基于大数据的出版流程变革
2014-08-21向安玲沈阳
向安玲 沈阳
[摘要]数据驱动的选题策划、读者主导的内容生产、机器智能的编排制作、精准定位的营销推广、“人”“文”交互式读者服务,大数据对出版流程可实现全方位、多角度、深层次的渗透。但在大数据的渗透过程中出版人必须把握主导权,在数据开放和隐私保护、作品质量和读者需求、内容生产和数据服务、海量数据和信息筛选之间权衡利弊。随着出版流程的数据化变革,未来出版行业的内容生产将从批量到个性,阅读模式将从私密到共享,销售模式将从固化到碎片,知识关联也将从平面到立体。
[关键词]大数据;数据类型;出版流程;流程变革
[作者简介]向安玲,武汉大学信息管理学院;沈阳,清华大学新闻传播学院。
大数据掀起的变革浪潮从学界、商界席卷到社会生活,部分出版企业已开始挖掘数据价值,探索多元化的业务变革。美国学乐(Scholastic)出版社通过在线游戏追踪人气线索和角色,由此创作了畅销全球的《The 39 Clues》系列小说[1];Coliloquy 出版社让读者参与情节和角色设计,通过数据分析调整内容,迎合大众口味[2];亚马逊的Kindle阅读器可以记录读者反复标注和强调的内容,对出版企业来说价值巨大[3];谷歌的图书数据库将1500-2008年间出版的各类图书数字化,通过文本分析揭示文化发展趋势[4]。国外出版传媒企业在数据创新中不断拓展出版价值,逐渐勾勒出大数据背景下图书出版的全新业态。相比之下,国内的出版企业则多处于驻足观望阶段,对大数据的设想远多于实践。在此背景下,本文对基于大数据的出版流程变革进行了分析,以求推动出版企业在大数据时代的创新和发展。
一、综述
关于大数据对出版行业带来的变革,业界的探索多于学界的研究。国外学者多从相关案例出发,总结出版企业利用大数据创造商业价值的实践经验。英国学者维克托·迈尔一舍恩伯格(2013)在《大数据时代》中对亚马逊和谷歌的图书数据化进行了评价。他认为亚马逊拥有大量数据化内容却没有通过文本分析发掘更大的价值,这对于出版企业而言是一个很大的损失[4];亚历山大·奥尔特(Alexandra Alter,2012)在文章《当心,电子书也在“读”你》中提到,包括Nook、Kobo、kindle在内的电子阅读器都开始记录读者的阅读行为,这些电子阅读数据已对出版流程带来多方面的变革[5]。
