邻传播聚类算法;Givoni等[11]将近邻传播算法与层次聚类相结合,提出一种分层近邻传播聚类算法,并应用于真实的HIV基因序列数据,取得较好效果;冯晓磊等[12]通过引入流形学习的思想,提出一种基于流形距离的半监督近邻传播聚类算法,更准确地反映数据的潜在结构,提高算法的聚类性能;王羡慧等[13]将近邻传播聚类算法与K均值算法相结合,提出一种基于近邻传播的聚类集成算法,有效地提高了K均值聚类的准确性、鲁棒性和稳定性.
10.13413/j.cnki.jdxblxb.2014.04.23
2014-05-13.
王丽敏(1975—),女,汉族,博士,教授,从事机器学习、数据挖掘和金融工程的研究,E-mail:wlm_new@163.com.通信作者:韩旭明(1971—),男,汉族,博士,副教授,从事机器学习和数据挖掘的研究,E-mail:hanxvming@163.com.
国家自然科学基金(批准号:61202306)、吉林省科技厅项目(批准号:20100507;201215119;20130522177JH)、吉林省教育厅重点规划项目(批准号:2012185)、吉林省高校新世纪优秀人才支持计划项目(批准号:2014159)和吉林财经大学青年学俊支持计划项目.
