本体领域综合概念相似度计算中的权重确定方法
2014-09-06成锦晖郑山红李万龙岳绍敏
成锦晖, 郑山红, 李万龙, 岳绍敏
(长春工业大学 计算机科学与工程学院, 长春 130012)
本体领域综合概念相似度计算中的权重确定方法
成锦晖, 郑山红, 李万龙, 岳绍敏
(长春工业大学 计算机科学与工程学院, 长春 130012)
利用粗糙集及条件信息熵的相关理论, 针对基于相似度计算的本体映射方法在相似度融合时权重过分依赖专家参与等问题, 给出一种自动确定权重的策略, 并通过实例验证了该方法的可行性.该方法充分考虑在信息量不确定情况下, 用各属性对系统信息熵的影响程度确定各属性在当前信息系统中所占的权重, 从而使本体的自动化映射和语义网的实时服务成为可能.
本体; 相似度; 概念相似度; 粗糙集; 信息熵; 权重
本体作为语义网的重要支撑, 近年得到快速发展.但由于知识领域的分布性和自治性及本体开发者的认知水平不同, 导致了本体异构性的产生, 因此本体映射与集成已成为当前本体研究领域的热点问题之一.本体映射过程分为3个步骤: 本体特征项的提取、概念相似度的计算和映射后处理.综合相似度计算是本体映射的关键, 由于目前在进行相似度合并时主要采用领域专家人工确定的方法设定各部分权重, 因此使映射效率受到较大影响且不适应实时网络服务.基于此, 本文提出一种基于粗糙集条件信息熵的综合相似度计算中权重的自动确定方法, 并以国际组织OAEI给出的测试数据benchmarks 2007为数据源进行了算法验证, 证明了该方法的有效性.
1 基本概念
1.1本体
本体是共享概念模型明确的形式化规范说明, 包含概念化、明确化、形式化和共享性4层含义.本文采用Gruber[1]提出的本体定义, 将本体表示为五元组:O=〈C,I,R,F,A〉, 其中:C表示概念集;I表示实例集合;R表示定义在概念集上的关系集;F表示函数集合;A表示公理集合.
1.2本体映射
本体映射是指两个本体存在语义上的概念关联, 通过语义关联, 将源本体的元素映射到目标本体的过程.Shvaiko等[2]给出了映射定义:f=〈id,e,e′,n,R〉, 其中:R表示实体e和e′的关系;n表示映射的置信度, 可通过相似度计算等方法获取.
2 综合概念相似度计算方法
目前, 研究人员普遍采用综合相似度计算方法[3], 即综合考虑待映射本体概念间的名称、属性、结构和实例的相似程度, 运用适当的权重予以集成.
2.1相似度计算方法
2.1.1 概念名称相似度计算 本文采用Wu-Palmer基于WordNet的相似度算法[4-5].WordNet是一部树状英语语义词典, 其根据词义组织词汇信息, 用同义词集合表示词义, 同义词集之间以语义相关联.对于本体O1中的概念A和本体O2中的概念B, 概念名称相似度计算方法为
其中: depth(x)表示该概念在WordNet树中所处的深度; lso(A,B)表示两个概念的最近公共祖先.
2.1.2 概念属性相似度计算 概念属性包括数据类型属性和对象类型属性, 本文采用文献[6]中的概念属性相似度计算方法.
对于数据类型, 将两个概念的数据类型属性按数据类型分类, 成为若干个属性集合; 对每种数据类型对概念A和B构造属性相似矩阵; 求出所有数据类型语义相似度的平均值, 记为S1(A,B).
对于对象类型, 设概念A和B的对象类型属性集合分别为attrA={a1,a2,…,am}和attrB={b1,b2,…,bn}, 且概念A和B的对象类型属性ai和bj所关联的概念分别是Ai和Bj.求出Ai和Bj的语义相似度作为概念属性ai和bj的相似度, 建立相似矩阵, 取出相似矩阵的最大项序列{t1,t2,…,tk}.该序列的算术平均数即为对象类型属性的语义相似度, 记为S2(A,B).基于数据类型属性和数据对象属性相似度, 概念属性相似度计算方法为
其中:α=数据类型属性数量/总属性数量;β=对象类型属性数量/总属性数量.
