基于GMM的说话人识别系统设计与实现
2014-08-07滕广超林嘉宇
刘 冰,滕广超,林嘉宇
(1.国防科学技术大学电子科学与工程学院,长沙410073;2.武警湖南省总队湘潭市支队,湘潭411104;3.武警黄金一总队通信科,哈尔滨150086)
基于GMM的说话人识别系统设计与实现
刘 冰1,2,滕广超1,3,林嘉宇1
(1.国防科学技术大学电子科学与工程学院,长沙410073;2.武警湖南省总队湘潭市支队,湘潭411104;3.武警黄金一总队通信科,哈尔滨150086)
现代通信中,说话人的身份认证技术一直是通信行业研究的重点和热点。而基于GMM和MFCC的说话人识别技术,是目前为止相对成熟和常用的方法。对说话人识别系统的构成做了相关的研究,并通过MATLAB编程,设计了一款以MFCC作为特征参数,基于GMM模型的说话人识别系统。经过实验测试,本系统能基本满足工作及家庭生活环境下的说话人识别需要。
说话人识别;Mel倒谱系数;混合高斯模型
1 引 言
说话人识别(Speaker Recognition)[1],也称声纹识别(Voiceprint Recognition),是一种利用说话人的语音特征与预先提取的说话人的语音特征相比较,进而确认和鉴别说话人身份的技术。说话人识别技术的研究始于二战时期美国的Bell实验室,经过几十年的研究和发展,说话人识别技术取得了突飞猛进的发展。特别是1995年,Reynolds[2]对高斯混合模型(Gaussian Mixture Model,GMM)[3-4]进行了详细介绍和应用,其简单、实用、高效的特点,使之成为说话人识别模式匹配过程中的重要技术。说话人识别可分为说话人确认(Speaker Verification)和说话人鉴别(Speaker Identification)两类。
2 说话人识别系统原理
说话人识别系统一般由训练模块和识别模块组成。其原理如图1所示。

图1 说话人识别系统原理框图
2.1 说话人识别系统预处理
说话人识别系统的预处理过程一般可分为:采样与量化、预加重处理、加窗和端点检测。
语音信号经过采样和量化之后,信号由模拟转为了数字信号。为便于频谱分析或声道参数分析,需要对信号进行预加重。预加重可以用一阶数字滤波器来表示:

其中μ为预加重系数,取值为0.9375。
根据语音信号在10ms到20ms内近似不变的假设,可以将语音信号分成一些短的段进行处理,即分帧。分帧后进行加窗,采用汉明窗函数。
端点检测(VAD)方面,采用的是短时能量与短时过零率相结合的方法,由此判断语音信号的起始点位置。短时能量可用来区分清音段和浊音段,有声段和无声段。短时过零率则表示一帧语音中语音信号波形经过零电平的次数。由于短时过零率对噪声非常敏感,很容易产生虚假过零,故我们对其进行了改进。设立一个门限T,将过零率的定义改进为越过±T的次数。即
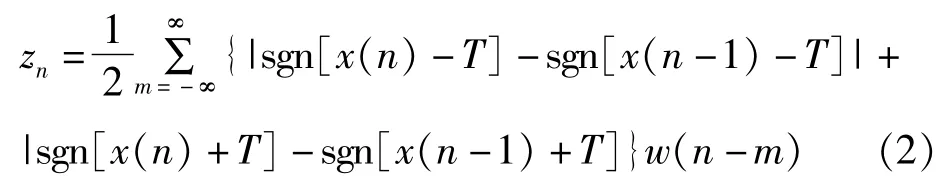
经过改进后,短时过零率有了较强的抗干扰能力,同时在进行说话人识别端点检测时,可以设立多个门限,进一步提高检测精度。
2.2 MFCC特征提取
Mel频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)[5-6]是一种基于梅尔尺度的频域倒谱参数。MFCC运用Mel频率刻度对实际频率轴进行弯折来模拟人耳所听到的声音高低和声音频率之间的非线性关系,因而在说话人识别中得到了极为广泛的应用。系统中MFCC参数提取的流程是:
(1)对语音信号进行预处理,其中语音采集频率8000Hz、16-bit、Mono,帧长为20ms,帧移为10ms;
(2)快速傅里叶变换(FFT):使用基2的离散傅里叶变换,将时域能量转换为频域能量;
(3)Mel能量:通过40个Mel滤波器组,得到40维的Mel频子带能量;
(4)Mel对数能量:对每个MEL频子带能量取对数,mel(i)=ln[filt(i)];
(5)离散余弦变换:

