改进型加权噪声功率谱估计算法
2014-08-14安宝坤
冯 炎 安宝坤
( 西藏大学现代教育技术中心, 拉萨 850000)
0 前言
现实世界中存在各种各样的噪声,语音信号常常被不相关的加性噪声所污染,噪声功率谱的变化要比语音缓慢的多,语音增强算法可以降低带噪语音信号中的噪声干扰。
在带噪语音信号中,常常假设噪声的均值为零,噪声方差即噪声功率谱需要予以估计。噪声功率谱的准确估计会直接影响语音增强效果。噪声功率谱的欠估计与过估计都会对语音增强算法带来较大的影响,噪声过估计会使增强后的语音出现较大的失真,原因是噪声的过估计等价于增益函数计算时后验信噪比和先验信噪比的欠估计,而后验信噪比和先验信噪比的欠估计会使算法过多地抑制噪声,从而使语音失真。语音增强的效果常常取决于噪声功率谱的准确估计[1-7],尤其是在非平稳噪声环境中。因此,快速地估计出背景噪声对语音增强算法有很大的帮助。
加权噪声功率谱估计算法(简称WN算法)能快速跟踪噪声变化,采用该算法使增强后的语音具有较高的语音质量[8]。WN噪声功率谱估计算法主要有三个步骤:即信噪比(简称SNR)估计, 通过估计出的信噪比结合加权因子函数从而得到加权因子,将带噪语音信号与加权因子相乘得到加权值并求平均得到估计出的噪声功率谱。
为了避免加权噪声功率谱估计算法不足,我们针对该算法提出了一个改进算法,该算法使用平滑因子对加权噪声功率谱估计算法计算出的噪声进行平滑。实验也验证了改进算法的性能。
1 加权噪声功率谱估计算法
用x(t)和d(t)分别表示纯净语音和不相关的加性噪声,观测到的带噪语音信号为y(t)为,进行短时离散傅利叶变换后得到:
Y(n,k)=X(n,k)+D(n,k)
(1)
其中n和k分别表示时间帧序号和频率点序号。
WN噪声功率谱估计算法首先从信噪比(简称SNR)估计开始, 通过估计出的信噪比结合加权因子函数从而得到加权因子,将带噪语音信号与加权因子相乘得到加权值并求平均得到估计出的噪声功率谱。

(2)
计算加权因子的非线性函数:
(3)

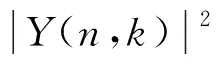
(4)
对计算得到的在窗口长度为Lz内的加权带噪语音求平均,进而得到估计的噪声功率谱:
(5)
式中Ψ(Z(n,k))表示Z(n,k)中非零元素的个数,trace{·}是对数组中对角元素求和的操作。由于Z(n,k)是一个行向量,所以trace{Z(n,k)}就是对简单的对该向量中的非零元素求和。
Z(n,k)计算如下:
(6)
式(6)是根据前面估计出的信噪比对Z(n,k)进行更新。Z(n,k)的长度一定,也就是求均值的窗长度不变,当所估计出的信噪比小于某个阀值时,认为该帧的噪声影响明显,则Z(n,k)求均值的窗需要更新一次,从而得到新的噪声估计值。

2 加权噪声估计算法的改进

(7)
在初始几帧一般都是噪声,本文对初始几帧进行平均,其中Tinit表示初始帧的大小。
3 仿真实验与结果分析
为评价本文提出的改进算法的性能,将WN算法及改进的WN算法分别应用于MMSE语音增强系统[6]进行实验仿真。实验中采用的语音段取自TIMIT数据库,分取其中的3个女声和3个男声。这些语音的采样频率是8kHz、16bits编码。实验中采用的噪声是来自于Noisex92噪声库,取其中的白噪声(White)、工厂噪声(factory)以及战斗机噪声(f16),将上述语音段分别与这3种噪声合成信噪比为0、5、10,15 dB的带噪语音。对这些语音信号作短时傅立叶变换,变换时采用分帧帧长为256点,帧间重叠为128点,为避免分帧时产生的截断效应,采用汉明窗对分帧的语音信号进行“加窗”处理。
先验信噪比估计中的参数设定[6]:α=0.98,ξmin=-25 dB。
改进算法中的参数设定:σ=0.96
为评价本文提出改进算法的性能,表1给出了噪声估计算法的相对估计误差对比。从表1可以看出,相对于传统的WN算法,本文提出的算法取得了更小的相对估计误差,从而证实改进算法抑制了更多的噪声过估计。

