基于空间自相关的支持向量机空间聚类研究
2014-08-08董承玮芮小平邓羽关兴良李峰
董承玮,芮小平,邓羽,关兴良,李峰
(1.北京市测绘设计研究院,北京 100038;2.中国科学院大学资源与环境学院,北京 100049;3.中国科学院地理科学与资源研究所,北京 100101;4.全国市长研修学院,北京 100029;5.防灾科技学院,河北 三河 065201)
0 引言
随着人类认知世界的技术和水平的飞速发展和提升,所需处理的多维度海量数据也越来越多,如何有效挖掘、利用这些数据,并转化成人们可以理解的信息和知识成为亟须解决的问题。降维作为能在低维可视空间中对数据内在结构和分布进行直观展现的技术,在数据分析中占据着越来越重要的地位。降维方法[1]从待处理数据的性质角度考虑,可分为线性方法和非线性方法:线性方法最常用的是主成分分析法(PCA)[2]和多维尺度变换[3-5];非线性方法有非线性映射(NLM)[6]、神经网络[7,8]等。对 于非线性结构的高维数据,线性的降维方法不能准确地分析和提取其内在的结构;而非线性方法的数学理论基础不同,各类方法的结果也各不相同。从是否需要已知样本训练分类过程的角度看,降维方法可划分为非监督分类和监督分类,以上所有算法都是非监督算法,而支持向量机(SVM)[9-12]是典型和常用的监督算法。
传统的降维研究大都运用的是非监督算法,这在没有已知样本集时能在一定程度上揭示多维数据的内在结构,但不同算法数学理论依据和适用范围不同,最终的结果具有较大差异,且聚类准确程度也无法相互验证。支持向量机从理论上能得到全局最优解,解决了在神经网络方法中无法避免的局部极值问题;SVM通过非线性变换将数据映射到高维特征空间,并用线性判别函数对数据分类,可以保证机器有较好的推广能力;SVM巧妙解决了维数问题,算法复杂度与样本维数无关。但作为监督分类,SVM需要已知样本集来训练分类过程,PCA和NLM算法的降维结果都可以作为选取SVM已知样本的依据,但研究证明选样过程的主观性对SVM分类结果的影响很大[13]。空间自相关[14-16]能分析多维经济统计数据的空间集聚程度,并揭示发展中心和典型区域,这些典型区域可被作为已知典型样本集来训练SVM的分类,这个过程将大大减小选样的主观性。
本文提出了一种空间自相关-SVM耦合分析的方法,即基于空间自相关分析选取小样本集,并结合SVM监督分类得到聚类结果。结合2007年四川统计年鉴数据及四川经济发展现状与规划[17-21],分别对PCA-SVM、NLM-SVM 和 空 间 自相关-SVM耦合分析聚类结果进行比较,验证了本文方法的优点。
1 方法原理简介
1.1 空间自相关
传统的统计学方法建立在样本独立与大样本假设的基础上,由于空间数据的特殊性,其独立性和大样本假设常得不到满足。空间统计学中的空间自相关技术很好地解决了经典统计方法在空间数据应用上的缺陷。空间自相关性使用全局和局部两种指标来度量,全局指标用于探测整个研究区域的空间模式,用单一的值反映该区域的自相关程度;局部指标计算每个空间单元与邻近单元某一属性的相关程度。由于全局指标有时会掩盖局部状态的不稳定性,因此在很多场合需要采用局部指标来探测空间自相关。常用的计算空间自相关的方法有Moran′s I、Geary′s C、Getis、Join Count等,本文基于 Moran′I研究四川经济发展的空间格局。Moran′I分为全局 Moran 指 数[14,15]和 局 部 Moran 指 数[16]:全 局Moran′s I从总体上反映了研究目标的空间相关性,局部Moran′s I描述区域单元与其相邻区域单元之间的空间集聚程度。