其中D=13,mfcc(n)即为原始的mfcc特征;
(6)一阶二阶差分:在原有13维mfcc特征的后面加入13维的一阶和二阶差分构成39维的特征。可通过一个长度为5的窗函数来求,从而使得这种静态特征得到相应的动态特征。通过实验表明,这种39维的动态特征能够很好的提高系统识别性能。
2.3 基于GMM混合高斯模型的模式匹配
混合高斯模型对不同说话人语音的短时谱特征矢量所具有的概率密度函数进行建模。通过对这些特征矢量进行聚类,并看做是一个多维的高斯分布函数,然后求出每一类的均值、协方差矩阵和出现的概率,作为每个说话人的模板。最后把观测序列代入模板,进行模式匹配,找到最大后验概率,即对应识别的人。
M阶GMM概率密度函数如下:

其中s为语音的特征矢量,M为高斯混合模型中分量的个数,αj为混合权值;P(s|λ)表示s属于λ模型的概率。其中等j个混合高斯概率密度函数可表示为P(s):
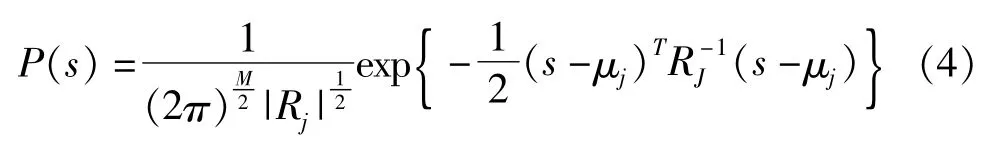
其中μj为均值向量,Rj为协方差矩阵。一个完整的混合高斯模型是由参数混合权重、均值向量和协方差矩阵组成,可表示为:

系统中的模式匹配即所有参考说话人构成的一个集合,识别判断目标说话人与集合中的哪一个说话人相匹配。其目的就是找到目标说话人与集合中模型的最大输出匹配概率,使得待识别语音特征矢量组X具有最大后验概率P(λi|X)。
由Bayes理论,最大后验概率可表示为
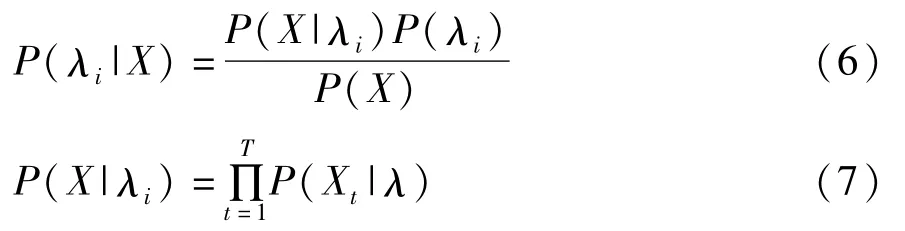

3 说话人识别系统软件开发
3.1 系统设置与数据库
实验主要是在PC机平台上,采用MATLAB 7.0编程语音完成的。系统以有源型麦克风作为录制语音的输入工具,运用CoolEdit ProV2.1对录入后的语音进行处理。
实验数据来自实验室环境下的采集。语音库中包含了30个说话人(15男,15女),年龄范围在10岁至40岁之间,共进行300次说话人识别测试。实验所用的主要参数如表1所示。

