中英平行短语依存树库构建
2014-09-07曹井香,黄德根,王伟,王帅军
曹 井 香, 黄 德 根, 王 伟, 王 帅 军
( 1.大连理工大学 计算机科学与技术学院, 辽宁 大连 116024;2.大连理工大学 外国语学院, 辽宁 大连 116024 )
电子与信息工程、管理工程
中英平行短语依存树库构建
曹 井 香*1,2, 黄 德 根1, 王 伟1, 王 帅 军2
( 1.大连理工大学 计算机科学与技术学院, 辽宁 大连 116024;2.大连理工大学 外国语学院, 辽宁 大连 116024 )
提出了面向翻译研究的融合短语结构树和依存分析的短语依存树库(phrase dependency treebank, PDT)的构建思想,阐述了中英平行PDT的构建方法.PDT 采用“扁平结构优先”的短语结构树和“基于语义”的依存句法功能标注原则,有别于传统依存分析的完全二分法.大连理工大学中英平行PDT(DUT-CEPDT)的生语料取自文本质量较高的政府工作报告和白皮书及其官方译文.首先,对文本进行分词和词性标注之后,利用专为语言学家开发的辅助工具LingTreeConstructor构建中文和英文的单语PDT;之后,在两个单语PDT之间从篇章到词的节点进行对齐,这种多层次的立体对齐比只有词、短语或句子的单层对齐能提供更丰富的翻译知识;最后,依据FrameNet进行双语平行的框架语义角色标注.DUT-CEPDT将为译员培训和机器翻译研究提供所需的标准语料.
短语依存树库;机器翻译;节点对齐;句法功能;语义角色
0 引 言
当前机器翻译取得的进展大都是基于统计的方法,或者是统计和规则相结合的方法.机器翻译研究所依赖的标注语料资源多是单句库,句子一般都不能太复杂.随着句子长度和复杂度的提高,人译的难度加大,机译则更困难.
目前中英平行语料库有Babel语料库,它有句对齐和词性标注,语料取自英文报刊文章及其中译版,主要用于中英语言对比研究[1];专利语料库,由中国专利的中英文摘要或专利中英文可比较语料挖掘的句对构建,句子结构复杂,但是都没有深加工[2].目前深加工的中文单语树库有美国宾州中文树库[3]、台北“中研院”Sinica中文树库[4]、清华大学中文树库[5]和哈尔滨工业大学中文依存树库[6]等.英文单语树库有很多,应用最广泛的是美国宾州英文树库[7].深加工的双语平行树库有布拉格捷克语-英语平行依存树库(Prague Czech-English dependency treebank, PCEDT),可把宾州英文树库的华尔街日报子库翻译成捷克语句子,同时实现了双语依存树的节点对齐[8].
随着我国改革开放和对外交往的不断发展,双语语料文本越来越多,如产品说明书、文件和论文的摘要、旅游景点介绍等,但这些译文大多是一个门面的装饰,译文质量参差不齐,不能作为翻译学习的样本.PCEDT专门把宾州英文树库翻译成捷克语而没有采用现有译文语料,考虑的原因之一就是能够收集到的翻译文本翻译太自由,意译和编译普遍,很难实现深度的平行.而政府文件的官方翻译是要向外界传达国家重要信息的,翻译质量很高.这些文本是译员学习的样本,也应该作为机译学习的样本,以提高机译的质量.因此,本文尝试利用人译的思路深度加工这些双语文本,并实现最大程度的对齐,为机器翻译研究构建一个高质量的学习和评测语料库.
本文提出短语依存树库(phrase dependency treebank, PDT)的构建思想,阐述大连理工大学中英平行短语依存树库(DUT-CEPDT)的构建过程,介绍比传统句对齐或词对齐更彻底的从篇章到词的节点翻译对齐.
1 辅助工具和资源
1.1 LingTreeConstructor的改造
LingTreeConstructor是由丹麦计算语言学家Sandborg-Petersen开发的语言学句法树构建软件[9],该软件专门为语言专业人员设计,其竖排图示与其他句法树可视化软件的横排图示不同,方便大段文本可视化加工(图1).