1.2 支持向量机
支持向量机在解决小样本、非线性及高维模式识别中表现出如下特有的优势:1)SVM避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题;2)SVM是专门针对有限情况的,其目标是得到现有信息下的最优解而不仅是样本数趋于无穷大时的最优值;3)计算的复杂性取决于支持向量(Support Vector,SV)的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”;4)算法最终将转化成为一个二次型寻优问题,从理论上而言,得到的结果将是全局最优解,解决了在神经网络方法中无法避免的局部极值问题,因而它具有很好的泛化性能和预测能力[22]。从本质上看,SVM是一种监督分类方法,在对数据进行分类时,必须要有一个已知样本集训练SVM。在SVM的训练样本选择策略中,有随机选样策略、盒子类凸包样本选择方法[23]、Adaboost方法[24],也可以通过PCA或者NLM算法的分类结果选择典型样本。
1.3 基于Moran的样本集选择
通常,经济统计数据不包含已知正确分类的样本集,而基于不同选择策略的SVM分类结果差异很大,因此,样本选择策略是采用SVM分析经济统计数据的关键,其方法的正确与否直接影响到分析结果的正确性。
在局部空间自相关中,滞后变量Wzi表示目标观测值相邻区域的加权平均对偏离平均值的度量,zi为对观察值x偏离平均值的度量。以(Wz,z)为坐标点的Moran指数散点图,常用来可视化研究局部空间不稳定性。Moran指数散点图的4个象限,分别对应于区域单元与其邻居之间4种类型的局部空间联系形式:第一象限(H-H区)代表高观测值的区域单元被同是高值的区域所包围的空间联系形式;第二象限(L-H区)代表低观测值的区域单元被高值的区域所包围的空间联系形式;第三象限(L-L区)代表低观测值的区域单元被同是低值的区域所包围的空间联系形式;第四象限(H-L区)代表高观测值的区域单元被低值的区域所包围的空间联系形式。
从区域经济发展角度看,经济发展中心对周边存在很强的作用力,使得周边区域经济也发展良好,这对应于H-H类型;而经济落后区域由于地形、交通等区域条件的限制具有较强的集聚特征,从而对应于L-L类型;经济发达区域的边缘地带由于自然条件或者政策性等问题制约了发展,属于L-H类型;而在欠发达地区,某些区县旅游、矿产等资源优越,发展具有一定优势,属于H-L类型。这种多维经济统计数据的局部空间分布模式,可以揭示经济发达区域、较发达区域、欠发达区域及奇异点,并进一步提取经济发展中心和典型区域。这些典型区域在一定程度上可作为已知典型样本集训练SVM分类过程,从而减少选样过程的主观性。

图1 Moran-SVM技术路线Fig.1 The Moran-SVM technology process
由此可以建立空间自相关-SVM耦合的空间聚类方法,图1显示了基于 Moran′s I的SVM聚类(Moran-SVM)的流程,其步骤为:1)运用空间自相关分析经济统计数据的PCA和NLM降维结果,得到Moran指数散点图和空间自相关显著性分析图;2)通过研究象限分布图和显著性分析图,提取高显著经济发达和不发达、较显著经济发达等各种不同发展类型的典型区域;3)将典型区域作为已知样本集导入SVM模型,得到聚类结果。
2 应用实例
2.1 数据说明