国内相关研究则主要集中在大数据时代下的出版企业转型和产业重构、商业模式构建、大数据技术应用等方面。张宏伟在国内首次明确提出“大数据出版”的概念,他认为大数据出版是构建在云出版之上的一种出版形态[6];吴赟对大数据时代出版产业重构所面临的问题做出思考,指出大数据将革新出版业对信息的搜集、储存和传播方式[7];刘鲲翔等人对大数据技术在出版行业中的应用前景做出展望,认为大数据在图书精准营销、生产过程优化、用户体验评估、数字教育等方面有很大价值[8];刘灿姣等人对云架构下出版企业大数据服务的动因进行了分析,并提出了搜集-分析-挖掘三个层次的大数据服务模式[9];张博等人对出版行业大数据的来源、分类和价值特点进行了分析,在此基础上对出版大数据的应用方式进行了探索[10]。
二、数据基础分析
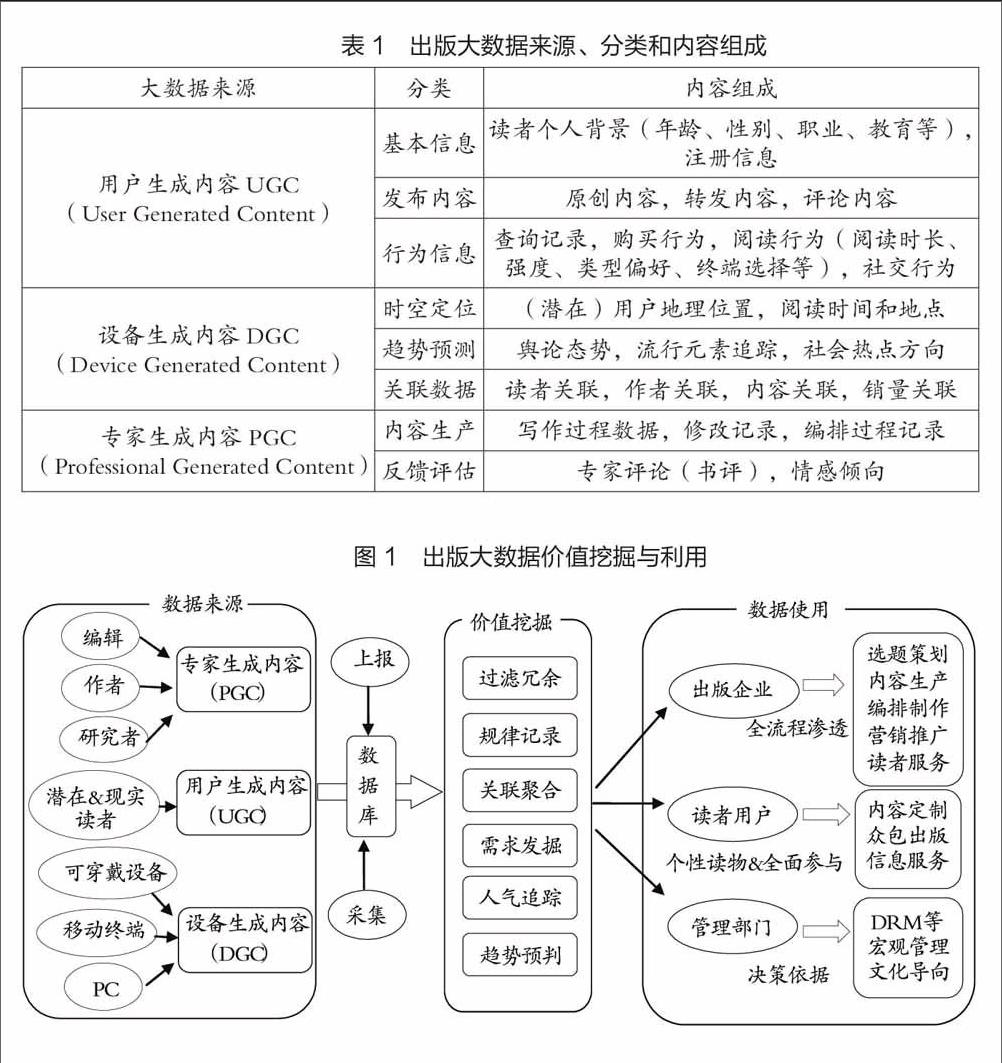
传统出版企业所掌握的数据资源通常是系统的、结构化的,数字出版和媒介融合使得出版数据不断拓展,大量非结构化数据被提取出来,出版企业需要通过过滤整理和关联分析去探索更深层次的价值。读者群体、专业团队和机器设备是出版过程中不可或缺的几大主体,他们参与到出版的各个环节并形成大量的出版数据。按数据来源本文将出版大数据分为用户生成内容(User Generated Content)、专家生成内容(Professional Generated Content)和设备生成内容(Device Generated Content)三大类,具体来源、分类和内容组成如表1所示。
对出版过程来说,用户生成内容(UGC)是一种驱动因子,可拓展出版内容广度,形成精细化市场;专家生成内容(PGC)是一种引导因子,可维持出版内容深度,形成品牌价值;设备生成内容(DGC)作为辅助因子对于发掘潜在读者群体和出版热点方向有预测导向作用。三种类型的数据对于出版企业都具有巨大的价值,本文将其价值挖掘和使用方式总结如图1所示。
三、流程变革分析
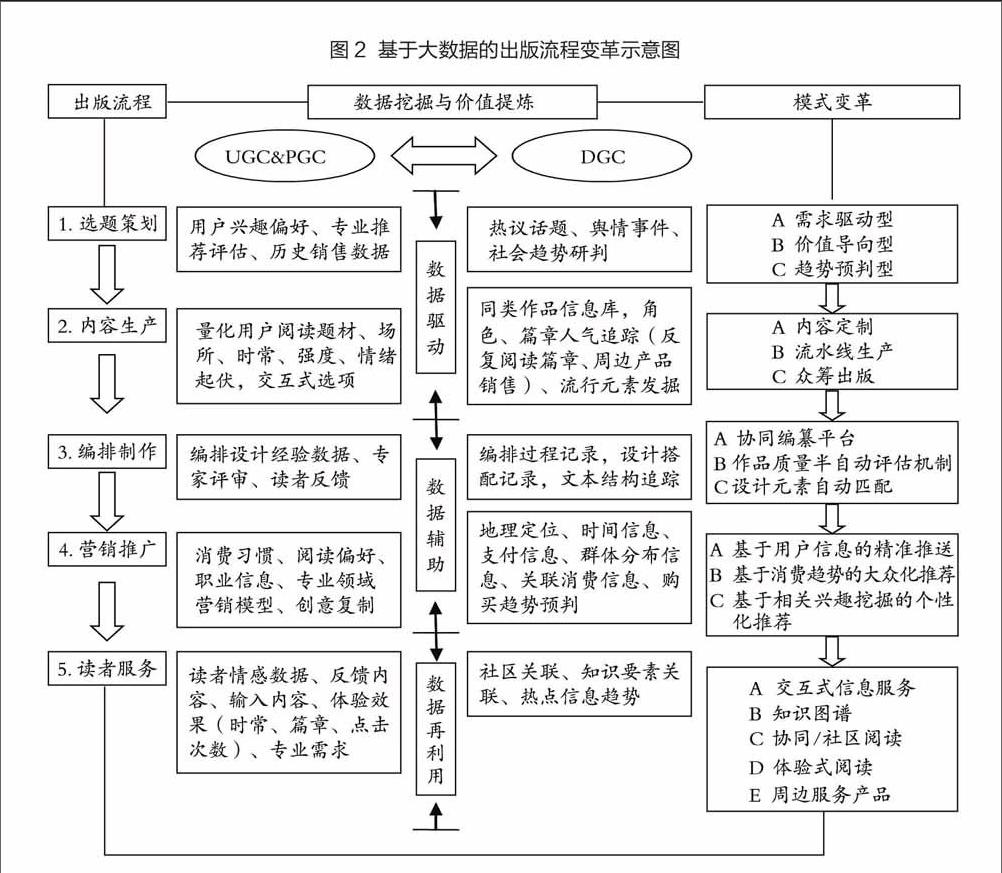
大数据以不同形式根植在图书出版的各环节中,逐步实现对出版流程全方位、多角度、深层次的渗透。本文从选题策划、内容生产、编排制作、营销推广和读者服务五个基本环节出发,分别阐述了大数据对出版流程的渗透方式和特点,得出以下流程图(见图2)。
1. 数据驱动选题策划