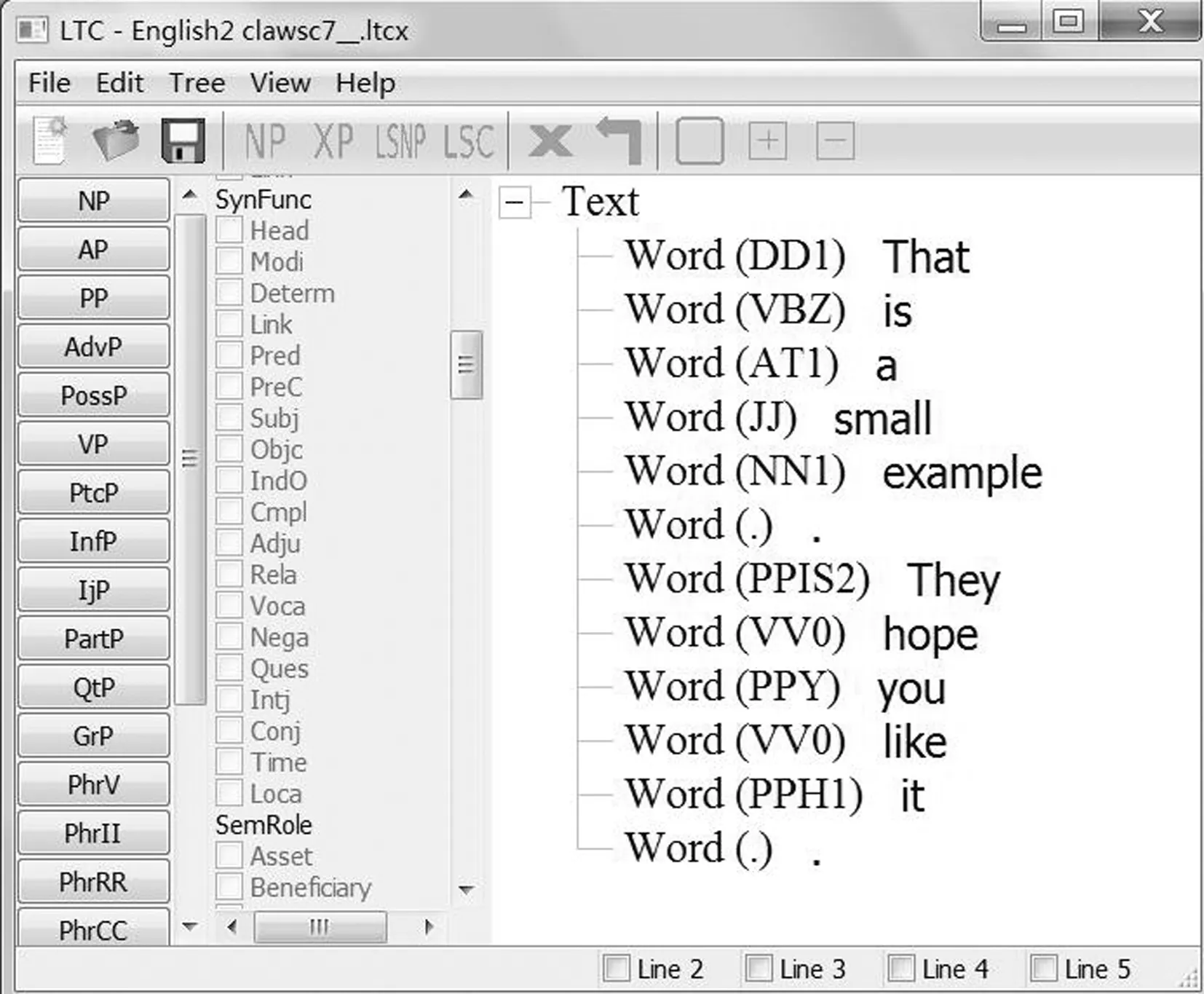
图1 句法树构建工具LingTreeConstructor
对这个软件的改造主要是增加以下功能:分离语料中的词性标注;实现平行翻译对齐节点连结;增加传统括号格式句法树输出,方便后期机器学习.
1.2 FrameNet的引入
FrameNet是美国加州大学伯克利分校创建的,用于标注中心语的语义类别及附属语与中心语的语义关系,也就是语义角色标注(semantic role labeling)[10].目前FrameNet已建框架还很有限.语义标注是一项巨大的工程,为了确保标注的质量,按词的语义类别分组进行,即不是一次性完成文本中所有词的语义标注,而是一次性完成某组同一义类的词的标注,然后逐步完成所有词的标注.表1是FrameNet总结的“保护”类词(bulwark n, cover n, guard v, insulate v, safeguard n, protect v, protection_(entity) n, protection_(event) n, safeguard v, secure v, shelter n, shelter v, shield n, shield v)的框架.
引入语义角色标注是要在句法功能标注依存关系以外添加语义关系.不同语种之间表达同一意思的句法结构和功能会有所不同,但语义关系应该是基本相通的,这也是翻译的基本假设,即相信两种语言可以表达相同的意思.