2.1.3 概念实例相似度计算 概念实例相似度计算[7]的原理为: 当本体中的概念具有相同的实例时, 概念可能是相似的.基于该思想的概念实例相似度计算方法为
其中CN表示属于概念N的实例集.
2.1.4 结构相似度计算 概念的结构包含丰富的语义, 两个概念的父概念和子概念的相似度会影响两个概念的相似性.因此可通过获取结构相似度度量概念间的相似度[8], 计算方法为

其中sim1和sim2分别是两个概念的父概念集和子概念集的相似度.
2.2相似度的合并
基于式(1)~(4), 概念A和B的综合相似度即为上述相似度值的加权平均, 计算方法为
其中ωi表示各部分相似度所占权重.在综合相似度计算中, 权重的确定关系到综合相似度计算结果的准确性和效率, 通常通过专家意见指定ωi, 这种人工参与方法直接影响了相似度计算的效率.近年来, 一些研究人员提出了运用Sigmoid函数自动生成各部分的权重, 但仍存在计算量大、区分度不高等问题.
3 基于粗糙集条件信息熵的权重确定
根据粗糙集理论, 设全域U表示参加相似度计算的概念对集合, 属性集合A={C,D}, 令条件属性集C={simname,simattr,simcase,simstruc}, 决策属性集D={d}(d的取值为1或0, 表示两概念相似与否), 属性的值域集合为V,f:U×A表示信息函数, 为U中的每对概念指定A中各属性的属性值.于是有决策表S=(U,C,D,V,f).
决策属性D(U/D={d1,d2})对各相似度属性C(U/C={c1,c2,c3,c4})的条件信息熵定义[9]为
相似属性ci的重要度定义[9]为
则各相似属性的权重为
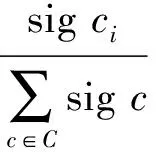
通过上述方法计算各属性的权重, 并将其应用到映射过程中.基于粗糙集条件信息熵的权重确定方法即为在信息不完整的情形下, 利用各部分相似度的信息熵及对整个系统影响的程度, 对其重要性给予评定, 最后确定各部分的权重值.整个过程可由程序自动进行, 避免了因为领域专家的过多参与而对系统性能产生影响, 为语义网的实时服务提供可能.
4 算法设计与实验验证
4.1算法设计
对于给定的两个本体O1和O2, 综合相似度计算中权重确定的算法如下.
输入: 待映射本体O1和O2;
输出: 概念对映射结果集;
1) 根据上述4种相似度计算方法分别计算O1和O2中各概念间的相似度simname,simattr,simcase和simstru, 记入数据集S1;
2) 随机选取O1中的一个概念A, 遍历源数据集S1, 选取数据构成历史数据集, 离散化处理后建立决策表;
3) 根据式(6)计算条件属性信息熵I(D/C),I(D/C1)和I(D/(C-{ci}));
4) 根据式(7)计算条件属性ci∈C的重要度;
5) 计算条件属性的权重ω(ci);
6) 处理当前映射中的每条记录, 运用权重ω进行加权平均, 得到概念间的最终相似度值, 获得最佳映射;
7) 循环; 处理源本体的剩余概念;
8) 结束.
4.2实验验证与分析
为了验证本文方法的有效性, 采用国际组织OAEI给出的测试数据benchmarks 2007中的标准本体test#101和同义词本体test#205进行实验.实验结果表明, 若两个概念存在相似的可能, 则两概念间的4种相似度值之和普遍大于某一阈值; 反之则小于(阈值的选取最好采用图像分割或Otsu自适应方法给定)该阈值.因此, 随机选取源本体中的一个概念(本文实验选取Organization, 简称Org), 在结果集中各随机选取6~8项记录, 以确保最少有两项其4种相似度之和不小于1.5, 并把其决策属性分别记为0和1(遍历后符合条件的词有Movie,Entry,Person等, 并将每条记录表示成Org-Movie的形式表示进行相似度计算的两个概念).这8组数据项作为相似度评价的历史记录, 将数据离散化后构成决策表, 结果分别列于表1和表2.
