改进的K-means算法及其在铁路客户细分中的应用
2014-08-07杨壮英古军杰
邓 程 ,杨壮英,古军杰,蔡 志,李 粤
(广州铁路(集团)公司 株洲北站,株洲 412001)
改进的K-means算法及其在铁路客户细分中的应用
邓 程 ,杨壮英,古军杰,蔡 志,李 粤
(广州铁路(集团)公司 株洲北站,株洲 412001)
提出使用距离均和识别孤立点,并引入方差对孤立点进行判断处理,对传统的K-means算法进行改进并将改进后的K-means算法应用到铁路客户细分领域,实验结果表明,改进后的K-means算法能更为准确地对铁路货运客户进行聚类分析,从多维的角度较为全面、深入地细分客户消费行为特征,从而辅助铁路货运营销部门制定有针对性的营销策略,进行高效的客户关系管理,提高市场竞争力。
数据挖掘;铁路货运;K-means算法
随着当今物流的高速发展,市场竞争日趋激烈,铁路客户营销策略缺少对客户消费行为的深入挖掘,无法对不同类型的客户开展有针对性的营销策略,导致客户流失率缓慢增长以及铁路货运营业额的逐年下降。因此,确定新的分类指标,建立定量分析模型,对铁路客户进行更为精准的分类,是当前铁路货运营销部门所面临的重要问题。
1 K-means算法
1.1 聚类分析的概念
聚类分析简而言之是“物以类聚”,是指将抽象或具体集合分为由类似的对象组成的多个类的过程。由聚类所生成的簇是一组数据对象的集合,这些对象与同一个簇中的对象彼此相似,与其他簇中的对象相异。在商务上,聚类分析能帮助市场分析人员从客户基本库中发现不同的客户群,并用购买模式来刻画不同客户群的特征。K-means算法是当前应用最为普遍的聚类算法。
1.2 K-means算法的基本思想
K-means算法的基本思想是:将数据集分为K个空间,以K个空间的中心点按照物以类聚的原则进行聚类,将其属性值最接近的归为一类。然后进行迭代,不断移动簇集中的对象,更新各簇类中心的值,直至总体平方误差Sum of squared errors(SSE)达到预先规定的阈值,使得相同簇中对象高相似度,不同簇中对象之间高相异度。
1.3 孤立点对K-means聚类结果的影响
在数据挖掘范畴内,孤立点是指数据集中不符合一般模型的那些对象,即和其它的数据有着不同的性质,它可能是度量或执行错误所导致的,也可能是固有数据变异性的结果。即使是少量孤立点的存在也会对聚类结果产生很大的影响,因为孤立点的存在会使平均值得到很大的偏离,影响聚类准确度,严重影响了K-means算法的实际使用效果。
1.4 传统K-means算法中的不足
目前在K-means算法中普遍采用Euclidean Distance公式,即欧式距离作为检测数据集之间的相关性,如公式(1)所示:

欧式距离是指两点在欧式空间的直线距离,其优点是几何意义简单直观,如图1所示,Euclidean Distance是以圆形方式逼近中心点。

图1 Euclidean Distance公式逼近中心点效果图