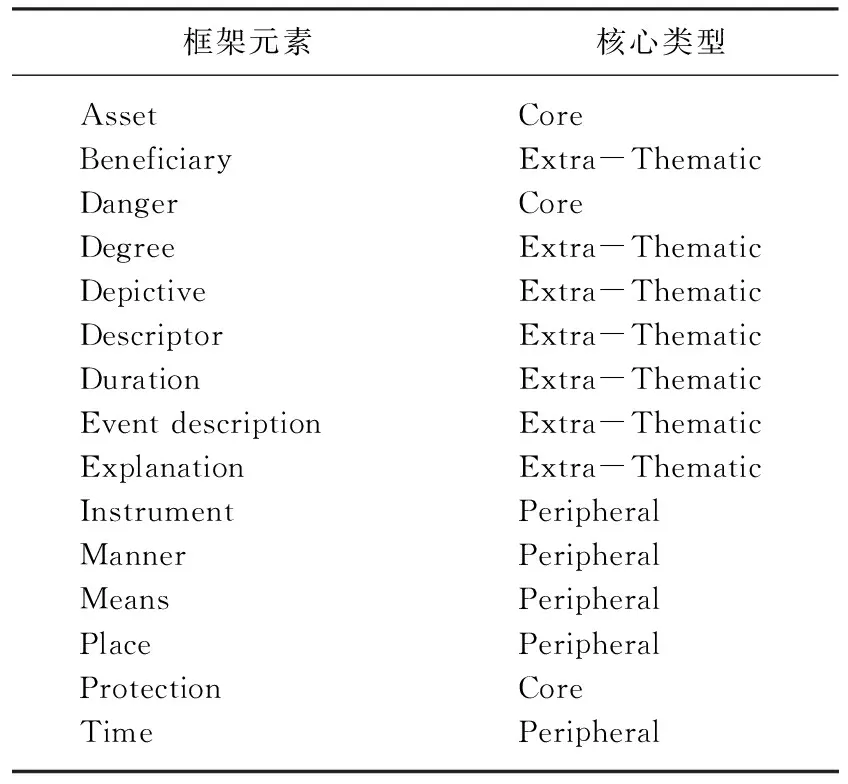
表1 保护语义的框架
2 DUT-CEPDT的构建思想和过程
2.1 政府文件文本及其预处理
原始文本从中华人民共和国中央人民政府官方网站(http://www.gov.cn)下载,目前只用了政府工作报告(Report on the Work of the Government, 2000~2012,每年一份)和白皮书(White Papers, 2000~2012,每年数目不等),英文788 670 词,28 569句;中文1 189 161字,33 318 句.中英文皆为官方发布,语言正式,句式复杂,内容广泛.比较政府文件翻译和其他文本翻译,可以观察到政府文件翻译高度忠实于原文,除了增加一些注释外,几乎没有改动.
中文文本分词和词性标注使用的是大连理工大学开发的NiHao语料标注系统[11],分词标准是北京大学的《规范2003》.分词结果如下例:
现在/NOUN-ADV, /WD 我/PERSON-PRON 代表/NVERB 国务院/ORG, /WD 向/PREP 大会/COM-NOUN 作/COM-VERB 政府/COM-NOUN 工作/NVERB-N 报告/NVERB-N, /WD 请/COM-VERB 各位/PERSON-PRON 代表/NVERB 审议/NVERB, /WD 并/CNJ 请/COM-VERB 全国/COM-NOUN 政协/ORG 委员/COM-NOUN 提出/NVERB 意见/COM-NOUN./WJ
对英文文本进行词性标注,使用的是英国兰卡斯特大学UCREL中心[12]开发的CLAWS7标注器,标注结果如下例:
On_II31 behalf_II32 of_II33 the_AT State_NN1 Council_NN1, _, I_PPIS1 now_RT present_VV0 to_II you_PPY my_APPGE report_NN1 on_II the_AT work_NN1 of_IO the_AT government_NN1 for_IF your_APPGE deliberation_NN1 and_CC approval_NN1 ._. I_PPIS1 also_RR invite_VV0 the_AT members_NN2 of_IO the_AT National_JJ Committee_NN1 of_IO the_AT Chinese_JJ People_NN ′s_GE Political_JJ Consultative_JJ Conference_NN1 (_( CPPCC_NP1 )_) to_TO submit_VVI comments_NN2 and_CC suggestions_NN2 ._.
之所以选择这两个标注器,是因为它们的词性分类都很细,包含了较丰富的语义和语法信息,有利于后期的机器学习.
另外,对比上例中的中英两个版本,中文只有1个句末标点,而英文有2个;中文用简称“全国政协委员”,而英文用全称the members of the National Committee of the Chinese People′s Political Consultative Conference (CPPCC).这两个现象在中英翻译中非常普遍,因此要做的是与常见的单句对齐或词对齐不同的节点对齐.
2.2 DUT-CEPDT的句法标注特点
当前的句法分析主要有两种形式:一种是传统的短语结构分析;另一种是依存关系分析.短语结构分析不直接包含依存关系,现有把短语结构树库转换为依存树库的研究都需要配合30条左右的转换规则,这些转换规则是短语结构树库以外的知识.但是依存树库可以直接根据继承推导来实现短语结构,不过也只能得到无标注的层次划分而已,不能得到结构类型标注.结构类型也需要外部的知识规则来判定,目前这类研究很少见.DUT-CEPDT的句法分析形式融合了这两种句法分析的结果,既保留了传统的短语结构树,又标注了依存方向和依存关系.短语结构的保留是为了节点对齐的块翻译研究;依存方向和关系可用于翻译的调序问题研究.
2.2.1 短语依存树的节点类型 当前自然语言处理领域的结构树都是以句子为最大单位.平行语料库多以翻译句对为计量单位.然而语言的理解和翻译经常需要句子之外的上下文语境,保留原文篇章的完整更符合人译的习惯.为了探讨拟合人译的机器翻译方法研究,篇章的根节点为text,定义的节点结构类型自底向上依次有:
(1)词word,中文分词和词性标注,英文词性标注之后,以空格为界的最小单位.本文不对词进行判定,而是直接采纳标注工具的标注结果.词是树库的终节点.