大数据作用于图书选题策划的过程,但并未改变选题的基本目的,需求驱动、价值导向、热点预判仍是其出发点。一方面,出版社从大数据分析中挖掘用户需求、进行趋势预判,利用专业经验获得更加精准的策划方案;另一方面,通过大数据的开放共享,让用户也参与到选题过程中,逐步形成具备自组织性、开源性的图书选题策划模式。这种读者参与度的变化也体现了选题策划从web1.0到web2.0、web3.0时代的转变,大数据的催化剂作用也将日益明显。
2. 读者深入内容生产
大数据时代“作者”的概念将被不断拓展,图书内容生产将更多地以读者为中心,让读者从出版产业链的终端参与到出版的各个重要环节中。通过量化分析读者的阅读题材、场所、时常、强度、情绪起伏等主观感受可以形成内容生产的“模范结构”。通过这些数据分析可以对作品篇幅长度、角色设定、文字风格、情节发展等方面做出人气评价,形成人气素材库、情节发展范式等储备资源,从而实现半自动化的流水线生产。
3. 机器智能编排制作
利用协同编纂平台进行编纂和交互的过程中会产生大量非结构化数据,比如文稿修改记录、易错文本记录、专家评审记录、编辑交流记录、时间进程记录等等。出版企业需要对这些“废弃数据”进行二次开发利用,从中发掘编纂过程中的问题环节、各环节的效率控制、需要注意的文本、编辑能力欠缺、专业经验和技巧等等,从而有针对性地进行编排过程优化和时间进度管理。此外,通过大数据技术探索图书编排设计的美学规律,从标签化的作品内容和设计风格的关联性分析中形成自动匹配机制,简化设计流程。
4. 精准定位的营销推广
出版企业根据用户消费数据(如价格接受区间、优先选择因素、常用支付方式等)可选择合适价位和类型的图书以合适的渠道进行推送;根据用户阅读偏好、职业信息和专业领域等数据,实现分类图书的按需推送;根据用户阅读行为数据(如阅读时间、场所、强度、终端选择等)也可确定推送图书的载体、篇幅、类别以及推送时间等要素;此外,通过对阅读同好圈内的活跃分子进行赠阅,还可实现口碑营销。除了静态数据,根据地理位置、时间、情绪等动态数据了解用户所处环境因素和心理需求,还可突破图书销售的时空限制。
5.“人”“文”交互式读者服务
出版大数据的深度开发、二次利用和开放共享让读者的消费形式发生变革,消费产品不再局限于图书内容,知识要素、关联数据、交互式信息等都被纳入出版企业服务范围。对出版大数据最直接的利用方式就是提供交互式信息服务,例如,谷歌的图书数据库提供了词频查询功能,用户可通过输入特定词组获取其历年(1500-2008)来的使用频率。虽然出版企业掌握的图书内容数据量有一定局限,但谷歌的数据服务模式是可以借鉴的,读者可通过I/O(输入/输出)方式实现对出版大数据的重组和利用,这也为出版企业开辟了新的收费空间。