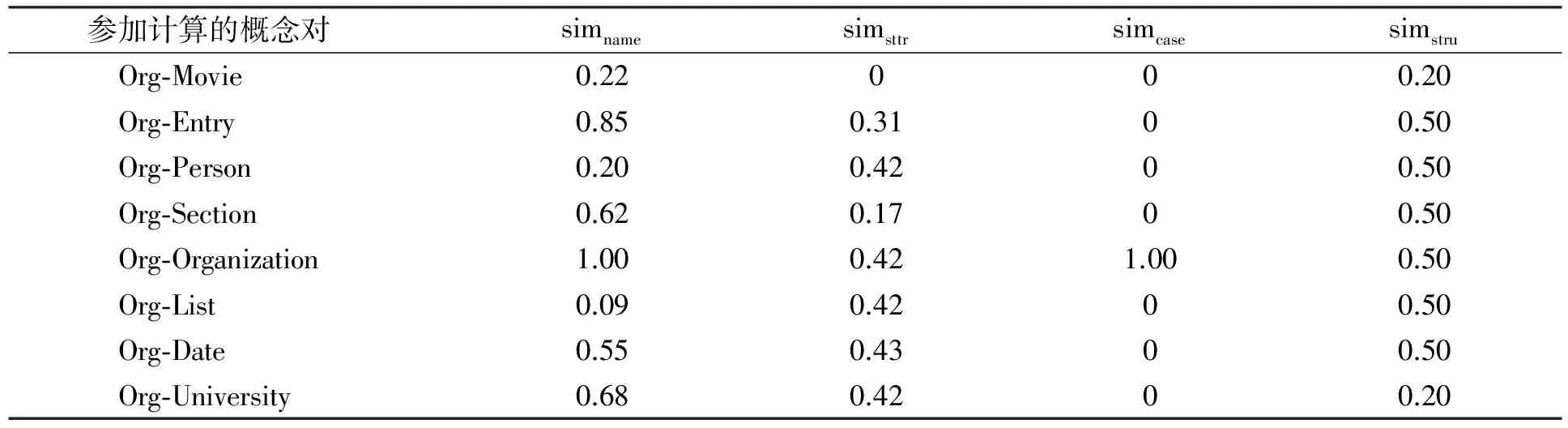
表1 概念对相似度Table 1 Similarity of concept pairs
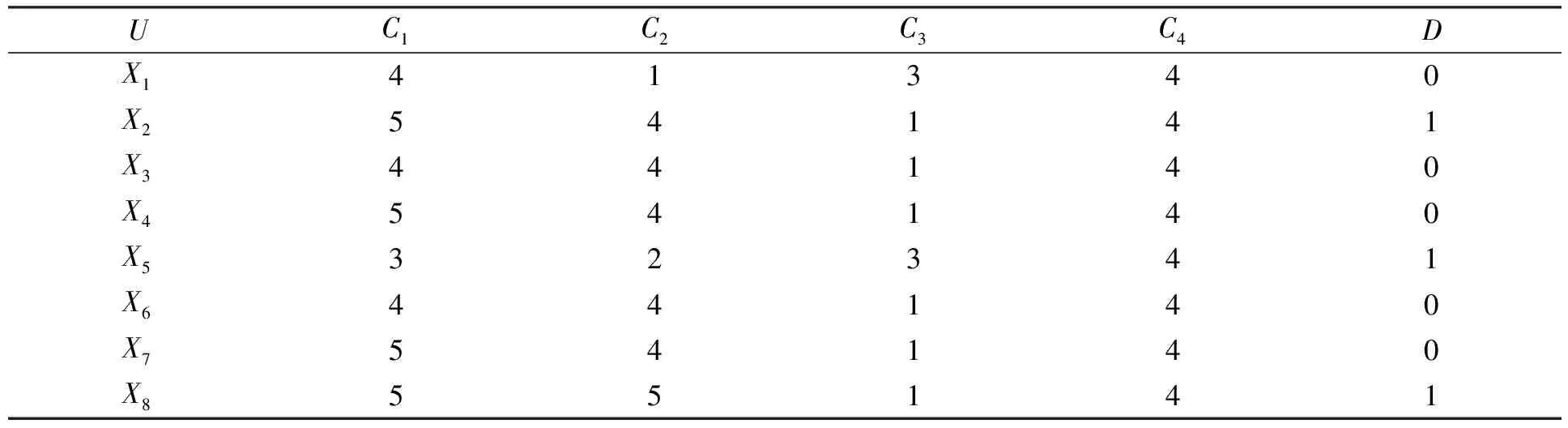
表2 决策表Table 2 Decision table
用式(6)~(8)计算各属性的权重:
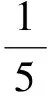
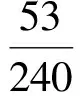
同理可得

最终每个属性的权重为
W(c1)=0.162,W(c2)=0.162,W(c3)=0.334,W(c4)=0.342.