本文以2007年四川统计年鉴数据为例,对四川省区县尺度的多维度经济统计数据进行分析。在行政单元为区县的经济统计数据中,大量属性维度的数据统计不完整。基于降维过程的维度应尽量最大化及其可获得性考虑,本文选择统计年鉴中最能反映地区经济发展情况的18个属性,分别是:国内生产值(第一、第二、工业、第三产业和人均生产总值)、民营经济生产情况(第一、第二、工业、第三产业和人均民营经济增加值)、从业情况(从业人员、职工人数、人均工资)、地方财政(财政收入和支出)、农林牧渔总产值、社会消费品零售总额、全社会固定资产投资。
2.2 基于 Moran′s I的SVM 聚类
笔者利用空间自相关对PCA和NLM的降维结果进行分析,得出四川经济统计数据的局部Moran′I散点图及其显著性分布图(图2-图5),通过分析典型区域的局部空间联系类型及其显著性,提取出若干经济发展情况明确且典型的区县,作为已知小样本集导入SVM中进行分类。
对PCA降维结果进行局部Moran指数分析,得到象限分布图(图2):成都周边-东南区域沿线、攀枝花处于第一象限,即属于H-H类型;第一象限周边区域受高观测值邻域影响,属于第二象限,即L-H类型;广大的西北区域、中南、多数东北和少数东南区县属于L-L类型,区县本身和周边邻域的观测值都较低;H-L类型主要集中在东北区域及第二象限周边的区县,绝大部分与L-L类型相邻,表示其观测值比较高,属于经济较发达地区。分析局部Moran指数的显著性分布图(图3)可知:四川绝大部分区域属于空间聚集不显著类型,而成都周边12个区县的空间聚集非常明显,其外围的德阳市等3个区县也具有显著的空间相似性,宜宾市也表现出较为显著的空间聚集效应;广大经济不发达的西北区域和南部攀枝花市则表现出离散的空间分布形式,这与现状有一定差异。

图2 PCA降维结果的Moran指数象限分布Fig.2 Moran′s I quadrant map of PCA

图3 PCA局部Moran指数显著性分析Fig.3 Significance of local Moran′s I of PCA

图4 NLM降维结果的Moran指数象限分布Fig.4 Moran′s I quadrant map of NLM

图5 NLM局部Moran指数显著性分析Fig.5 Significance of local Moran′s I of NLM
对NLM降维结果进行局部Moran指数分析,得到象限分布图(图4):东北区域-成都周边-东南区域沿线属于H-H情况;第一象限周边区域受其影响,属于L-H类型;广大的西北区域、中南和少数东南区县属于L-L类型;H-L类型主要集中在成都周边和南部区县,与L-L类型相邻,属于经济相对较发达地区。分析局部Moran指数的显著性分布图(图5)可知:四川东北、中南和东南区域都属于空间集聚不显著类型,而成都周边、广大西北区域空间集聚非常显著,较为显著的区县主要分布在显著区域的周边邻域地区。
基于PCA和NLM降维结果的Moran指数显著性分类结果可知,成都周边为高显著H-H类型,西北地区为高显著L-L类型,可分别采集到第一等级和第四等级的小样本集;从两者的Moran′s I象限分布图可知,成都外围和东北广安市附近区县属于第一象限,经济较周边发达,而空间聚集效应又不显著,可作为第二等级;在东北区县和第四等级的交叉区域,存在部分相对高值区域,其较落后区域发达,可作为第三等级。依次每个等级采集3个样本,导入SVM算法中,并采用RBF核函数[13],调节参数,结果如图6。
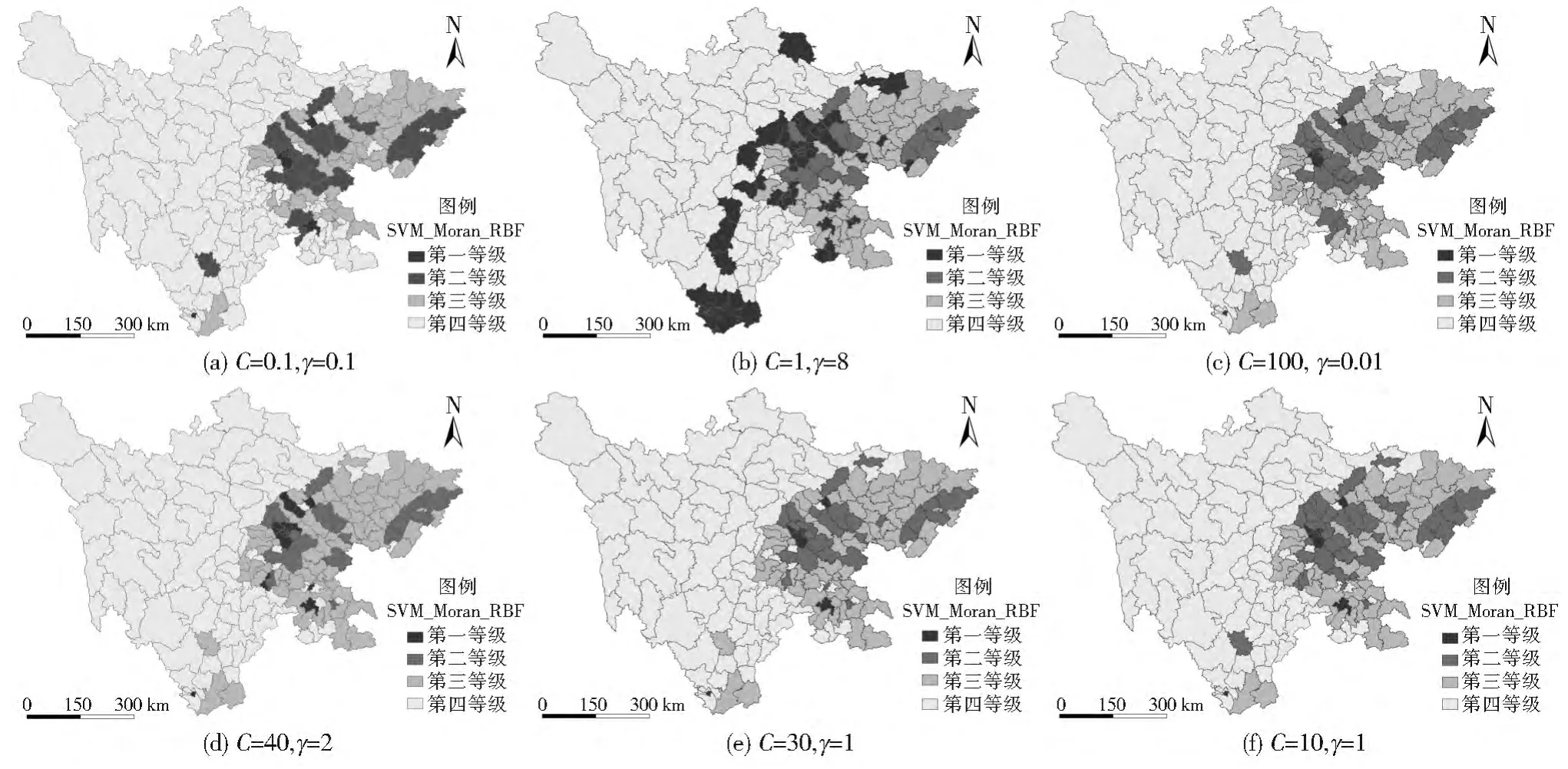