(2)短语词phrasal word,书写有空格为界的几个词,但从语义和用法看是一个整体,都是结构相对稳固的习语或成语.CLAWS7在词性标注阶段就有标注,如前文例子中的On_II31 behalf_II32 of_II33、中文“在中国共产党的领导下”中的“在……下”,又如中文的“特别是”“环比”等.中文的原始文本无分词标识的,不同分词方法和工具对同一文本的标注可能不同.短语词的构建是对分词结果的一个修正,就是把不该切分的单位复合成一个单位.短语词的可操作性判别有3个标准:①朗读和口语中的语感,是不可停顿的整体,异常停顿后会感觉表达不流畅;②内部结构关系不好确定,需要查阅词源信息;③译文是一个词.特征①和②是最重要的,③只做参考.短语词按整体的功能以词性分类,如短语名词、短语动词、短语连词等(如图1左下角的PhrV、PhrII、PhrRR、PhrCC).
(3)短语phrase,由两个及以上词组成且不能构成小句的非短语词结构.短语是介于小句和词之间的单位,几个词是否能够组合成短语,主要看这个结构在语义上是否相对完整,同时可以整体被替换或移动.短语基本按传统语法功能分类(如图1中的NP、AP等).谓语动词,包括助动词和主动词,设为PredVP,其宾语、状语和补语分开另设,这个是以动词为中心语的依存设计.
(4)小句clause,以主谓结构定义.英文小句是以谓语动词为中心语的结构;中文小句的主语不是必要成分,主要参照的是谓语,主语承前省略的并列谓语结构也为小句.主语省略的小句与非谓语动词短语的区别在于非谓语动词有上一层小句作为父节点,而省略主语的小句通常是并列谓语.
(5)句子sentence,以原文的书写为准.中文以句末标点(。?!……)定义,英文以句首字母大写和句末标点(.?!…)定义.小句加句末标点是句子,短语加句末标点也是句子.
(6)句群group sentence,在翻译对齐中,中英文句子会有一对多、多对一的时候,句群是对应同一句子的多个句子.这个节点标注在双语节点对齐的工序中补加.
(7)段落paragraph,以原文的排版为准,如首行缩进、换行.标题、独立呼语行(如“各位代表,”,“各位来宾,”)等都划为段落.
以上的节点类型定义中,段落和句子是完全按形式定义的,小句、短语和短语词是按语义和内部结构定义的,而句群是按翻译的对齐结果定义的.标点符号在分词处理中与词相同对待,因此在终节点上归入词一级.定义短语词是为了高效处理一些已经石化的习语,免去对其词源历史的追踪,这些短语词通常被译成一个词;定义句群是为了研究翻译过程中句子之外结构的调整,合译与分译是人译经常采用的处理技巧.
2.2.2 “扁平结构优先”的短语结构分析 本文的短语结构分析基本相当于传统的短语成分层次分析.符合英语习惯的是中心语先与前置附属语组合,然后再与后置附属语组合.符合汉语习惯的是中心语先与近的附属语组合,再与较远的附属语组合.图2所示的Stanford parser对以下句对的分析结果就体现了这种单语分析的特点.
“十一五”时期是我国发展进程中极不平凡的五年。The Eleventh Five-Year Plan period was a truly extraordinary time in the course of the country′s development.

(a) 中文

(b) 英文
图2 斯坦福句法分析结果
Fig.2 Stanford parser result
英文a truly extraordinary time 先组合,然后再与 in the course of the country′s development 组合;而中文 “我国发展过程中”先与 “极”“不”“平凡”组合,再与“的”组合之后才与“五年”组合.都是先就近组合再与较远的附属语组合.这样的结构分析除了末端节点的词对齐之外,就只有根节点、主语节点和谓语节点3个能对齐的了.但是如果尽量采取前后修饰语扁平处理的话,可对齐的节点就更多,对翻译研究有益,也更忠实于深层语义结构.
因此,为了服务于翻译研究,本文不采用把句子首先划分为主语和谓语的传统二分法,而是以主句谓词为中心语(head),传统语法的主语、宾语、状语和补语都是同级对待的,都是谓词中心语的附属语(dependent).而且每个结构的前置附属语和后置附属语也是同一层的,而不是前后依次嵌套的.这就是本文提出的“扁平结构优先”原则,能并列的就不分层,减少层次,这样有助于后期的节点对齐,有助于翻译调序处理[11],也有助于探索多语统一的分析标注体系.图3是依据“扁平结构优先”原则对图2的例子进行人工分析的结果,词性标注为本文2.1所述标注器的标注结果.

(a) 中文

(b) 英文
图3 “扁平结构优先”原则
Fig.3 Flat structure preference rule
这个处理方法有别于目前单语依存树库构建思想.在单语依存树库构建中,很多的课题是研究把扁平结构进行二分处理的.本文从探索多语统一标注体系和翻译研究的角度出发,最大限度保留扁平结构,以实现多语的一致性和翻译的灵活性.2.2.3 基于语义的依存方向标注 本文的依存句法关系标注是指分层标注中心语及其附属语的句法关系,也就是标注本层结构的中心语以及附属语组块与中心语的关系.依存处理是以格语法为依据的,即小句(clause)的中心语(head)是谓语动词,主语、宾语、状语、补语都是附属语.单语依存树库的构建通常是为了实现一致的二分法依存,很多虚词甚至是标点符号被认定为中心语,比如连词、介词甚至是冠词.