从图1中可以看出距离公式法的不足之处在于:欧式距离将数据集中的不同属性之间的差别同等看待,即各属性对欧式距离的贡献是相同的。相异度很小的属性之间对欧式距离的贡献很小。因此欧式距离往往不能满足实际情况的需要。本文从对孤立点的识别和处理作为切入点,对传统的K-means算法进行改进。
2 K-means优化算法的改进
2.1 算法的改进思想
(1)对孤立点的识别
定义1:距离和Hi
Hi代表点i和其它点距离的总和,如公式(2)所示。
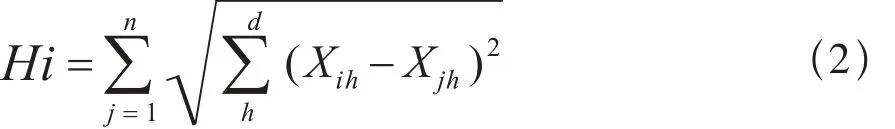
公式(2)中,Xih,Xjh分别代表两点的坐标值。
定义2:距离均和S
S代表点i和其它点距离的均和,如公式(3)所示。

其中n为样本数据d位数据的维数。对每个数据点i,首先计算其距离和Hi,并计算距离均和S,公式(3)中α为距离调节因子,本文通过实验对α值进行对比,确定为1.05。即当某个点距离待聚类的种群数据的平均距离均和的1.05倍时,则认定为孤立点。将该孤立点从初始样本中挑选出来,以此类推,找出初始样本中所有的孤立点。
(2)引入方差对孤立点进行处理
由于相异度很小的属性之间对欧式距离的贡献很小。所以不能仅仅依靠距离来判断孤立点属于脏数据而给予抛弃。因此在对孤立点进行考核的时候,还要依据孤立点与簇内的相似度。在此引入方差,因为相似度可以用方差来衡量。如果簇内的方差越大,则说明簇内的相似度越小。反之如果簇内方差越小,则说明簇内的相似度越大。
类K的方差Vk的定义:
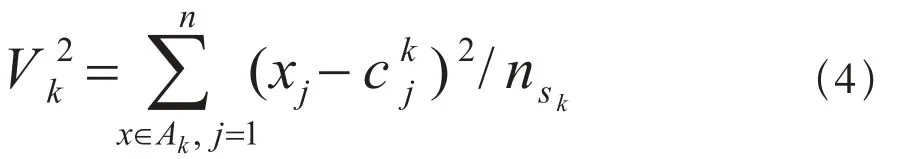
公式(4)中Ak表示类k内的数据集x所构成的空间;x表示类k的数据集;Xj表示数据点在变量j上的取值;nsk表示类k内的数据集数量;表示k的中心点在变量j上的取值;
相对距离的定义:
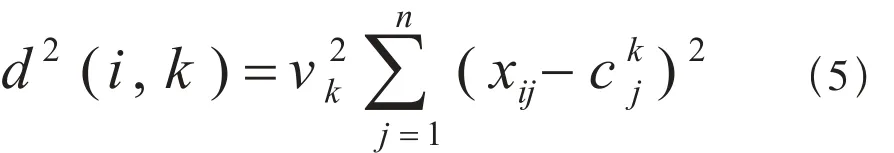
计算每个孤立点各簇内中心的相对距离,将孤立点分配到与之最近的簇中,如果加入孤立点后的SSE大于加入孤立点之前的SSE,则抛弃该孤立点,反之则将将孤立点分配到该簇。
2.2 改进的K-means算法描述

3 基于改进的K-means算法的铁路货运客户细分
3.1 铁路客户细分指标的确定和数据预处理
(1)分类指标的确定
通过与铁路货运营销人员沟通,确定客户细分分类指标包括:客户关系建立时间、月平均运费、年度运输配送次数、年度运输配送次数、是否存在附加收益、年发送量、客户影响力。
(2)数据预处理
在数据挖掘中,提取自2012年6月1日00: 00 ~ 2013年6月1日23:59,2年共129 196条记录。数据来源于中铁快运货票中的历史数据,这些原始的数据不可能不加处理的直接用于数据挖掘,存在的一些噪声,缺失数据和不一致性数据会给数据挖掘的结果产生较大影响。因此,在进行数据挖掘之前,必须对这些数据进行预处理。所用的数据预处理包含数据集成、数据归约、数据清理和数据变换几种方法。由于年度运输配送次数采用的是离散型的数值,而年度运输配送次数是一个连续性数值属性,需要把连续值属性离散化,采用概念分层的方法,具体约定如表1所示。