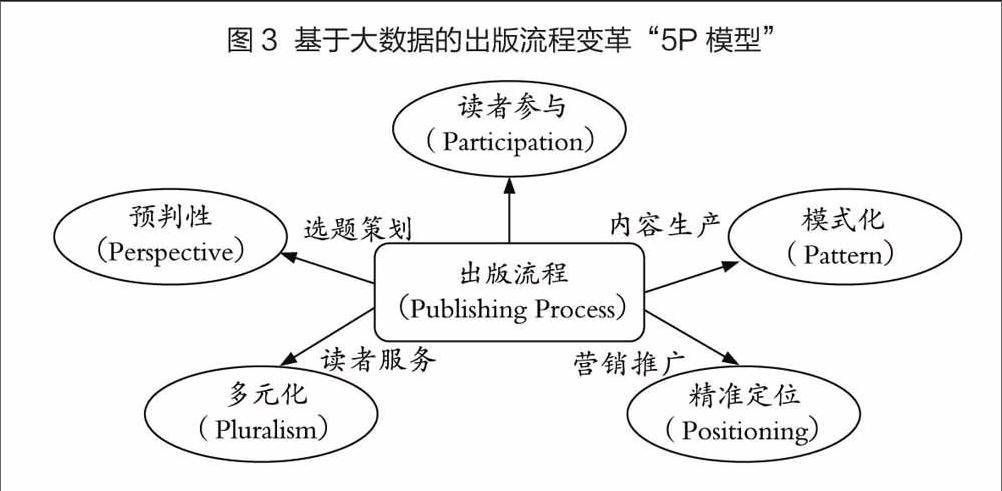
6. 出版流程变革“5P模型”
结合上文的分析,本文构建了基于大数据的出版流程变革“5P模型”。归纳总结了大数据对出版各环节的变革方式和优化方向,如图3所示。
大数据渗透到图书出版各环节。概括来说,数据驱动的选题策划将更具预判性(Perspective),更能把握读者潜在需求和社会发展趋势;众包模式的内容生产让读者的意愿能直接地反映在图书内容中,读者不再仅仅是知识信息的接收者,也是作品创作的参与者(Participation);从大数据中挖掘图书编排制作的经验模式和美学规律,打造机器主导、人工辅助的模式化(Pattern)编排流程;基于大数据分析实现读者市场定位、推广平台定位、时间空间定位、关联圈子定位,在精准定位(Positioning)的基础上提升图书营销推广的效率和准确性;出版内容作为一种高质量的大数据可为读者提供多元化(Pluralism)的信息服务,通过交互式服务进一步实现用户与文本的深层次对话。
四、数据使用之博弈
大数据威胁论令很多出版人惶然,但大数据给出版带来的不利影响并非大数据本身的缺陷,而在于出版人对大数据的利用是否合理。面临数据使用上存在的多面利弊博弈,出版人必须做好权衡选择。
1. 数据开放VS隐私保护
电子阅读器在不知不觉中窥视着读者的阅读过程,将阅读行为逐渐转变成一种可测量、半公开的数据化信息。很多情况下用户只能被动地成为数据源,对于企业而言这可能是价值衍生过程,但对于用户来说这很可能是隐私的二次利用。并不是每个读者都愿意公开自己的阅读行为和消费行为的,网络安全专家布鲁斯·施奈尔就表示“我们读的东西有许多是不想让别人知道的”。除了相关法律保障,出版企业也必须尊重读者私人阅读空间。
2. 需求驱动VS创意风格
大数据中蕴藏的商业价值在一定程度上扼杀了文化从业者的创造力和艺术追求。诸如Coliloquy、Scholastic的流水线生产模式虽然取得了不错成果,但这种程序化内容生产对作者的构思、创作、个人风格都带来了很大的干扰,不仅使得作品质量难以突破现有水准,也可能让读者产生一种审美疲劳和倦怠感。当然,读者需求和创意风格之间并不存在绝对的对抗性,出版人在利用大数据的同时,维持好内容把关者的角色,在两者间寻求最佳平衡点。