Chomsky学派就提出用DP(限定短语)替代NP(名词短语)的语法理论,提出了限定词(如a, the, this, his)是传统名词短语的中心语的说法,而没有限定词的泛指名词短语则引入空语类(null)来解释[13].包括汉语在内的很多语言都被探讨,试图说明DP是比NP更有解释力的普遍语法.介词(前置词)短语结构(prepositional phrase, PP)已经被广泛接受,普遍把介词当成PP的中心语,现有文献中的依存也都是把介词当成中心语的,在介宾结构中,宾语是附属语.还有并列结构和同位语结构,起初是规定连词或标点符号为中心语,现在普遍规定首个或末尾组分为中心语.因此宾州依存树库在给出typed dependency 之外还有dependency collapsed[14-15].而Prague依存树库则在analytical level之外又另设一层tectogrammatical level[8].这些处理的核心都是简化或者删除虚词为中心语的依存关系表示,突出语义层面的关系.
针对以上情况,为了方便翻译研究,本文对中心语,即依存方向,作了一些不同于传统语法,也不同于大多数现有依存树的处理.
(1)短语词phrasal word,是补充的在短语一级定义的与词相同的结构.在结构和依存分析中,把短语词看成是一个词,不再分析.同时像a lot of, a number of 等短语量词与名词组合时,这些量词是附属语,而后面的名词是中心语.
(2)谓语动词短语PredVP,就是小句谓语动词,包含助动词.主动词是中心语,这也是与其他依存句法分析中把助动词定义为中心语不同的处理.
(3)属格短语PossP(possessive phrase),英文词性标注把 ′s分隔成词,名词或名词短语与′s组合后就是PossP.属格短语的中心语是前面的名词或名词短语.
(4)中文“的”字结构deP,中文分词把“的”分隔成词,“的”字前面的部分是中心语.
(5)中文方位短语LocP(locative phrase),就是名词+“里、中、内”等,前面没有“在”的情况.方位词前面的部分是中心语.
本文规定的中心语都是语义中心语,而非传统句法依存中心语.世界不同语种之间的差异重在语法虚词的使用,翻译的核心是语义转达.以中英语言为例,英文译成中文时冠词、介词和助动词通常被省略,而中文译成英文时需要添加.这些虚词通常都没有内含嵌套的结构,本文把这些虚词附属语与中心语的依存关系定义为句法限定语(determiner)和连接语(link).
基于语义的依存方向标注简化了现有依存标注因部分结构句法依存和语义依存方向相反而使得全库需要用两套标注的烦琐,而且这样的理解也是传统语言学的主张.
2.2.4 并列及同位结构的多中心分析 并列结构和同位语结构是依存关系构建中需要特殊处理的结构.为了满足二分法的要求,目前的处理方法可以归纳为“就近原则”,即靠近父节点中心的部分为中心,Stanford parser就是这样处理的.
图4中的每对依存关系中前面的是中心语,后面的是附属语,图4(a)是Stanford的分析结
国防和军队现代化建设取得重大成就。Great progress was made in the modernization of national defense and the army.

(a) 句法中心与并列单中心分析

(b) 语义中心与并列多中心分析
果.中文“国防和军队”的依存中心是“军队”,“国防”与“军队”的关系是conj,“和”与“军队”的关系是cc.英文“national defense and the army”的依存中心是defense,national、and和army都是defense 的附属语.把并列关系和修饰关系等同对待,在翻译对齐上就会造成混乱.允许多中心的分层次依存,就是“国防和军队”中“国防”和“军队”都是中心,“和”是附属于两个中心的.这个NP再附属于“现代化”,意思是“国防现代化和军队现代化”,再一起附属于“建设”.这种并列的结构和理解在翻译过程中是时常会遇到的.
图4(b)是根据DUT-CEPDT构建结果的等同表示,不含短语结构信息.与图4(a)的主要区别就在于并列结构的多中心和介词的非中心语处理,即介词、连词和冠词等语法功能词都在依存关系括号的后位.同时对中文的语义依存分析有一处不同,即图4(a)认为“现代化”和“国防与军队”同为“建设”的修饰语,而图4(b)认为“现代化”是“国防和军队”的中心语,“建设”只是“现代化”的中心语.
2.2.5 句法依存关系类别 本文的单语标注阶段还需要对同级关系进行依存关系类别标注.句法依存关系类别基本是以传统的句法功能定义的.小句(句子)的内部句法依存关系类别有:主语(subject)、谓语(predicate)、直接宾语(object)、间接宾语(indirect object)、谓语状语(adjunct)、小句状语(disjunct)、插入语(parenthesis/expletives)、呼语(vocative);短语的内部句法功能类别有:中心语(head)、内容附属语(modifier)、虚词限定语(determiner)和连结语(link).连结语包括并列连词、从属连词、标点符号和中文“的”.虚词限定语是指英文的冠词、形容词性物主代词等.句法依存关系是在单语处理阶段标注的.