由结果可见, 本文中所占权重最大的是概念结构的相似度, 而名称相似度权重最小.分析源计算结果集、源概念Organization和目标概念集间的simname值(即概念间名称相似度)相差较大, 对两个概念是否相似有很强的区分度, 应给予小的权重值; 概念间结构的相似度值在本文实验中相差不大, 但较大的结构差异将对最终结果产生决定性影响, 与本文方法所得结果相符.
由于本体开发者的习惯和同一领域内资源分布呈现一定规律等特点, 本体中的不同概念在结构和实例分布等方面所占的比重并没有太大差异.因此, 在本文方法中, 通过利用部分数据所得的权重值, 完全可运用到当前概念的整个映射过程中, 而避免了过多的重复计算.运用本文所得权重计算test#101和test#205间概念的相似度, 得到相似度最大的概念对集合, 与OAEI组织提供的结果集相比, 正确率基本达到要求.
将本文方法所得权重与其他采用Sigmoid函数方法所得的权重进行对比分析, 结果列于表3(用SigmoidX表示运用Sigmoid计算事件Xi中各属性权重的方法).
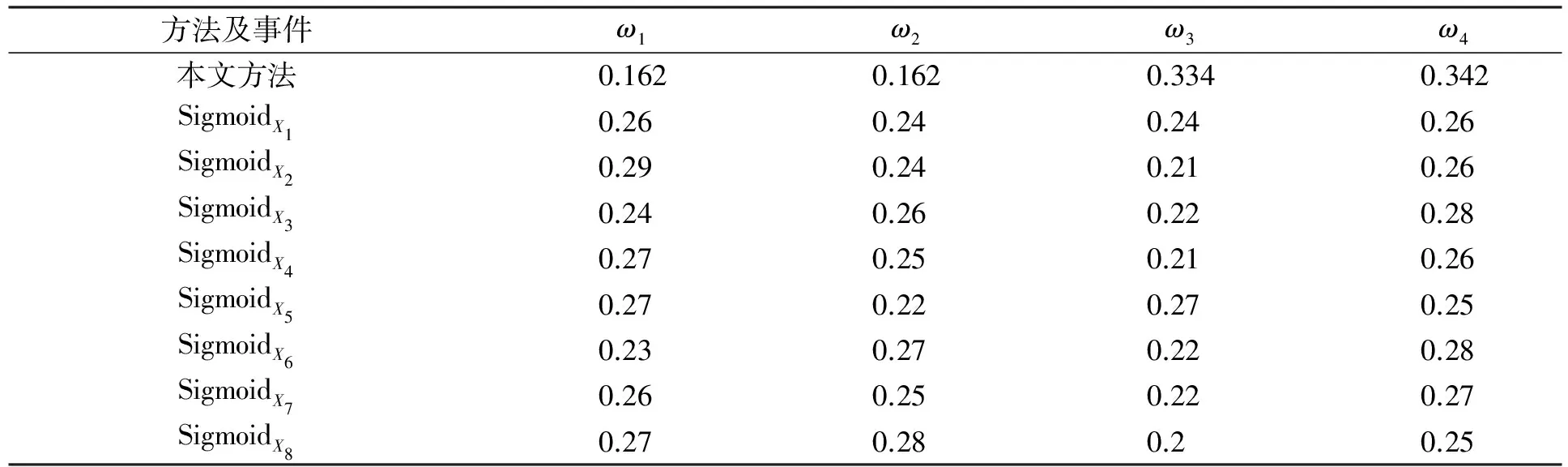
表3 本文方法与Sigmoid函数所得权重对比分析Table 3 Contrastive analysis between weight by this paper method and that by Sigmoid function
由表3可见, Sigmoid函数对每对概念都要进行一次运算, 计算量大, 且所得各权重值趋于平滑, 区分度不明显.而本文方法利用一部分数据, 经过分析计算最终得到的权重值在当前候选概念集映射过程中均适用, 避免了重复计算, 特别是在本体规模较大的情况下, 计算次数极大减少, 且计算结果更接近于实际权重.在本体领域的综合相似度计算中, 比Sigmoid函数更高效.