3. 内容生产VS数据服务
是专注于内容生产还是拓展数据业务,是选择合作共享还是把握数据所有权,大数据背景下出版企业的角色定位也面临着新的选择。无论是内容、数据、技术三足鼎立的旗舰式出版集团,还是精细化作业、分众化生产、专注于内容的小型工作室,都有自己的独特优势和发展空间。尽管大数据给出版业务带来了各种可能性,但选择最适合企业的发展方向才是最重要的。
4. 海量数据VS信息筛选
大数据强调的是混杂性而非精准性,但对于出版来说,知识信息的精准性至关重要。数据样本质量良莠不齐,分析过程也可能出现偏差,这使得大数据分析结果并不可靠。例如,读者的消费和阅读行为往往掺杂着很多非理性因素和偶然因素,根据数据分析结果进行定向推送很可能成为一种骚扰广告,使用户产生厌烦心理。尤其是在读者市场不成熟的情况下,出版企业更应慎重地利用大数据,加强数据分析团队的建设,从海量数据中挖掘真正有价值的信息。
五、 展望
大数据的运用是创意思维驱动的,出版企业在数据利用上存在很大的想象空间,本文对出版内容、阅读模式、销售模式、知识关联数据化发展做出了展望。
1. 出版内容:从批量到个性
大数据提供了一种新的按需出版模式。一方面,通过交互式选项获取读者偏好自动形成“私人定制”内容;另一方面,基于数据关联进行内容集成,为读者提供专属的“知识套餐”。从市场整体到垂直领域,再到特定群体和个体用户,精细化的数据分析让小众需求甚至是个体需求得以发掘,批量化的出版内容在分众市场不再具有竞争力,个性化定制将成趋势。而就短期发展来看,面向精英群体和专业领域的数据挖掘和内容定制将成为出版业务的一个新方向。
2. 阅读模式:从私密到共享
出版企业对用户数据的需求日益膨胀,个体、私密的阅读行为已无法满足企业的数据需求,在开放共享的阅读平台上去测量读者群体的行为数据和心理数据已成趋势。社交媒体和专业网站为我们提供了一种共享阅读模式,出版企业要做的则是将阅读与社交融合起来,打造开放性、社交化、分众化的阅读平台,实现媒介融合之上的平台特性融合。与此同时,针对敏感性读物或特定用户的私密化阅读空间也将独立出来,满足读者对隐私保护的需求。
3. 销售模式:从固化到碎片