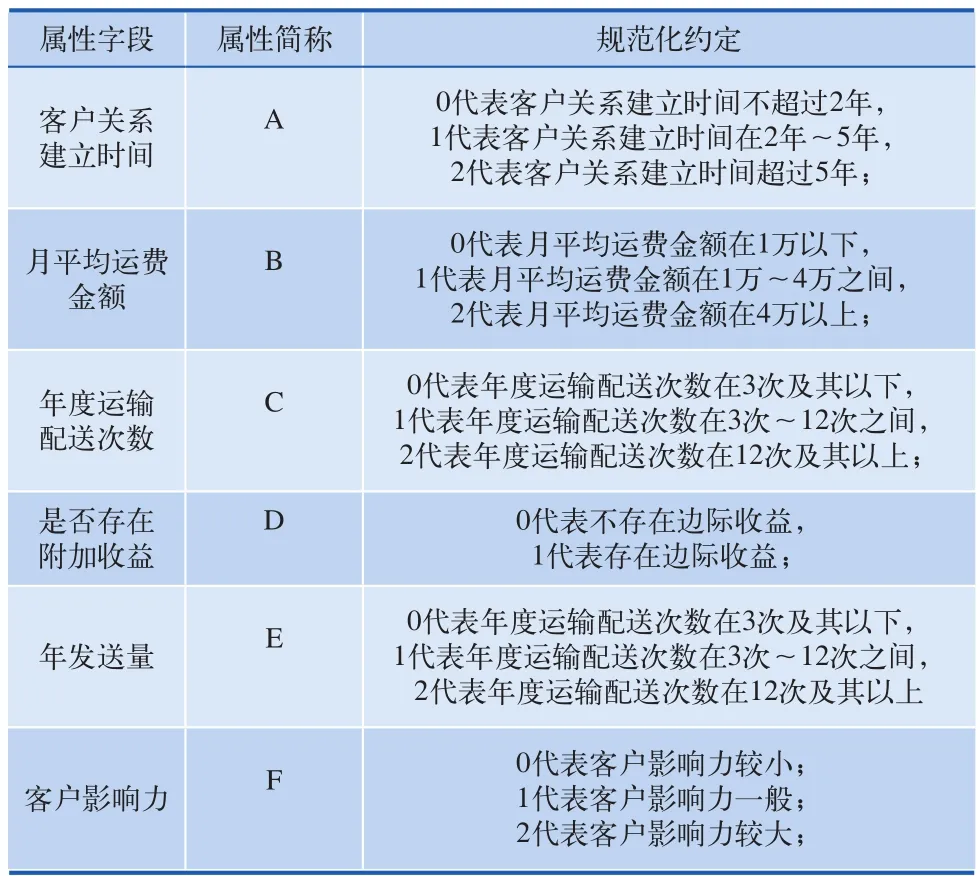
表1 规范化约定表
3.2 聚类结果分析
经过反复实验,最终将铁路客户划分为5个簇类,聚类分析如表2所示。
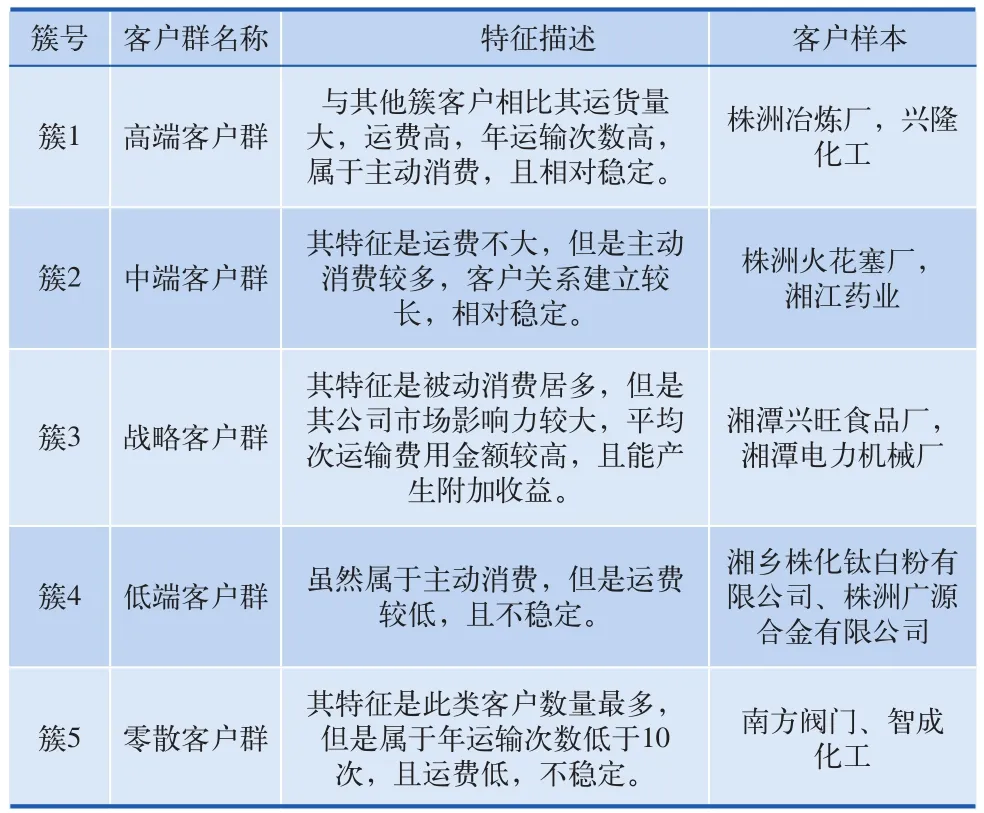
表2 聚类结果分析表
从表2可以看出,高端客户占铁路运输收益的贡献值最大,在今后的工作中要进一步加强这部分客户关系的维护工作。战略客户群虽然不稳定,但是达到了铁路平均收益的1/4,是铁路营销部门开拓市场重点发展的对象,提供有针对性的个性化服务,争取将这部分客户发展在铁路的高端客户,这将极大提高铁路的经济收益。
用原K-means算法对相同的预处理后数据集进行挖掘,其聚类结果相差较大。每个簇之间的界定,无法清晰地给出,因为某些客户群的划分是矛盾的。2次实验结果差异的原因就是在于是否对数据集去除了孤立点。
例如“株洲火炬工业炉有限责任公司”这个客户,在去除孤立点之后的K-means中聚类到簇1高端客户群中。而在没有去除孤立点之后的K-means聚类中,则被划分到簇3战略客户群中,其原因就是“永利化工”这个客户,按照优化K-means是一个孤立点,“永利化工”在2012年5月~2012年9月,共产生运输次数71次,超过任何一个客户当年运输总次数。因此其特征更加靠近簇2中端客户群,但是“永利化工”其它的属性特征,例如客户类型,客户关系发生时间,运费金额,客户忠诚度等属性又符合簇1低端客户群的特征,因此在做聚类分析的时候,造成质心偏离,得出不一样的聚类结果。经过和铁路货运人员沟通确定,“株洲火炬工业炉有限责任公司”应属低端客户群,从而也论证了去除孤立点算法对准确进行客户的聚类划分是有帮助。
4 结束语
本文针对传统的基于距离识别孤立点的K-means算法中,无法处理密度不均匀的数据集局部特征的缺点进行了改进,提出了使用距离均和识别孤立点,并引入方差对孤立点进行判断处理。通过实验验证,改进后的K-means算法有效避免了将孤立点全部抛弃的盲目性,有效降低了总体平方误差,把相同特质的数据划为一个簇内,提高了聚类的精确度。将改进后的K-means算法,应用到铁路客户细分领域,使得聚类结果更为精确,从多维的角度较为全面、深入地细分客户消费行为特征。在确定目标客户后,铁路货运营销部门可以实施有针对性的营销和客服方案,进行高效的客户关系管理。下一步工作的重点是全面分析铁路营业额季节性周期变化规律与客户特征之间的关联规则,以提高铁路货运的竞争力和市场占有率。
[1]Johannes Grabneier,Andreas Rudolph. Techniques of Cluster Algorithms in Data Mining, Data Mining and Knowledge Discovery[J]. Kluwer Academic Publishers, 2002(6): 303-360.
[2]景 波,刘 莹,黄 兵. 基于孤立点检测的工作流研究 [J]. 计算机工程,2008,4(22): 268-270.