综上可见, 本文提出的方法改进了现有的综合概念相似度计算方法, 实验证明本文方法达到需求的同时避免了领域专家过多的参与, 从而达到综合概念相似度计算自动进行的目的.
[1]Gruber T R.A Translation Approach to Portable Ontology Specifications [J].Knowledge Acquisition, 1993, 5(2): 199-220.
[2]Shvaiko P, Jérme E.A Survey of Schema Based Matching Approaches [J].Journal on Data Semantics Ⅳ, 2005, 3730: 146-171.
[3]王颖, 刘群, 张冰.基于Top-k映射的本体匹配方法 [J].计算机工程, 2008, 34(15): 57-59.(WANG Ying, LIU Qun, ZHANG Bing.Ontology Matching Method Based on Top-kMapping [J].Computer Engineering, 2008, 34(15): 57-59.)
[4]Chantal Reynaud, Brigitte Safar.Exploiting WordNet as Background Knowledge [C]//International ISWC’07 Ontology Matching (OM-07) Workshop.Busan: [s.n.], 2007: 271-275.
[5]WU Zhibiao, Palmer M.Verb Semantics and Lexical Selection [C]//Proc of the 32nd Annual Meeting of the Association for Computational Linguistics.New York: ACM, 1994: 133-138.
[6]聂规划, 左秀然, 陈东林.本体映射中一种改进的概念相似度计算方法 [J].计算机应用, 2008, 28(6): 1563-1565.(NIE Guihua, ZUO Xiuran, CHEN Donglin.Improved Concept Similarity Computing Approach in Ontology Mapping [J].Computer Applications, 2008, 28(6): 1563-1565.)
[7]Doan A, Madhavan J, Dhamankar R, et al.Learning to Match Ontologies on the Semantic Web [J].VLDB Journal, 2003, 12(4): 303-319.
[8]徐德智, 肖文芳, 王怀民.本体映射过程中的概念相似度计算 [J].计算机工程与应用, 2007, 43(9): 167-169.(XU Dezhi, XIAO Wenfang, WANG Huaimin.Concept Similarity Calculating during the Process of Ontology Mapping [J].Computer Engineering and Applications, 2007, 43(9): 167-169.)
[9]鲍新中, 张建斌, 刘澄.基于粗糙集条件信息熵的权重确定方法 [J].中国管理科学, 2009, 17(3): 131-135.(BAO Xinzhong, ZHANG Jianbin, LIU Cheng.A New Method of Ascertaining Attribute Weight Based on Rough Sets Conditional Information Entropy [J].Chinese Journal of Management Science, 2009, 17(3): 131-135.)
WeightDetermineMethodforComprehensiveSimilarityCalculationaboutConceptofOntology
CHENG Jinhui, ZHENG Shanhong, LI Wanlong, YUE Shaomin
(SchoolofComputerScience&Engineering,ChangchunUniversityofTechnology,Changchun130012,China)
Using the theory of rough set and conditional information entropy, we presented a strategy to automatically determine the weight in connection with determining weight in integrated similarity calculation relying too heavily on domain experts in the ontology mapping method based on similarity calculation.In full consideration of uncertain information using the influence degree of each attribute on the system information entropy to determine each attribute’s weight in the current information system made the automatic mapping of ontology and semantic network real-time services possible.At last, the feasibility of this method was verified by examples.
ontology; similarity; concept similarity; rough set; information entropy; weight
2013-12-09.
成锦晖(1989—), 男, 汉族, 硕士研究生, 从事智能计算的研究, E-mail: cjh985034577@126.com.通信作者: 郑山红(1970—), 女, 汉族, 博士, 副教授, 从事智能计算的研究, E-mail: bioszsh2007@aliyun.com; 李万龙(1963—), 男, 汉族, 博士, 教授, 从事智能计算的研究, E-mail: lwl@mail.ccut.edu.cn.
吉林省自然科学基金(批准号: 20130101060JC)和吉林省教育厅“十二五”科学技术研究项目(批准号: 2014131; 2014125).
TP391
A
1671-5489(2014)06-1272-05
10.13413/j.cnki.jdxblxb.2014.06.31
韩 啸)