表1 实验主要参数列表
3.2 系统功能设计
该说话人识别系统具有以下功能:
(1)能较准确的识别待验证人是否为合法用户;
(2)可实现语音波形的显示;
(3)可训练说话人语音,增加训练样本库;
(4)可较准确的识别待验证人的身份信息。
3.3 系统基本结构
说话人识别系统主要分为两个部分:训练过程和识别过程。
在训练阶段,首先读取训练对象的若干语音文件作为训练语句,然后对这些训练语句进行端点检测、预加重、MFCC特征参数提取,最后为训练对象建立各自的语音特征参数模型。
在识别阶段,首先将事先录制的语音文件作为测试语句在系统中读取,然后系统对这些测试语句的特征参数进行提取,然后将这些参数与系统内部建立的各个语音模型进行特征参数相似度计算,最终得到识别结果。
3.4 系统性能评估
一个说话人识别系统的好坏主要由正确识别率、训练时间长短、识别时间长短、语音环境变化等元素进行反映。一般来说,一个好的说话人识别系统,应该具备较高的正确识别率,较短的训练时间,较短的识别时间,能适应多种语音环境等特点。
为了测试系统性能,系统使用了39维差分MFCC特征参数进行了小数据库文本的说话人识别实验,参与实验的共有30人(15男,15女)。在录入训练样本时,每人录入4句文字和2句数字,共录两次,累积时长为1分钟,建模时间约为30s。测试时,每人再录入1句文字和1句数字,共录两次,累积时长为20s。在测试过程中,将每人的测试语音分别截取成1s、2s、4s、8s、10s的语音段,用来测试不同时长的测试语音对于系统正确识别率的影响。实验结果如表2所示。

表2 在不同测试时间长度下识别准确率和识别时间
4 结束语
通过测试可知,在训练样本时间相对一致的情况下,测试样本时间越长,识别的准确度越高,完成识别所用时间越长;其参数提取采用39维差分MFCC方法能有效提高说话人识别系统性能。实验结果表明,设计的说话人识别系统具有较高的识别率和较短的识别时间,能基本满足办公室、家居环境下较少用户的说话人识别需要。
[1]吴朝晖,杨莹春.说话人识别模型与方法[M].北京:清华大学出版社,2009.
[2]D A Reynolds,Thomas F.Quatier and Robert B.Dram.Speaker verification using adapted Gaussian Mixture Models[J].Digital Singal Processing 10,Academic Press.2000:19-24.
[3]蒋伟,范明钰.基于高斯混合模型的说话人识别研究[D].成都.电子科技大学,2005.
[4]D A Reynolds,Campbell W,Gleason T T.The 2004 MIT Lincoln laboratory speaker recognition system[A].In Processdings of ICASSP[C],Philadel Phia,USA,2008.
[5]何朝霞,潘平.说话人识别中改进的MFCC参数提取方法[J].科学技术与工程,2011,11(18):4215-4218.
[6]王刚,邓方.电话信道下应用DMFCC进行说话人识别[J].清华大学学报,2009,49(10):1597-1600.
Design and Im plementation of Speaker Identification System Based on GMM
LIU Bing1,2,TENG Guang-chao1,3,LIN Jia-yu1
(1.Shool of Electronic Science and Engineering,National Defense Technology University,Changsha 410073,China;2.Xiangtan City Team,The Armed Police Corps of Hunan,Xiangtan 411104,China;3.Communications Department,Gold Corp I,The Armed Police,Harbin 150086,China)
In modern communication,the technology of the speaker's ID authentication is the focus of research and hotspots in communications industry.At present,the speaker identification technology,based on GMM and MFCC,is usable and poplar.In this paper,the composition of speaker identification system is researched and a system which uses Mel frequency cepstral coefficients(MFCC)as feature parameter and GMM for speakermodel is designed by Matlab.The test results show that the system can generallymeet the requirements of identification for work and life.
Speaker Recognition;MFCC;GMM
10.3969/j.issn.1002-2279.2014.03.018
TP391.4
:A
:1002-2279(2014)03-0063-03
刘冰(1985-),男,湖南省湘乡市人,工程硕士,主研方向:语音信号处理,说话人识别。
2013-10-30