[3]潘 莹,梁京章,黎慧娟. 基于K-means算法的校园网用户行为的聚类分析 [J]. 计算技术与自动化,2007,26(1):66-68.
[4]陈 伟. Apriori算法的优化方法[J]. 计算机技术与发展,2009,19(6):80-83.
责任编辑 方 圆
Improved K-means Algorithm and its application in railway customer segmentation
DENG Cheng, YANG Zhuangying, GU Junjie, CAI Zhi, LI Yue
( Zhuzhou North Station, Guangzhou Railway Group Company, Zhuzhou 412001, China )
This paper put forward the idea of improving the traditional K-means Algorithm with identifying the isolated points by average distance sum, and judged and processed the isolated points by introducing variance. The improved K-means Algorithm was applied to the field of railway freight customer segmentation. The experimental result showed that the improved K-means Algorithm could carry out cluster analysis on railway freight customers more accurately, sectionalize the characteristics of customers’ consuming behaviors in a comprehensive and in-depth manner from multidimensional perspectives, thus assist railway freight marketing department to formulate targeted marketing strategies, carry out high eff i cient customer relation management and increase market competitiveness.
data mining; railway freight transportation; K-means Algorithm
U293∶TP39
:A
1005-8451(2014)06-0045-04
2013-12-19
邓 程 ,技术员;杨壮英,工程师。