图6 Moran-SVM分类结果Fig.6 The classification map of Moran-SVM
当γ取值较大(大于2)时,分类结果出现欠学习问题,有非H-H类型被划入第一等级;而其他参数条件下的分类结果差异不大,将成都周边、涪城区和攀枝花东区分为第一等级,将成都周围其他区县和东北少数区县分为第二等级,将东北和东南其他区县及南部分为第三等级,广大的西部、北部和东南区县则属于第四等级,这与四川经济发展现状完全吻合。与NLM分类结果相比较,具有很强的相似性,这也说明了结果的正确性。
2.3 结果分析
(1)采集于PCA和NLM的不同已知样本集的SVM聚类结果之间差异大(表1)。在PCA-SVM中,第二等级区县的数目非常少,而东北多数区县被划分至第四等级,并与PCA的分类结果相似,都未能准确展现四川经济发展现状;而NLM-SVM的结果与NLM类似,都能体现出经济发展的核心区域及经济较发达区域。由这两者结果之间的较大差异可知,已知小样本集选取的主观性对结果影响很大,所以需要进一步考虑样本集的合理选择。
(2)针对上述已知样本集选取的主观性问题,笔者利用PCA和NLM的空间自相关分析结果选取样本集,证明该步骤不仅能大量减少样本集的选择范围,而且分类结果能揭示出成都经济发达地区、东北和东南经济较发达区域、西北经济极不发达区,能准确展现四川经济发展现状(表1)。
SVM作为一种监督分类算法,需要已知样本集对聚类过程进行训练,由于经济统计数据不具有已知类别样本,需要利用一定的方法来选取,而选样过程的主观性对SVM的分类结果具有很大的影响,同时最优参数的获取是一个复杂的区间搜索过程,不仅较难获取最优参数,而且效率也较低。PCA和NLM降维结果的Moran指数分析结果能揭示出显著的H-H和L-L类型,而 Moran指数的象限分布能提取出空间集聚不显著、但能揭示经济发展情况的典型空间单元,从而得到不同经济发展水平的典型区域,这些典型区域可作为小样本集训练SVM算法聚类过程。分类结果正确揭示了四川经济发展现状的空间格局,证明该方法能大大缩减样本集的选取范围,避免选样过程的主观性,并具有很好的分类效果,这为SVM已知样本集的合理选取提供了新方法。

表1 各种方法的等级分布比较Table 1 The comparison of classification results of different methods
3 结论
SVM具有很好的数学理论基础,能避免“维数灾难”,具有很好的泛化性能,且算法效率高,能够最大化各类之间的距离,对具有已知样本集的数据能很好地进行分析;但它是一种监督分类,在分析经济统计数据过程中缺少已知样本,需要利用选样策略选取典型样本,比如在PCA和NLM等算法的降维结果中选取不同类别的典型单元,但该过程主观性较强,对聚类结果的准确性影响很大,为此笔者提出运用空间自相关分析数据的局部空间聚集模式及其显著性指数,并基于局部Moran′I散点图和显著性分布图提取不同类别的已知小样本集,再训练SVM聚类过程,以解决选样过程中的主观性和复杂性问题。本文论证了空间自相关不仅能大量减少特征样本集的数目,同时能准确提取不同经济发展水平的典型区域,这不仅简化了SVM算法小样本集选取过程,其聚类结果也能准确反映四川经济发展实际情况。空间自相关和SVM耦合方法不仅能大量缩减选样范围和简化选样过程,从而提取出不同类别的典型样本和解决样本选择的主观性问题,同时也能基于SVM的优点准确揭示高维数据的内在聚类结构。
[1] 吴晓婷,闫德勤.数据降维方法分析与研究[J].计算机应用研究,2009,26(8):2832-2835.