2.3 翻译节点对齐
2.3.1 翻译节点对齐设计 目前平行语料对齐是段落、句子、短语或者词对齐.本文希望实现不同层级的最充分对齐,即节点对齐.也就是比照双语文本,节点所表示的结构整体互译,连结后该节点保存对译树库中的节点ID,既方便翻译知识学习,也方便后期的语义角色平行标注.本文认为除文学和广告文本翻译外,绝大部分翻译的本质是语义的翻译,语义是基本对应的,不同的是语言形式,其深层结构对应,表层结构不同.图5是对以下句子的节点对齐示意图.
我们在国际事务中发挥重要的建设性作用,有力维护国家主权、安全和发展利益,全方位外交取得重大进展。We played an important and constructive role in international affairs; effectively safeguarded our national sovereignty, security and development interests; and made major progress in our all-around diplomacy.
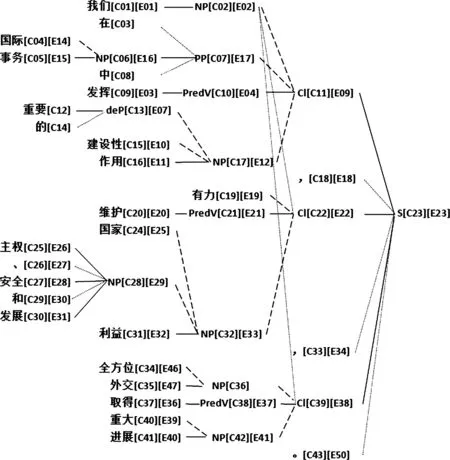
(a) 中文树
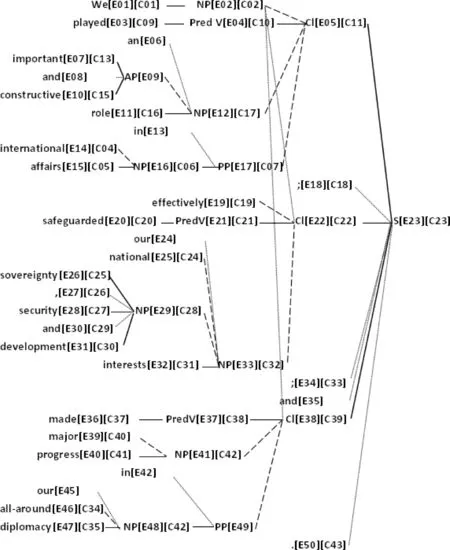
(b) 英文树
图5 节点翻译对齐
Fig.5 Translation node alignment
包括标点符号在内,中文树共27个终节点,英文树共30个终节点,中文多了“的”和“中”,英文多了an、our、in和2个and.对齐的节点共41对.在子节点与父节点的连线中,点虚线表示虚词附属语,短画线表示实词附属语,实线表示中心语.这些句法关系都是相对于同一父节点的同级关系.
对齐连结就是在两个树库中可以对译的节点之间建立关联.图5中每个节点只保留了一个主参数,叶子节点就是原词,词性标注省略,中间节点是短语类名,所有节点的句法功能标注和语义角色标注都省略.中括号内信息是该节点在单语库的ID和对译节点在对译单语库中的ID.如中文节点C17对译英文节点E12,即“重要的建设性作用”对译“an important and constructive role”.
传统短语结构分析法首先是主语谓语切分,但本文采用“扁平结构优先”原则.以E38和C39节点表示的小句为例, “全方位外交取得重大进展”和“and made major progress in our all-round diplomacy”的主语是不一样的,中文的主语“全方位外交”对译是“in our all-round diplomacy”,是状语.如果把它们放在同一层级,在节点翻译后调整位置就完成翻译了.
自然文本的语篇对齐,句子层面会有一对多、多对一情况.以较长文本为准,对译的多句添加一个句群节点与之对齐,可用于研究翻译中的断句与合句规则学习.
2.3.2 节点对齐操作 节点对齐人工操作辅助工具是作者自行开发的.
图6中的左上方实现词性提取和转换功能,右上方实现对齐操作.主框左右便是双语树库了.每个节点可收可放,已经对齐的显示为绿色(文中深色部分),未对齐的节点为白色.选中左右要对齐的节点,点击“建立关联”,两个节点的树库ID码便建立了关联,保存在关联文件里.
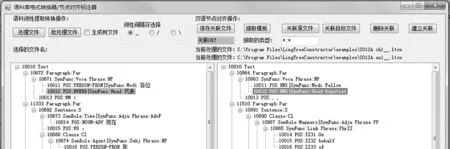
图6 节点对齐标注工具
关联文件表示以下对齐:
10010 Text,10010 Text,
10011 各位,10011 Fellow,
10012 代表,10012 Deputies 等
2.4 语义依存关系标注
对齐的节点连结之后,分层标注附属语与中心语的语义依存关系.由于翻译节点之间建立关联,在语义角色标注中能实现双语同时标注,源语与译语的语义关系是相同的.传统依存关系把句法关系和语义关系融合成一个标注符,也就是说依存关系标注的一个特征值里包含了句法和语义信息.本文的标注把句法功能和语义关系分开,句法功能在单语库标注,语义关系可在关联之后标注.因为翻译的前提就是假设两个文本意思相同,那么同一中心语的附属语的语义角色也相同,中文的时间不会变成英文的地点,但是中文的主语很可能译成英文的状语.标注语义关系为“的”的区别于同一级附属语的不同元素,为翻译规则学习增加一项可用的特征参数.