大数据时代,出版企业面向的不再是“受众”,而将是“用户”,他们有权选择自己真正所需的内容片段,实现知识信息的高效率、低成本利用。出版物的售卖单位也不再局限于“一套”“一本”“一章”“一篇”或者“一段”,而将突破文本章节限制,根据用户需求实现信息内容的智能筛选和自动集成,甚至可提炼出主题思想、结论观点、写作模式、故事线索、人物特征、经典语录等内容单独出售,在人与文深层次交流的基础上实现具有针对性的碎片化销售。
4. 知识关联:从平面到立体
海量数据的关联将不再局限于表象,信息知识网络也将更加错综复杂。出版人要突破常规,形成思维的联动,为读者打造立体化、深度化、动态化的知识图谱,从而实现知识要素的关联推荐和打包出售。知识网络的节点将不再局限于图书、网页、多媒体等内容载体,一句话、一个人、一则新闻、一件历史事件、一个游戏产品……世间万物均可被提炼成相互关联的知识要素,共同构成以特定出版物为核心的知识网络。立体化的知识关联加强了出版企业与其他产品提供商的合作交流,也为用户提供了更深入的阅读体验和更全面的解决方案。
[1] 刘志伟. 云计算大数据升温中探模式[N]. 中国出版传媒商报,2013-11-08.
[2] Coliloquy:读者和作者互动,换个方式讲故事[EB/OL]. 腾讯网, http://tech.qq.com/a/20120119/000286.htm.
[3] 维克托·迈尔-舍恩伯格,肯尼思·库克耶. 大数据时代[M].杭州:浙江人民出版社,2013 .
[4] 杨鑫倢. 终有一天 大数据会“颠覆”出版业[N]. IT时报,2013-08-19.
[5] Alexandra Alter. Your E-Book Is Reading You [N]. The Wall Street Journal,2012.
[6] 张宏伟:出版业迎来“大数据出版”的新模式[EB/OL]. 中国经济网,
http://www.ce.cn/culture/gd/201307/09/t20130709_24555744.shtml.
[7] 吴赟. 产业重构时代的出版与阅读——大数据背景下出版业应深度思考的五个关键命题[J]. 出版广角,2013(12):32-36.
[8] 刘鲲翔,杜丽娟,丁雪. 大数据技术在数字出版中的应用前景展望[J]. 出版发行研究,2013(4):9-11.
[9] 刘灿姣,叶翠. 基于云计算的出版企业大数据服务研究[J]. 出版发行研究,2013(11):59-62.
[10] 张博,乔欢,李武. 基于大数据的出版内容价值发现与应用[J]. 出版发行研究,2014(3):5-8.