[2] 张吉献.基于主成分分析法的河南省各城市综合实力评价[J].河南科学,2009,27(1):115-118.
[3] BORG I,GORENEN P.Modern Multidimensional Scaling:Theory and Application[M].Springer:New York,1997.
[4] DIMITRIS K A,DMITRII N R,VICTOR S L.Multidimensional scaling and visualization of large molecular similarity tables[J].Journal of Computational Chemistry,2001,22(5):488-500.
[5] NAUD A.An accurate MDS-based algorithm for the visualiza-tion of large multidimensional datasets[J].Artificial Intelligence and Soft Computing-ICAISC 2006,2006,4029:643-652.
[6] SAMMON J W.A nonlinear mapping for data structure analysis[J].IEEE Transactions Computers,1969,18(5):401-409.
[7] 高隽.人工神经网络原理及仿真实例[M].北京:机械工业出版社,2003.8.
[8] 阎平凡,张长水.人工神经网络与模拟进化计算(第二版)[M].北京:清华大学出版社,2005.
[9] CORTES C,VAPNIK V.Support vector networks[J].Machine Learning,1995,20:273-297.
[10] BURGES C J C.A tutorial on support vector machines for pattern recognition[J].Data Mining and Knowledge Discovery,1998,2(2):121-167.
[11] GUNN S.Support Vector Machines for Classification and Regression[R].ISIS Technical Report,1998.
[12] 张学工.关于统计学习理论与支持向量机[J].自动化学报,2000,26(1):32-42.
[13] 董承玮,芮小平,邓羽,等.空间多维经济统计数据的降维方法——以四川省经济统计数据为例[J].地理研究,2012,31(8):1411-1421.
[14] GETIS A,ORD J K.The analysis of spatial association by use of distance statistics[J].Geographical Analysis,1992,24:189-206.
[15] GOODCHILD M F.Spatial Autocorrelation,Concepts and Techniques in Modern Geography[M].Norwich,UK:Geo Books,1986.
[16] ANSELIN L.Local indicators of spatial association[J].Geographical Analysis,1995,27:93-115.
[17] 王如渊,李翠华,张学辉,等.四川省FDI区位选择的特征与机理[J].地理研究,2008,27(2):385-396.
[18] 陈钊.四川重点区域发展战略研究[J].西华大学学报(哲学社会科学版),2005,4(3):17-20.
[19] 李斌,董锁成,李雪.四川省生态经济区划研究[J].四川农业大学学报,2009,27(3):302-308.
[20] 张杰.川渝经济发展水平的比较研究[J].重庆工学院学报,2006,20(7):47-49.
[21] 张杰.重庆、四川主要经济指标的比较研究[J].重庆工商大学学报(西部论坛),2006,16(3):43-45.
[22] STEINWART I.On the influence of the Kernel on the generalization ability of Support Vector Machines[J].The Journal of Machine Learning Research,2002,2:67-93.
[23] 姜文瀚,周晓飞,杨静宇.核子类凸包样本选择方法及其SVM应用[J].计算机工程,2008,34(16):212-124.
[24] 易辉,宋晓峰,姜斌,等.基于AdaBoost方法的支持向量机训练样本选择[J].仪器仪表学报,2009,30(10):72-74.