FrameNet团队为相同语义类别的词归纳框架,归纳了框架的主要元素和次要元素[10].框架元素就是该框架中心语的附属语.该团队已经标注了大量的框架,但是还有很多需要总结.框架的总结依据语料库的检索行(concordance).常用的语料库检索工具目前有AntConc、WordSmith Tools和ParaConc等.虽然ParaConc是针对平行语料的,但输入语料要求已经句对齐.本文保留了篇章的原貌,没有先进行句对齐,而是采用语料库语言学领域使用最多的WordSmith Tools 5.0[16].图7是protect的检索行界面截图.
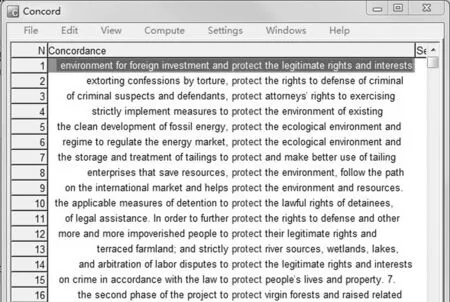
图7 WordSmith Tools 5.0 检索
图8是表1所示protect框架的标注实例.根据目标词在检索行所在语境的附属语类别,归纳出语义框架,特别是该框架的框架元素.语义依存关系标注,也就是语义角色标注,是非常复杂而艰巨的任务,需要分批次逐个完成.

图8 “protect”语义角色标注实例
3 DUT-CEPDT的主要特点
DUT-CEPDT的主要特点归纳如下:
(1)翻译节点多层对齐.这个是文献中还未见到的.它的优势在于对齐彻底,计划用于各个层次的翻译知识获取、词语翻译、短语翻译、小句翻译等.
(2)短语结构语法与依存语法相结合.常规依存树是单点之间的联系,只能通过继承来实现层次连接,因此所有结构都只有唯一中心,并列结构也要先单点连结;同位语结构甚至把标点符号作为中心.虽然在形式上一致了,但在语言理解上与人的直觉理解相悖,在翻译过程中也会出现困难.因此本文采用“扁平结构优先”的短语结构分析和基于语义的依存分析来解析句法结构和功能,允许多中心结构,只有实词可作为中心语,既符合人对语言的理解,也有利于翻译知识的提取.短语层次的依存有助于互译块和翻译规则的学习.
(3)生语料语言规范,译文质量很高.政府文件文本句法结构复杂,话题内容广泛.不是新闻题材,也不是专业题材,而是常见主题的正规表达.
中英平行短语依存树库是崭新的尝试,工程浩大.其困难之一在于这样的精细加工需要大量的语言专业人力投入,这也是一开始就把建库应用领域定位在语言和语言学教学、译员培训和翻译机器学习的考虑.在教学工作中积累所需语料,项目可以得到持续扩展和升级.困难之二是后期的自动化或半自动化分析.人工标注只是一个基础,工程应用需要实现自动化,需要实现规模.实现这样精细的加工自动化有很大的困难,但是可以依赖现有的一些工具的拼接和整合先实现半自动化,逐步训练匹配的分析器可以实现自动化.
4 结 语
2013年刚由Springer出版的自然语言处理理论与应用丛书之一的《计算机语言获取的认知问题》第十章专门讨论“树库分析和语言知识”[17],介绍了利用标注语料库来获取传统语言学意义上的“语言知识”的思路和方法,认为当前利用大规模语料统计学习来获取语言知识的方法的性能有限,语料的持续增加会积累“不自然”的语言结构,因此获取传统语言学知识对于提高机器学习和句法分析的性能很重要.实验表明未经加工或者是浅层加工的语料规模加大并不能持续提高机器学习的效果,目前更需要深加工的语料来提高机器学习的性能.DUT-CEPDT的单语库可用于语法教学和语言学研究,机器学习语法规则;双语库可用于语言对比研究,机器翻译规则学习.
由于标注信息量加大,无论是人工标注,还是机器标注总体上操作性都变难了.但是由于采用了更符合人们直觉的语义优先的标注体系,在单项任务上人工标注的一致性容易实现.目前的标注全部是人工进行的,但只有实现自动和半自动标注才能实现工程上的运用,因此,下一步工作重点就是以人工标注为基础进行自动化标注研究.
[1]Xiao R. Babel English-Chinese parallel corpus [DB/OL]. [2013-02-13]. http://www. lancs. ac. uk/fass/projects/corpus/babel/babel. htm.