表1 相对估计误差对比
为了评价本文的语音增强算法的整体性能,表2给出了分段信噪比增益实验,值越大说明所增强后的语音越接近实际语音。从实验数据可看出,在不同的输入信噪比和不同的噪声环境的实验中,本文的改进算法可以较好地提高增强后语音的分段信噪比。
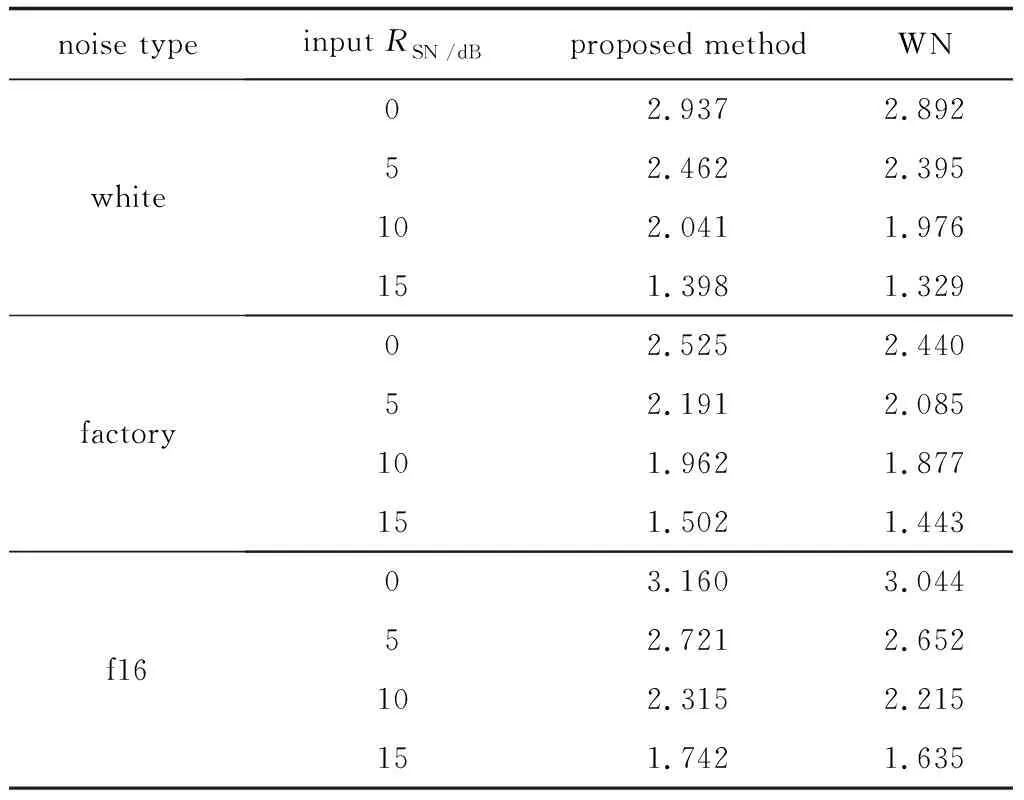
表2 分段信噪比增益对比
4 结 语
以上主要研究了带噪语音增强算法中的噪声估计问题。通过分析传统WN估计算法,发现该算法会在语音剧烈变化区域出现噪声过估计,针对该问题提出了改进算法,通过对WN算法估计的噪声进行平滑,从而抑制了在语音剧烈变化区域的噪声过估计。将改进算法应用到基于最小均方误差的语音增强系统时,发现采用改进算法能够提供更准确的噪声估计,进而会使增强后的语音有充分的噪声抑制和更好的语音质量。客观实验证实了该算法的优越性能。本文研究的结果为进一步的带噪语音识别技术奠定基础。
[1] Hao J,Attias H,Nagarajan S,et al.Speech Enhancement,Gain,and Noise Spectrum Adaptation Using Approximate Bayesian Estimation[J].IEEE Transactions on Audio,Speech and Language Processing,2009,17(1):24-37.
[2] Ephraim Y,Cohen I.Recent Advancements in Speech Enhancement[M]The Electrical Engineering Handbook:3rd ed.Boca Raton,FL:CRC,2004.
[3] 冯炎.基于直接判决估计和预测估计的语音增强算法[J],信息与电子工程,2010,8(1):76-7979.
[4] 冯炎,尼玛扎西.基于频带间相关性的加权噪声功率谱估计[J].信息与电子工程,2010,8(4):431-435.
[5] Benesty Jacob,Makino Shoji,CHEN Jingdong.Speech Enhancement[M].Berlin:Springer,2005:115-133.
[6] Ephraim Y,Malah D.Speech Enhancement Using a Minimum Mean-square Error Short-time Spectral Amplitude Estimator[J].IEEE Transactions on Acoustics,Speech and Signal Processing,1984,32(6):1109-1121.
[7] CappéO.Elimination of the Musical Noise Phenomenon with the Ephraim and Malah Noise Suppressor[J].IEEE Transactions on Speech and Audio Processing,1994,2(2):345-349.
[8] Kato M,Sugiyama A, Serizawa M,Noise Suppression with High Speech Quality Based on Weighted Noise Estimation and MMSE STSA[G].IWAENC,2001:183-186.