[2]LU B, Tsou B K, JIANG Tao,etal. Mining large-scale parallel corpora from multilingual patents:an English-Chinese example and its application to SMT [C] // Proceedings of the1st CIPS-SIGHAN Joint Conference on Chinese Language Processing (CLP-2010). Beijing:CLP, 2010.
[3]XUE Nian-wen, XIA Fei, Chiou Fu-dong,etal. The Penn Chinese TreeBank:phrase structure annotation of a large corpus [J]. Natural Language Engineering, 2005,11(2):207-238.
[4]陈凤仪, 蔡碧芳, 陈克健, 等. 中文句结构树资料库的构建[J]. 中文计算语言学期刊, 1999,4(2):87-104.
Chen Feng-yi, Tsai Bi-fang, Chen Keh-Jiann,etal. The construction of the Sinica treebank [J]. Computational Linguistics and Chinese Language Processing, 1999,4(2):87-104. (in Chinese)
[5]周 强. 汉语句法树库标注体系[J]. 中文信息学报, 2004,18(4):1-8.
ZHOU Qiang. Annotation scheme for Chinese treebank [J]. Journal of Chinese Information Processing, 2004,18(4):1-8. (in Chinese)
[6]LIU Ting, MA Jin-shan, LI Sheng. Building a dependency treebank for improving Chinese parser [J]. Journal of Chinese Language and Computing, 2006,16(4):207-224.
[7]Marcus M, Santorini B, Marcinkiewicz M. Building a large annotated corpus of English:The Penn treebank [J]. Computational Linguistics, 1993,19(2):313-330.
[9]Sandborg-Petersen U. LingTreeConstructor [DB/OL]. [2013-01-10]. http://ltc.sourceforge.net/.
[10]Baker C F, Fillmore C J, Lowe J B. The Berkeley FrameNet project [C] // COLING-ACL ′98:Proceedings of the Conference. Montreal:COLING-ACL, 1998:86-90
[11]HUANG De-gen, TONG De-qin. Context information and fragments based cross-domain word segmentation [J]. China Communications, 2012,9(3):49-57.
[12]Garside R, Smith N. A hybrid grammatical tagger:CLAWS4 [C] // Corpus Annotation:Linguistic Information from Computer Text Corpora. London:Longman, 1997:102-121.
[13]肖欣延,刘 洋,刘 群,等. 面向层次短语翻译的词汇化调序方法研究[J]. 中文信息学报, 2012,26(1):37-41.
XIAO Xin-yan, LIU Yang, LIU Qun,etal. Lexical reordering for hierarchical phrase-based translation [J]. Journal of Chinese Information Processing, 2012,26(1):37-41. (in Chinese)
[14]Szabolcsi A. The possessor that ran away from home [J]. The Linguistic Review, 1983,3(1):89-102.[15]Marneffe M, Maccartney B, Manning C. Generating typed dependency parses from phrase structure parses [C] // Proceedings of the International Conference on Language Resources and Evaluation (LREC-06). Genoa:Diplomarbeit, 2006:449-454.
[16]Scott M. WordSmith Tools version 5 [DB/OL]. [2013-01-10]. http://www. lexically. net/wordsmith/version5/index. html.
[17]Fong S, Malioutov I, Yankama B,etal. Treebank parsing and knowledge of language [C] // Cognitive Aspects of Computational Language Acquisition, Theory and Application of Natural Language Processing. Heidelberg:Springer-Verlag, 2013:133-172.
ConstructionofparallelChinese-Englishphrasedependencytreebank
CAO Jing-xiang*1,2, HUANG De-gen1, WANG Wei1, WANG Shuai-jun2
( 1.School of Computer Science and Technology, Dalian University of Technology, Dalian 116024, China;2.School of Foreign Languages, Dalian University of Technology, Dalian 116024, China )
A phrase dependency treebank (PDT) integrating phrase structure grammar and dependency grammar is proposed and elaborated to cater for translation studies. The construction of DUT Parallel Chinese-English PDT (DUT-CEPDT) is reported. PDT favors flat structures and the dependency is based on semantics rather than syntactic functions, which differs from the mainstream dependency analysis that favors binary branching. The raw texts of DUT-CEPDT are Chinese government work reports and White Papers and their official English translation. First of all, after word segmentation and part of speech (POS) tagging, Chinese PDT and English PDT are constructed manually with the aid of LingTreeConstructor, a tool tailored for linguists. Then, node alignment, which covers translation alignments of words, phrases, clauses up to the whole passage, is proposed instead of traditional word or sentence alignment to provide more translation knowledge. Lastly, semantic roles based on the FrameNet are labeled simultaneously on the aligned nodes of the English and Chinese trees. DUT-CEPDT can serve as a resource and standard of the training and assessment of both human translators and machine translation systems.
phrase dependency treebank; machine translation; node alignment; syntactic function; semantic roles
2012-10-02;
: 2013-11-08.
国家自然科学基金资助项目(61173100).
曹井香*(1973- ),女,博士,副教授,硕士生导师,E-mail: caojx@dlut.edu.cn;黄德根(1965-),男,博士,教授,博士生导师,E-mail:huangdg@dlut.edu.cn.
TP391
:A
10.7511/dllgxb201401015
